6个冷门但实用的pandas知识点
1 简介
pandas作为开展数据分析的利器,蕴含了与数据处理相关的丰富多样的API,使得我们可以灵活方便地对数据进行各种加工,但很多pandas中的实用方法其实大部分人都是不知道的,今天就来给大家介绍6个不太为人们所所熟知的实用pandas小技巧。

2 6个实用的pandas小知识
2.1 Series与DataFrame的互转
很多时候我们计算过程中产生的结果是Series格式的,而接下来的很多操作尤其是使用链式语法时,需要衔接着传入DataFrame格式的变量,这种时候我们就可以使用到pandas中Series向DataFrame转换的方法:
- 利用to_frame()实现Series转DataFrame
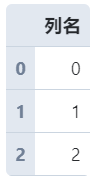
s = pd.Series([0, 1, 2])
# Series转为DataFrame,name参数用于指定转换后的字段名
s = s.to_frame(name='列名')
s
顺便介绍一下单列数据组成的数据框转为Series的方法:
- 利用squeeze()实现单列数据DataFrame转Series
# 只有单列数据的DataFrame转为Series
s.squeeze()

2.2 随机打乱DataFrame的记录行顺序
有时候我们需要对数据框整体的行顺序进行打乱,譬如在训练机器学习模型时,打乱原始数据顺序后取前若干行作为训练集后若干行作为测试集,这在pandas中可以利用sample()方法快捷实现。
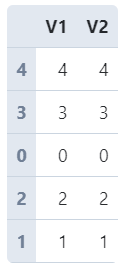
sample()方法的本质功能是从原始数据中抽样行记录,默认为不放回抽样,其参数frac用于控制抽样比例,我们将其设置为1则等价于打乱顺序:
df = pd.DataFrame({
'V1': range(5),
'V2': range(5)
})
df.sample(frac=1)
2.3 利用类别型数据减少内存消耗
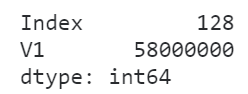
当我们的数据框中某些列是由少数几种值大量重复形成时,会消耗大量的内存,就像下面的例子一样:
import numpy as np
pool = ['A', 'B', 'C', 'D']
# V1列由ABCD大量重复形成
df = pd.DataFrame({
'V1': np.random.choice(pool, 1000000)
})
# 查看内存使用情况
df.memory_usage(deep=True)
这种时候我们可以使用到pandas数据类型中的类别型来极大程度上减小内存消耗:
df['V1'] = df['V1'].astype('category')
df.memory_usage(deep=True)
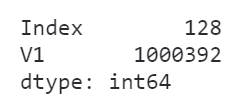
可以看到,转换类型之后内存消耗减少了将近98.3%!
2.4 pandas中的object类型陷阱
在日常使用pandas处理数据的过程中,经常会遇到object这种数据类型,很多初学者都会把它视为字符串,事实上object在pandas中可以代表不确定的数据类型,即类型为object的Series中可以混杂着多种数据类型:
s = pd.Series(['111100', '111100', 111100, '111100'])
s
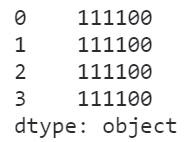
查看类型分布:
s.apply(lambda s: type(s))

这种情况下,如果贸然当作字符串列来处理,对应的无法处理的元素只会变成缺失值而不报错,给我们的分析过程带来隐患:
s.str.replace('00', '11')
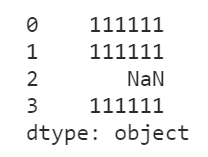
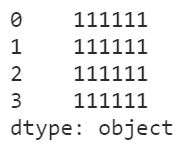
这种时候就一定要先转成对应的类型,再执行相应的方法:
s.astype('str').str.replace('00', '11')
2.5 快速判断每一列是否有缺失值
在pandas中我们可以对单个Series查看hanans属性来了解其是否包含缺失值,而结合apply(),我们就可以快速查看整个数据框中哪些列含有缺失值:
df = pd.DataFrame({
'V1': [1, 2, None, 4],
'V2': [1, 2, 3, 4],
'V3': [None, 1, 2, 3]
})
df.apply(lambda s: s.hasnans)

2.6 使用rank()计算排名时的五种策略
在pandas中我们可以利用rank()方法计算某一列数据对应的排名信息,但在rank()中有参数method来控制具体的结果计算策略,有以下5种策略,在具体使用的时候要根据需要灵活选择:
- average
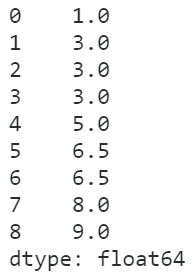
在average策略下,相同数值的元素的排名是其内部排名的均值:
s = pd.Series([1, 2, 2, 2, 3, 4, 4, 5, 6])
s.rank(method='average')
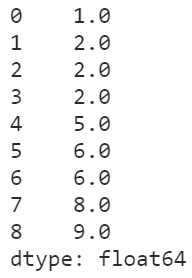
- min
在min策略下,相同元素的排名为其内部排名的最小值:
s.rank(method='min')
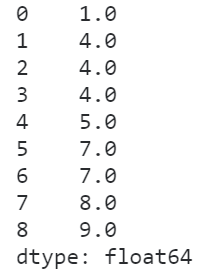
- max
max策略与min正好相反,取的是相同元素内部排名的最大值:
s.rank(method='max')
- dense
在dense策略下,相当于对序列去重后进行排名,再将每个元素的排名赋给相同的每个元素,这种方式也是比较贴合实际需求的:
s.rank(method='dense')

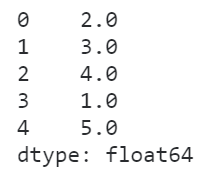
- first
在first策略下,当多个元素相同时,会根据这些相同元素在实际Series中的顺序分配排名:
s = pd.Series([2, 2, 2, 1, 3])
s.rank(method='first')
关于pandas还有很多实用的小知识,以后会慢慢给大家不定期分享~欢迎在评论区与我进行讨论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号