爬虫_图片下载
目录
2.requests模块爬取页面,Beautifulsoup模块获取图片url,再下载
3.scrapy爬取页面,xpath获取url,item+pipeline进行图片下载
4.scrapy爬取页面,xpath获取url,使用scrapy自带的ImagesPipeline下载多个图片
5.针对js异步加载图片的html,使用selenium模块下载网页提取url
6.针对gif,另外写的半ImagesPipeline半自定义pineline
1.requests模块直接下载图片url


import requests url = "http://img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg" res = requests.get(url) with open(r"img\requests模块直接下载url.jpg","wb") as f: f.write(res.content)

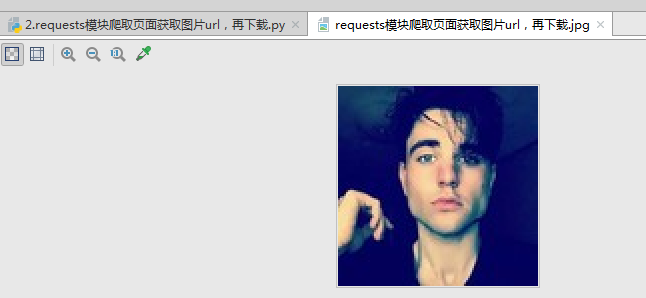
2.requests模块爬取页面,Beautifulsoup模块获取图片url,再下载
import requests from bs4 import BeautifulSoup url = "http://photo.hupu.com/" htm = requests.get(url) htm.encoding = "gbk" soup = BeautifulSoup(htm.text,"html.parser") img_tag = soup.find("div",attrs={"class":"tuijian"}).find("img") # <img border="0" src="//img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg"/> img_url = img_tag.attrs["src"] # //img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg img = requests.get("http:{}".format(img_url)) with open(r"img\requests模块爬取页面获取图片url,再下载.jpg","wb") as f: f.write(img.content)
3.scrapy爬取页面,xpath获取url,item+pipeline进行图片下载
# -*- coding: utf-8 -*- import scrapy from scrapy.selector import Selector,HtmlXPathSelector from baidu import items # 此处baidu是项目名称 # import requests # from bs4 import BeautifulSoup class HupuSpider(scrapy.Spider): name = 'hupu' allowed_domains = ['hupu.com'] start_urls = ['http://photo.hupu.com/'] def parse(self, response): # 使用BeautifulSoup # soup = BeautifulSoup(response.text, "html.parser") # # img_tag = soup.find("div", attrs={"class": "tuijian"}).find( # "img") # <img border="0" src="//img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg"/> # img_url = img_tag.attrs["src"] # //img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg # # img = requests.get("http:{}".format(img_url)) # # with open(r"img\scrapy下载图片.jpg", "wb") as f: # f.write(img.content) ############################################################################################################# # 使用hxs hxs = Selector(response=response).xpath('//div[@class="tuijian"]/table/tbody/tr/td[1]/a/img/@src') # 按标签的顺序,不能跳过某个标签 # class为tuijian的div标签 # 第1个td标签 # src属性 img_url = hxs.extract_first() url = "http:{}".format(img_url) obj = items.HupuImgItem() obj["img_url"] = url obj["img_name"] = "scrapy下载图片" yield obj
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class BaiduItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class HupuImgItem(scrapy.Item): img_url = scrapy.Field() img_name = scrapy.Field()
import requests import os class ImgPipeline(object): def __init__(self): if not os.path.exists('imgs'): os.makedirs('imgs') def process_item(self, item, spider): response = requests.get(item['img_url'], stream=True) file_name = '%s.jpg' % (item['img_name']) with open(os.path.join('imgs', file_name), mode='wb') as f: f.write(response.content) return item
ITEM_PIPELINES = { 'baidu.pipelines.ImgPipeline': 300, }
4.scrapy爬取页面,xpath获取url,使用scrapy自带的ImagesPipeline下载多个图片
# -*- coding: utf-8 -*- import scrapy from scrapy.selector import Selector from cl import items class HupuSpider(scrapy.Spider): name = 'hupu' allowed_domains = ['hupu.com'] start_urls = ['https://photo.hupu.com/'] def parse(self, response): hxs = Selector(response=response).xpath('//div[@class="tuijian"]/table/tbody/tr/td/a/img/@src') # 按标签的顺序,不能跳过某个标签 # class为tuijian的div标签 # 第1个td标签 # src属性 img_urls = hxs.extract() img_urls_iter = map(lambda x:"http:{}".format(x),img_urls) # url = "http:{}".format(img_url) obj = items.HupuImgItem() obj["img_urls"] = img_urls_iter # 这里设计是多个url的合集,当然也可以一个一个传 yield obj
import scrapy class HupuImgItem(scrapy.Item): img_urls = scrapy.Field()
from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem from scrapy.http import Request class HupuImgPipeline(ImagesPipeline): def get_media_requests(self, item, info): for img_url in item['img_urls']: yield Request(img_url) def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ print(results) # [(True, {'url': 'http://img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg', # 'path': '0-33-1492767262jpg_100x100_2017-04-21.jpg', 'checksum': 'a65aceb927b92d04248478d720 # 608ea3'}), 。。。。。] if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 return item def file_path(self, request, response=None, info=None): """ 返回文件名 这里是自己写一个file_path,如果不写,则对url进行hashlib.sha1生成一个文件名full/%s.jpg' """ return request.url.split('/')[-1] def open_spider(self,spider): """ 爬虫开始执行时,调用 :param spider: :return: """ print('open_spider') super(HupuImgPipeline, self).open_spider(spider) # def close_spider(self,spider): # """ # 爬虫关闭时,被调用 # :param spider: # :return: # """ # print('close_spider')
ITEM_PIPELINES = { # 'cl.pipelines.FilePipeline': 300, 'cl.pipelines.HupuImgPipeline': 300, } IMAGES_STORE = os.path.join(r"D:\临时\爬虫\scrapy\tmp2")
补充:
import re from scrapy.pipelines.images import ImagesPipeline from scrapy import Request class ImagesrenamePipeline(ImagesPipeline): def get_media_requests(self, item, info): # 循环每一张图片地址下载,若传过来的不是集合则无需循环直接yield for image_url in item['imgurl']: # meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path yield Request(image_url,meta={'name':item['imgname']}) # 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字 def file_path(self, request, response=None, info=None): # 提取url前面名称作为图片名。 image_guid = request.url.split('/')[-1] # 接收上面meta传递过来的图片名称 name = request.meta['name'] # 过滤windows字符串,不经过这么一个步骤,你会发现有乱码或无法下载 name = re.sub(r'[?\\*|“<>:/]', '', name) # 分文件夹存储的关键:{0}对应着name;{1}对应着image_guid filename = u'{0}/{1}'.format(name, image_guid) return filename
关于ImagesPipeline官方资料: https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/images.html?highlight=image
5.针对js异步加载图片的html,使用selenium模块下载网页提取url
from gevent import monkey,joinall;monkey.patch_all() from gevent.pool import Pool import requests from bs4 import BeautifulSoup import hashlib import os from selenium import webdriver options = webdriver.ChromeOptions() # options.add_argument('--window-position=0,0') # chrome 启动初始位置 # options.add_argument('--window-size=1080,800') # chrome 启动初始大小 options.add_argument('--headless') options.add_argument('--disable-gpu') # options.add_argument('--proxy-server=http://ip:port') # options.add_arguments("start-maximized") 最大化窗口 browser=webdriver.Chrome(chrome_options=options) url = "http://jandan.net/pic" browser.get(url) # print(browser.page_source) soup = BeautifulSoup(browser.page_source,"html.parser") pool = Pool(10) tmp_list = [] def get_img(url): print(url) img_obj = requests.get(url) suffix = url.rsplit(".", 1)[1] file_name = hashlib.sha1(bytes(url, encoding="utf-8")).hexdigest() file_name = "{}.{}".format(file_name, suffix) with open("tmp/{}".format(file_name),"wb") as f: f.write(img_obj.content) img_list = soup.select("div.text p img") for img in img_list: url = img.attrs["src"] tmp_list.append(pool.spawn(get_img,url)) joinall(tmp_list)
6.针对gif,另外写的半ImagesPipeline半自定义pineline
# -*- coding: utf-8 -*- import os # Scrapy settings for cl project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'cl' SPIDER_MODULES = ['cl.spiders'] NEWSPIDER_MODULE = 'cl.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 16 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 2 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'cl.middlewares.ClSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { # 'cl.middlewares.ClDownloaderMiddleware': 543, 'scrapy.downloadermiddlewares.stats.DownloaderStats':543, } # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { # 'cl.pipelines.FilePipeline': 300, # 'cl.pipelines.ImgsPipeline': 300, # 'cl.pipelines.XxxxxPipeline': 300, } IMAGES_STORE = os.path.join(r"D:\临时\爬虫\scrapy\tmp5") # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' TEST_FROM_CRAWLER_1 = "abc" TEST_FROM_CRAWLER_2 = 34 COMMANDS_MODULE = 'cl.commands' BASE_URL = "http://www.caoliu2054.com" DOWNLOAD_TIMEOUT = 15 DOWNLOADER_STATS = True
import scrapy class ClItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class ImgsItem(scrapy.Item): img_urls = scrapy.Field() title = scrapy.Field() class ImgItem(scrapy.Item): img_url = scrapy.Field() title = scrapy.Field()
from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem from scrapy.http import Request import re from cl.src import logger image_log = logger.file_logger("image") class ImgsPipeline(ImagesPipeline): def get_media_requests(self, item, info): for img_url in item['img_urls']: print(img_url) yield Request(img_url,meta={"title":item["title"]}) def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ # [(True, {'url': 'http://img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg', # 'path': '0-33-1492767262jpg_100x100_2017-04-21.jpg', 'checksum': 'a65aceb927b92d04248478d720 # 608ea3'}), 。。。。。] if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 return item def file_path(self, request, response=None, info=None): file_path_super = super(ImgsPipeline, self).file_path(request,response,info) title = request.meta["title"] title = re.sub(r'[?\\*|“<>:/]', '', title) file_name = file_path_super.split("/")[1] image_log.info(request.url) return "{}_{}".format(title,file_name) # """ # 返回文件名 # 这里是自己写一个file_path,如果不写,则对url进行hashlib.sha1生成一个文件名full/%s.jpg' # """ # return request.url.split('/')[-1] # def open_spider(self,spider): # """ # 爬虫开始执行时,调用 # :param spider: # :return: # """ # print('open_spider') # super(HupuImgPipeline, self).open_spider(spider) # def close_spider(self,spider): # """ # 爬虫关闭时,被调用 # :param spider: # :return: # """ # print('close_spider') class XxxxxPipeline(ImagesPipeline): def get_media_requests(self, item, info): for img_url in item['img_urls']: print(img_url) yield Request(img_url,meta={"title":item["title"]}) # break def process_item(self, item, spider): _super = super(XxxxxPipeline, self).process_item(item,spider) # return _super print(type(item)) pass def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ # [(True, {'url': 'http://img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg', # 'path': '0-33-1492767262jpg_100x100_2017-04-21.jpg', 'checksum': 'a65aceb927b92d04248478d720 # 608ea3'}), 。。。。。] if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 return item def file_path(self, request, response=None, info=None): file_path_super = super(XxxxxPipeline, self).file_path(request,response,info) title = request.meta["title"] title = re.sub(r'[?\\*|“<>:/]', '', title) file_name = file_path_super.split("/")[1] # if request.url.endswith("gif"): # file_name = file_name.replace("jpg","gif") image_log.info(request.url) return "{}_{}".format(title,file_name) # """ # 返回文件名 # 这里是自己写一个file_path,如果不写,则对url进行hashlib.sha1生成一个文件名full/%s.jpg' # """ # return request.url.split('/')[-1] # def open_spider(self,spider): # """ # 爬虫开始执行时,调用 # :param spider: # :return: # """ # print('open_spider') # super(HupuImgPipeline, self).open_spider(spider) # def close_spider(self,spider): # """ # 爬虫关闭时,被调用 # :param spider: # :return: # """ # print('close_spider') from cl import settings # 暂时没找到怎么科学地引入settings,类似于django那样引入自定义+global的那种。 class ImgPipeline(ImagesPipeline): def get_media_requests(self, item, info): yield Request(item['img_url'],meta={"title":item["title"]}) def process_item(self, item, spider): img_url = item['img_url'] if not img_url.endswith("gif"): return super(ImgPipeline, self).process_item(item, spider) else: img_dir = settings.IMAGES_STORE download_delay = settings.DOWNLOAD_DELAY _file_name = hashlib.sha1(bytes(img_url, encoding="utf-8")).hexdigest() title = item["title"] file_name = '{}_{}.gif'.format(title, _file_name) response = requests.get(img_url, stream=True) with open(os.path.join(img_dir, file_name), mode='wb') as f: f.write(response.content) time.sleep(download_delay) return item def item_completed(self, results, item, info): """ 文件下载完成之后,返回一个列表 results 列表中是一个元组,第一个值是布尔值,请求成功会失败,第二个值的下载到的资源 """ # [(True, {'url': 'http://img2.hupucdn.com/photo/0-33-1492767262jpg_100x100_2017-04-21.jpg', # 'path': '0-33-1492767262jpg_100x100_2017-04-21.jpg', 'checksum': 'a65aceb927b92d04248478d720 # 608ea3'}), 。。。。。] if not results[0][0]: # 如果下载失败,就抛出异常,并丢弃这个item # 被丢弃的item将不会被之后的pipeline组件所处理 raise DropItem('下载失败') # 打印日志 return item def file_path(self, request, response=None, info=None): file_path_super = super(ImgPipeline, self).file_path(request,response,info) title = request.meta["title"] title = re.sub(r'[?\\*|“<>:/]', '', title) file_name = file_path_super.split("/")[1] image_log.info(request.url) return "{}_{}".format(title,file_name)
import scrapy from cl.src.jiandan_src import jiandan from scrapy.http.request import Request from cl.items import ImgsItem,ImgItem class JiandanSpider(scrapy.Spider): name = 'jiandan' custom_settings = { 'ITEM_PIPELINES': { # 'cl.pipelines.XxxxxPipeline': 400, 'cl.pipelines.ImgPipeline': 400, # 'cl.pipelines.GifPipeline': 400 } } allowed_domains = ['jandan.net'] start_urls = ['http://jandan.net/ooxx'] def parse(self, response): # plus_arg = jiandan.get_plus_arg() # 通过requests模块,获取js内容,从js获取这个plus_arg plus_arg = "xG37WnrgkZXhrtekj13g4tyspXPcXSRv" img_hash_list = response.xpath("//span[@class='img-hash']/text()").extract() img_url_iter = map(lambda x: "http:" + jiandan.jiandan_decrypt(x, plus_arg), img_hash_list) # obj = ImgsItem() # obj["img_urls"] = img_url_iter # obj["title"] = "__" # yield obj # 一个一个url去yield item for img_url in img_url_iter: obj = ImgItem() obj["img_url"] = img_url obj["title"] = "__" yield obj next_page_url = response.xpath("//a[@class='previous-comment-page']/@href").extract_first() next_page_url = "http:" + next_page_url # yield Request(url=next_page_url,method="GET",callback=self.parse) # print(next_page_url)
# -*- coding:utf-8 -*- """ var jdTwvMhQwqVdjNW3JtVz7yMe2m4HZTFpFy = function (n, t, e) { var f = "DECODE"; var t = t ? t : ""; var e = e ? e : 0; var r = 4; t = md5(t); var d = n; var p = md5(t.substr(0, 16)); var o = md5(t.substr(16, 16)); if (r) { if (f == "DECODE") { var m = n.substr(0, r) } } else { var m = "" } var c = p + md5(p + m); var l; if (f == "DECODE") { n = n.substr(r); l = base64_decode(n) } var k = new Array(256); for (var h = 0; h < 256; h++) { k[h] = h } var b = new Array(); for (var h = 0; h < 256; h++) { b[h] = c.charCodeAt(h % c.length) } for (var g = h = 0; h < 256; h++) { g = (g + k[h] + b[h]) % 256; tmp = k[h]; k[h] = k[g]; k[g] = tmp } var u = ""; l = l.split(""); for (var q = g = h = 0; h < l.length; h++) { q = (q + 1) % 256; g = (g + k[q]) % 256; tmp = k[q]; k[q] = k[g]; k[g] = tmp; u += chr(ord(l[h]) ^ (k[(k[q] + k[g]) % 256])) } if (f == "DECODE") { if ((u.substr(0, 10) == 0 || u.substr(0, 10) - time() > 0) && u.substr(10, 16) == md5(u.substr(26) + o).substr(0, 16)) { u = u.substr(26) } else { u = "" } u = base64_decode(d) } return u }; """ import hashlib import base64 import requests from scrapy.selector import Selector import re class Jiandan(): __plus_arg = "" def get_plus_arg(self): if self.__plus_arg: return self.__plus_arg else: index_url = "http://jandan.net/ooxx" index_htm = requests.get(index_url) js_url = Selector(response=index_htm).xpath("//script[starts-with(@src,'//cdn.jandan.net')][2]/@src").extract_first() js_url = "http:" + js_url js_htm = requests.get(js_url) # self.__plus_arg = re.findall("""jd3Nnd5AOLks7xsb5E3WV4gGEAUy0dVQdZ\(e,"(.+?)"\);""", js_htm.text)[0] self.__plus_arg = re.findall("""var c=.+?\(e,"(.+?)"\);""", js_htm.text)[0] return self.__plus_arg def _md5(self,x): return hashlib.md5(x.encode("utf-8")).hexdigest() def _base64_decode(self,x): return str(base64.b64decode(x))[2:-1] def jiandan_decrypt(self,farg,sarg="",e=0): f = "DECODE" r = 4 sarg = self._md5(sarg) p = self._md5(sarg[0:16]) # o = _md5(sarg[16:32]) if r and f == "DECODE": m = farg[0:r] else: m = "" c = p + self._md5( p + m ) if f == "DECODE": n = farg[r:] l = self._base64_decode(n) b = [] for h in range(256): tmp_n = h % len(c) b.append(ord(c[tmp_n])) k = list(range(256)) g = 0 for h in range(256): g = (g +k[h] + b[h]) % 256 k[h],k[g] = k[g],k[h] u = "" # l = l.split() q = 0 g = 0 for h in range(len(l)): q = (q+1) % 256 g = (g+k[q]) % 256 k[q],k[g] = k[g],k[q] u += chr(ord(l[h]) ^ (k[(k[q] + k[g]) % 256])) u = self._base64_decode(farg) return u jiandan = Jiandan() # print(jiandan.get_plus_arg())
# -*- coding:utf-8 -*- import logging import os LOG_LEVEL = logging.INFO LOG_TYPES = { 'page_html': 'page_html.log', 'pic_html': 'pic_html.log', 'image':"image.log" } LOG_FILES_DIR = os.path.join("D:\Python相关\项目\爬虫_scrapy\cl\cl","log") def logger(log_type): # create logger logger = logging.getLogger(log_type) logger.setLevel(LOG_LEVEL) # create console handler and set level to debug ch = logging.StreamHandler() ch.setLevel(LOG_LEVEL) # create file handler and set level to warning log_file = os.path.join(LOG_FILES_DIR,LOG_TYPES[log_type]) fh = logging.FileHandler(log_file) fh.setLevel(LOG_LEVEL) # create formatter formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # add formatter to ch and fh ch.setFormatter(formatter) fh.setFormatter(formatter) # add ch and fh to logger logger.addHandler(ch) # #logger对象可以添加多个fh和ch对象 logger.addHandler(fh) return logger def file_logger(log_type): # create logger logger = logging.getLogger(log_type) logger.setLevel(LOG_LEVEL) # create console handler and set level to debug # ch = logging.StreamHandler() # ch.setLevel(LOG_LEVEL) # create file handler and set level to warning log_file = os.path.join(LOG_FILES_DIR,LOG_TYPES[log_type]) fh = logging.FileHandler(log_file) fh.setLevel(LOG_LEVEL) # create formatter formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # add formatter to ch and fh # ch.setFormatter(formatter) fh.setFormatter(formatter) # add ch and fh to logger # logger.addHandler(ch) # #logger对象可以添加多个fh和ch对象 logger.addHandler(fh) return logger
# -*- coding:utf-8 -*- from scrapy.cmdline import execute import sys,os sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy", "crawl", "jiandan","--nolog"])

附:笔记爬虫_自己写的笔记
其他:https://blog.csdn.net/cxylvping/article/details/80624130

 浙公网安备 33010602011771号
浙公网安备 33010602011771号