

python3常用函数
学习步骤:数据类型 》 数据类型函数 》控制流程语句 》类和对象 》标准库 》 网络爬虫
定义:
Python 是强类型的动态脚本语言(php是弱类型动态脚本语言,java是强类型静态编译型语言)。
1、强类型是指,一个变量被指定了数据类型,如果不经过强制转换,那么就一直是这个数据类型,不允许不同类型相加。
2、动态是指,不使用显示的数据类型声明,在运行期间才去确定数据的类型(第一次赋值时动态判断),这与静态类型(比如java)相反。
3、脚本是指,运行只需要一个解释器,不需要编译,脚本属于解释性语言一种。
常识:
1、python使用缩进来表示代码块,而不使用 {} ,同一个代码块的语句,保持相同的缩进空格数,否则会运行错误。
2、单行注释 # 号,多行注释用 ''' (三个单引号)和 """(三个双引号)。
3、一行中,使用多条语句,语句之间使用分号分割,只有一条语句,则不需要加分号。
4、将整个模块导入: import module;从模块中只导入某个函数: from module import function;
变量:
1、定义变量时,直接写变量名,系统自动判断类型,不用声明类型,不用加$。
2、Python3 中有六个标准的数据类型:
1)、不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
2)、可变数据(3 个):List(列表)、Dictionary(字典或映射)、Set(集合)。
3)、数字有四种类型:int (整数)、bool (布尔)、float (浮点数)、complex (复数)。
数字:
1)、Python3 的整型不限制大小,Python3废弃了 python2 中的 Long,新增了bool,bool 是 int 的子类,True=1、False=0;在 Python2 中用数字 0 表示 False,用 1 表示 True;
2)、数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数;比如:2 / 4 = 0.5 ; 2 // 4 = 0;
数字函数:
#数学函数, 导入 math 模块:import math
round(70.23) #四舍五入,输出70
round(70.236, 2) #四舍五入,输出70.24
ceil(4.1) #向上取整,输出 5
floor(4.7) #向下取整,输出 4
#随机数,导入 random 模块:import random
randint(0,10) #产生 1 到 10 的一个整数型随机数
random() #生成 0-1之间(0<=n<1)的实数
uniform( min, max) #生成min-max之间(min<=n<max)的实数,比如:round( random.uniform(5, 10) ) 生成5-10之间的整数;
random.choice( 序列) #从序列中随机返回一个元素,序列可以是列表、元组、字符串;
数字和字符串转换:
int(a); float(a) ;str(a) #a为数字或字符串,注意这不是强制转化,int、float、str是类,这是用类的构造;
字符串:
1、Python 中单引号 ' 和双引号 " 使用完全相同,反斜杠可以用来转义,比如\n,使用 r 可以让反斜杠不发生转义。
2、使用三引号(''' 或 """)可以指定一个多行字符串。
3、字符串可以用 + 运算符连接在一起,用 * 运算符重复。
4、Python 中的字符串不能改变,比如str[0] = 'a'会导致错误。
5、Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
字符串的截取:
语法:变量[头下标:尾下标:步长]: str='123456789' 或者 str = [ 'aa', 11 , 2.12, 'bb']; print(str) # 输出字符串 print(str[0:-1]) # 输出第一个到倒数第二个的所有字符 print(str[0]) # 输出字符串第一个字符 print(str[2:5]) # 输出从第三个开始到第五个的字符 print(str[2:]) # 输出从第三个开始后的所有字符 print(str[1:5:2]) # 输出从第二个开始到第五个且每隔一个的字符(步长为2) print(str * 2) # 输出字符串两次 print(str + '你好') # 连接字符串
print("%s age is %d" % ('jack', 20)) #多于一个时候,格式化输出字符串:print(字符串 % 元组)
str = " {} age is {1},height is {2:.2f}, weight is {3:10d}".format('jack', 20, 170.1723, 150 ) #语法:"……{数字:格式化标识符}……":字符串.format(元素1,元素2),{}中的数字对应format的元素位置,也可省略
if( "aa" in str) #成员运算符in,判断字符串是否包含给定的字符
if( "aa" not in str) #成员运算符 not in,判断字符串是否不包含给定的字符
列表的截取 与字符串的操作一样!
如果str=[ 'aa', 11 , 2.12, 'bb'],上面的操作同样适用,与字符串不一样的是,列表中的元素能改变!比如:str[0]=9
字符串的方法:
len( str ) #字符串长度
str.upper() # 将字符串的首字母变大写
str.lower() # 将字符串的首字母变小写
str.strip() #删除字符串头尾指定的字符(不带参数,默认为空白符,例如:/n, /r, /t, ' '),str.lstrip( "a" )为左删除,str.rstrip( " " )为右删除;
str.find("hello"); #字符串查找,找到返回位置,否则返回-1,语法:str.find(字符串, 查找开始位置=0, 查找结束位置=末尾)
str.replace( "old", "new",) #字符串替换,语法:str.replace( 旧字符串, 新字符串 );
str.isalnum() #是否由字母和数字组成
str.isdigit() #是否只由数字组成
str.split("-") #把字符串分隔符为列表;
"-".join( list ) #把序列中的元素 以指定的字符 拼接为一个字符串
列表List:常用,List中元素的类型可以不相同。
定义:
list = ['aaa', 'bbb', 111, 222, 3.33] #中括号包裹
list = [ ['aaa', 'bbb'], [111, 222], 3.33] #列表嵌套
列表的操作:
len( list ) #列表长度
list.append( 'ccc' ) #追加
list.insert(1, 'ccc' ) #插入
list.pop(); list.pop(5); #按索引移除元素,并返回该元素,如果不传参,则移除最后一个元素,即出栈;
list.remove(obj) #找到某个元素,并删除,无返回值;
del list[2] #删除
list.index('aaa') #查找元素,如果找不到则报错,解决方法是,在查找前先判断是否存在:if 'aaa' in list:list.index('aaa')
list + list #列表拼接,相加
list1 = list.copy() #复制一个副本,跟=区别是:使用=赋值,是引用赋值,更改一个,另一个同样会变;
operator.eq( list1 , list2 ) #列表比较是否相等,导入 operator 模块:import operator;
list.clear() #清空
list.reverse() #反转列表中元素,相对于:list[-1::-1]
list.sort(); #降序 list.sort(reverse=True) #升序,一般对同类型的字符和数字排序
random.shuffle( list ) #打乱列表顺序
max( list ) #返回列表中的最大值
min( list ) #返回列表中的最小值
#判断元素是否存在于列表中
if 3 in list:
print(“exists”)
#遍历
for x in list :
print(x)
列表推导式:[ 表达式 for 变量 in 序列 if 条件 ]
names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] new_names = [ name.upper() for name in names if len(name)>3 ] #根据某一个列表,生成新的列表,其中,if条件可以忽略 print( new_names ) #输出:['ALICE', 'JERRY', 'WENDY', 'SMITH']
元组Tuple:与列表操作一样,但元组的元素不能修改,字符串是一种特殊的元组,不常用。
定义:
tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 ) #小括号包裹
tup1 = () # 空元组
tup2 = (20,) # 只含一个元素,需要在元素后加逗号
集合Set:存放不能重复的数据,常被用于过滤重复,不常用。
定义:
set = {'aaa', 'bbb', 'ccc', 'ddd', 'eee'}
set = set() #创建空集合
映射(字典、Dictionary):常用,键是不可变类型,可以用数字,字符串或元组
定义:
map = {'key1': 1111, 'key2':"aaaa", ‘key3’: 'bbbb'}
map = {} #创建空字典
map = dict() #创建空字典,创建字典另一种方法,是使用内建函数dict()
方法:
len(map) #长度
str(map) #把字典转换为字符串
map["key"] #返回键的值,如果键不在,则报错;
map.get("key"); map.get("key","null"); #返回键的值,如果键不在,则返回默认值None, 默认值可以设置;
map.pop("key1"); map.pop("key1",None); #返回键的值,并删除,当键不存在时,如果没有默认值,会报错;
del map['key1'] #删除键值
del map #删除字典
map.clear() #清空字典
map.update(map) #字典拼接,相同的键会被替换
map.copy() #字典的浅拷贝,跟=区别是:使用=赋值,是引用赋值,更改一个,另一个同样会变;
map.keys() #获取所有键,返回为视图对象,可以 list( map.keys() ) 转换为列表
map.values() # 获取所有值
map.items() #获取所有键值对
#判断
if "key" in map: #in 操作符,判断键是否存在,not in 操作符刚好相反;
#遍历
for key,value in map.items():
print(key,":",value)
映射推导式:[ 键表达式:值表达式 for 变量 in 序列 if 条件 ]
list = ['Google','Runoob', 'Taobao'] map = { item:len(item) for item in list } #利用列表生成映射,其中,if条件可以忽略 print( map ) #输出{'Google': 6, 'Runoob': 6, 'Taobao': 6}
流程控制语句:
1、python中用 or、and、not 表示 或、且、非
2、for、while循环外,可以有else
3、函数的参数传递时,如果是可变类型:列表,字典,函数内部修改其自身,比如list[0]=1,函数外他们也跟着改变;如果是重新赋值,比如list=[1,3],则无影响;
if x > 0:
print("x>0")
elif x == 0:
print("x=0")
else:
print("x<0")
for i in range(5):
print(i)
while x >0:
print("x>0")
#自定义函数:
语法:def 函数名:函数体
c = 0;
def sum(a, b=0) : #b=0为默认参数
"这个位置写函数说明" #调用sum.__doc__可显示;
global c; #global引用全局变量;
return a+b
#匿名函数:只有一行的表达式,而非代码块,使用 lambda 来创建;
sum = lambda a, b: a+ b
类和对象:
1、类的方法跟普通函数区别是,第一个参数必须为自身实例,一般叫self,名字不固定。
2、用@classmethod标注的为类方法,用@staticmethod标注的为静态方法,都能被类和对象调用,区别是类方法有cls,可调用类成员(cls只能获得类变量初始化的值,不能获得new以后赋的值),而静态方法不能调用类成员;
class People: name = "" # 公有变量,外部可直接访问 __age = 0 #私有变量,俩个下划线开头 def __init__(self, name,age): #__init__是构造函数, self.name = name self.__age = age def show(self): ## 普通方法,对象调用 print(self.name) def __setAge(self, age): #私有方法,内部调用,俩个下划线开头 self.__age = age @classmethod #类方法,对象和类均能调用,cls是class的缩写,代表的是类,而不是对象self def getAge(cls): return cls.__age @staticmethod #静态方法,没有self或cls,对象和类均能调用 def fun(): print("fun") class Student( People ): #类的继承,可以多继承 weight = 0 def __init__( self, name, age, weight ): People.__init__(self, name, age) #调用父类构造 self.weight = weight def show(self): #重写父类的方法 print("name={} age={} weight={}".format( self.name, self.getAge(), self.weight) ) p = People("jack", 20) # 实例化类,不需要用"new" p.show() s = Student("tom",22,170) #实例化 s.show()
模块:
定义:一个包含自定义的函数和变量的文件,其后缀名是.py
导入全部:import 文件名1,文件名2
导入部分:from 文件名 import 函数名,变量名
包定义:把模块分类保存在不同的文件夹中,每个文件夹都包含__init__.py(一个空文件,告诉 Python 该目录是一个 Python 包),此时可以通过import path1.path2.path3的形式导入模块。
导入包全部:from 文件名.文件名.文件名 as model #使用as简化
导入包部分:from 文件名.文件名.文件名 import 函数名,变量名
m.py文件: str1 = "aa" def test(): print("bb") test01.py文件: #导入全部 import m m.test() print(m.str) test02.py文件: #导入部分 import str1,test from m test() print(str)
标准库、常用库:
import os #操作系统相关联的函数
import shutil #日常的文件和目录管理
import glob #用于从目录通配符搜索中生成文件列表
import sys #命令行输入、输出、参数
import re #正则表达式工具
import math #数学运算
import random #随机数
import urllib #访问网络
import requests #访问网络,更简洁
import time #时间
import calendar #年历和月历
import datetime #日期
import zlib #打包、压缩
import json #json
import threading #多线程
import smtplib #发送邮件
第三方库: 更多 参考1 参考2
import pymongo #MongoDB库
主流web框架:Django、Flask、Tornado
时间模块:import time
time() #当前时间戳
localtime(); localtime(时间戳) #返回时间信息的元组,包含年月日时分秒,默认为当前时间;
strftime("%Y-%m-%d %H:%M:%S", localtime() ) #返回格式化日期:2022-09-20 11:45:39
sleep( 秒数 ) #休眠几秒
正则表达式:import re
匹配标识:re.I:忽略大小写;re.M:匹配多行;re.S:使 . 匹配包括换行在内的所有字符;
search( r"\d+", "abc123ABC" , re.M|re.I) #返回第一个成功的【匹配对象】,否则返回None,通常用于判断(是否存在),语法:search(正则, 字符串, 标识);
match( r"\d+", "abc123ABC" , re.M|re.I) #同上,不同点是,必须起始位置能够匹配,否则返回None,不常用;
findall( r"\d+", "abc123ABC" , re.M|re.I) #返回所有匹配到的列表list,通常用于查找;
sub( r"\d+"," ", "abc123ABC" ) #返回替换的字符串,语法:sub(正则,替换的字符串,查找字符串);
compile( r"\d+" ) #编译并生成一个正则表达式对象,该对象可调用 match、search、findall等函数,而无需再传递正则;
【匹配对象】的方法:
span():返回一个元组,包含匹配 (开始,结束) 的位置;
group():返回匹配的字符串;
其他函数:
print ("Hello, Python") # 输出,有换行;
print ("Hello, Python", end=" ") #输出,没有换行;
str = input("按下 enter 键后退出") #等待用户输入;
print(r "Hello, Python \n" ) # 反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
del var1, var2 #使用del语句删除单个或多个对象
type( obj ) #获取数据类型
isinstance( sonObj, fatherObj ) #isinstance判断 sonObj是否继承fatherObj
if obj1 is obj2 :... #is判断两个对象是否为同一类,不判断值是否相等
id( obj ) #id函数返回对象的唯一标识符
range(10) #内建函数,创建一个整数列表,返回 0-9,不包括10,相等于:range(0,10),语法:range(start, end[, step]),步长默认1
sys.exit() #系统退出
raise 异常名称 #主动抛出异常
python3关键字有:None、default
python命令行里写多行代码,在每行后面加上 ;\ 就可以了
Python 3 源码文件默认以 UTF-8 编码,自定义编码:# -*- coding: UTF-8 -*-
pip 是一个通用的 Python 包管理工具
__name__是python文件的内置变量,当文件被当做脚本执行时, 其值为 '__main__',当被其他文件导入时,则不为 '__main__';
Python中提供一个底层接口WSGI(Python Web Server Gateway Interface: Web服务器网关接口),这个底层接口很好的模拟了web服务器端的类似于Nginx和Apache的功能;
Python 3.5版本出现了:async/await 异步编程;
Scrapy爬虫框架:
基本模块:详解参考
(1) 调度器(Scheduler)、(2) 下载器(Downloader)、(3) 爬虫(Spider)、(4) 实体管道(Item Pipeline)、(5) Scrapy引擎(Scrapy Engine)、(6) 中间件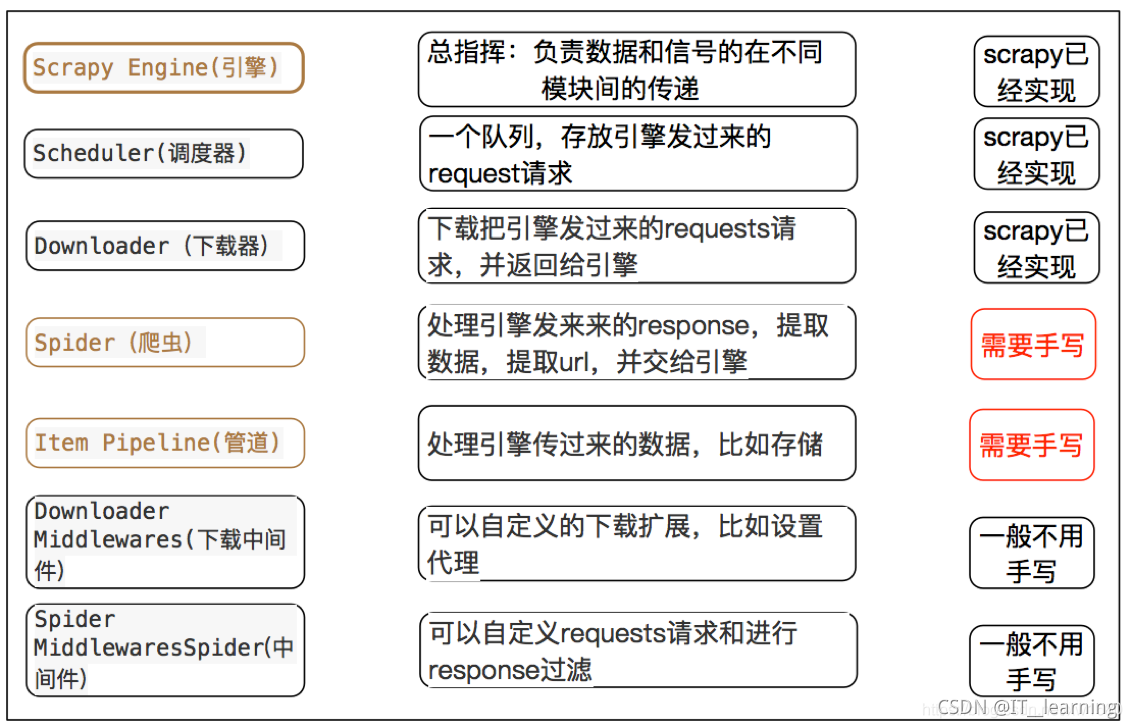
知识点:
1、Scrapy shell 是一个交互终端,使用XPath或CSS表达式,来测试抓取内容;
启动方法:1)在cmd中:scrapy shell 网址;2)测试response.xpath、response.css等抓取效果;
2、抓取内容有response.xpath(常用,参考)、response.css、response.re(正则提取)等方法;
3、简易流程:爬取(手写爬虫)-》处理数据(管道中,手写代码,比如过滤、存储);
4、自定义中间件:1)下载器中间件:用于自动更换user-agent、IP; 2)爬虫中间件:用于处理输入(response)和输出(items或requests);
5、pipelines.py:实体管道,接收爬取的数据,并进一步处理,比如验证、整理数据、存入数据库、存入文本文件等,注意使用管道前,需要在配置文件中开启:ITEM_PIPELINES 或者 在自定义配置中custom_settings={ITEM_PIPELINES: '...' };
6、items.py:定义数据结构,对抓取的数据结构化,类似于java的bean;
7、settings.py:项目配置文件,比如定义User-Agent、是否遵循robots协议、最大并发量、下载延迟时间等;也可以在爬虫程序中单独配置custom_settings={配置项};参考1
几个创建命名:
创建爬虫项目: scrapy startproject 项目名
创建爬虫程序(进入项目目录):scrapy genspider 爬虫名 爬取域名,此时spider目录下会创建【爬虫名.py】,该文件包含:起始地址 start_url、parse 函数,爬虫逻辑在 parse 中编写;
运行爬虫项目(进入项目目录):scrapy crawl 项目名 或 scrapy crawl 项目名 -o 文件名.json(.jsonlines、.csv、.xml)
备注:爬取通过js动态加载的内容,需要配合selenium使用。
spider类派生了四种子爬虫:
CrawlSpider:常用,可使用【链接提取器】跟进爬取子网页,参考 参考2 参考3;XMLFeedSpider:爬取XML文件,比如RSS;CSVFeedSpider:爬取CVS文件;SitemapSpider:爬取网站的sitemap;
创建CrawlSpider爬虫程序:scrapy genspider -t crawl 爬虫名 爬取域名


 浙公网安备 33010602011771号
浙公网安备 33010602011771号