golang_语言基础
目录
int
float
bool
string
struct
interface
关键字与保留字
25个关键字
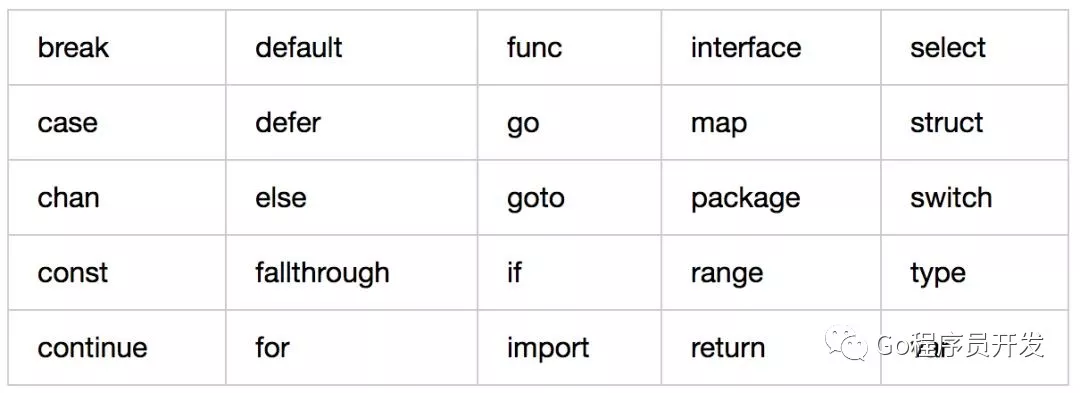
关键字用途
var :用于变量的声明
const :用于常量的声明
type :用于声明类型
func :用于声明函数和方法
package :用于声明包文件
import :用于导入其它package
return :用于从函数返回
defer :延迟调用,在函数退出之前执行
go :创建一个协程
select :用于选择不同类型的通讯
interface :用于定义接口
struct :用于定义数据类型
break、case、continue、for、fallthrough、else、if、switch、goto、default :用于流程控制
chan :用于声明chan类型数据
map :用于声明map类型数据
range :用于遍历array、slice、map、channel数据
37个保留字

变量声明
变量声明
// 变量初始化的标准格式 var 变量名 类型 = 表达式 // 短变量声明并初始化 变量名 := 表达式
// 匿名变量“_”
补充:
单个变量的声明
go语言中,所有变量都必须先声明在使用,下面是声明变量和赋值方法:
- 先声明后赋值: var <变量名称> <变量类型> 赋值:变量的赋值格式: <变量名称> = <表达式>
- 声明的同时赋值:var <变量名称> <变量类型> = <表达式> (简写为 变量名称 := 表达式)
多个变量声明
- 先声明后赋值:var <变量1>,<变量2>,<变量3> <变量类型> 赋值 : <变量1>,<变量2> = 值1,值2
- 声明同时赋值 :var <变量1>,<变量2> = 值1,值2 可简写为: <变量1>,<变量2> = 值1,值2
- 多个变量还可以使用var()声明
变量名
命名原则:
- 首字符可以是任意的Unicode字符或者下划线
- 剩余字符可以是Unicode字符、下划线、数字
- 不能作为用以下关键字作为变量名
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var
可见性
可见性即对包外可见,当其他包调用当前包的变量时候是否允许可见(可访问)。
- 变量开头字符大写,表示可见
- 变量开头字母非大写,则表示私有,不可见
变量的作用域
- 函数内定义的变量称为局部变量,其作用域在函数内
- 函数外定义的变量称为全局变量,作用于整个包,并且该变量首字母大写,则对其他包可见
例子
// 变量要先声明,再赋值 // 声明: var a int // 声明 int 类型的变量 var b [10] int // 声明 int 类型数组 var c []int // 声明 int 类型的切片 var d *int // 声明 int 类型的指针 // 赋值: a = 10 b[0] = 10 // 同时声明与赋值 var a = 10 a := 10
// 多个变量同时声明赋值 a,b,c,d := 1,2,true,"def"
// 交换
a,b = b,a
常量声明
const filename = "ab"
const a,b = 3,4 // 常量可作为各种类型调用,此处即可用作int类型,也可用作 float
const(
java = 1
php = 2
python = 3
)
const(
java = iota // 自增值,初始为0
php
python
)
// 注意:iota是根据自己在const的位置给出对应的值
const(
x = iota // 自增值,初始为0
y
z
)
// 此处是0 1 2
const(
i = 10 // 自增值,初始为0
j = "jjjjjj"
k = iota
l
)
// 此处是10 "jjjjjj" 2 3
常用数据类型
内置类型
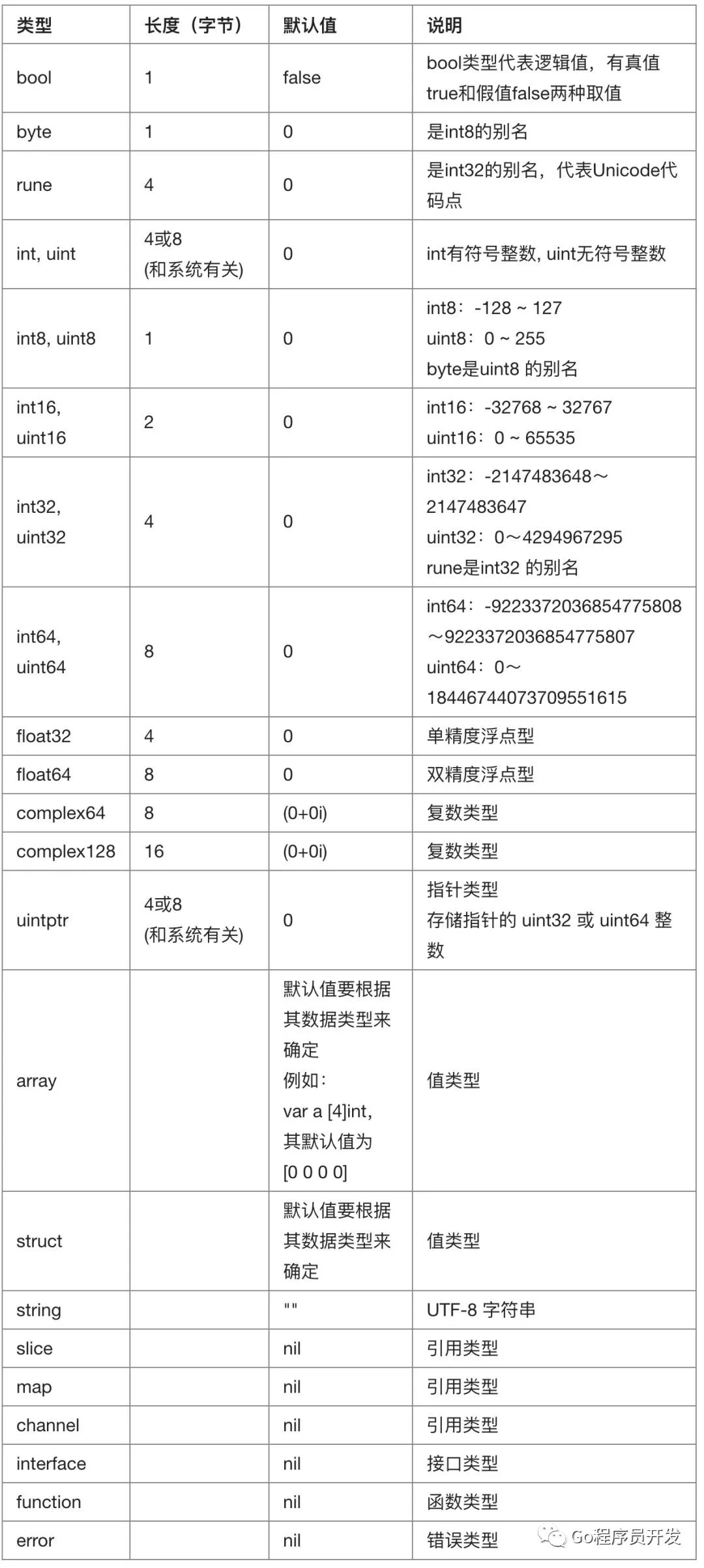
指针
指针(pointer)概念在 Go 语言中被拆分为两个核心概念: - 类型指针,允许对这个指针类型的数据进行修改。传递数据使用指针,而无须拷贝数据。类型指针不能进行偏移和运算。 - 切片,由指向起始元素的原始指针、元素数量和容量组成。
格式:
ptr := &v // v的类型为T
// 其中 v 代表被取地址的变量,被取地址的 v 使用 ptr 变量进行接收,ptr 的类型就为*T,称做 T 的指针类型。*代表指针。
取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址(&)操作,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
数值型数据
int
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 还有对应的无符号整型:uint8、uint16、uint32、uint64 其中,uint8 就是我们熟知的 byte 型,int16 对应C语言中的 short 型,int64 对应C语言中的 long 型。
| min | max | ||
| int8 |
-128 = - 2**7 |
127 = 2**7 - 1 |
math.MinInt8, math.MaxInt8 |
| int16 |
-32768 = – 2**15 |
32767 = 2**15 - 1 |
math.MinInt16, math.MaxInt16 |
| int32 |
-2147483648 = – 2**31 |
2147483647 = 2**31 - 1 |
math.MinInt32, math.MaxInt32 |
| int64 |
-9223372036854775808 = – 2**63 |
9223372036854775807 = 2**63 - 1 |
math.MinInt64, math.MaxInt64 |
| uint8 | 0 | 255 = 2**8 - 1 | |
| uint16 | 0 | 65535 = 2**16 - 1 | |
| uint32 | 0 | 4294967295 = 2**32 - 1 | |
| uint64 | 0 | 18446744073709551615 = 2**64 - 1 |
float
Go语言支持两种浮点型数:float32 和 float64。这两种浮点型数据格式遵循 IEEE 754 标准: float32 的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32。 float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
配合fmt包%f打印float
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f\n", math.Pi)
fmt.Printf("%.2f\n", math.Pi)
}
bool
布尔型数据在 Go 语言中以 bool 类型进行声明,布尔型数据只有 true(真)和 false(假)两个值。
string
表示符
string表示符 单行:双引号"" 多行:反引号``
rune表示:单引号''
转义符
| 转移符 | 含 义 |
|---|---|
| \r | 回车符(返回行首) |
| \n | 换行符(直接跳到下一行的同列位置) |
| \t | 制表符 |
| \' | 单引号 |
| \" | 双引号 |
| \\ | 反斜杠 |
类型
Go 语言的字符有以下两种: byte型:一种是 uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。 rune型:另一种是 rune 类型,代表一个 UTF-8 字符。当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型实际是一个 int32。
golang里默认string是一个[]byte的array
打印验证字符串类型
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
var a byte = 'a'
// 注意,使用的是%d
fmt.Printf("data:%d type:%T\n", a, a)
// data:97 type:uint8
//var a2 byte = '你'
//fmt.Printf("data:%v type:%T\n", a2, a2)
// 报错
//# command-line-arguments
//.\test.go:10:16: constant 20320 overflows byte
var b rune = 'a'
// 注意,使用的是%d
fmt.Printf("data:%d type:%T\n", b, b)
// data:97 type:int32
var b2 rune = '你'
// 注意,使用的是%d
fmt.Printf("data:%d type:%T\n", b2, b2)
// data:20320 type:int32
var c string = "hello世界"
// 注意,使用的是%s
fmt.Printf("data:%s type:%T len:%d\n", c, c,len(c))
// data:hello世界 type:string len:11
// 这里的长度是11,英文长度是1byte,中文是3byte
var d string = "hello世界"
for index,x := range d {
fmt.Printf("index:%d data:%v string:%v len:%d\n",index,x,string(x),len(string(x)))
}
//index:0 data:104 string:h len:1
//index:1 data:101 string:e len:1
//index:2 data:108 string:l len:1
//index:3 data:108 string:l len:1
//index:4 data:111 string:o len:1
//index:5 data:19990 string:世 len:3
//index:8 data:30028 string:界 len:3
var e []rune = []rune(d)
fmt.Printf("data:%v string:%v len:%d\n",e,string(e),len(e))
//data:[104 101 108 108 111 19990 30028] string:hello世界 len:7
for index,x := range e {
fmt.Printf("index:%d data:%v string:%v len:%d\n",index,x,string(x),len(string(x)))
}
//index:0 data:104 string:h len:1
//index:1 data:101 string:e len:1
//index:2 data:108 string:l len:1
//index:3 data:108 string:l len:1
//index:4 data:111 string:o len:1
//index:5 data:19990 string:世 len:3 // 因为转为string后就变[]byte了,长度为3byte
//index:6 data:30028 string:界 len:3
// index已变成
var f string = "hello世界"
fmt.Printf("len([]byte):%v\n",len([]byte(f)))
fmt.Printf("len(str):%v\n",len(f))
fmt.Printf("RuneCountInString:%v\n",utf8.RuneCountInString(f))
//len([]byte):11
//len(str):11
//RuneCountInString:7
}
struct
interface
引用型数据
array
C语言和 Go 语言中的数组概念完全一致。C语言的数组也是一段固定长度的内存区域,数组的大小在声明时固定下来。
语法
var 数组变量名 [元素数量]T - 数组变量名:数组声明及使用时的变量名。 - 元素数量:数组的元素数量。可以是一个表达式,但最终通过编译期计算的结果必须是整型数值。也就是说,元素数量不能含有到运行时才能确认大小的数值。一旦定义,长度不可改变。 - T 可以是任意基本类型,包括 T 为数组本身。但类型为数组本身时,可以实现多维数组。
- 注意:var a[5] int 和 var a[10] int是不同类型的
- array是值类型,因此,作为函数参数时会复制一份副本,修改副本不会改变本身的值。当然,可以通过传入内存地址以修改该内存地址存放的值
使用


package main
import "fmt"
func main(){
var a [10]int
fmt.Println(a)
var b = [5]int{1,2,3,4,5}
fmt.Println(b)
var c = [...]int{11,12,13,14}
fmt.Println(c)
var str = [5]string{2:"hello world",4:"tom"}
fmt.Println(str)
}
//[0 0 0 0 0 0 0 0 0 0]
//[1 2 3 4 5]
//[11 12 13 14]
//[ hello world tom]
package main
import "fmt"
func main(){
var a [5][3]int
fmt.Println(a)
var b [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}
fmt.Println(b)
}
//[[0 0 0] [0 0 0] [0 0 0] [0 0 0] [0 0 0]]
//[[1 2 3] [7 8 9]]
string实际是[]byte类型的array
string是不可以修改的,那么,如何对string进行“修改”呢?把string转换为[]byte的array,修改其中元素,再转回string,但已经是另一内存下的string了
package main
import "fmt"
func main() {
str := "hello world"
fmt.Println(str)
s := []byte(str)
s[0] = '0'
str = string(s)
fmt.Println(str)
}
//hello world
//0ello world
slice
切片(Slice)是一个拥有相同类型元素的可变长度的序列。Go 语言切片的内部结构包含地址、大小和容量。切片一般用于快速地操作一块数据集合。如果将数据集合比作切糕的话,切片就是你要的“那一块”。切的过程包含从哪里开始(这个就是切片的地址)及切多大(这个就是切片的大小)。容量可以理解为装切片的口袋大小,如下图所示。
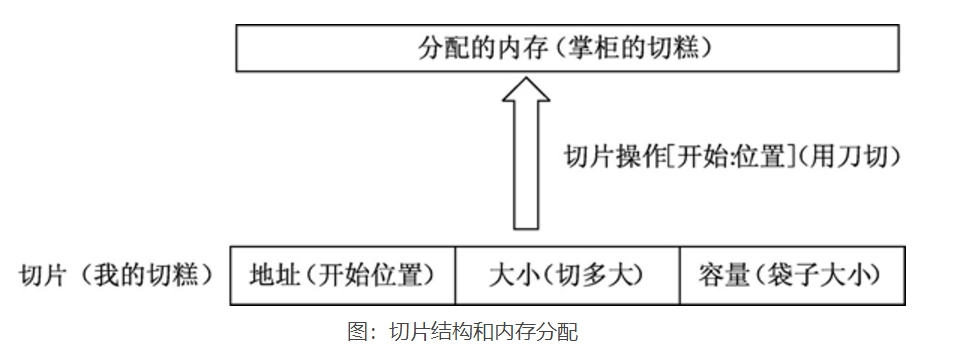
说明
1. 切片:切片是数组的一个引用,因此切片是引用类型 2. 切片的长度可以改变,因此,切片是一个可变的数组 3. 切片遍历方式和数组一样,可以用len()求长度 4. cap可以求出slice最大的容量,0 <= len(slice) <= (array),其中array是slice引用的数组 5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int
内存说明
通过array生成的slice
在slice的cap范围下,修改slice的同时,原本的array也会改变。
package main
import "fmt"
func main() {
a := [5]int{0,1,2,3,4}
b := a[1:3]
// 对应元素的内存地址相同
fmt.Printf("a[1]=%p\nb[0]=%p\n",&(a[1]),&b[0])
// b的cap(b)=cap(a)-b的开始index,此处是5-1=4,意味着如果b超过4个元素,则需要另起一块内存已扩容,见下面验证
fmt.Printf("b=%v &b=%p cap(b)=%d len(b)=%d\n",b,&b,cap(b),len(b))
//a[1]=0xc04203df58
//b[0]=0xc04203df58
//b=[1 2] &b=0xc042040400 cap(b)=4 len(b)=2
// 增加至4个元素,b的元素内存地址还是与a相等的
b = append(b,10,11)
fmt.Printf("a[1]=%p\nb[0]=%p\n",&(a[1]),&b[0])
fmt.Printf("b=%v &b=%p cap(b)=%d len(b)=%d\n",b,&b,cap(b),len(b))
fmt.Println(a)
//a[1]=0xc04203df58
//b[0]=0xc04203df58
//b=[1 2 10 11] &b=0xc042040400 cap(b)=4 len(b)=4
//[0 1 2 10 11]
// 增加至5个,元素的内存地址不一致了
b = append(b,12)
fmt.Printf("a[1]=%p\nb[0]=%p\n",&(a[1]),&b[0])
fmt.Printf("b=%v &b=%p cap(b)=%d len(b)=%d\n",b,&b,cap(b),len(b))
fmt.Println(a)
//a[1]=0xc04203df58
//b[0]=0xc0420420c0
//b=[1 2 10 11 12] &b=0xc042040400 cap(b)=8 len(b)=5
//[0 1 2 10 11]
}
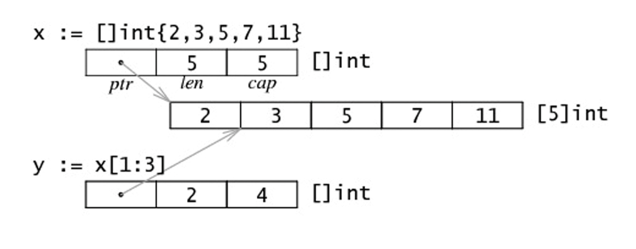
使用make创建的slice
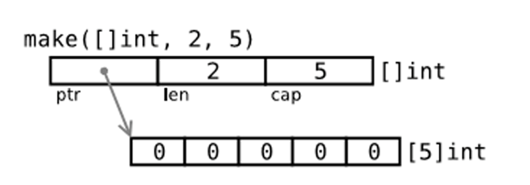
使用
package main
import "fmt"
func main() {
// 声明字符串切片
var strList []string
// 声明整型切片
var numList []int
// 声明一个空切片
var numListEmpty = []int{}
// 输出3个切片
fmt.Println(strList, numList, numListEmpty)
// 输出3个切片大小
fmt.Println(len(strList), len(numList), len(numListEmpty))
// 切片判定空的结果
fmt.Println(strList == nil)
fmt.Println(numList == nil)
fmt.Println(numListEmpty == nil)
}
//[] [] []
//0 0 0
//true
//true
//false
make( []T, size, cap )
T:切片的元素类型。
size:就是为这个类型分配多少个元素。
cap:预分配的元素数量,这个值设定后不影响 size,只是能提前分配空间,降低多次分配空间造成的性能问题。
package main
import "fmt"
func main() {
a := make([]int, 2)
fmt.Println(a)
fmt.Println(a == nil)
}
//[0 0]
//false
package main
import "fmt"
func main() {
var a [5]string
fmt.Println(a)
a[0] = "h"
a[1] = "e"
a[2] = "l"
a[3] = "l"
a[4] = "o"
fmt.Println(a)
a1 := a[1:5]
fmt.Println(a1)
a2 := a1[0:2]
fmt.Println(a2)
}
//[ ]
//[h e l l o]
//[e l l o]
//[e l]
append
package main
import "fmt"
func main() {
var car []string
// 添加1个元素
car = append(car, "OldDriver")
// 添加多个元素
car = append(car, "Ice", "Sniper", "Monk")
// 添加切片,必须同一类型
team := []string{"Pig", "Flyingcake", "Chicken"}
car = append(car, team...)
fmt.Println(car)
}
//[OldDriver Ice Sniper Monk Pig Flyingcake Chicken]
copy
copy( destSlice, srcSlice []T) int - srcSlice 为数据来源切片。 - destSlice 为复制的目标。目标切片必须分配过空间且足够承载复制的元素个数。来源和目标的类型一致,copy 的返回值表示实际发生复制的元素个数。
package main
import "fmt"
func main() {
slice1 := []int{1,2,3,4,5,}
slice2 := []int{0,0,0,1,2,3,4,5,6,7}
copy(slice2,slice1)
fmt.Println(slice1)
fmt.Println(slice2)
}
//[1 2 3 4 5]
//[1 2 3 4 5 3 4 5 6 7]
删除(没有专门的delete方法)
package main
import "fmt"
func main() {
seq := []string{"a", "b", "c", "d", "e"}
// 指定删除位置
index := 2
// 查看删除位置之前的元素和之后的元素
fmt.Println(seq[:index], seq[index+1:])
// 将删除点前后的元素连接起来
seq = append(seq[:index], seq[index+1:]...)
fmt.Println(seq)
}
//[a b] [d e]
//[a b d e]
map
Go 语言提供的映射关系容器为 map,map使用散列表(hash)实现。
散列表:可以简单描述为一个数组(俗称“桶”),数组的每个元素是一个列表。根据散列函数获得每个元素的特征值,将特征值作为映射的键。如果特征值重复,表示元素发生碰撞。碰撞的元素将被放在同一个特征值的列表中进行保存。散列表查找复杂度为 O(1),和数组一致。最坏的情况为 O(n),n 为元素总数。散列需要尽量避免元素碰撞以提高查找效率,这样就需要对“桶”进行扩容,每次扩容,元素需要重新放入桶中,较为耗时。 平衡树:类似于有父子关系的一棵数据树,每个元素在放入树时,都要与一些节点进行比较。平衡树的查找复杂度始终为 O(log n)。
语法
map[KeyType]ValueType
- KeyType为键类型。
- ValueType是键对应的值类型。
- map作为参数时是引用类型
必须先声明类型,声明不会分配内存,初始化需要make
var a map[string]string
var a map[string]int
var a map[int]string
var a map[string]map[string]string // 可以嵌套多个
使用
package main
import "fmt"
func main(){
m := map[string]string{
"W": "forward",
"A": "left",
"D": "right",
"S": "backward",
}
fmt.Println(m)
}
// map[W:forward A:left D:right S:backward]
package main
import "fmt"
func main(){
//scene := make(map[string]int)
var scene map[string]int
scene = make(map[string]int)
scene["route"] = 66
fmt.Println(scene["route"])
}
package main
import "fmt"
func main(){
scene := make(map[string]int)
scene["route"] = 66
fmt.Println(scene["route"])
v := scene["route2"] // 没有,则返回0
fmt.Println(v)
}
package main
import "fmt"
func main(){
m := map[string]string{
"W": "forward",
"A": "left",
"D": "right",
"S": "backward",
}
fmt.Println(m)
for k,v := range m {
fmt.Println(k,v)
}
}
//map[D:right S:backward W:forward A:left]
//W forward
//A left
//D right
//S backward
语法
delete(map, 键)
package main
import "fmt"
func main(){
m := map[string]string{
"W": "forward",
"A": "left",
"D": "right",
"S": "backward",
}
fmt.Println(m)
delete(m,"A")
fmt.Println(m)
}
//map[W:forward A:left D:right S:backward]
//map[W:forward D:right S:backward]
chan
channel可分为三种类型: 只读channel:只能读channel里面数据,不可写入 只写channel:只能写数据,不可读 一般channel:可读可写 注意: 需要注意的是: - 管道如果未关闭,在读取超时会则会引发deadlock异常 - 管道如果关闭进行写入数据会pannic - 当管道中没有数据时候再行读取或读取到默认值,如int类型默认值是0
详见https://www.cnblogs.com/fat39/p/10332339.html#chan
类型转换
T(表达式)
举例
后补
运算符
运算符用于在程序运行时执行数学或逻辑运算。
Go 语言内置的运算符有:算术运算符、关系运算符、逻辑运算符、位运算符、赋值运算符、其他运算符。
算术运算符
| 运算符 | 描述 |
|---|---|
|
+ |
相加 |
|
- |
相减 |
|
* |
相乘 |
|
/ |
相除 |
|
% |
求余 |
|
++ |
自增 |
|
-- |
自减 |
关系运算符
| 运算符 | 描述 |
|---|---|
|
== |
检查两个值是否相等,如果相等返回 True 否则返回 False。 |
|
!= |
检查两个值是否不相等,如果不相等返回 True 否则返回 False。 |
|
> |
检查左边值是否大于右边值,如果是返回 True 否则返回 False。 |
|
< |
检查左边值是否小于右边值,如果是返回 True 否则返回 False。 |
|
>= |
检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 |
|
<= |
检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 |
逻辑运算符
| 运算符 | 描述 |
|---|---|
|
&& |
逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 |
|
|| |
逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 |
|
! |
逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 |
位运算符
| 运算符 | 描述 |
|---|---|
|
& |
按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 |
|
| |
按位或运算符"|"是双目运算符。 其功能是参与运算的两数各对应的二进位相或。 |
|
^ |
按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 |
|
<< |
左移运算符"<<"是双目运算符。左移n位就是乘以2的n次方。 其功能把"<<"左边的运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 |
|
>> |
右移运算符">>"是双目运算符。右移n位就是除以2的n次方。 其功能是把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数。 |
赋值运算符
| 运算符 | 描述 |
|---|---|
|
= |
简单的赋值运算符,将一个表达式的值赋给一个左值 |
|
+= |
相加后再赋值 |
|
-= |
相减后再赋值 |
|
*= |
相乘后再赋值 |
|
/= |
相除后再赋值 |
|
%= |
求余后再赋值 |
|
<<= |
左移后赋值 |
|
>>= |
右移后赋值 |
|
&= |
按位与后赋值 |
|
^= |
按位异或后赋值 |
|
|= |
按位或后赋值 |
其他运算符
| 运算符 | 描述 |
|---|---|
|
& |
取地址符,返回变量存储地址 |
|
* |
取值符,返回指针的变量 |
运算符优先级
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
|
7 |
^ ! |
|
6 |
* / % << >> & &^ |
|
5 |
+ - | ^ |
|
4 |
== != < <= >= > |
|
3 |
<- |
|
2 |
&& |
|
1 |
|| |
特殊标识符
“_”是特殊标识符,又称占位符(空标识符号),用来忽略结果。
1、特殊标识符应用在import中
在Go语言里,import的作用是导入其他package。
特殊标识符(如:import _ oldboy/golang)的作用:当导入一个包时,该包下的文件里所有init()函数都会被执行,然而,有些时候我们并不需要把整个包都导入进来,仅仅是是希望它执行init()函数而已。这个时候就可以使用 import _ 引用该包。即使用(import _ 包路径)只是引用该包,仅仅是为了调用init()函数,所以无法通过包名来调用包中的其他函数。
流程控制
if else
语法
if 表达式1 {
分支1
} else if 表达式2 {
分支2
} else{
分支3
}
var ten int = 11
if ten > 10 {
fmt.Println(">10")
} else {
fmt.Println("<=10")
}
// >10
特殊用法
在判断主体里,可进行一次赋值操作
// Connect 是一个带有返回值的函数,err:=Connect() 是一个语句,执行 Connect 后,将错误保存到 err 变量中。
// 只有有一个赋值语句
if err := Connect(); err != nil { fmt.Println(err) return }
package main
import "fmt"
func main(){
if a,b := 99,100;(a+b)>100 {
fmt.Println("hello world")
} else {
fmt.Println("<99")
}
}
// hello world
for
语法
// 其中 初始语句;条件表达式;结束语句 均可以省略
for 初始语句;条件表达式;结束语句{
循环体代码
}
package main
import "fmt"
func main(){
for i := 0; i < 3; i++ {
fmt.Println(i)
}
}
//0
//1
//2
package main
import "fmt"
func main(){
var i int = 3
for {
if i < 0 {
break
}
fmt.Println(i)
i--
}
}
//3
//2
//1
//0
package main
import "fmt"
func main(){
var i int = 3
for i > 0{
fmt.Println(i)
i--
}
}
//3
//2
//1
package main
import "fmt"
func main(){
str := "hello world,您好世界"
for index,value := range str {
// value是ascii
fmt.Printf("index[%d] val[%c] len[%d]\n",index,value,len(string(value)))
//fmt.Printf("index[%d] val[%c] len[%d]\n",index,value,len([]byte(string(value))))
}
}
//index[0] val[h] len[1]
//index[1] val[e] len[1]
//index[2] val[l] len[1]
//index[3] val[l] len[1]
//index[4] val[o] len[1]
//index[5] val[ ] len[1]
//index[6] val[w] len[1]
//index[7] val[o] len[1]
//index[8] val[r] len[1]
//index[9] val[l] len[1]
//index[10] val[d] len[1]
//index[11] val[,] len[1]
//index[12] val[您] len[3]
//index[15] val[好] len[3]
//index[18] val[世] len[3]
//index[21] val[界] len[3]
for range(键值循环)
可以使用 for range 遍历数组、切片、字符串、map 及通道(channel)。通过 for range 遍历的返回值有一定的规律:
- 数组、切片、字符串返回索引和值。
- map 返回键和值。
- 通道(channel)只返回通道内的值。
package main
import "fmt"
func main(){
for key, value := range []int{1, 2, 3, 4} {
fmt.Printf("key:%d value:%d\n", key, value)
}
}
//key:0 value:1
//key:1 value:2
//key:2 value:3
//key:3 value:4
package main
import "fmt"
func main(){
var str = "hello 你好"
for key, value := range str {
fmt.Printf("key:%d value:0x%x\n", key, value)
}
}
//key:0 value:0x68
//key:1 value:0x65
//key:2 value:0x6c
//key:3 value:0x6c
//key:4 value:0x6f
//key:5 value:0x20
//key:6 value:0x4f60
//key:9 value:0x597d
package main
import "fmt"
func main(){
m := map[string]int{
"hello": 100,
"world": 200,
}
for key, value := range m {
fmt.Println(key, value)
}
}
//hello 100
//world 200
package main
import "fmt"
func main(){
c := make(chan int)
go func() {
c <- 1
c <- 2
c <- 3
close(c)
}()
for v := range c {
fmt.Println(v)
}
}
//1
//2
//3
注意:在for range里,在for循环内所有v的都是指向统一内存地址
package main
import "fmt"
func main() {
// slice
arr := []int{1,2,3,4}
fmt.Println("// slice")
for index,value := range arr {
fmt.Printf("%d %p\n",index,&value)
}
// map
m := make(map[string]interface{})
m["a"] = 1
m["b"] = 1.1
m["c"] = "c"
m["d"] = []int{1,2,3,4}
fmt.Println()
fmt.Println("// map")
for k,v := range m {
fmt.Printf("%v %p\n",k,&v)
}
}
//D:\go dev\PROJECT\bin>go run test.go
//// slice
//0 0xc00004a090
//1 0xc00004a090
//2 0xc00004a090
//3 0xc00004a090
//
//// map
//a 0xc00003e1c0
//b 0xc00003e1c0
//c 0xc00003e1c0
//d 0xc00003e1c0
break、continue
与其他语言用法一样 break 终止,跳出本循环 continue 跳过,不执行后面代码,继续执行循环的下一状态
switch case
语法
switch 变量 {
case 变量相关表达式1 :
do sth
case 变量相关表达式2 :
do sth
default :
do sth
}
package main
import "fmt"
func main(){
var a = "hello"
switch a {
case "hello":
fmt.Println(1)
case "world":
fmt.Println(2)
default:
fmt.Println(0)
}
}
// 1
package main
import "fmt"
func main(){
var a = "mum"
switch a {
case "mum", "daddy":
fmt.Println("family")
}
}
// family
package main
import "fmt"
func main(){
var r int = 11
switch {
case r > 10 && r < 20:
fmt.Println(r)
}
}
// 11
package main
import "fmt"
func main(){
var s = "hello"
switch {
case s == "hello":
fmt.Println("hello")
fallthrough
case s != "world":
fmt.Println("world")
fallthrough
case true:
fmt.Println("您好")
default:
fmt.Println("世界")
}
}
// hello
// world
// 您好
goto label
语法
label:
do sth
if xx {
goto label
}
package main
import "fmt"
func main() {
LABELxxx:
for i := 0; i <= 2; i++ {
for j := 0; j <= 2; j++ {
if j == 2 {
continue LABELxxx
}
fmt.Printf("i is: %d, and j is: %d\n", i, j)
}
}
}
//i is: 0, and j is: 0
//i is: 0, and j is: 1
//i is: 1, and j is: 0
//i is: 1, and j is: 1
//i is: 2, and j is: 0
//i is: 2, and j is: 1
package main
func main() {
i := 0
HEREyyy:
print(i)
i++
if i == 5 {
return
}
goto HEREyyy
}
//01234
//package main
//import "fmt"
//func main() {
// var breakAgain bool
// // 外循环
// for x := 0; x < 10; x++ {
// // 内循环
// for y := 0; y < 10; y++ {
// // 满足某个条件时, 退出循环
// if y == 2 {
// // 设置退出标记
// breakAgain = true
// // 退出本次循环
// break
// }
// }
// // 根据标记, 还需要退出一次循环
// if breakAgain {
// break
// }
// }
// fmt.Println("done")
//}
//done
package main
import "fmt"
func main() {
for x := 0; x < 10; x++ {
for y := 0; y < 10; y++ {
if y == 2 {
// 跳转到标签
goto breakHere
}
}
}
// 手动返回, 避免执行进入标签
return
// 标签
breakHere:
fmt.Println("done")
}
//done
err := firstCheckError()
if err != nil {
goto onExit
}
err = secondCheckError()
if err != nil {
goto onExit
}
fmt.Println("done")
return
onExit:
fmt.Println(err)
exitProcess()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号