
大数据学习——sparkSql对接mysql
1上传jar

2 加载驱动包
[root@mini1 bin]# ./spark-shell --master spark://mini1:7077 --jars mysql-connector-java-5.1.32.jar --driver-class-path mysql-connector-java-5.1.32.jar
create table dept( deptno int , dname varchar(14) , loc varchar(13) ) ; create table emp( eno int , ename varchar(10), job varchar(9), mgr int, hirdate date, sal int, comm int, deptno int not null ); INSERT INTO dept VALUES(10,'ACCOUNTING','NEW YORK'); INSERT INTO dept VALUES(20,'RESEARCH','DALLAS'); INSERT INTO dept VALUES(30,'SALES','CHICAGO'); INSERT INTO dept VALUES(40,'OPERATIONS','BOSTON'); INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20); INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30); INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30); INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20); INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30); INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30); INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10); INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,'1987-06-13',3000,NULL,20); INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10); INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30); INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,'1987-06-13',1100,NULL,20); INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30); INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20); INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,'1983-01-23',1300,NULL,10);
3
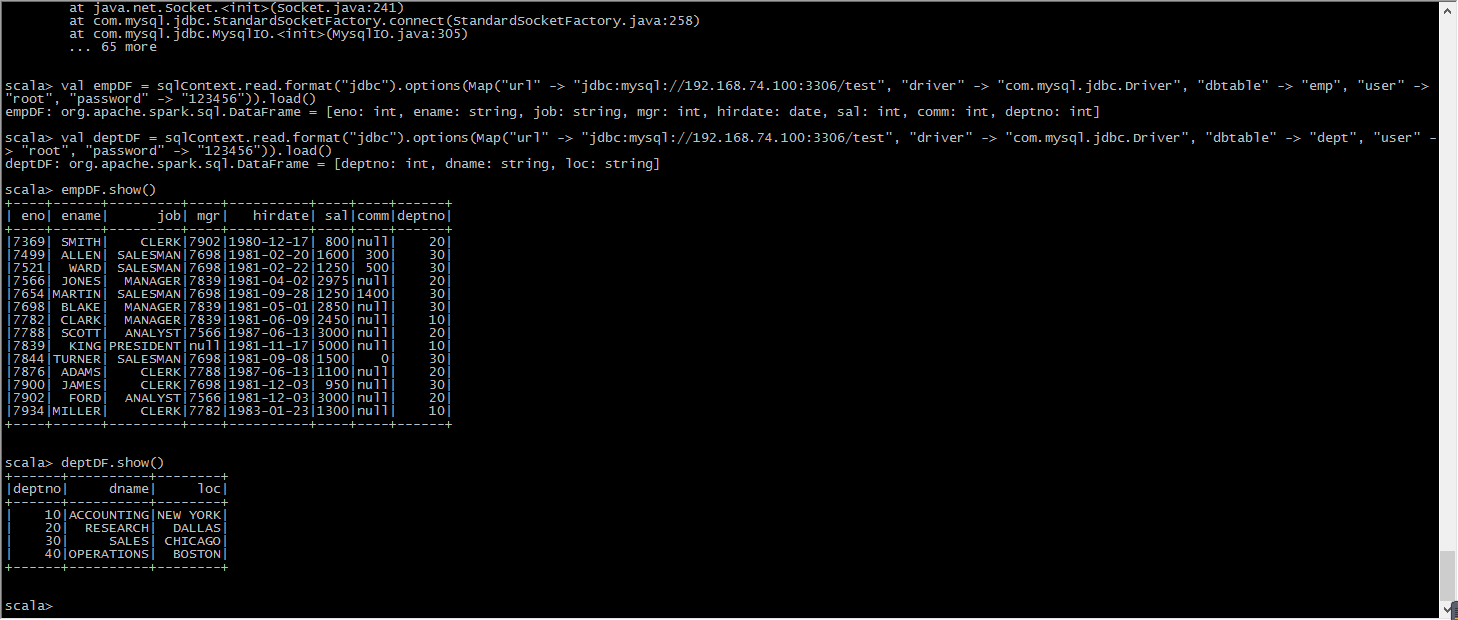
val sqlContext = new org.apache.spark.sql.SQLContext(sc) val empDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.74.100:3306/test", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "emp", "user" -> "root", "password" -> "123456")).load()
val deptDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.74.100:3306/test", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "dept", "user" -> "root", "password" -> "123456")).load()
4 读取数据(注意mysql要启动)
empDF.show()
deptDF.show()
empDF.registerTempTable("emp")
deptDF.registerTempTable("dept")
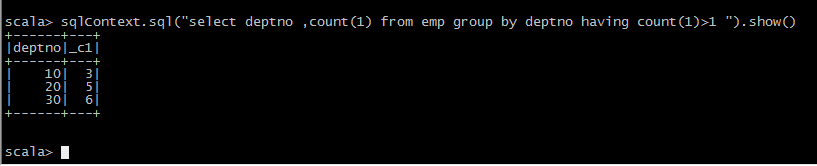
1.列出至少有一个员工的所有部门。 分析:每个部门有多少员工 ------ 根据部门编号进行分组 select deptno,count(*) from emp group by deptno having count(*) >= 1; 2.列出薪金比“SMITH”多的所有员工。(是否支持子查询) 分析:先查询出SMITH工资 : select sal from emp where ename='SMITH'; select * from emp where sal > (select sal from emp where ename='SMITH'); 3.***** 列出所有员工的姓名及其直接上级的姓名。 分析:表自映射,为表起别名,进行关联 t1 表模拟员工表 t2 表保存直接上级信息 select t1.ename 员工姓名, t2.ename 直接上级 from emp t1,emp t2 where t1.MGR = t2.empno; 4.列出受雇日期早于其直接上级的所有员工。 分析:原理和上题类似 select t1.*,t2.hirdate from emp t1,emp t2 where t1.MGR = t2.eno and t1.hirdate < t2.hirdate 5.列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。 分析:部门没员工也要显示 --- 外连接。无论怎样部门信息一定要显示,通过部门去关联员工 select * from dept left outer join emp on dept.deptno = emp.deptno ; 6.列出所有“CLERK”(办事员)的姓名及其部门名称。 分析:查找job为CLERK 员工姓名和部门名称 员工姓名 emp表 部门名称 dept表 select emp.ename,dept.dname,emp.job from emp,dept where emp.deptno = dept.deptno and emp.job='CLERK'; 7.列出最低薪金大于1500的各种工作。 分析:工作的最低薪金 ---- 按工作分组,求最低薪金 select min(sal) from emp group by job; 大于1500 是一个分组条件 --- having select job,min(sal) from emp group by job having min(sal) > 1500; 8.列出在部门“SALES”(销售部)工作的员工的姓名,假定不知道销售部的部门编号。 分析:员工姓名位于 emp 部门名称 dept select emp.ename from emp,dept where emp.deptno = dept.deptno and dept.dname = 'SALES'; 9.列出薪金高于公司平均薪金的所有员工。 分析:先求公司平均薪金 select avg(sal) from emp; select * from emp where sal > (select avg(sal) from emp); 10.列出与“SCOTT”从事相同工作的所有员工。 分析:先查询SCOTT : select job from emp where ename ='SCOTT'; select * from emp where ename <> 'SCOTT' and job = (select job from emp where ename ='SCOTT'); 13.列出在每个部门工作的员工数量、平均工资。 分析:按部门分组 select deptno, count(*),avg(sal) from emp group by deptno; 14.列出所有员工的姓名、部门名称和工资。 分析: select emp.ename,dept.dname,emp.sal from emp,dept where emp.deptno = dept.deptno; 15.列出所有部门的详细信息和部门人数。 分析: select dept.deptno,count(1) from emp,dept where emp.deptno=dept.deptno group by dept.deptno ; 16.列出各种工作的最低工资。 分析:各个工作 分组 , 最低工资 min select job,min(sal) from emp group by job; 17.列出各个部门的MANAGER(经理)的最低薪金。 分析:where job='MANAGER' 过滤所有不是经理数据 select deptno,min(sal) from emp where job ='MANAGER' group by deptno; 18.列出所有员工的年工资,按年薪从低到高排序。 分析: select ename, sal*12 from emp order by sal*12 asc; 19.查出emp表中薪水在3000以上(包括3000)的所有员工的员工号、姓名、薪水。 分析: select * from emp where sal >= 3000; 22.查询出emp表中所有的工作种类(无重复) 分析: select distinct job from emp; 23.查询出所有奖金(comm)字段不为空的人员的所有信息。 分析:不为空 is not null select * from emp where comm is not null; 24.查询出薪水在800到2500之间(闭区间)所有员工的信息。(注:使用两种方式实现and以及between and) 分析:select * from emp where sal >= 800 and sal <= 2500; select * from emp where sal between 800 and 2500; 25.查询出员工号为7521,7900,7782的所有员工的信息。(注:使用两种方式实现,or以及in) 分析:select * from emp where eno in(7521,7900,7782); select * from emp where eno=7521 or eno = 7900 or eno = 7782; 26.查询出名字中有“A”字符,并且薪水在1000以上(不包括1000)的所有员工信息。 分析: 模糊查询 select * from emp where ename like '%A%' and sal > 1000; 27.查询出名字第三个字母是“M”的所有员工信息。 分析:第三个字母 __M% select * from emp where ename like '__M%'; 28.将所有员工按薪水升序排序,薪水相同的按照入职时间降序排序。 分析:select * from emp order by sal asc,hiredate desc; 29.将所有员工按照名字首字母升序排序,首字母相同的按照薪水降序排序。 分析:SUBSTRING('字符串',第几个字符,长度); ---- 首字母 substring(ename,1,1) select * from emp order by substring(ename,1,1) asc,sal desc;
5 往mysql数据库写数据
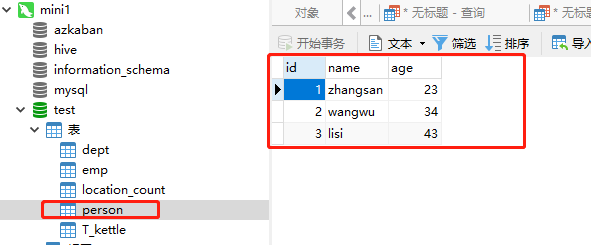
package org.apache.spark import java.util.Properties import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, DataFrameHolder, SQLContext} /** * Created by Administrator on 2019/6/13. */ object JDBCsparksql { def main(args: Array[String]) { val conf = new SparkConf().setAppName("spark-joindemo").setMaster("local") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) val file = sc.textFile("hdfs://mini1:9000/person.json") val personRDD: RDD[Person] = file.map(_.split(" ")).map(x => Person(x(0).toLong, x(1), x(2).toInt)) import sqlContext.implicits._ val personDF: DataFrame = personRDD.toDF() personDF.registerTempTable("person") val p: Properties = new Properties() p.put("user", "root") p.put("password", "123456") sqlContext.sql("select * from person").write.mode("overwrite").jdbc("jdbc:mysql://192.168.74.100:3306/test", "person", p) sc.stop() } } case class Person(id: Long, name: String, age: Int)
愿你遍历山河
仍觉人间值得

 浙公网安备 33010602011771号
浙公网安备 33010602011771号