
面试准备
2. 专业技能
2.1 Java基础
2.1.1 IO流
IO,即in和out,也就是输入和输出,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道。
- 字节流: 字节流主要用来处理二进制文件,比如说图片啊、MP3 啊、视频啊
- InputStream
- FileInputStream
- ....
- OutputStream
- FileOutputStream
- ...
- InputStream
- 字符流: 字符流一般用于处理纯文本类型的文件,如TXT文件等
- Reader
- InputStreamReader
- FileReader
- ...
- InputStreamReader
- Writer
- OutputStreamWriter
- FileWriter
- ...
- OutputStreamWriter
- Reader
2.1.2 集合
| 体系 | 接口/类 | 核心特征 | 底层实现 | 性能特点 | 线程安全 | 适用场景 |
|---|---|---|---|---|---|---|
| Collection (单元素集合) | List (有序,可重复) | ArrayList | 动态数组 | 查询快 (O(1)),增删慢 (O(n)) | 否 | 读多写少,随机访问频繁 |
| LinkedList | 双向链表 | 增删快 (O(1)),查询慢 (O(n)) | 否 | 写多读少,可作队列/栈 | ||
| Vector | 动态数组 | 同ArrayList,但线程安全(性能低) | 是 | 已过时,不推荐 | ||
| Set (无序,唯一) | HashSet | 哈希表 | 查询、插入、删除快 (平均O(1)) | 否 | 快速去重,不关心顺序 | |
| LinkedHashSet | 哈希表+链表 | 在HashSet基础上保证插入/访问顺序 | 否 | 需要去重且保持顺序 | ||
| TreeSet | 红黑树 | 元素自动排序,操作O(log n) | 否 | 需要去重且排序 | ||
| Queue (队列) | PriorityQueue | 优先级堆 | 按优先级出队,非FIFO | 否 | 任务调度,优先级处理 | |
| Map (键值对) | HashMap | 数组+链表/红黑树 | 查询、插入、删除快 (平均O(1)) | 否 | 最常用的键值对存储 | |
| LinkedHashMap | HashMap+链表 | 在HashMap基础上保证插入/访问顺序 | 否 | 缓存实现(如LRU) | ||
| TreeMap | 红黑树 | 键自动排序,操作O(log n) | 否 | 需要按键排序的映射 | ||
| Hashtable | 数组+链表 | 同HashMap,但线程安全(性能低) | 是 | 已过时,不推荐 | ||
| ConcurrentHashMap | 分段锁/CAS | 高并发下的线程安全,性能优 | 是 | 替代Hashtable,高并发场景 |
2.1.3 泛型和注解
- 泛型
泛型的核心思想是在定义类、接口或方法时,不指定具体的类型,而是使用一个类型参数(如T),等到使用时再确定这个参数的具体类型。
上界通配符 <? extends T>:表示“未知的特定子类型”。它支持读取(你取出的元素肯定是T或其子类),但不支持写入(因为编译器不知道具体是哪个子类,无法保证类型安全)。
下界通配符 <? super T>:表示“未知的特定父类型”。它支持写入(你可以安全地放入T及其子类),但读取受限(读出的对象只能赋值给Object,因为不知道具体的父类是什么)。
泛型的核心价值在于编译时类型安全和代码复用,它让我们的数据结构(如集合)和算法变得更加通用和可靠。
- 注解
注解的本质是为代码元素(类、方法、变量等)附加一些元数据。这些元数据本身不直接执行业务逻辑,但可以被编译器、开发工具或运行时环境(通过反射)读取,并根据这些元数据执行相应的操作。
注解的核心价值在于声明式编程和元数据驱动,它让代码的配置和意图更加清晰,并被各种框架和工具所利用。
2.2 JUC
2.2.1 synchronized锁升级机制
-
Java对象内存分布
-
对象头
- 对象标记(Mark Word):HashCode,GC标记,GC存活次数,同步锁标记,偏向锁持有者
- 类元信息(又叫类型指针):指向该对象类元数据(klass)的首地址
- 长度(数组对象特有)
-
实例数据(属性数据)
-
对齐填充(保证8字节的倍数)
-
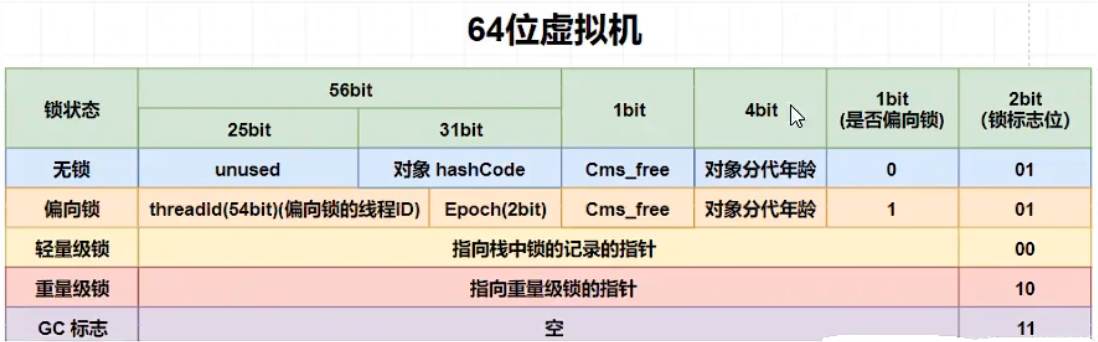
无锁, 偏向锁, 轻量级锁, 重量级锁
-
无锁 001
-
偏向锁 : 1个线程重复获取 101
MarkWord存储的是偏向的线程ID
如果不是自己线程ID, 则升级为轻量级锁.
- 轻量级锁: 多个线程, CAS获取 000
MarkWord存储的是指向线程虚拟机栈中Lock Record的指针
CAS次数达到上限(默认10), 升级为重量级锁
- 重量级锁 多个线程获取 010
MarkWord存储的是指向堆中的Monitor对象的指针
Monitor中包含 获取锁的线程,重入次数等数据
2.2.2 线程池机制
public ThreadPoolExecutor(int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 线程存活时间,超过核心线程数时又空闲
TimeUnit unit, // 时间单位
BlockingQueue<Runnable> workQueue, // 阻塞队列
ThreadFactory threadFactory, // 创建线程的工厂
RejectedExecutionHandler handler) { // 拒绝策略
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
任务 ==> 核心线程 ==> 阻塞队列 ==> 工作线程
(1) 系统中线程池的线程数量,设置多少比较合理?
- CPU密集型的任务:也就是需要进行复杂计算的业务场景,线程数应接近CPU核心数,避免过多的线程切换损耗性能,通常建议设置为 CPU核心数 +1。
- I/O密集型任务:那些以数据库CRUD操作为主的业务系统,线程数可设置为 CPU核心数 ×2,充分利用CPU在I/O等待时的空闲时间。
2.2.3 CAS 与 Unsafe
Compare And Swap, 比较并交换,实现并发算法时常用的一种技术。
它包含三个操作数:
- 内存位置
- 预期原值
- 更新值
Java中CAS操作的执行依赖于Unsafe类的方法。CAS是一条CPU的原子指令(cmpxchg指令),不会造成所谓的数据不一致问题,Unsafe提供的CAS方法(如compareAndSwapXXX)底层实现即为CPU指令cmpxchg。
// 自定义自旋锁
class SpinLockDemo{
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void lock(){
Thread thread = Thread.currentThread();
while(!atomicReference.compareAndSet(null,thread)) {
// 自定义自旋 ==> 空转
}
}
public void unlock(){
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread,null);
}
}
2.2.4 AQS
AQS定义
抽象的队列同步器- 整体就是一个抽象的FIFO队列来完成资源获取线程的排队工作,并通过一个int类型变量来表示持有锁的状态。
基本结构
- 同步状态
state, 它是一个int类型的变量, 用来表示持有锁的状态. :volatile int state及相应的CAS操作 - FIFO的双向链表, 作为获取锁的线程等待队列:CLH锁队列的变体
- 模板方法:由子类实现的
tryAcquire,tryRelease等方法
常用类
- ReentrantLock
- 获取锁流程
- 非公平锁:
- CAS尝试加锁
- 加锁成功返回true,失败返回false
- 公平锁
- 尝试加锁
- 前面有线程排队,加锁失败,将排在队列尾部
- 前面没有线程排队,CAS尝试加锁
- 加锁成功,返回true
- 加锁失败,返回false
- 非公平锁:
- 释放锁流程
- 当前线程不是加锁线程,抛出异常
int c = getStatus() - 1;- c 等于0,则将当前owner置null
- 如果
c != 0, 则status(重入次数) - 1, 并且返回false
- 获取锁流程
- ReentrantReadWriteLock
- 读锁和写锁
- StampedLock
| 锁模式 | 获取方法 | 特性 | 适用场景 |
|---|---|---|---|
| 写锁 (独占锁) | writeLock() |
排他性。同一时间只有一个线程能获取。与任何读锁(悲观、乐观)互斥。 | 需要写入数据,保证数据独占性的场景。 |
| 悲观读锁 | readLock() |
共享性。多个线程可同时获取。但与写锁互斥(有写锁请求时,新读锁会被阻塞)。 | 读操作频繁,且预计读操作时间较长,不希望被写入打断。 |
| 乐观读锁 | tryOptimisticRead() |
无锁机制。不阻塞任何线程。仅返回一个邮戳(stamp)。使用前必须用validate(stamp)验证数据未被修改。 |
读多写少,且读操作很快,希望最大化吞吐量的场景。 |
2.3 JVM
2.3.1 JVM数据分布
- 线程共享
- 堆区
- 永生代 / 方法区 / 元空间
- 常量池
- 类信息
- 静态变量
- 线程私有区
- 虚拟机栈
- 本地方法栈
- 程序计数器
2.3.2 JMM模型
JVM规范中定义的一种Java内存模型,来屏蔽掉各种硬件和操作系统的内存访问差异。用来实现Java程序在各个平台下都能达到一致的内存访问效果.
JMM规范将Java内存分为了主内存和工作内存, 每个线程拥有自己的工作内存, 工作内存中的数据是主内存中数据的拷贝. 通过先行发生原则保证数据的可见性和有序性.
happens-before总原则
- 可见:如果一个操作
happens-before另一个操作,那么第一个操作对第二个操作可见 - 重排:如果两个操作之间存在
happens-before关系,并不一定按照happens-before的顺序进行执行,只要结果一致,执行顺序可能改变。
2.3.3 垃圾回收机制
可达性分析: GCRoot
-
根对象:
-
虚拟机栈中引用的对象
-
方法区/元空间中的静态变量等
-
-
CMS: 标记清除算法
- 新生代
- 幸存区
- 老年代
-
G1: 根据Region的垃圾堆积程度排序,优先收集垃圾收集收益大的Region
- Region:1M~32M的大小相等且独立
- Eden
- Survivor
- 老年代
- Humongous
- Region:1M~32M的大小相等且独立
2.3.4 JVM调优核心参数
- 堆内存
- 堆内存大小:
XMS, XMX - 新生代、元空间
- 堆内存大小:
- 垃圾收集器
- GC 问题排查时, 开启GC日志记录
- 选择垃圾回收器:
-XX:+UseZGC
- 处理OOM
在发生 OOM 时生成堆转储文件 -XX:+HeapDumpOnOutOfMemoryError
2.3.5 JVM调优工具
- jps: 查看所有Java进程
- jmap : 内存布局
- jstack:生成当前虚拟机线程的快照,每一个线程执行的方法堆栈集合
- jstat:Java程序运行状态
- jconsole : GUI
2.4 MySQL
2.4.1 事务
-
读未提交:主要的问题是发生脏读
-
读已提交:主要发生的问题:不可重复读
-
可重复读:还存在幻读
-
串行化
2.4.2 MVCC
- 读视图:RR隔离级别下,仅在事务中第一次执行快照读的时候生成ReadView, 后续复用该读视图。RC每次查询都更新视图
- m_ids:当前活跃事务id集合
- min_trx_id: 最小事务id
- max_trx_id: 下一个新事务分配的id
- create_trx_id: 本读视图的事务id
- 三个隐藏字段:主键id,事务id,上一个事务Id
- undo log:插入, 更新、删除的反向记录。
2.4.3 索引失效原则
大厂面试官:聊下 MySQL 慢查询优化、索引优化?-阿里云开发者社区
- 模糊查询
- 存在隐式类型转换
- 使用函数
- OR语句中包含非索引字段
- 违背了最左前缀法则
2.4.4 SQL优化
- 数据插入优化:批量插入,主键顺序,大批量使用
load命令加载 - 更新优化:选择有索引字段进行查询更新,否则行锁升级为表锁
- 主键优化:选择有序数据作为主键,尽量降低主键的长度
- 分页查询优化:大表分页查询所有行记录时,可以通过覆盖索引+子查询的方式进行分页查询
- count优化:尽量使用count(*)
2.5 Redis
2.5.1 持久化
- RDB:二进程的数据快照,体积小,恢复快。用于快速全量同步或恢复。
- AOF:命令日志,体积大,恢复慢。主要用于增量数据同步。
2.5.2 内存淘汰机制
-
不淘汰:默认
-
volatile-ttl: 存活时间越短的,越先淘汰
-
ttl-随机
-
allkeys-随机
-
ttl-lru: 最近最少使用, 最近使用的排在队头,删除队尾元素
-
allkeys-lru
-
ttl-lfu
-
allkeys-lfu:最不经常使用,使用频率低的排在队尾,删除队尾元素
2.5.3 主从复制,哨兵 集群分片原理
- 主从模式
- 哨兵模式
- 分片集群模式
- 创建节点,每个master占用一段分片值
- CRC-16算法对key计算hash值,然后根据hash值对16384取余,得到分片值
为什么16384?
- 2^14 bit
- 太小,主节点中hash槽(通过bitmap方式存储)压缩率低
- 太大,ping包大,浪费带宽
- 建议master节点小于1000,超过1000,会网络堵塞。16384个槽位足以应对1000个master节点。
京东面试题(Redis):为啥RedisCluster设计成16384个槽 - 知乎
2.5.4 缓存问题
- 缓存穿透:非法空值
- 缓存雪崩:大量key同时失效
- 缓存击穿:热点key失效 ==> 单个热点 key 过期时,大量并发请求瞬间击穿缓存直达数据库 == > 通过加锁
- 缓存数据一致性:开启事务数据库更新后删除缓存,版本号乐观锁,TTL (一致性由高到低)
2.6 Spring系列以及微服务框架
2.6.1 Spring
-
控制反转:将对象的创建和销毁交给Spring容器处理
-
AOP:面向切面编程
- 创建AOP步骤
- 定义切面类, 加上@Aspect注解
- 定义切入点表达式,用于匹配目标方法
- 定义通知方法,用于对目标方法增强
- 创建AOP步骤
-
AOP通知5类型
- 前置通知:方法执行前
- 后置通知:方法执行后生效(无论成功与失败)
- 后置返回通知:成功返回生效
- 后置异常通知:发生异常生效
- 环绕通知,控制方法执行的整个生命周期
-
注入Bean的方式:
- 构造器声明
- Setter注入
- 字段注入:@Autowire, @Resource (@Qualifier)
-
Bean的作用域
- 默认情况
- singleton
- prototype
- Web应用
- request: 每个请求一个bean
- session: 每个session一个bean
- ...
- 默认情况
-
Bean生命周期
- 创建Bean实例
- 属性赋值
- Bean初始化:调用Bean对象实现的一些初始化方法,以及BeanPostProcessor相关的初始化方法
- 使用Bean
- 销毁Bean: 调用对应的销毁方法
-
SpringBoot 实现热部署有哪几种方式?
-
无需重启程序,直接将代码自动更新到后台程序中
-
Spring Loaded
-
Spring-boot-devtools
-
2.6.2 Sentinel
- 限流算法
- 固定窗口计数器
- 实现简单:窗口1分钟,固定窗口开始和结束时间,一分钟内最多1000个请求
- 限流不平滑:窗口1分钟,第一秒计数满了,后续请求全部拒绝
- 滑动窗口计数器:环形数组
- 实现较复杂:窗口1分钟,窗口起止随时间移动,比如每秒向前移动一次,窗口内请求有限
- 限流比固定窗口计数平滑
- 漏桶算法
- 实现简单:固定流量速率,一旦超过该速率则拒绝后续请求
- 限流平滑,但无法处理流量激增或者超出速率会使一部分请求始终被拒绝
- 实际业务场景中,基本不会使用漏桶算法
- 令牌桶算法
- 实现复杂:以一定速率向桶中添加令牌,请求被处理前从桶中拿到令牌,处理一个请求消耗一个令牌。
- 动态调整令牌生产速率,按照一定速率向桶中添加令牌,桶中令牌满了
- 固定窗口计数器
2.6.3 OpenFeign
2.7 RabbitMQ
- 基础
- 交换机类型
- fanout
- topic:* 一个, # 0~多个
- direct
- headers
- 队列类型
- 普通队列
- 死信队列:可以转发消息的队列
- 交换机类型
2.7.1 消息丢失
- 生产者
- 开启重试机制
- 开启确认机制,收到MQ的成功接收确认后才认为发送成功
- 消息队列: 进行数据持久化操作,将消息写入磁盘
- 消费者
- 消费成功后,手动ACK
- 如果消费失败,消息重新进入队列或者进入死信队列
2.7.2 消息重复消费 / 消息幂等性
- 唯一索引:通过数据的唯一索引来限制消息重复,主要应用于一些数据插入操作,比如新增一行数据
- 版本号 + 乐观锁:给消息增加版本号,如果有更新,将版本号更新,然后通过乐观锁的方式判断消息是否重复消费
- 消息消费记录:给每个消息分配一个不同的id,记录消息的消费状态,可以存在redis或者关系性数据库中
2.7.3 消息顺序消费
RabbitMQ的顺序消费需要“顺序存储”和“单一消费者”两个条件同时满足才能实现
- 单队列,单消费者:无需任何操作,天然顺序消费
- x-single-active-consumer:单活模式,表示是否最多只允许一个消费者消费,如果有多个消费者同时绑定,则只会激活第一个,除非第一个消费者被取消或者死亡,才会自动转到下一个消费者。
- 多消费者:版本号 + 乐观锁。
2.7.4 大规模消息积压
- 短期
- 增加消费者实例
- 将消息先持久化存储到数据库,高峰期过了再陆续消费
- 生产者端进行限流降级
- 批量处理:批处理消费者拉取消息,将消息批量打包然后再转发
- 长期
- 提高单条消息的处理效率:比如进行
- 配置死信队列,反复处理失败的消息进入死信队列,避免阻塞正常消费
- 建立监控预警机制,达到积压阈值发送预警通知

 浙公网安备 33010602011771号
浙公网安备 33010602011771号