
pandas学习笔记
pandas是什么?为什么要用pandas?
pandas是一个第三方python库,有强大的数据加载,操作,分析功能。
可以认为pandas是python中的数据库。
如何使用pandas?
pandas主要有两种数据存储类型:Series 和 DataFrame,分别是二维数据和三维数据。
接下来学习如何加载,读取,操作,分析。
Series
加载
Series 和 dict 是很像的。
普通方式:
x=pd.Series([1, 2, 3], index=[1, 2, 'a'])
而index可以省略,这时候默认为从 0 开始编号的数字。
dict方式:
x=pd.Series({'a':1, "b":2},index=['b', 'c'])
这里的index可以省略,默认为字典的keys()。但是如果不省略,那么索引就一定只是index里面的,比如上面就只剩下 b。同时上面的 c 在字典中没出现,这时候在 Series 会保存为 NaN,pandas 的数据存储允许某些位置数据缺失。
读取
直接索引访问,所以说和dict很像:
print(x['a'])
这时候输出的是一个元素对象。
可以使用切片操作:
print(x[:1])
可以使用索引列表:
print(x[['a', 'b']])
这两个的结果都是一个 Series 对象。
分析
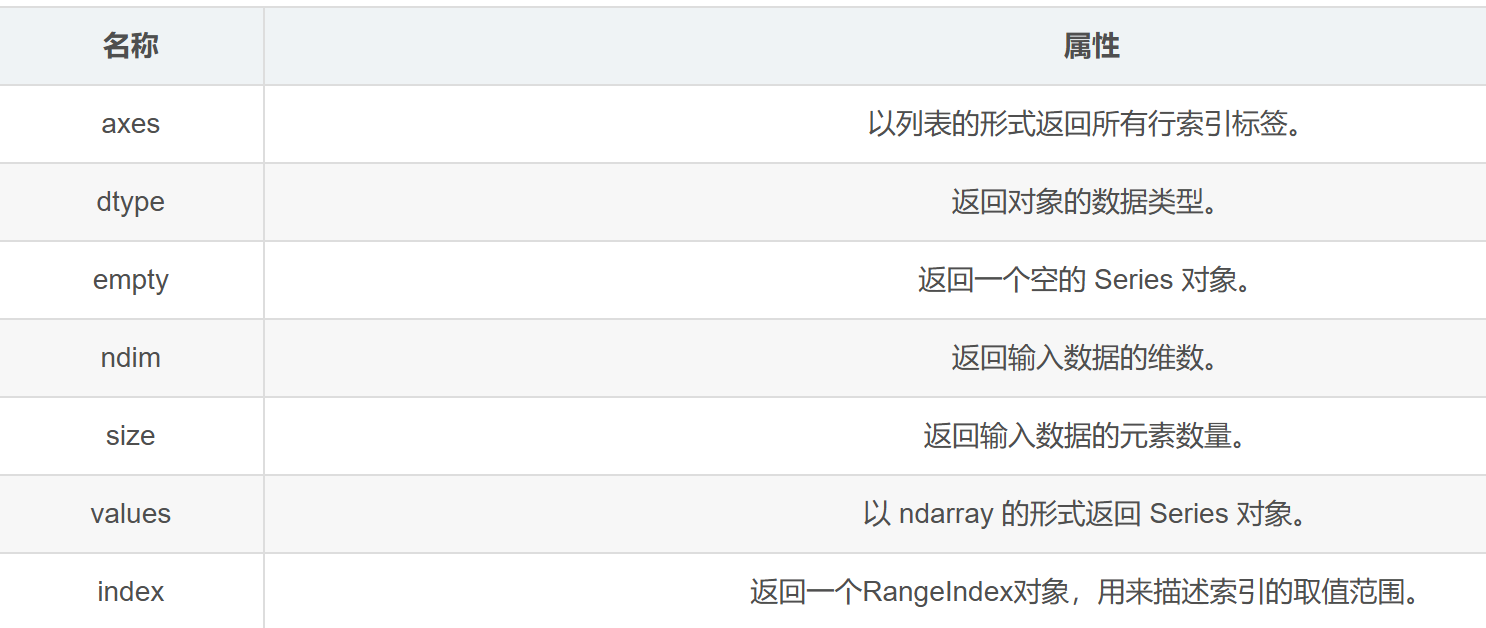
这里有些常用的 Series 属性。
isnull()&nonull()检测缺失值方法。
s=pd.Series([1,2,5,None])
print(pd.isnull(s)) #是空值返回True
print(pd.notnull(s)) #空值返回False
output:
0 False
1 False
2 False
3 True
dtype: bool
notnull():
0 True
1 True
2 True
3 False
dtype: bool
操作
还没学。
DataFrame
通识
DataFrame是一个既有 Index 又有 Column 的二维表。允许表内的数据是 NaN。

创建
pd.DataFrame( data, index, columns, dtype, copy)
data 表示数据,index 表示行标签,columns 表示列标签,dtype 表示数据类型,copy 表示是否将 data 复制一份再构造。
下面解析 data 的几种形式。
第一种,二维列表:
x=pd.DataFrame([[1, 2, 3], [3, 4, 5]])
这样构造出一个两行三列,行标签和列标签都默认的表。
第二种,字典嵌套列表:
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
这里列标签就会变成 Name 和 Age。可以联想到构建 Series 可以用普通字典。想法都是把字典的键值作为列标签/索引。
第三种,列表嵌套字典:
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
这里第一行第三列会使 NaN。
第三种,字典嵌套 Series:
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
联想到 Series 和字典差不多,所以字典嵌套字典也行。
总之,第一层是列标签,第二层是行标签。
读取
列读取方法。
通过列标签取出一个 Series,再用 Series 方法取出某个元素。
x=pd.DataFrame([[1,2],[3,4]]])
x[0] # 一个 Series
x[[0, 'a']] # 一个子 DataFrame
x[0][0]
行读取方法。
一样的,取出来是 Series。
x=pd.DataFrame([[1,2],[3,4]]])
x.loc[0]
两者都可以实现切片于 [] 列表索引,和 Series 是一样的。
操作
列添加方法。
像字典一样直接赋值就好了。
x=pd.DataFrame([[1,2],[3,4]]])
x['a']=pd.Series([1, 2])
x['b']=x[0]+x[1]
而且还能用向量化加法,因为 Series 是基于 ndarray 实现的。
列删除方法,del 或者 pop。
del x['a']
x.pop('a')
行添加方法。
x.append(y) # y 是一个 DataFrame

 浙公网安备 33010602011771号
浙公网安备 33010602011771号