

华为昇腾 910B GPU
1 术语
1.1 与 NVIDIA 术语对应关系
大部分人目前还是对 NVIDIA GPU 更熟悉,所以先做一个大致对照,方便快速了解华为 GPU 产品和生态:
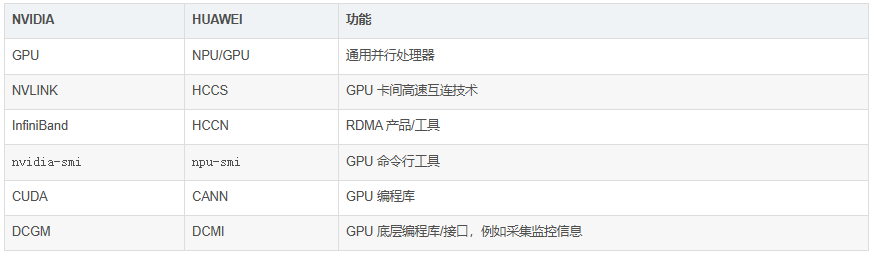
说明:华为很多地方混用术语 NPU 和 GPU,为简单起见,本文统称为 GPU。
1.2 缩写
NPU: Neural-network Processing Unit
HCCS: Huawei Cache Coherence System
HCCN: Huawei Cache Coherence Network
CANN: Huawei compute Architecture for Neural Networks
DCMI: DaVinci Card Management Interface
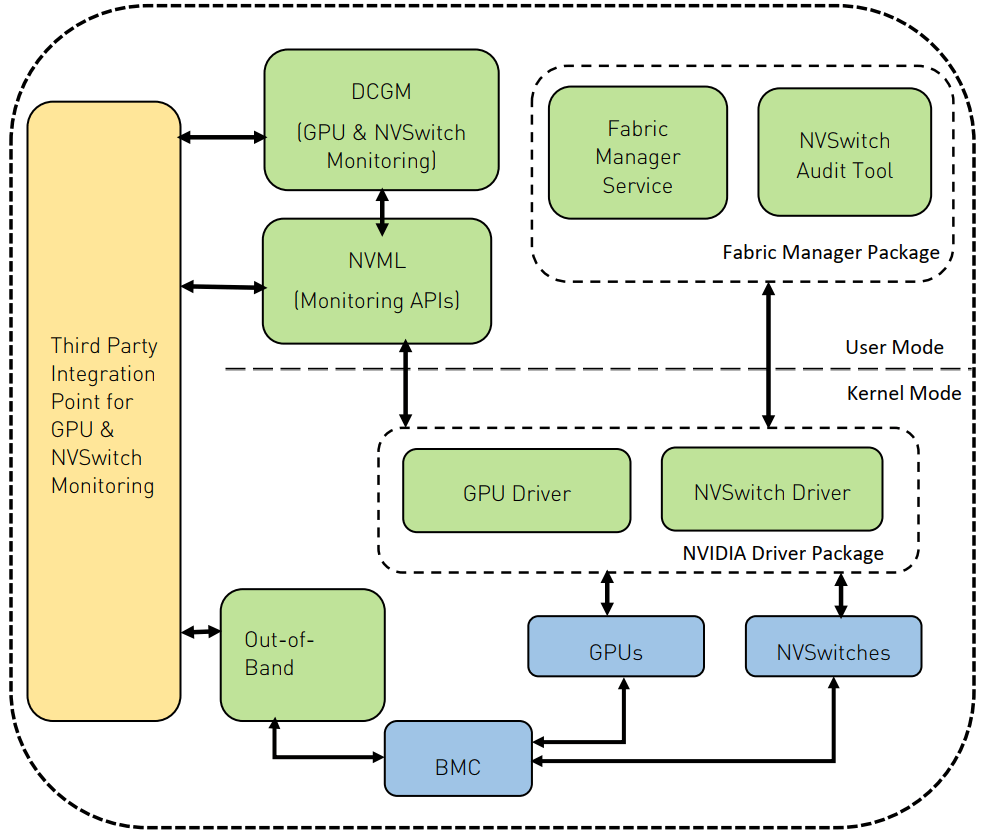
2 产品与机器
2.1 GPU 产品
- 训练:昇腾 910B,对标 NVIDIA
A100/A800,算力对比; - 推理:Atlas 300 系列,对标 NVIDIA T4;
2.2 训练机器
底座 CPU
根据 CPU 不同分为两种:
-
x86 底座
- 客户需要适配的工作量小一些;
-
arm 底座:鲲鹏系列
- 华为云上一般提供的是这种
- 功耗低,叠加液冷,可以实现比常规 NVIDIA 服务器更好的“性能/功耗”比;
功耗
16 卡昇腾 910B 训练机器,8U,功耗对比:
- X86: 12KW
- ARM: 4.5KW
2.3 性能
一些公开信息:
3 实探:鲲鹏底座 8*910B GPU 主机
8 卡训练机器配置,来自华为云环境:
机型: physical.kat2ne.48xlarge.8.ei.pod101
CPU: Kunpeng 920 (4*48Core@2.6GHz),ARM 架构,192 核
内存: 24*64GB DDR4
网卡: 2*100G + 8*200G
浸没式液冷
3.3 GPU 信息

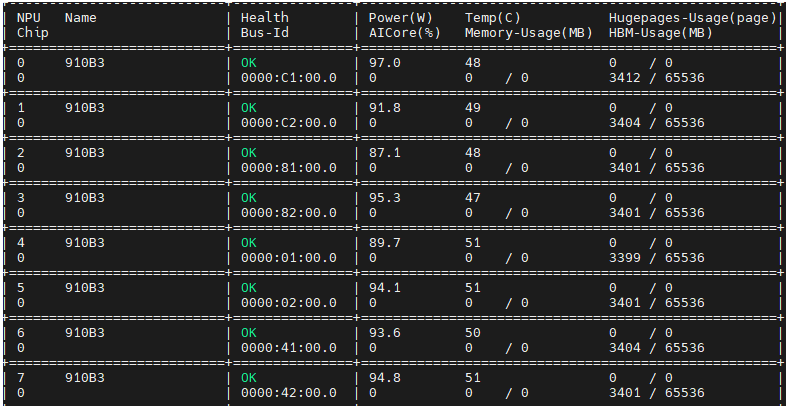
npu-smi info HBM-Usage(MB)
npu-smi info命令中的HBM-Usage(MB)指的是片上内存(HBM)占用率,单位是MB(兆字节)。这个参数用于显示NPU(神经网络处理单元)设备上当前被占用的片上内存量。 具体来说,在使用npu-smi info命令查询NPU设备的基本信息时,HBM-Usage(MB)会列出每个NPU设备上当前正在被使用的片上内存量。这个信息对于了解设备的内存使用情况、优化内存分配以及进行故障排查等方面都是非常有用的。 需要注意的是,业务训练结束后,由于操作系统的缓存机制,可能会显示有0~8M的片上内存被占用,这属于正常现象。下次训练时,这部分内存会再次被分配使用。 此外,npu-smi info命令还会提供其他关于NPU设备的信息,如芯片名称、健康状态、功率、温度、大页内存占比、AICore占用率、内存占比以及进程信息等。这些信息共同构成了对NPU设备状态的全面描述,有助于用户更好地了解和管理设备。
npu-smi info health Bus-Id 是什么
在npu-smi info命令的输出中,health和Bus-Id是两个重要的参数,分别表示NPU(神经网络处理单元)设备的健康状态和总线标识符。 health health参数用于显示NPU设备的健康状态。这个状态通常有以下几种可能: OK:表示设备处于正常状态,没有检测到任何异常。 Warning:表示设备存在一般告警,可能需要用户关注并采取相应的措施。 Alarm:表示设备存在重要告警,需要用户立即关注并处理。 Critical:表示设备处于紧急告警状态,需要用户立即采取措施以防止设备损坏或数据丢失。 UNKNOWN:表示该设备不存在或未启动,无法获取其健康状态。 Bus-Id Bus-Id参数提供了NPU设备在系统中的总线标识符,它通常遵循一个特定的格式,即“域号:总线号:设备号.功能号”。这个标识符对于识别和管理系统中的多个NPU设备非常有用。具体来说: 域号:对于大多数系统来说,域号通常是默认值,如“0000”。 总线号:表示NPU设备连接到哪个PCIe总线上。 设备号:表示在特定的总线上,NPU设备是第几个设备。 功能号:对于NPU设备来说,功能号通常是“0”。 例如,一个NPU设备的Bus-Id可能是“0000:01:00.0”,这意味着该设备连接到第一个PCIe总线上,是该总线上的第一个设备,功能号为“0”。 通过npu-smi info命令查看health和Bus-Id等参数,用户可以更好地了解和管理NPU设备的状态,从而确保系统的稳定运行和高效性能。
npu-smi info power(W) AICore(%)
在npu-smi info命令的输出中,power(W)和AICore(%)是两个关键的参数,它们分别表示NPU(神经网络处理单元)设备的功耗和AI核心的使用率。 power(W) power(W)参数显示了NPU设备的当前功耗,单位是瓦特(W)。这个参数对于了解设备的能耗情况、进行功耗管理以及优化能源使用等方面都非常重要。在输出中,如果功耗显示为“NA”,则表示未提供或不可用。 AICore(%) AICore(%)参数表示NPU设备上AI核心的使用率,即当前正在使用的AI核心占总AI核心的比例。这个参数对于评估设备的性能负载、优化资源使用以及进行故障排查等方面都很有用。需要注意的是,在某些特定场景下,如算力切分容器场景下,获取的AICore(%)可能为0,此时该值实际无意义。 通过npu-smi info命令查看power(W)和AICore(%)等参数,用户可以更好地了解NPU设备的运行状况,从而进行更有效的管理和优化。例如,如果发现功耗过高或AI核心使用率不足,用户可以采取相应的措施来降低能耗或提高资源利用率。 总之,npu-smi info命令是一个强大的工具,它提供了关于NPU设备的详细信息,包括功耗、AI核心使用率等关键参数,有助于用户更好地了解和管理设备。
npu-smi info Temp(C) memory-Usage(MB)
在npu-smi info命令的输出中,Temp(C)和memory-Usage(MB)是两个重要的参数,分别表示NPU(神经网络处理单元)设备的温度和内存使用量。 Temp(C) Temp(C)参数显示了NPU设备的当前温度,单位是摄氏度(C)。这个参数对于监控设备的热状态、预防过热以及确保设备在安全温度范围内运行非常重要。如果设备温度过高,可能会导致性能下降、系统不稳定甚至硬件损坏。因此,定期监控Temp(C)参数并根据需要采取冷却措施是很重要的。 memory-Usage(MB) memory-Usage(MB)参数表示NPU设备上当前被占用的内存量,单位是兆字节(MB)。这个参数对于了解设备的内存使用情况、优化内存分配以及避免内存不足导致的性能瓶颈或任务失败非常关键。如果内存使用量接近或达到设备的总内存容量,用户可能需要考虑增加内存资源、优化内存使用策略或终止一些不必要的任务来释放内存。 通过npu-smi info命令查看Temp(C)和memory-Usage(MB)等参数,用户可以实时监控NPU设备的运行状况,并根据需要进行相应的调整和优化。这有助于确保设备的稳定运行、高效性能以及延长硬件寿命。 请注意,具体的npu-smi info命令输出可能会因NPU型号、驱动程序版本以及系统配置的不同而有所差异。因此,在实际使用中,用户应参考相应的文档或手册来了解特定系统和NPU设备的详细信息和参数解释。
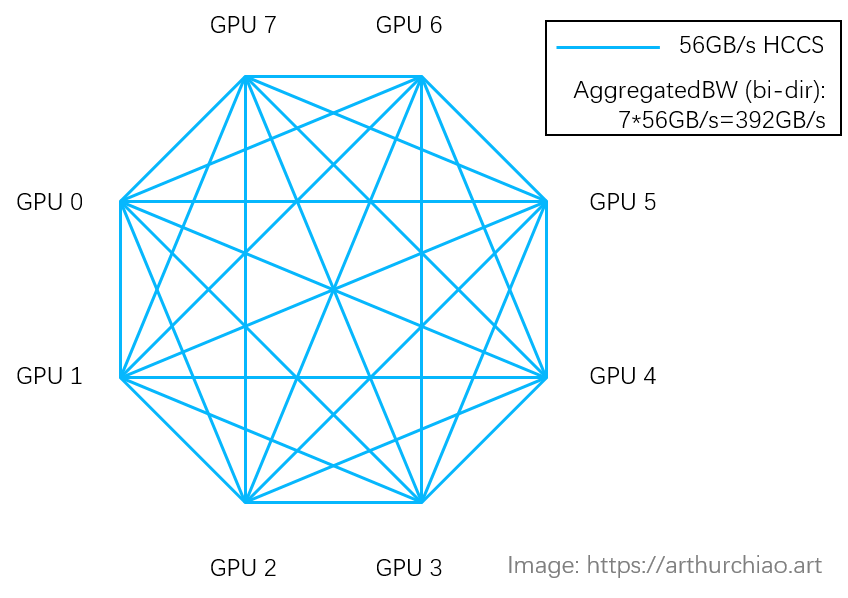
3.3.1 GPU 卡间互连:HCCS
角色类似于 NVIDIA NVLink。
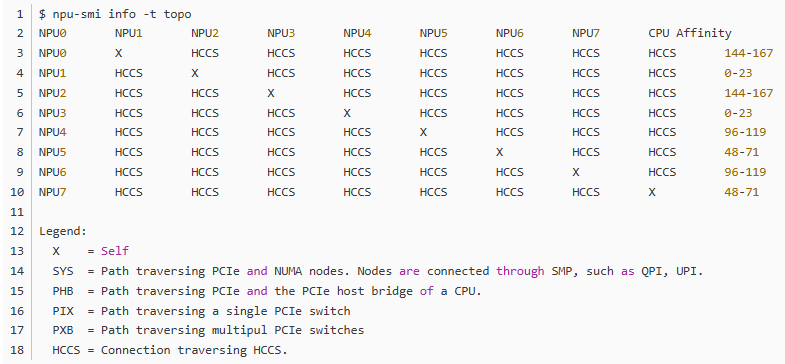
很多资料都说 910B 的卡间互连带宽是 392GB/s,看起来跟 A800 的 400GB/s 差不多了, 但其实还是有区别的,主要是互连拓扑不同导致的,详见 [1]。
3.4 Linux 设备
8 张 910B GPU 及一个管理设备:
$ ls /dev/davinci* /dev/davinci0 /dev/davinci1 /dev/davinci2 /dev/davinci3 /dev/davinci4 /dev/davinci5 /dev/davinci6 /dev/davinci7 /dev/davinci_manager
davinci 是华为 GPU/NPU 的架构名,更多信息见下一篇 GPU 进阶笔记(三):华为 NPU (GPU) 演进(2024)。 还有两个设备比较重要
$ ll /dev/hisi_hdc # HDC-related management device crw-rw---- 1 HwHiAiUser HwHiAiUser 237, 0 /dev/hisi_hdc $ ll /dev/devmm_svm # Memory-related management device crw-rw---- 1 HwHiAiUser HwHiAiUser 238, 0 /dev/devmm_svm
然后 docker run 可以直接启动容器,挂载必要的设备、驱动等等:
$ sudo docker run -itd --cap-add=SYS_PTRACE --net=host --shm-size="32g" \ --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 \ --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 \ --device=/dev/davinci6 --device=/dev/davinci7 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
$ ls /usr/local/dcmi/
dcmi_interface_api.h libdcmi.so
摘自
https://blog.csdn.net/hao_wujing/article/details/144820794

 浙公网安备 33010602011771号
浙公网安备 33010602011771号