

flink调优之压测任务的合理并行度
压测合理并行度的方法:
①获得高峰期的qps,如每秒5w条
②消费该高峰期的数据,达到反压状态后查看每秒处理的数据量y,就是单并行度的处理上限
③x除以y,增加一点富余: 乘以1.2,就是合理的并行度。
在flink中,设置并行度的地方有:
①配置文件 ②提交任务时的参数 ③代码env ④代码算子
案例:
提交一个flink程序,内容是计算uv,设置并行度为5
测试时记得关闭chain来看到每一个算子的情况 : env.disableOperatorChaining();
在flink ui界面查看整个DAG图,看到明显产生了反压情况(数据处理速度达到100%)

接着查看source的情况:
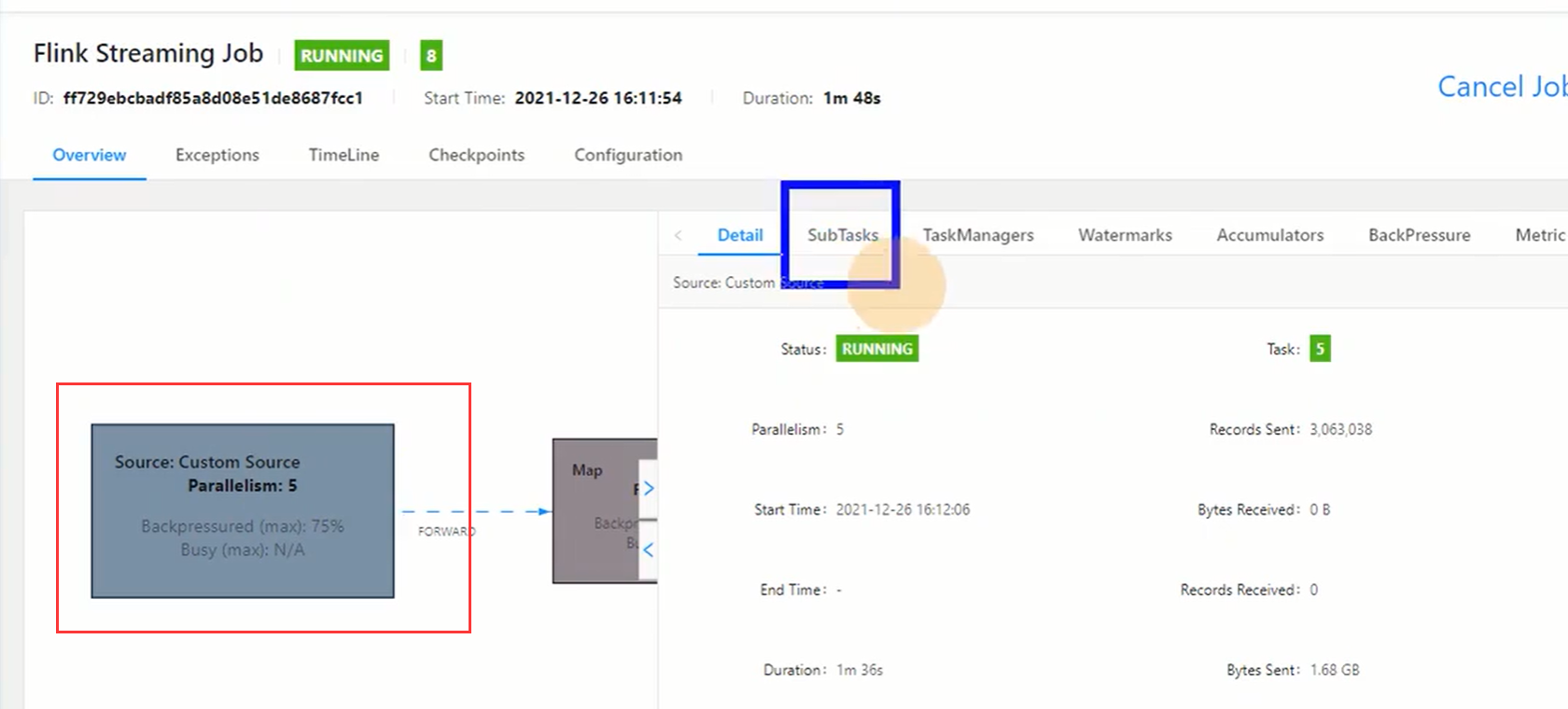
点击subtask,因为并行度是5,可以看到5个task(ID为0-4)的数据接收量和发送量(流量大小和条数),因为是source端,所以接收都是0 。
从下图看到ID为0的task发送量已经达到了35MB,共有62w条。这是总共的,我们要查看每秒的量

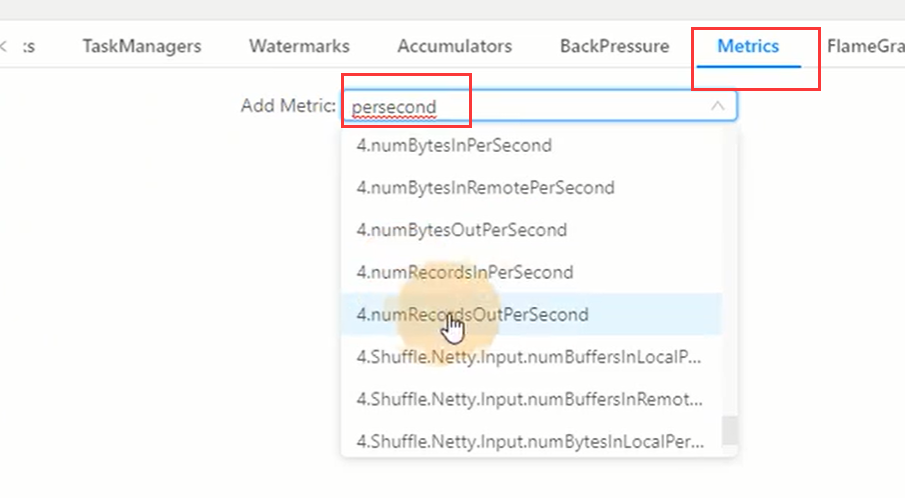
打开metric输入persecond搜索:
从下图中我们可以看到ID为4的子任务每秒发送的量在7000+
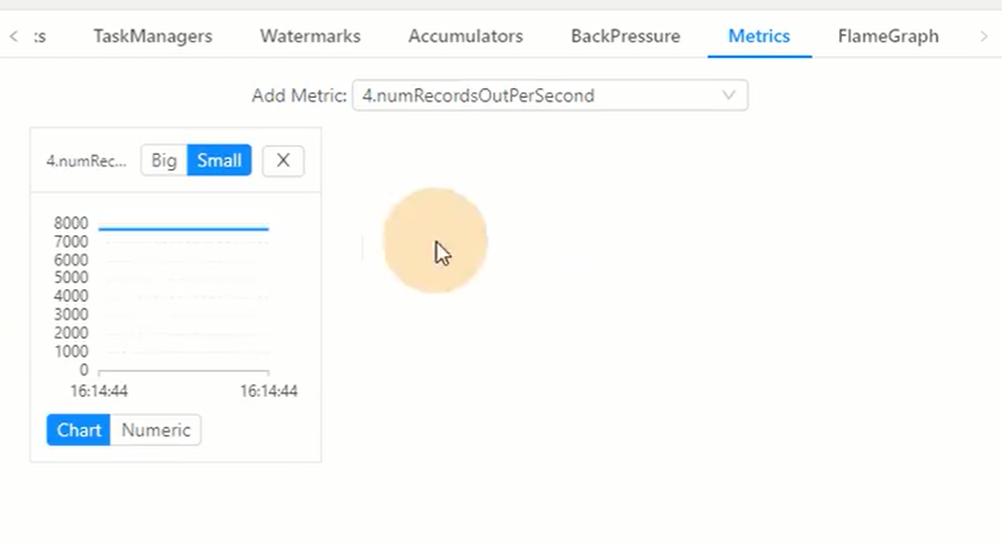
可以看到几个task的发送量都差不多,由此可见单并行度的处理能力为7000条,假设该业务高峰期时每秒产生的数据量(qps)为7w,
所以7/0.7*1.2, 该业务合理的并行度为12

并行度的推荐配置
- source端
数据源端是kafka,source的并行度设置为kafka对应topic的分区数。
如果已经等于kafka的分区数,消费速度仍更不上数据生产速度,考虑下kafka要扩大分区,同时调大并行度等于分区数。
flink的一个并行度可以处理一至多个分区的数据,如果并行度多于kafka的分区数,那么就会造成有的并行度空闲,浪费资源
- Transform端
第一次keyby之前的算子,比如map、fliter、flatmap等处理较快的算子,并行度和source保持一致即可。
第一次keyby之后的算子,视具体情况而定,可以通过上面测试反压的方法,得到keyby算子上游的数据发送量和该算子的处理能力来得到合理的并行度(在无倾斜情况下)
- sink端
sink端是数据流向下游的地方,可以根据sink端的数据量及下游的服务抗压能力进行评估。
如果sink端是kafka,可以设为kafka对应topic的分区数。
sink端的数据量若比较小,比如一些高度聚合或者过滤比较大的数据(比如监控告警),可以将并行度设置的小一些。
如果source端的数据量最小,拿到source端流过来的数据后做了细粒度的拆分,数据量不断的增加,到sink端的数据量非常大的这种情况,就需要提高并行度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号