
实验5 文件应用编程
实验任务6
task6
# 读取并处理原始数据with open('data6.csv','r',encoding = 'gbk') as f: old_data = f.read().split('\n') del old_data[0] # 四舍五入得到新数据 new_data = [] for i in range(len(old_data)): if eval(old_data[i]) + float(0.5) >= int(eval(old_data[i])) + 1: new_data.append(str(int(eval(old_data[i]))+1)) else: new_data.append(str(int(eval(old_data[i])))) # 形成二维列表 title = ['原始数据','四舍五入后数据'] data = [] for i in range(len(old_data)): data.append([old_data[i],new_data[i]]) # 写入 with open('data6.csv','w',encoding = 'gbk') as f: f.write(','.join(title) + '\n') for i in data: f.write(','.join(i) + '\n') print('原始数据:')print(old_data)print('四舍五入后数据:')print(new_data)
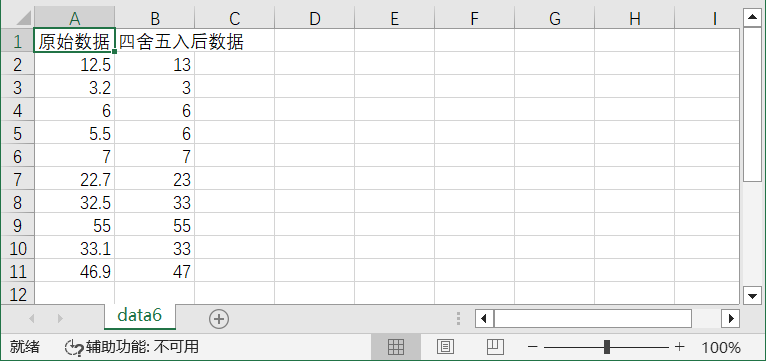
运行结果如图:

实验任务7
更新数据:
# 读取并处理信息 with open('data7.csv','r',encoding = 'gbk') as f: info = f.read().split('\n') del info[0] # 首先按专业排序 # 以专业为值创建字典 major_dict = {} for i in info: person_list = i.split(',') major_dict[i] = person_list[2] # 排序 items = [[k,v] for k,v in major_dict.items()] items.sort(key=lambda x:x[1]) # 将同一专业的学生放在一起,并按照分数排序 # 计算专业数量并建立专业列表 majors_count = 1 majors_list = [] for i in range(len(items)-1): if items[i+1][1] == items[i][1] and items[i][1] not in majors_list: majors_list.append(items[i][1]) pass elif items[i+1][1] == items[i][1] and items[i][1] in majors_list: pass else: majors_list.append(items[i+1][1]) majors_count += 1 # 将相同专业学生放在一起: for i in range(majors_count): x = locals()[f'major{i+1}'] = [] # 循环创建变量 for j in range(len(items)): if items[j][1] == majors_list[i]: x.append(items[j][0]) else: pass # 每个专业内按照分数排序 # 以分数为值创建字典并排序 score_dict1 = {} for i in major1: person_list = i.split(',') score_dict1[i] = person_list[3] items1 = [[k,v] for k,v in score_dict1.items()] items1.sort(key=lambda x:x[1],reverse = True) score_dict2 = {} for i in major2: person_list = i.split(',') score_dict2[i] = person_list[3] items2 = [[k,v] for k,v in score_dict2.items()] items2.sort(key=lambda x:x[1],reverse = True) together = items1 + items2 final_data = [i[0] for i in together] # 更新数据文件 final_list = [] for i in final_data: person_list = i.split(',') final_list.append(person_list) print(final_list) title = ['学号','姓名','专业','分数'] with open('data7.csv', 'w', encoding = 'gbk') as f: f.write(','.join(title) + '\n') for item in final_list: f.write(','.join(item) + '\n')
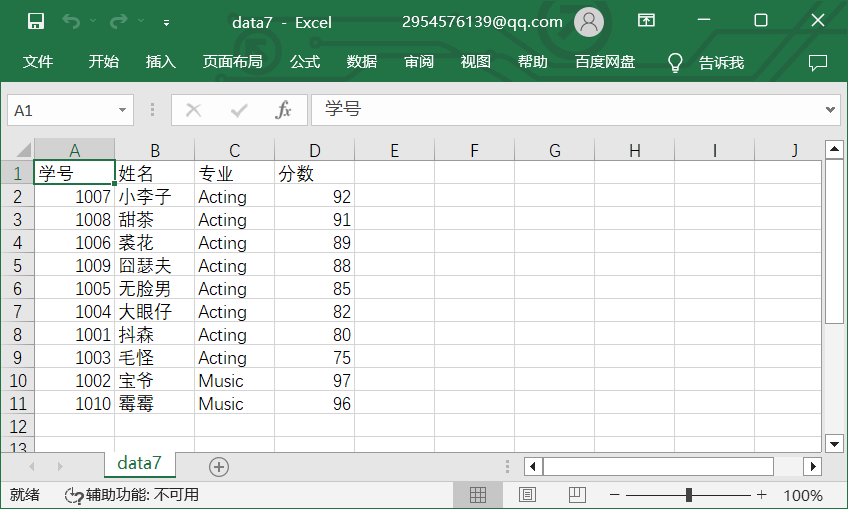
运行结果如图:
实验任务8
# 统计lines_count = 0 words_count = 0 chrs_count = 0 space_count = 0 with open('hamlet.txt','r',encoding = 'utf-8') as f: for line in f: words = line.split() lines_count += 1 words_count += len(words) chrs_count += len(line) for i in list(line): if i == ' ': space_count += 1 else: pass print('行数:',lines_count) print('单词数:',words_count) print('字符数:',chrs_count) print('空格数:',space_count)
运行结果如图:

# 给每一行加上序号 with open('hamlet.txt','r',encoding = 'utf-8') as f: text = f.readlines() for i in range(len(text)): if text[i]: text[i] = str(i+1) + ' ' + text[i] with open('hamlet.txt','w',encoding = 'utf-8') as f: f.writelines(text)
运行结果如图:

实验任务9
# 判断是否合法 def is_valid(p_id): if len(p_id) != 18: return False else: a = p_id[-1] b = p_id[:-1] if b.isdigit() == True and a == 'X' or p_id.isdigit() == True: return True else: return False # 读取并筛选出合法的数据 with open('data9_id.txt','r',encoding = 'utf-8') as f: info = f.read().split('\n') del info[0] id_list = [] for i in info: x = i.split(',') if x[0] not in id_list and is_valid(x[1]) == True: id_list.append([x[0],x[1]]) # 每个人的出生年月日, import datetime t = datetime.datetime.now() year_now = int(t.strftime('%Y%m%d')[0:4]) month_now = int(t.strftime('%Y%m%d')[4:6]) day_now = int(t.strftime('%Y%m%d')[6:8]) year_dict = {} for i in range(len(id_list)): p_id = id_list[i][1] year = int(p_id[6:10]) month = int(p_id[10:12]) day = int(p_id[12:14]) p_info = id_list[i][0] + ',' + str(year) + '-' + str(month) + '-' + str(day) + ',' if month <= month_now and day < day_now: # 判断今年是否已经过生日 year_dict[p_info] = year_now - year - 1 else: year_dict[p_info] = year_now - year # 排序 print('姓名,出生日期,年龄') items = [[k,v] for k,v in year_dict.items()] items.sort(key=lambda x:x[1],reverse = True) for i in items: print(f'{i[0]}{i[1]}')
运行结果如图:

实验任务十
task10_1
print(f"{'抽点开始':*^40}") import random as r with open('data10_stu.txt','r',encoding = 'utf-8') as f: stu = f.readlines() # 定义抽取函数 def the_lucky_dogs(n): stu_list = [] while True: if n != 0: i = r.randint(0,len(stu)-1) if stu[i] not in stu_list: stu_list.append(stu[i]) print(stu[i]) n -= 1 else: pass else: print(f"{'抽点结束':*^40}") break # 抽取 n = int(input('输入随机抽点人数:')) the_lucky_dogs(n)
运行结果如图:

task10_2
print(f"{'抽点开始':*^40}") import random as r with open('data10_stu.txt','r',encoding = 'utf-8') as f: stu = f.readlines() # 定义抽取函数 def the_lucky_dogs(n): stu_list = [] while True: if n != 0: i = r.randint(0,len(stu)-1) if stu[i] not in stu_list: stu_list.append(stu[i]) print(stu[i]) n -= 1 else: pass else: break for i in stu_list: # 排除之前已经被抽到的学生 stu.remove(i) # 抽取 while True: n = int(input('输入随机抽点人数:')) if n != 0: the_lucky_dogs(n) else: print(f"{'抽点结束':*^40}") break
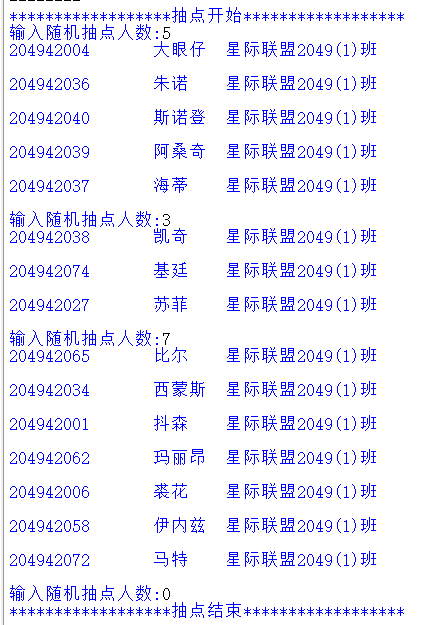
运行结果如图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号