5,pandas高级数据处理
1、删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
- keep参数:指定保留哪一重复的行数据 - 创建具有重复元素行的DataFrame
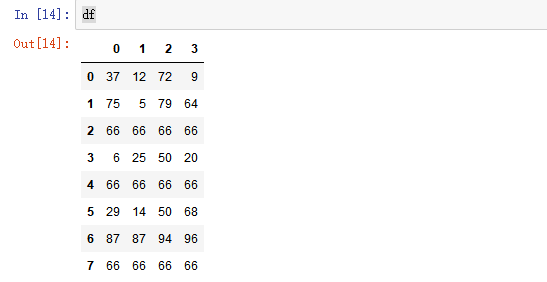
import numpy as np import pandas as pd from pandas import Series,DataFrame #创建一个df np.random.seed(1) df = DataFrame(data=np.random.randint(0,100,size=(8,4))) df
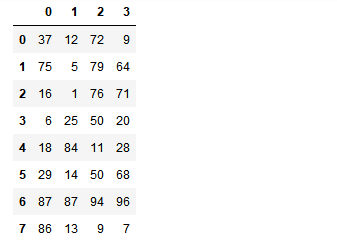
#手动将df的某几行设置成相同的内容 df.iloc[2] = [66,66,66,66] df.iloc[4] = [66,66,66,66] df.iloc[7] = [66,66,66,66] df

- 使用duplicated查看所有重复元素行
df.duplicated(keep='last')
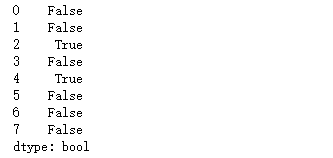
indexs = df.loc[df.duplicated(keep='last')].index df.drop(labels=indexs,axis=0)
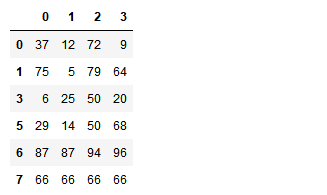
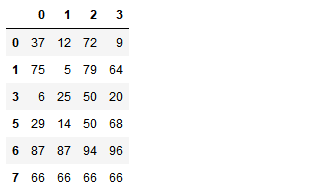
使用drop_duplicates()函数删除重复的行
- drop_duplicates(keep='first/last'/False)
df.drop_duplicates(keep='last')
2. 映射
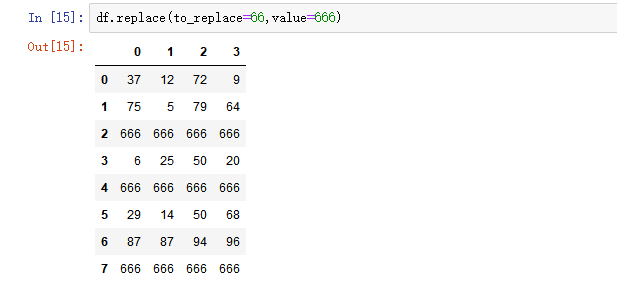
1) replace()函数:替换元素
使用replace()函数,对values进行映射操作
Series替换操作
- 单值替换
- 普通替换
- 字典替换(推荐)
- 多值替换
- 列表替换
- 字典替换(推荐)
- 参数
- to_replace:被替换的元素
DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
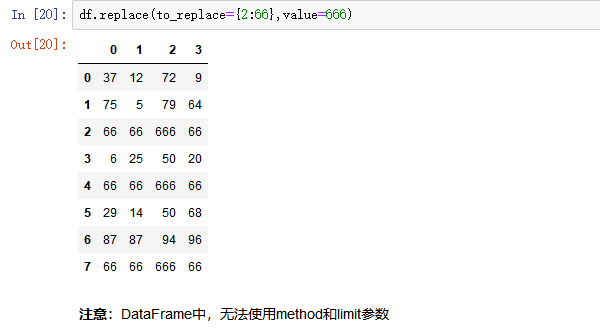
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
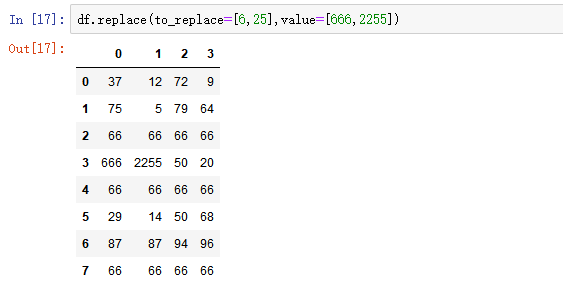
- 列表替换: to_replace=[] value=[]
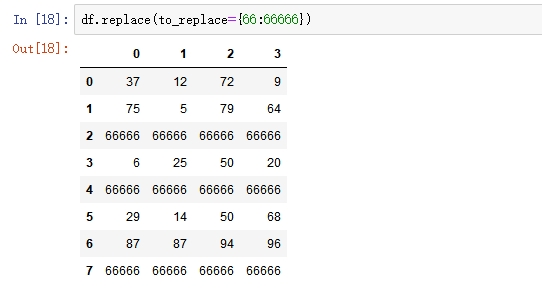
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}
2) map()函数:新建一列 , map函数并不是df的方法,而是series的方法
- map()可以映射新一列数据
- map()中可以使用lambd表达式
-
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
- 注意 map()中不能使用sum之类的函数,for循环
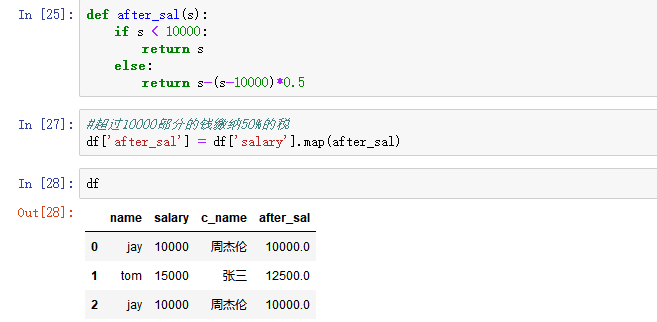
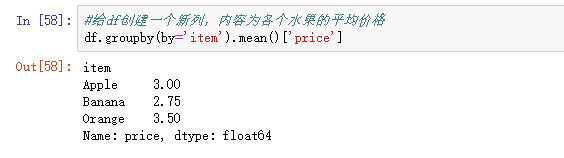
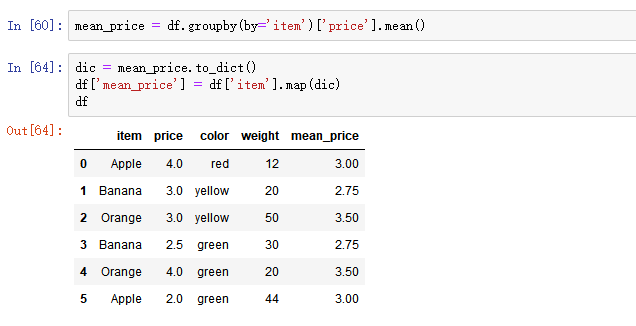
- 新增一列:给df中,添加一列,该列的值为英文名对应的中文名


map当做一种运算工具,至于执行何种运算,是由map函数的参数决定的(参数:lambda,函数)
- 使用自定义函数
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。
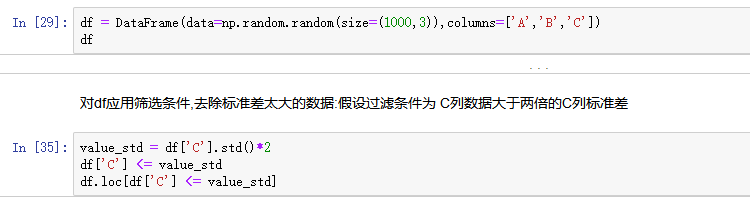
3. 使用聚合操作对数据异常值检测和过滤
使用df.std()函数可以求得DataFrame对象每一列的标准差
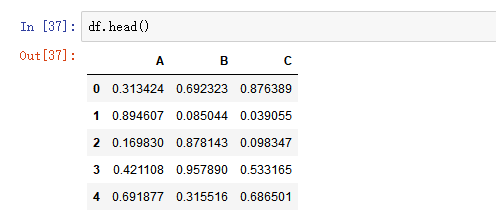
- 创建一个1000行3列的df 范围(0-1),求其每一列的标准差
4. 排序
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])可以借助np.random.permutation()函数随机排序
random_df = df.take(np.random.permutation(1000),axis=0).take(np.random.permutation(3),axis=1) random_df[0:100]
- np.random.permutation(x)可以生成x个从0-(x-1)的随机数列
5. 数据分类处理【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
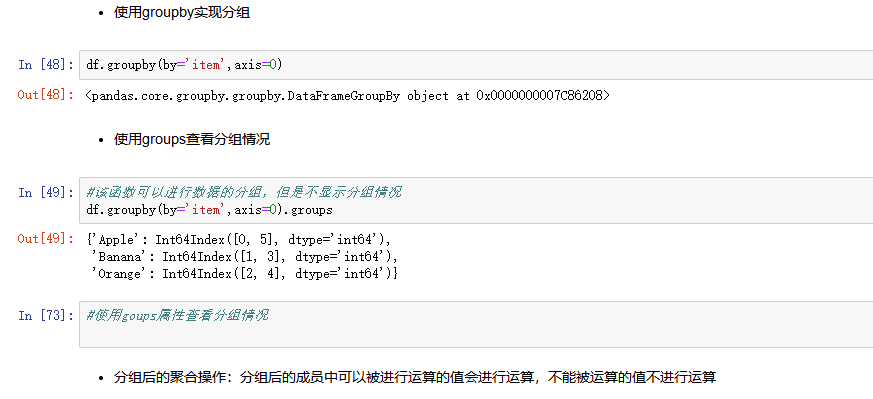
- groupby()函数
- groups属性查看分组情况
- eg: df.groupby(by='item').groups
分组
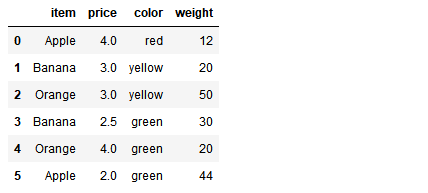
from pandas import DataFrame,Series df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'], 'price':[4,3,3,2.5,4,2], 'color':['red','yellow','yellow','green','green','green'], 'weight':[12,20,50,30,20,44]}) df

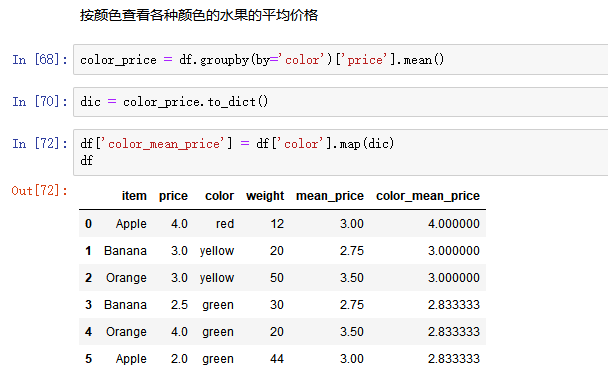
6. 高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
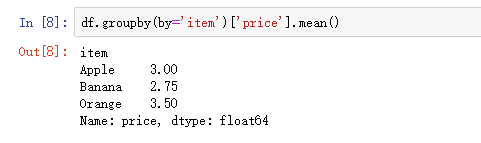
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式



 浙公网安备 33010602011771号
浙公网安备 33010602011771号