

转 Python多版本管理-pyenv (pandas)
#######for linux
https://www.cnblogs.com/saneri/p/7642316.html
经常遇到这样的情况:
系统自带的Python是2.x,自己需要Python 3.x,此时需要在系统中安装多个Python,但又不能影响系统自带的Python,即需要实现Python的多版本共存,pyenv就是这样一个Python版本管理器。
1.安装pyenv:

1.>安装依赖包:
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel -y
2.>安装pyenv包:
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
3.>设置环境变量:
#vim ~/.bashrc
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
#source ~/.bashrc
#即是启动语句,重启系统执行这条语句
exec $SHELL
2.查看pyenv支持的python版本,同时也是检验有没有安装成功:
|
1
|
pyenv install --list |
3.查看当前pyenv可检测到的所有版本,处于激活状态的版本前以 * 标示.
|
1
2
3
4
|
[root@localhost ~]# pyenv versions system 3.5.1* 3.5.3 (set by /root/.pyenv/version) |
4.查看当前处于激活状态的版本,括号中内容表示这个版本是由哪条途径激活的(global、local、shell)
|
1
2
|
[root@localhost ~]# pyenv version 3.5.3 (set by /root/.pyenv/version) |
5.将3.5.1作为全局变量,使用如下命令.
|
1
2
3
|
[root@localhost ~]# pyenv global 3.5.1[root@localhost ~]# pyenv version3.5.1 (set by /root/.pyenv/version) |
6.设置面向程序的本地版本,通过将版本号写入当前目录下的.python-version 文件的方式。
#在本地创建目录ops,执行pyenv local 3.5.3后,只有在这个目录是3.5.3的版本,别的目录使用默认的版本.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@localhost ~]# python -VPython 3.5.1[root@localhost ~]# pyenv versions system* 3.5.1 (set by /root/.pyenv/version) 3.5.3[root@localhost ~]#[root@localhost ~]# mkdir ops[root@localhost ~]# cd ops/[root@localhost ops]# pyenv local 3.5.3[root@localhost ops]# python -VPython 3.5.3[root@localhost ops]# cd ..[root@localhost ~]# python -VPython 3.5.1 |
7.安装你需要的Python版本(如3.4.0):
|
1
2
3
|
pyenv install 3.4.0 -v#小技巧,可以在/root/.pyenv/目录下创建cache目录,将下载好的Python-3.4.0的包放在该目录下,就可以直接执行安装,而不需要下载,节省下载时间. |
8.安装完成之后需要对数据库进行更新:
|
1
|
pyenv rehash |
9.卸载python 3.4.0版本.
|
1
|
pyenv uninstall 3.4.0 |
参考文档:
http://www.jianshu.com/p/a23448208d9a
http://www.360doc.com/content/16/0821/11/35455208_584738668.shtml
http://www.linuxidc.com/Linux/2017-02/140201.htm
#####for windows python2 和python3:
https://blog.csdn.net/dream_an/article/details/51248736
0.0 因为公司项目,需要Python两个版本共存开发,一个2.7x用来处理空间数据主要配合ArcGIS,而另一个3.5x用来做算法应用。因此就必须在计算机中共存2.7x和3.5x版本的。这次解决共存后记录下来过程,分享给大家。
1.0 下载Python2.7x和Python3.5x版本
2.0 安装Python2.7x和Python3.5x版本
很简单,直接点击安装,注意安装位置,我的安装位置为E:\IDES\Python27\和E:\IDES\Python35
3.0 配置环境变量,分别添加如下至path路径(我的计算机是Windows10系统)
E:\IDES\Python35
E:\IDES\Python35\Scripts
E:\IDES\Python27
E:\IDES\Python27\Scripts
1
2
3
4
4.0 只修改Python27(E:\IDES\Python27)文件中的.exe文件(这样系统默认为Python3.5)
将python.exe修改为python2.exe
5.0 如何在cmd中分别调用Python2.7和Python3.5
5.1 输入Python2 可调用Python2.7版本
5.2输入Python 可调用Python3.5版本
6.0 使用pip安装科学栈如numpy、pandas等
6.1 为Python2.7版本安装科学栈
查看已安装科学栈情况和版本
python2 -m pip list 查看
python2 -m pip install --upgrade pip 更新
python2 -m pip install numpy 安装
1
2
3
6.2 为Python3.5版本安装科学栈
查看已安装科学栈情况和版本
pip list
pip install --upgrade pip
pip install numpy
1
2
3
6.3 如果想通过pip安装其他科学栈如pymssql simpleitk mysqlclient bottleneck nitime bazaar mkl-service yt等到
送上科学栈镜像网址,这里有可安装的二进制科学栈文件以及依赖(就是安装某个科学栈之前必须先安装哪些)说明。
(https://www.lfd.uci.edu/~gohlke/pythonlibs/)
6.4 也可参考我另一个学习笔记Python数据科学安装Numby,pandas,scipy,matpotlib等(IPython安装pandas)
Windows下Python多版本共存
Python数据科学安装Numby,pandas,scipy,matpotlib等(IPython安装pandas)
---------------------
作者:王小雷-多面手
来源:CSDN
############windowss pycharm
pycharm当中,如何导入python2或者python3环境
https://blog.csdn.net/u010801439/article/details/78460962
- step 1
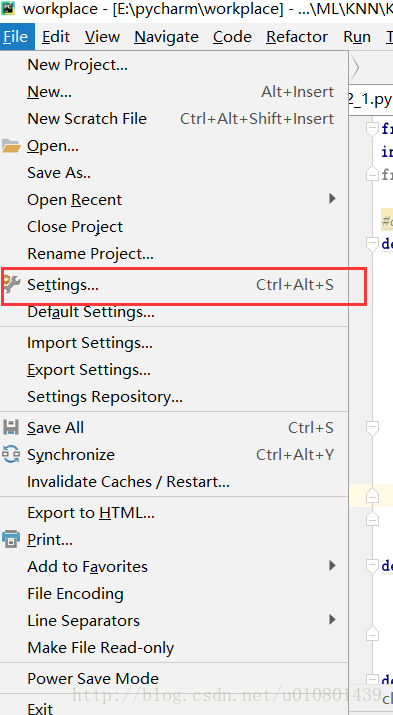
- step 2
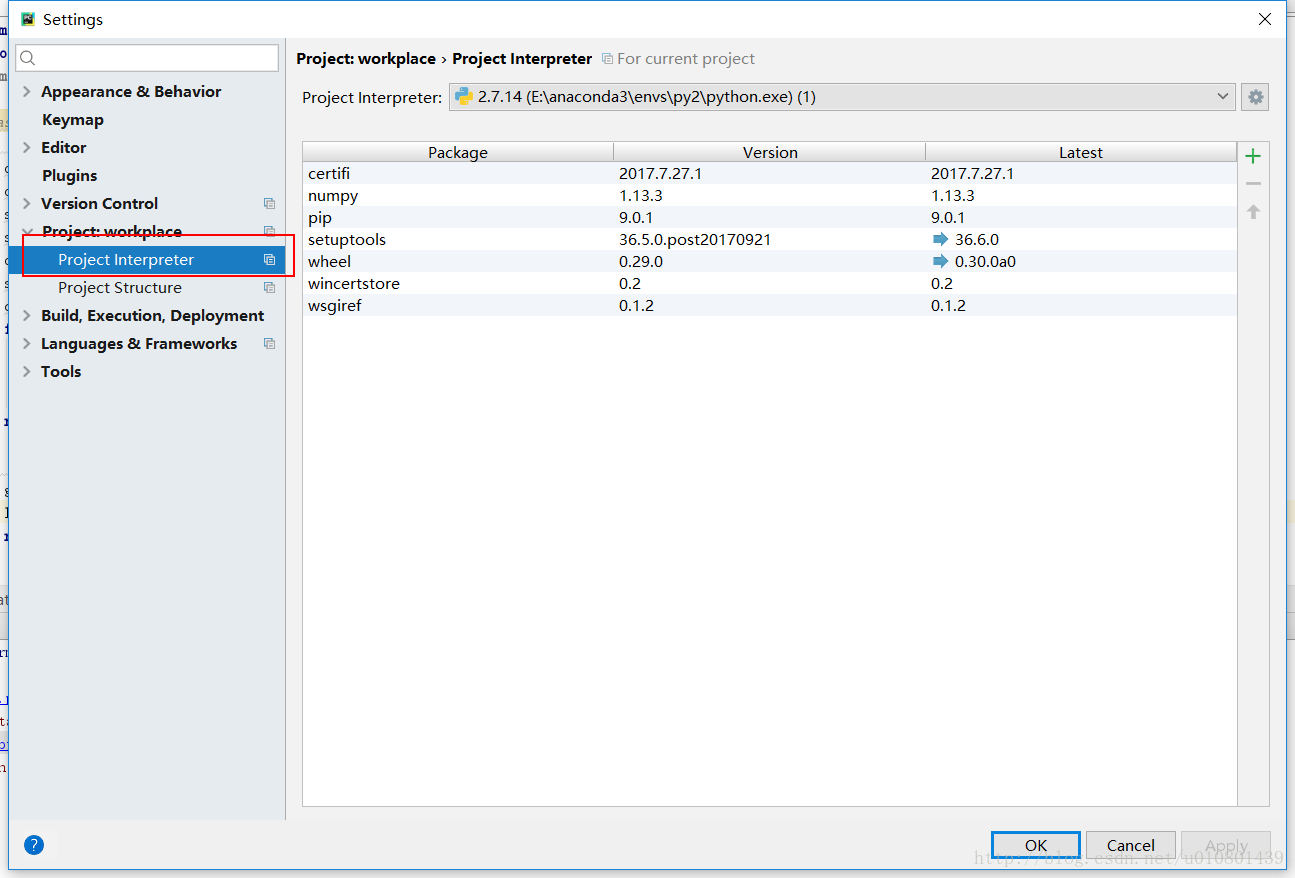
- step 3
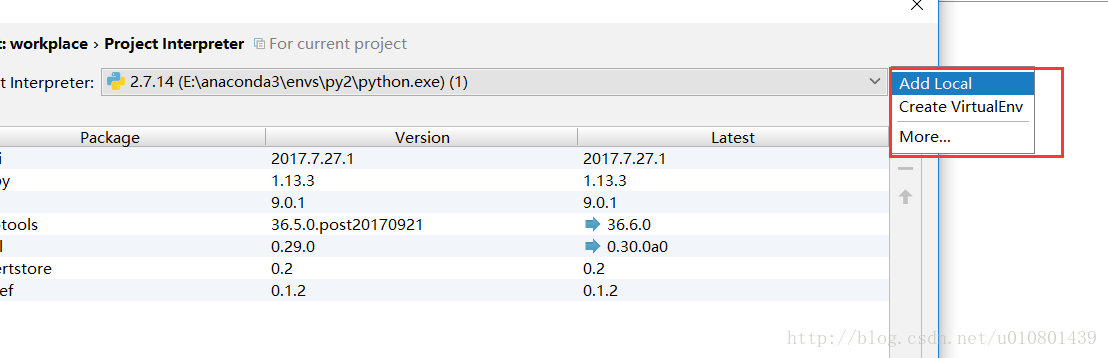
OK ,环境添加完毕,此环境为python 2.7.17(python 3可按此步骤添加),如此一来,我们可以灵活的再此处切换所有的编译环境。
###pandas
#######1 https://www.learnfk.com/question/python/74847574.html
Python 通过 pandas 读取后,逐行打印 csv
我会建议你使用Pandas 和迭代器
复制代码
import pandas as pd
df = pd.read_csv("file.csv")
# iterate over the rows of the DataFrame
for index, row in df.iterrows():
print(row['column_name'])
##########22 https://www.itguest.com/post/abccaj1a1.html
如果您只想查看列名,可以这样做:
print(df.columns.tolist())
############## python 将后台 print的方法输入文件
新手应知应会:python程序运行结果如何输出到文件
方法一:命令行
在Python编程中,如果想把程序的所有输出都放到一个文件中,可以使用命令行中的重定向运算符>。例如,如果你的Python程序叫做my_program.py,你想把它的输出重定向到一个名为output.txt的文件中,你可以运行以下命令:
python my_program.py > output.txt
这将运行程序并将所有输出从控制台重定向到文件output.txt中。如果该文件不存在,它将被创建。如果它已经存在,输出将被追加到文件末尾。
方法二:内置函数
你也可以修改你的Python程序,直接使用Python的内置文件I/O函数将其输出写入到文件中。例如:
with open('output.txt', 'w') as f:
print('Hello, world!', file=f)
这将以写入模式打开文件output.txt,并将字符串'Hello, world!'打印到文件中。如果该文件不存在,它将被创建。如果它已经存在,它的内容将被覆盖。
方法三:第三方库
第三种方法是使用第三方库来保存Python的输出为txt。其中一个常用的库是numpy,它提供了numpy.savetxt()函数,用于将数组保存为txt文件。以下是实现该方法的步骤:
步骤1:安装第三方库。使用pip命令安装numpy库:
pip install numpy
步骤2:导入库。在Python脚本中导入numpy库:
import numpy as np
步骤3:将输出保存为txt。使用numpy.savetxt()函数将输出保存为txt文件。例如,下面的代码将一个包含两行三列数据的二维数组保存为txt文件:
data = np.array([[1, 2, 3], [4, 5, 6]])
np.savetxt('output.txt', data)
完整的代码示例:
import numpy as np
data = np.array([[1, 2, 3], [4, 5, 6]])
np.savetxt('output.txt', data)
通过以上代码,输出将保存为名为output.txt的txt文件。
方法四:使用标准输出重定向
第四种方法是使用Python的标准输出重定向功能,将输出保存为txt文件。以下是实现该方法的步骤:
步骤1:导入sys库。在Python脚本中导入sys库:
import sys
步骤2:重定向标准输出。使用sys.stdout将标准输出重定向到txt文件。例如,下面的代码将输出重定向到名为output.txt的txt文件:
sys.stdout = open('output.txt', 'w')
步骤3:打印输出。直接使用print()函数进行输出,输出将被重定向到指定的txt文件中。例如,下面的代码将字符串Hello, World!输出到txt文件:
print('Hello, World!')
步骤4:恢复标准输出。在完成输出后,需要将标准输出恢复到原来的状态:
sys.stdout.close()
sys.stdout = sys.__stdout__
完整的代码示例:
import sys
sys.stdout = open('output.txt', 'w')
print('Hello, World!')
sys.stdout.close()
sys.stdout = sys.__stdout__
通过以上代码,输出将保存为名为output.txt的txt文件。
综上所述,我们介绍了四种常用的方法将Python的输出保存为txt文件,包括使用命令行、内置函数、第三方库以及标准输出重定向。根据实际需求选择适合的方法,即可轻松实现输出保存为txt的功能。
————————————————
版权声明:本文为CSDN博主「天 禾」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/2201_75593109/article/details/132587448
###pandas 使用方法
https://www.jb51.net/article/254075.htm
Python Pandas中loc和iloc函数的基本用法示例
1 loc和iloc的含义
loc表示location的意思;iloc中的loc意思相同,前面的i表示integer,所以它只接受整数作为参数。
2 用法
|
1
2
3
4
5
|
import pandas as pdimport numpy as np# np.random.randn(5, 2)表示返回5x2的矩阵,index表示行的编号,columns表示列的编号df = pd.DataFrame(np.random.randn(5, 2), index=range(0, 5, 1), columns=list('AB'))print(df) |
打印df的结果:

2.1 loc函数的用法
loc表示通过标签取数据,标签就是上面的‘0’-‘4’和‘A’-‘B’。
|
1
|
print(df.loc[0]) |

|
1
|
print(df.loc[0, :]) |

|
1
|
print(df.loc[0:2, 'A']) |

2.2 iloc函数的用法
iloc函数表示通过位置取数据,即第m行,第n列数据,只接受整型参数。记住:0:2为“包左不包右”,即取0, 1。
|
1
|
print(df.iloc[0, :]) |

|
1
|
print(df.iloc[:, 0]) |

|
1
|
print(df.iloc[0:2, :]) |

补充:Pandas中loc和iloc函数实例
利用loc、iloc提取行数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import numpy as npimport pandas as pd#创建一个Dataframedata=pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('ABCD')) In[1]: dataOut[1]: A B C Da 0 1 2 3b 4 5 6 7c 8 9 10 11d 12 13 14 15 #取索引为'a'的行In[2]: data.loc['a']Out[2]:A 0B 1C 2D 3 #取第一行数据,索引为'a'的行就是第一行,所以结果相同In[3]: data.iloc[0]Out[3]:A 0B 1C 2D 3 |
loc函数:通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据)
利用loc、iloc提取列数据
取'500到600行,多取几列格式['trade_date','ps'
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
In[4]:data.loc[:,['A']] #取'A'列所有行,多取几列格式为 data.loc[:,['A','B']]Out[4]: Aa 0b 4c 8d 12 In[5]:data.iloc[:,[0]] #取第0列所有行,多取几列格式为 data.iloc[:,[0,1]]Out[5]: Aa 0b 4c 8d 12 |
总结
到此这篇关于Python Pandas中loc和iloc函数的基本用法的文章就介绍到这了,更多相关Pandas loc和iloc函数用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号