


Elasticsearch集群异常状态(RED、YELLOW)分析
集群状态为什么会异常?
想知道这个,我们首先需要了解一下集群的几种状态。
Elasticsearch 集群健康状态分为三种:
- GREEN
- YELLOW
- RED
GREEN是最健康的状态,说明所有的分片包括副本都可用。这种情况Elasticsearch集群所有的主分片和副本分片都已分配,Elasticsearch集群是100%可用的。
那么,集群状态在什么情况下发生RED和YELLOW呢?
YELLOW:主分片可用,但是副本分片不可用。这种情况Elasticsearch集群所有的主分片已经分配了,但至少还有一个副本是未分配的。不会有数据丢失,所以搜索结果依然是完整的。不过,集群高可用性在某种程度上会被弱化。可以把yellow想象成一个需要关注的warnning,该情况不影响索引读写,一般会自动恢复。
RED:存在不可用的主分片。此时执行查询虽然部分数据仍然可以查到,但实际上已经影响到索引读写,需要重点关注。这种情况Elasticsearch集群至少一个主分片(以及它的全部副本)都在缺失中。这意味着索引已缺少数据,搜索只能返回部分数据,而分配到这个分片上的请求都返回异常。
查看集群状态
使用kibana开发工具,查看集群状态:
GET /_cluster/health
这里可以看到,当前集群状态为red,有9个未分配的分片
ES健康接口返回内容官方解释
|
指标 |
含义 |
|---|---|
|
cluster_name |
集群的名称 |
|
status |
集群的运行状况,基于其主要和副本分片的状态。状态为:– green所有分片均已分配。– yellow所有主分片均已分配,但未分配一个或多个副本分片。如果群集中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用。– red未分配一个或多个主分片,因此某些数据不可用。在集群启动期间,这可能会短暂发生,因为已分配了主要分片。 |
|
timed_out |
如果false响应在timeout参数指定的时间段内返回(30s默认情况下) |
|
number_of_nodes |
集群中的节点数 |
|
number_of_data_nodes |
作为专用数据节点的节点数 |
|
active_primary_shards |
活动主分区的数量 |
|
active_shards |
活动主分区和副本分区的总数 |
|
relocating_shards |
正在重定位的分片的数量 |
|
initializing_shards |
正在初始化的分片数 |
|
unassigned_shards |
未分配的分片数 |
|
delayed_unassigned_shards |
其分配因超时设置而延迟的分片数 |
|
number_of_pending_tasks |
尚未执行的集群级别更改的数量 |
|
number_of_in_flight_fetch |
未完成的访存数量 |
|
task_max_waiting_in_queue_millis |
自最早的初始化任务等待执行以来的时间(以毫秒为单位) |
|
active_shards_percent_as_number |
群集中活动碎片的比率,以百分比表示 |
问题分析
当集群状态异常时,需要重点关注unassigned_shards没有正常分配的分片,这里举例说明其中一种场景。
找到异常索引
查看索引情况,并根据返回找到状态异常的索引
GET /_cat/indices
查看详细的异常信息
GET /_cluster/allocation/explain

这里通过异常信息可以看出:
- 主分片当前处于未分配状态(
current_state),发生这个问题的原因是因为分配了该分片的节点已从集群中离开(unassigned_info.reason); - 发生了上诉问题之后,分片无法自动分配分片的原因是集群中没有该分片的可用副本(
can_allocate); - 同时也给出了更详细的信息(
allocate_explanation)
这种情况发生的原因是因为集群有节点下线,导致主分片已没有任何可用的分片数据,当前唯一能做的事就是等待节点恢复并重新加入集群。
注:某些极端场景,比如单副本集群的分片发生了损坏,或是文件系统故障导致该节点被永久移除,而此时只能接受数据丢失的事实,并通过reroute commends来重新分配空的主分片。
分片未分配(unassigned_info.reason)的所有可能
|
reason |
原因 |
|---|---|
|
INDEX_CREATED |
索引创建,由于API创建索引而未分配的 |
|
CLUSTER_RECOVERED |
集群恢复,由于整个集群恢复而未分配 |
|
INDEX_REOPENED |
索引重新打开 |
|
DANGLING_INDEX_IMPORTED |
导入危险的索引 |
|
NEW_INDEX_RESTORED |
重新恢复一个新索引 |
|
EXISTING_INDEX_RESTORED |
重新恢复一个已关闭的索引 |
|
REPLICA_ADDED |
添加副本 |
|
ALLOCATION_FAILED |
分配分片失败 |
|
NODE_LEFT |
集群中节点丢失 |
|
REROUTE_CANCELLED |
reroute命令取消 |
|
REINITIALIZED |
重新初始化 |
|
REALLOCATED_REPLICA |
重新分配副本 |
可以通过上诉分析方式初步判断集群产生未分配分片的原因,一般都可以在allocation explain api中得到想要的答案。
异常状态分析
我们已经了解了 ES 集群异常状态分为 YELLOW 和 RED。
YELLOW:主分片可用,但是副本分片不可用。这种情况 Elasticsearch 集群所有的主分片已经分配了,但至少还有一个副本是未分配的。不会有数据丢失,所以搜索结果依然是完整的。不过,集群高可用性在某种程度上会被弱化。可以把 yellow 想象成一个需要关注的 warnning,该情况不影响索引读写,一般会自动恢复。
RED:存在不可用的主分片。此时执行查询虽然部分数据仍然可以查到,但实际上已经影响到索引读写,需要重点关注。这种情况 Elasticsearch 集群至少一个主分片(以及它的全部副本)都在缺失中。这意味着索引已缺少数据,搜索只能返回部分数据,而分配到这个分片上的请求都返回异常。
本文我们将讲解集群在 YELLOW 异常状态下的处理思路,以及哪些情况下无需人工干预,哪些情况下需要人工干预。
YELLOW 异常
yellow 异常是 ES 最常见的集群异常,当负载较高时,集群往往会长时间陷入 yellow 状态无法脱离,其表现则是:
- 无需人工干预,副本分片恢复缓慢,大部分副本分片处于排队等待初始化
- 需要人工干预,副本分片无法分配
无需人工干预
场景1:写入触发索引创建(INDEX_CREATED)
ES 支持在索引不存在的情况下发起对该索引的写入,当对不存在的索引发起写入时,ES 会自动创建该索引,并开始自动映射(put-mapping)不存在的索引字段,这是个很重的操作,会对元数据造成较大压力。
尤其当有大量写入或者集群本身元数据较大时,ES 会延迟分配副本分片,进入 pending_task 队列,这则会导致集群陷入 yellow 状态。这时即便副本分片开始初始化,也会因为索引有大量写入而需要同步主分片数据,进而导致副本初始化缓慢。
整体表现就是集群长时间处于 yellow 状态,短时间无法脱离,但这种情况都会自动恢复,当副本分片初始化完成后,yellow 状态也就变为 green 了。
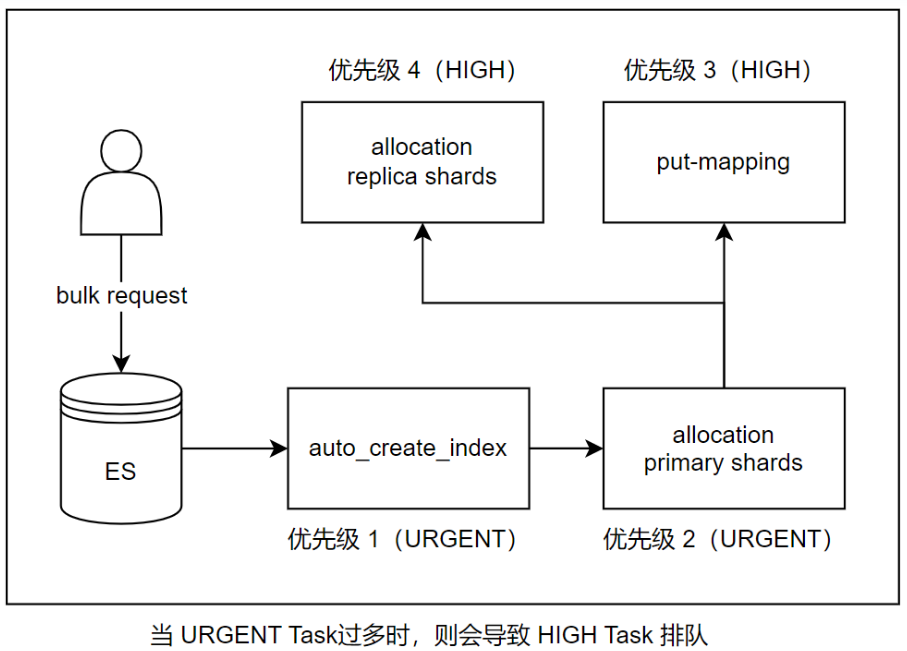
如图:当 URGENT Task过多时,则会导致 HIGH Task 排队,进入 pending 状态
优化建议:
业务提前预创建索引,而不是让 bulk request 自动触发索引创建(create-index)。
场景2:节点临时离线(NODE_LEFT)
我们假设集群当中所有索引都有冗余副本分片,且只有一个节点宕机下线,那么集群这时会进入 yellow 状态。由于索引目前还有主分片在线,对业务的使用不会造成影响。如果节点是因为短时间压力过大而导致节点脱离,则一般会自动恢复,这种情况无需人工干预:
[o.e.c.r.a.AllocationService] [1699879628011021732] failing shard [failed shard, shard [.ds-cdwch-2023.11.13-000404][23], node[vAnpreEnTaSWY-QYV3GGWg], [R], recovery_source[peer recovery], s[INITIALIZING], a[id=r48vj2pQRmauAuXKm-qX9g], unassigned_info[[reason=NODE_LEFT], at[2023-11-14T06:58:10.583Z], delayed=true, details[node_left [vAnpreEnTaSWY-QYV3GGWg]], allocation_status[no_attempt]], message [failed recovery], failure [RecoveryFailedException[[.ds-cdwch-2023.11.13-000404][23]: Recovery failed from {1675171390003468332}{QUotMJ0DRsiM442JPtqlmA}{2aWADQvMRjSKRRsFg-Abrw}{10.1.0.47}{10.1.0.47:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800007, xpack.installed=true, set=800007, transform.node=true, ip=9.15.118.138, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8} into {1670988404000091932}{vAnpreEnTaSWY-QYV3GGWg}{-vaCwjbhSpG1iGEY18Wz4A}{10.0.128.45}{10.0.128.45:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800006, xpack.installed=true, set=800006, transform.node=true, ip=9.15.104.46, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8}]; nested: RemoteTransportException[[1675171390003468332][10.1.0.47:9300][internal:index/shard/recovery/start_recovery]]; nested: ScpRecoveryIsRunningException[Another recovery task is running for same replica and node. Existing recovery: RecoveryKey{shard: [.ds-cdwch-