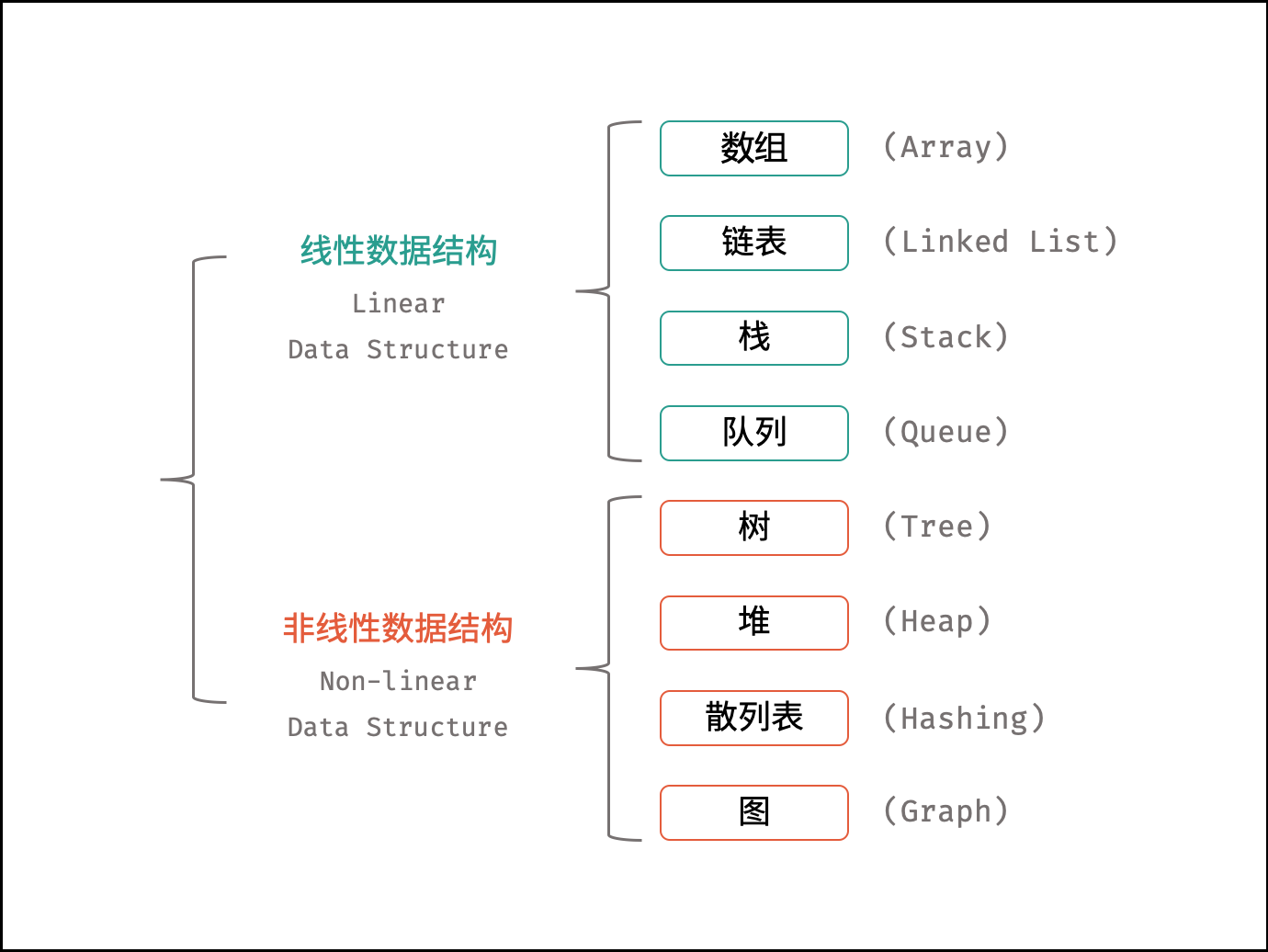
数据结构基础知识
概述
数据结构是为实现对计算机数据有效使用的各种数据组织形式,服务于各类计算机操作。不同的数据结构具有各自对应的适用场景,旨在降低各种算法计算的时间与空间复杂度,达到最佳的任务执行效率。
分类
线性数据结构(物理结构)
数组(Array)、链表(Linked List)、栈(Stack)、队列(Queue)
非线性数据结构(逻辑结构)
树(Tree)、堆(Heap)、散列表(Hashing)、图(Graph)
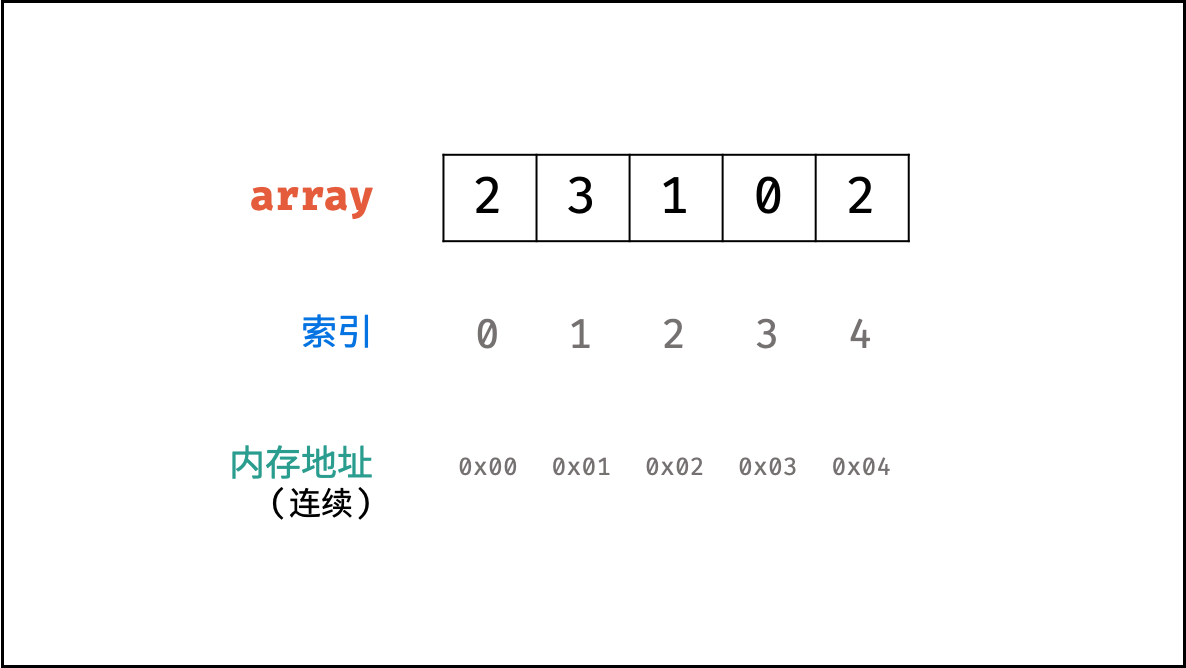
数组
数组是将相同类型的元素存储于连续内存空间的数据结构,其长度不可变。
如下图所示,构建此数组需要在初始化时给定长度,并对数组每个索引元素赋值,代码如下:
// 初始化一个长度为 5 的数组 array
int[] array = new int[5];
// 元素赋值
array[0] = 2;
array[1] = 3;
array[2] = 1;
array[3] = 0;
array[4] = 2;
或者可以使用直接赋值的初始化方式,代码如下:
int[] array = {2, 3, 1, 0, 2};
可变数组
可变数组是经常使用的数据结构,其基于数组和扩容机制实现,相比普通数组更加灵活。常用操作有:访问元素、添加元素、删除元素。
// 初始化可变数组
List<Integer> array = new ArrayList<>();
// 向尾部添加元素
array.add(2);
array.add(3);
array.add(1);
array.add(0);
array.add(2);
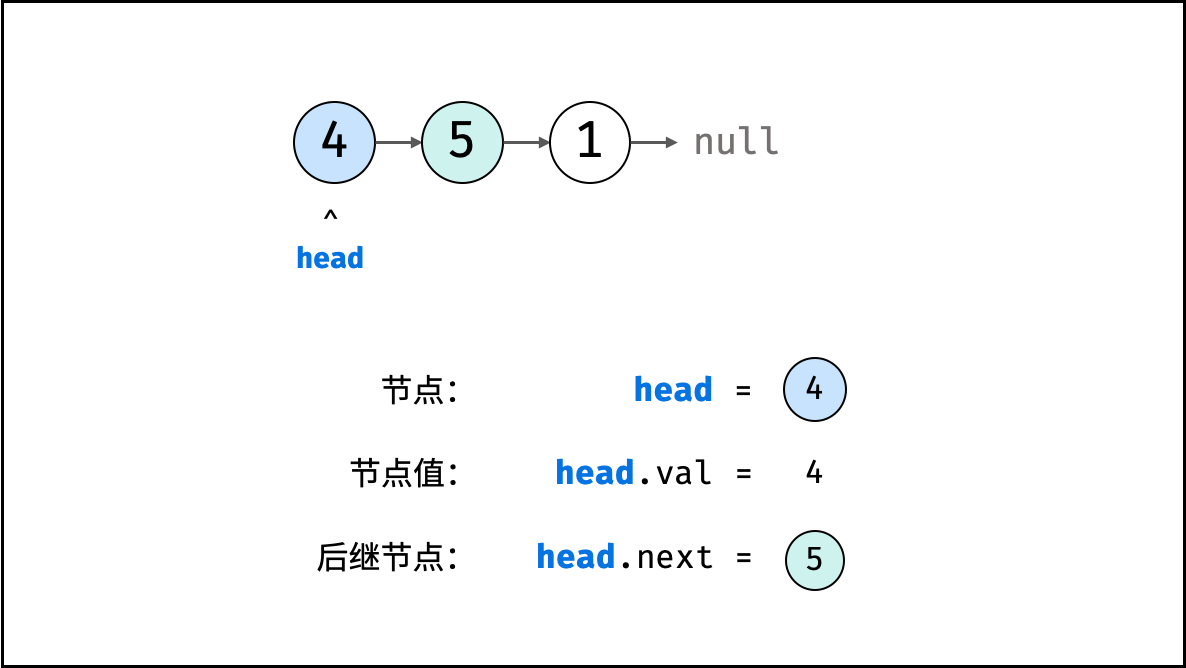
链表
链表以节点为单位,每个元素都是一个独立对象,在内存空间的存储是非连续的。链表的节点对象具有两个成员变量:「值 val」,「后继节点引用 next」。
class ListNode {
int val; // 节点值
ListNode next; // 后继节点引用
ListNode(int x) { val = x; }
}
如下图所示,建立此链表需要实例化每个节点,并构建各节点的引用指向。
// 实例化节点
ListNode n1 = new ListNode(4); // 节点 head
ListNode n2 = new ListNode(5);
ListNode n3 = new ListNode(1);
// 构建引用指向
n1.next = n2;
n2.next = n3;
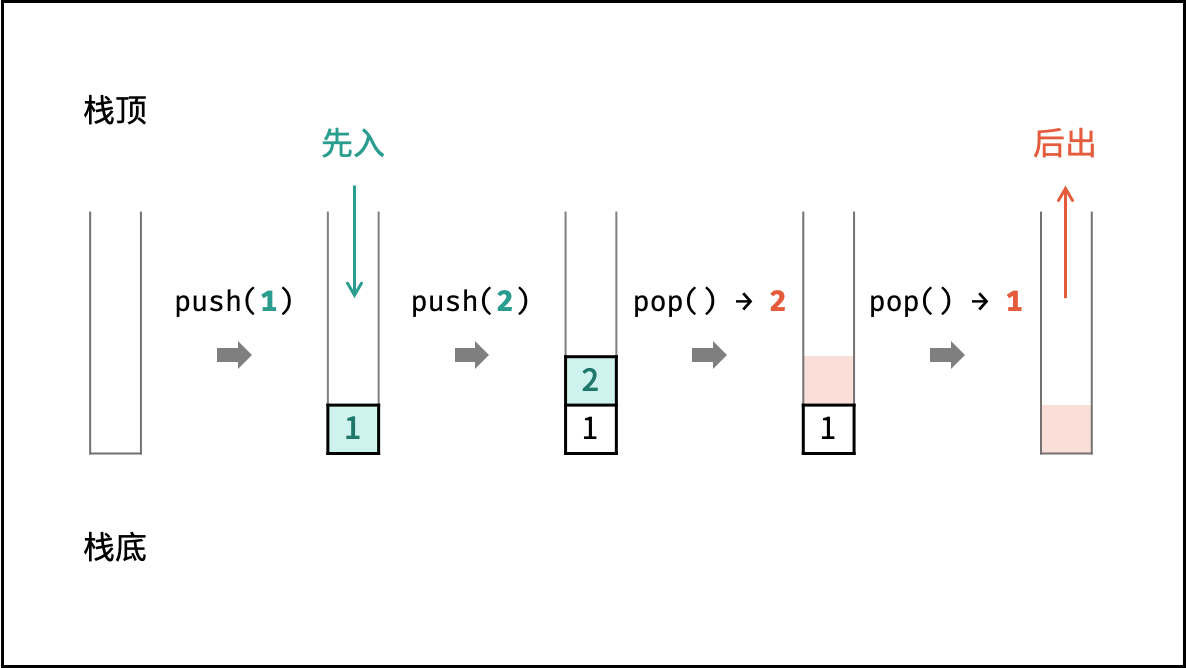
栈
栈是一种具有 「先入后出」 特点的抽象数据结构,可使用数组或链表实现。
Stack<Integer> stack = new Stack<>();
如下图所示,通过常用操作 「入栈 push()」,「出栈 pop()」,展示了栈的先入后出特性。
stack.push(1); // 元素 1 入栈
stack.push(2); // 元素 2 入栈
stack.pop(); // 出栈 -> 元素 2
stack.pop(); // 出栈 -> 元素 1
注意:通常情况下,不推荐使用 Java 的 Vector 以及其子类 Stack ,而一般将 LinkedList 作为栈来使用。
LinkedList<Integer> stack = new LinkedList<>();
stack.addLast(1); // 元素 1 入栈
stack.addLast(2); // 元素 2 入栈
stack.removeLast(); // 出栈 -> 元素 2
stack.removeLast(); // 出栈 -> 元素 1
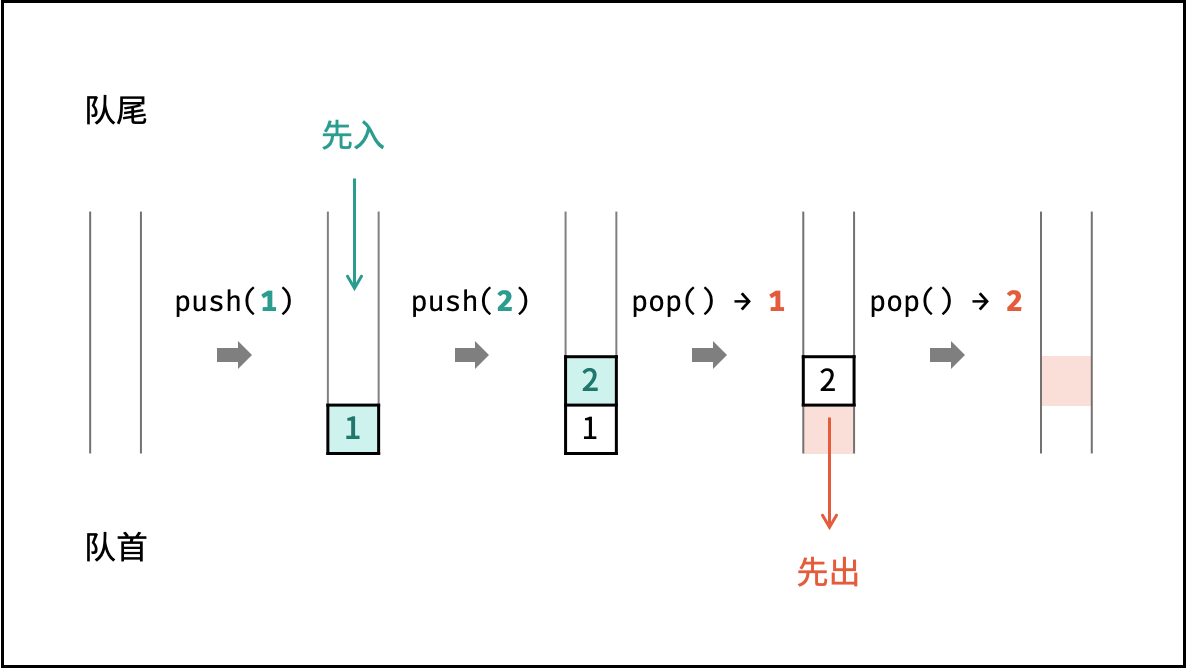
队列
队列是一种具有 「先入先出」 特点的抽象数据结构,可使用链表实现。
Queue<Integer> queue = new LinkedList<>();
如下图所示,通过常用操作 「入队 push()」,「出队 pop()」,展示了队列的先入先出特性。
queue.offer(1); // 元素 1 入队
queue.offer(2); // 元素 2 入队
queue.poll(); // 出队 -> 元素 1
queue.poll(); // 出队 -> 元素 2
树
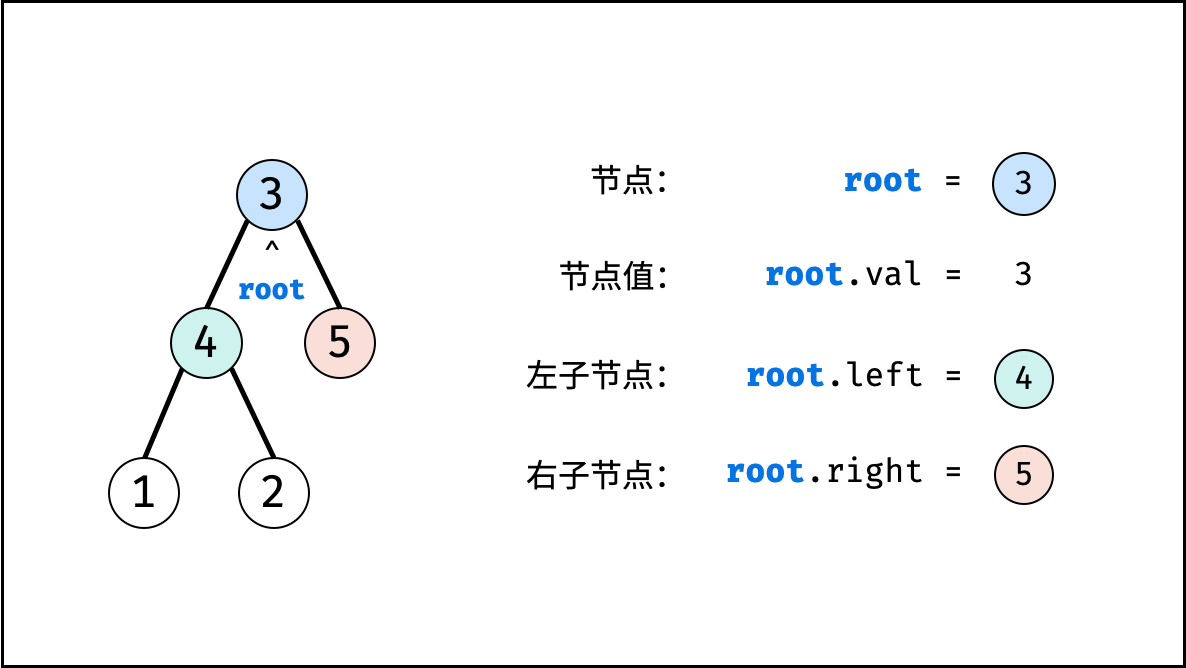
树是一种非线性数据结构,根据子节点数量可分为 「二叉树」 和 「多叉树」,最顶层的节点称为 「根节点 root」。以二叉树为例,每个节点包含三个成员变量:「值 val」、「左子节点 left」、「右子节点 right」 。
class TreeNode {
int val; // 节点值
TreeNode left; // 左子节点
TreeNode right; // 右子节点
TreeNode(int x) { val = x; }
}
如下图所示,建立此二叉树需要实例化每个节点,并构建各节点的引用指向。
// 初始化节点
TreeNode n1 = new TreeNode(3); // 根节点 root
TreeNode n2 = new TreeNode(4);
TreeNode n3 = new TreeNode(5);
TreeNode n4 = new TreeNode(1);
TreeNode n5 = new TreeNode(2);
// 构建引用指向
n1.left = n2;
n1.right = n3;
n2.left = n4;
n2.right = n5;
图
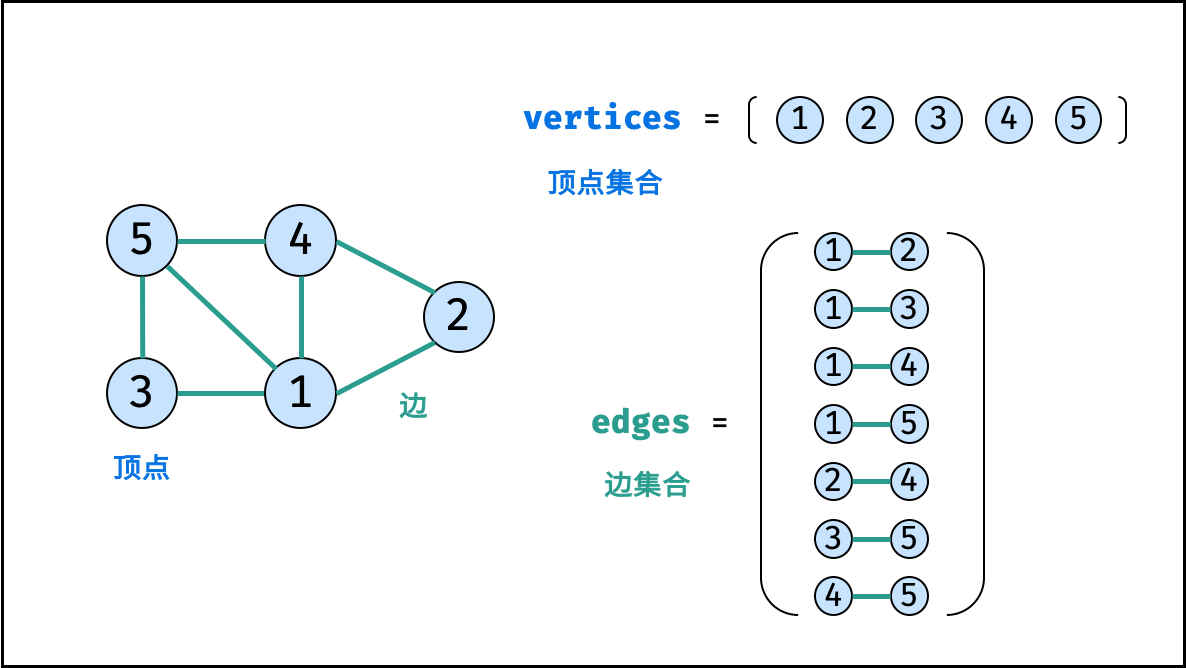
图是一种非线性数据结构,由 「节点(顶点)vertex」 和 「边 edge」 组成,每条边连接一对顶点。根据边的方向有无,图可分为 「有向图」 和 「无向图」 。
如下图所示,此无向图的 顶点 和 边 集合分别为:
- 顶点集合: vertices =
- 边集合: edges =
表示图的方法通常有两种:
1、邻接矩阵: 使用数组 verticesvertices 存储顶点,邻接矩阵 edgesedges 存储边;edges[i][j] 代表节点 i + 1和节点 j + 1之间是否有边。
int[] vertices = {1, 2, 3, 4, 5};
int[][] edges = {{0, 1, 1, 1, 1},
{1, 0, 0, 1, 0},
{1, 0, 0, 0, 1},
{1, 1, 0, 0, 1},
{1, 0, 1, 1, 0}};
2、邻接表: 使用数组vertices存储顶点,邻接表edges存储边。 edges为一个二维容器,第一维 i 代表顶点索引,第二维 edges[i] 存储此顶点对应的边集和;例如 edges[0] = [1, 2, 3, 4]代表 vertices[0]的边集合为 [1, 2, 3, 4]。
int[] vertices = {1, 2, 3, 4, 5};
List<List<Integer>> edges = new ArrayList<>();
List<Integer> edge_1 = new ArrayList<>(Arrays.asList(1, 2, 3, 4));
List<Integer> edge_2 = new ArrayList<>(Arrays.asList(0, 3));
List<Integer> edge_3 = new ArrayList<>(Arrays.asList(0, 4));
List<Integer> edge_4 = new ArrayList<>(Arrays.asList(0, 1, 4));
List<Integer> edge_5 = new ArrayList<>(Arrays.asList(0, 2, 3));
edges.add(edge_1);
edges.add(edge_2);
edges.add(edge_3);
edges.add(edge_4);
edges.add(edge_5);
邻接矩阵 VS 邻接表 :
邻接矩阵的大小只与节点数量有关,即N^2,其中N为节点数量。因此,当边数量明显少于节点数量时,使用邻接矩阵存储图会造成较大的内存浪费。因此,邻接表 适合存储稀疏图(顶点较多、边较少);邻接矩阵适合存储稠密图(顶点较少、边较多)。
散列表
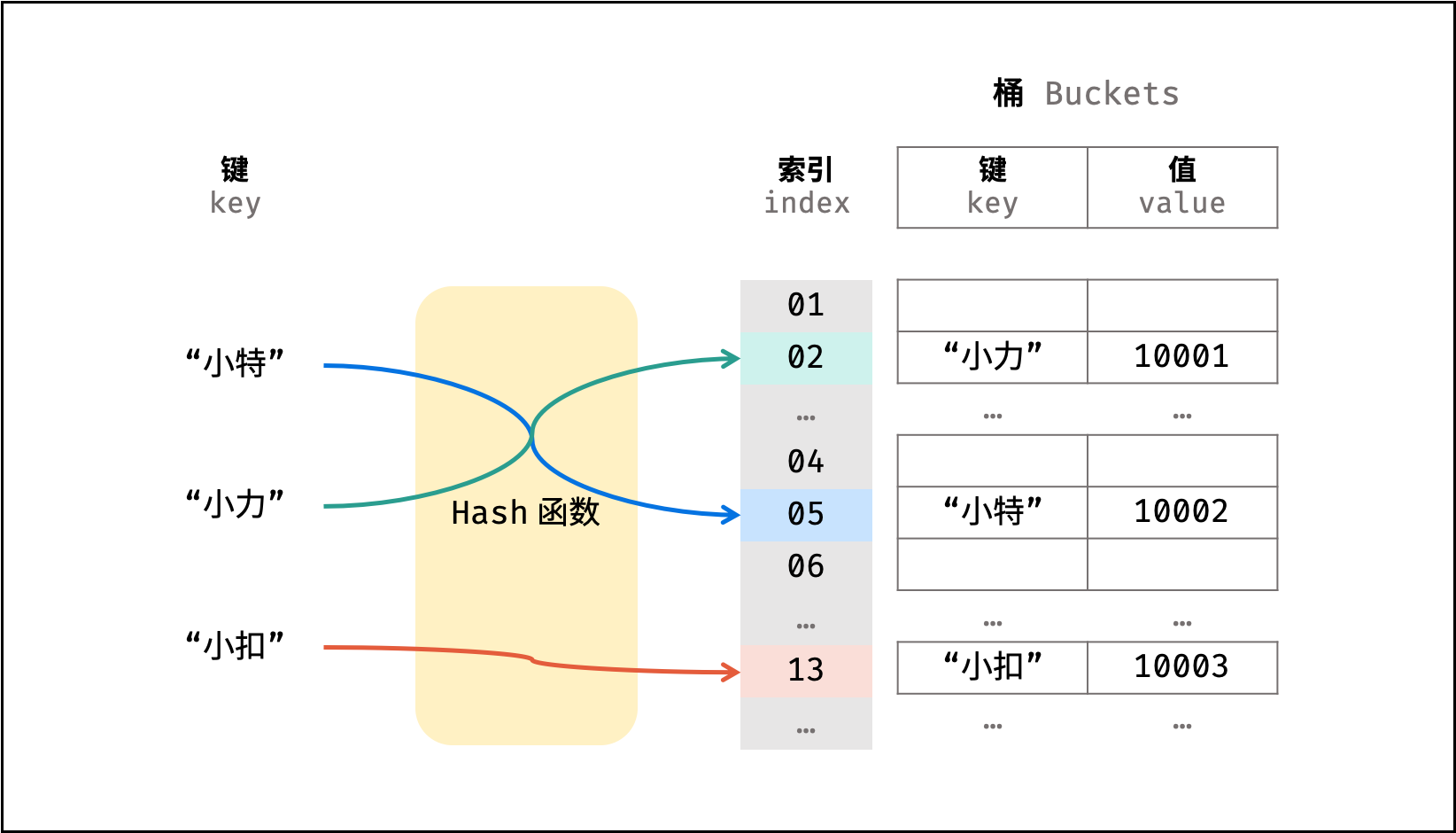
散列表是一种非线性数据结构,通过利用 Hash 函数将指定的 「键 key」 映射至对应的 「值 value」 ,以实现高效的元素查找。
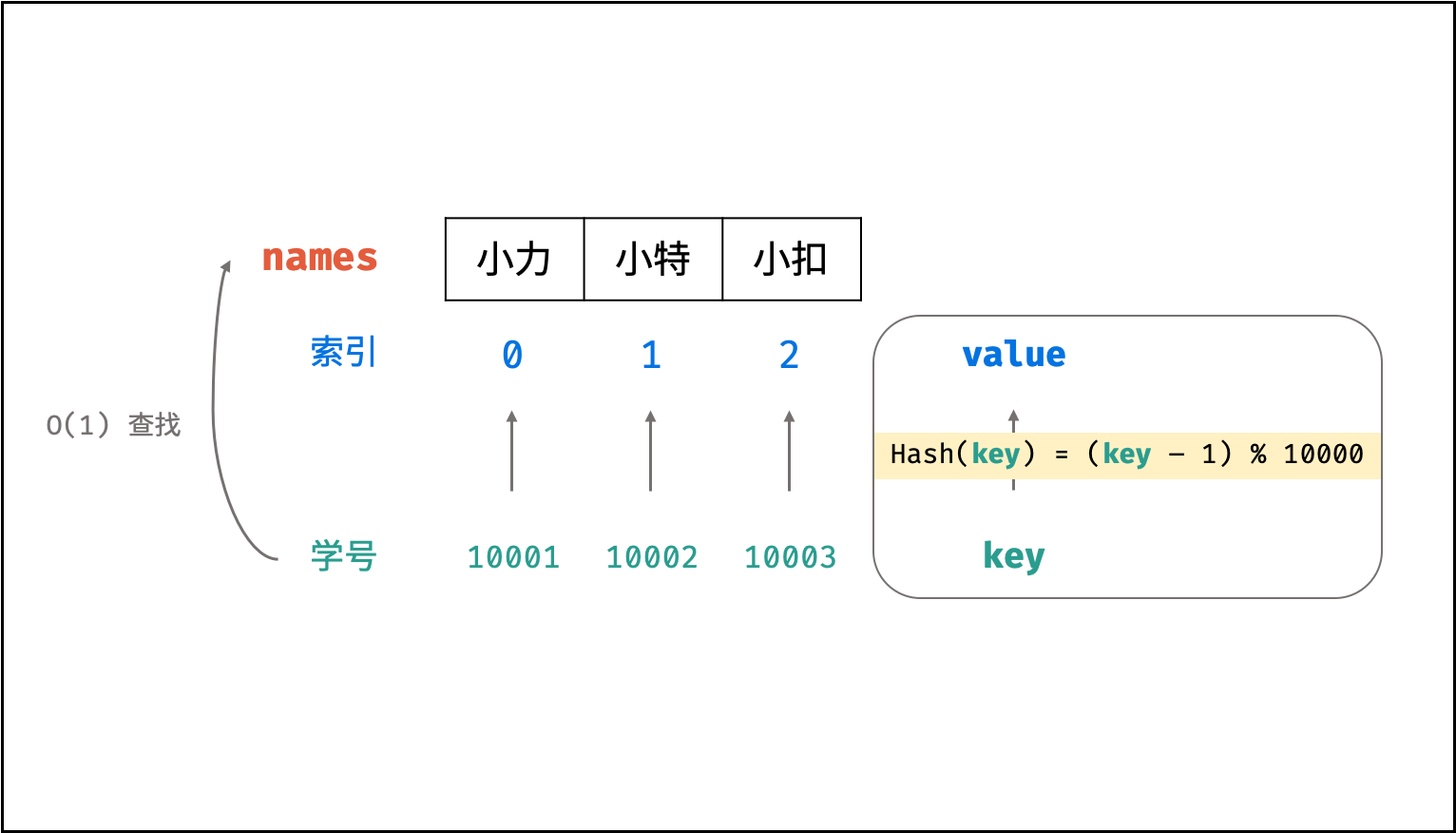
设想一个简单场景:小力、小特、小扣的学号分别为 10001, 10002, 10003 。现需求从「姓名」查找「学号」。
则可通过建立姓名为 key ,学号为 value 的散列表实现此需求,代码如下:
// 初始化散列表
Map<String, Integer> dic = new HashMap<>();
// 添加 key -> value 键值对
dic.put("小力", 10001);
dic.put("小特", 10002);
dic.put("小扣", 10003);
// 从姓名查找学号
dic.get("小力"); // -> 10001
dic.get("小特"); // -> 10002
dic.get("小扣"); // -> 10003
自行设计 Hash 函数:
假设需求:从「学号」查找「姓名」。
将三人的姓名存储至以下数组中,则各姓名在数组中的索引分别为 0, 1, 2。
String[] names = { "小力", "小特", "小扣" };
此时,我们构造一个简单的Hash函数(%为取余符号),公式和封装函数如下所示:
hash(key) = (key - 1) % 10000
int hash(int id) {
int index = (id - 1) % 10000;
return index;
}
则我们构建了以学号为 key 、姓名对应的数组索引为 value 的散列表。利用此 Hash 函数,则可在 O(1) 时间复杂度下通过学号查找到对应姓名,即:
names[hash(10001)] // 小力
names[hash(10002)] // 小特
names[hash(10003)] // 小扣
以上设计只适用于此示例,实际的 Hash 函数需保证低碰撞率、
高鲁棒性(健壮性)等,以适用于各类数据和场景。
堆
堆是一种基于 「完全二叉树」 的数据结构,可使用数组实现。以堆为原理的排序算法称为 「堆排序」 ,基于堆实现的数据结构为 「优先队列」 。堆分为 「大顶堆」 和 「小顶堆」 ,大(小)顶堆:任意节点的值不大于(小于)其父节点的值。
完全二叉树定义: 设二叉树深度为 k ,若二叉树除第 k 层外的其它各层(第 1 至 k−1 层)的节点达到最大个数,且处于第 k 层的节点都连续集中在最左边,则称此二叉树为完全二叉树。
如下图所示,为包含 1, 4, 2, 6, 8 元素的小顶堆。将堆(完全二叉树)中的结点按层编号,即可映射到右边的数组存储形式。

通过使用「优先队列」的「压入 push()」和「弹出pop()」操作,即可完成堆排序,实现代码如下:
// 初始化小顶堆
Queue<Integer> heap = new PriorityQueue<>();
// 元素入堆
heap.add(1);
heap.add(4);
heap.add(2);
heap.add(6);
heap.add(8);
// 元素出堆(从小到大)
heap.poll(); // -> 1
heap.poll(); // -> 2
heap.poll(); // -> 4
heap.poll(); // -> 6
heap.poll(); // -> 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号