
RAG 工具和框架介绍: Haystack、 LangChain 和 LlamaIndex

Haystack、 LangChain 和 LlamaIndex,以及这些工具是如何让我们轻松地构建 RAG 应用程序的?
我们将重点关注以下内容:
- Haystack
- LangChain
- LlamaIndex
增强LLM
那么,为什么会有这些工具存在呢?如你所知,ChatGPT和其他LLM是在某个时间点之前的一组数据上进行训练的。更重要的是,它们无法访问诸如你本地机器上的文档等私密信息。
现实场景:
你有一个20GB大小的PDF文件。你不能简单地将其内容复制粘贴到ChatGPT中并期待它能处理。你甚至无法使用OpenAI API向模型输入20GB的数据,因为存在诸多限制。在这种情况下,我们可以将数据创建为数值表示形式(称为向量嵌入),并将其存储在向量数据库中。然后,基于给定查询,我们从向量数据库中查找相关信息,并将这些信息以及原始查询一起作为上下文提供给模型。
RAG与向量嵌入:
检索增强生成(RAG,Retrieval-Augmented Generation)是一种架构,用于通过利用数据源中的相关信息帮助像GPT-4这样的大型语言模型提供更好的响应,同时降低LLM泄露敏感数据或“幻觉”出不正确或误导性信息的可能性。
向量嵌入(Vector Embeddings) 是数据的数值表示形式。RAG架构将用户查询的嵌入与数据源中存储的嵌入进行比较,以找出相似之处。然后将原始用户提示与知识库中相关的上下文拼接,形成最终的增强型提示。这个增强型提示随后被发送给语言模型。
下图显示了文本是如何通过嵌入模型转换成数字表示的:
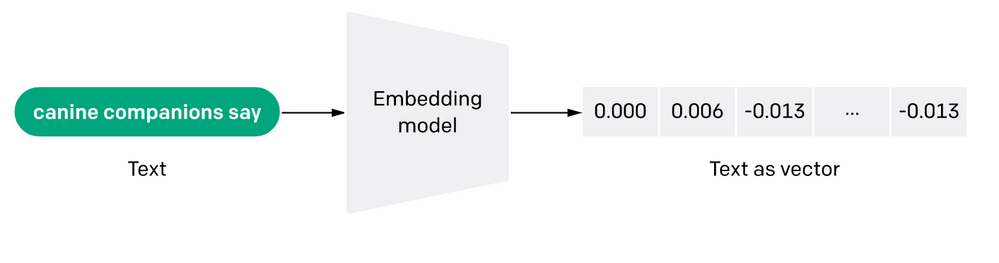
你可以阅读更多关于矢量嵌入的内容:
Ref:https://www.gettingstarted.ai/introduction-to-rag-ai-apps-and-frameworks-haystack-langchain-llamaindex/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号