[PaperReading] Qwen2.5-VL Technical Report
Qwen2.5-VL Technical Report
link
时间:25.02
单位:Qwen
相关领域:多模态理解
作者相关工作:shuai bai
被引次数:1330
项目主页:https://github.com/QwenLM/Qwen2.5-VL
TL;DR
Qwen2.5VL具备杰出的bounding boxes or points定位物体 以及 从表格与发票等文档中提取结构化信息的能力。能够处理动态分辨率图片、编码绝对时序信息,据有事件定位能力。该模型具备处理空间多尺度,时序动态信息能力。通过动态分辨率的ViT以及整合Window Attention,可以降低计算量并保持原生分辨率。Qwen2.5VL擅长静态图片与文档理解,也可作为一个具有推理能力的交互视觉代理。
Method
- LLM:复用Qwen2.5 LLM,使用1D MRoPE来编码位置信息。
- Vision Encoder: 2D RoPE + window attention,图像的长宽被Resize为28的倍数。
- MLP-based Vision-Language Merger: Vision Encoder之后的视觉特征,先压缩相邻4个patch,再过两个MLP,之后与text embedding融合。
![image]()
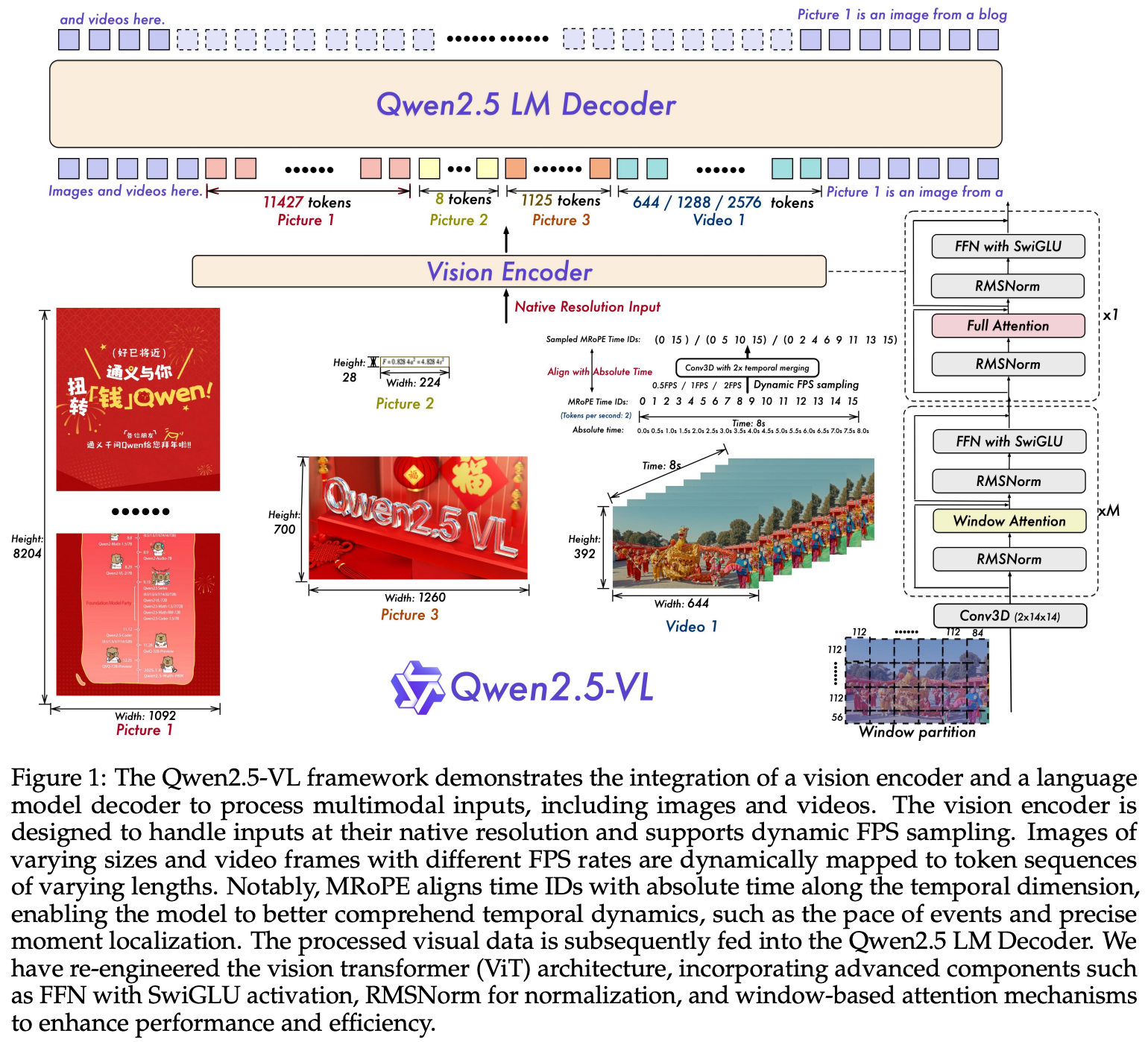
Fast and Efficient Vision Encoder
Window Attention通过将二次复杂度降为线性复杂度来提升效率:对于一个有N个patch的输入,全局自注意力的计算复杂度为O(N²)。而Window Attention将其划分为M个不重叠的窗口(每个窗口有固定数量的K个patch),每个窗口内部独立计算自注意力,总复杂度变为O(M * K²)。由于K是固定值,复杂度最终与patch数量N呈线性关系(O(N)),从而大幅减少了计算量。
MRoPE对齐绝对时间信息
将时序位置ID与绝对时间戳(Absolute Time) 进行对齐。不像Qwen2-VL使用帧序号作为Temperal ID,本工作(Qwen2.5-VL)将Temporal ID转换为帧所对应的真实时间戳(单位为秒)。例如,一个10 FPS的视频,其第5帧(帧号为4,从0开始计算)的Temporal ID不再是4,而是0.4(秒)。
Pre-Training
从1.2T提升至4T,一些数据源的介绍:
Interleaved Image-Text Data
步骤一:标准清洗方法参考,
- 进行主体内容提取,去除广告和无关元素;
- 进行文本初步过滤,剔除低质量文本;
- 进行文档去重和图像下载,并应用尺寸、美学及安全过滤;
- 通过详细文本过滤和人工反馈机制进一步提升质量;
![image]()
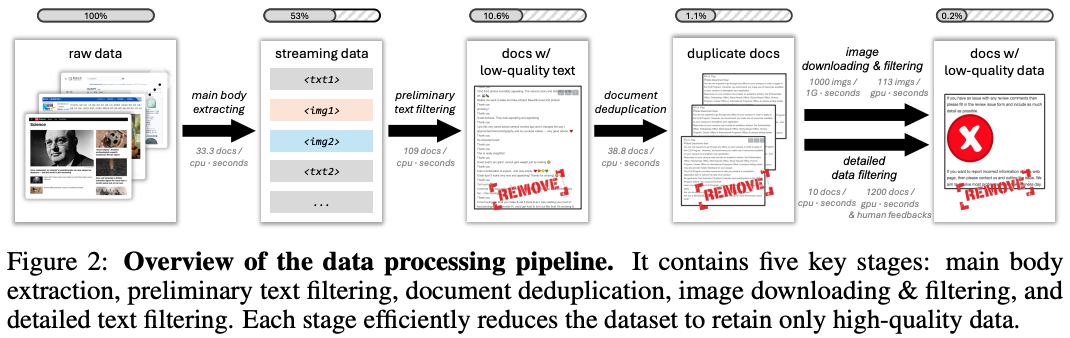
步骤二:
- Text-Only Quality(纯文本质量)
采用与纯文本模型(Qwen2.5)对齐的过滤标准,包括:使用BERT类模型评估文本流畅性、语法正确性 以及 剔除广告与重复文本。 - Image-Text Relevance(图文相关性)
计算图像与相邻文本的CLIP相似度得分,保留高分样本。 - Image-Text Complementarity(图文互补性)
检测图像与文本的信息互补程度,例如,文本描述“制作项链的步骤”,图像展示项链的原材料以及项链成品效果(如何用模型检查暂未想到好办法)。 - Information Density Balance(信息密度平衡)
- 量化配比:控制图文数量比,避免单模态主导。
- 内容密度检测:过滤低信息图像(如纯色背景)或冗余文本(重复描述)。
Grounding Data with Absolute Position Coordinates
- 公开数据集(Public Datasets)
直接利用了现有的大规模目标检测、实例分割和指代理解数据集。这些数据集已包含图像、边界框坐标及对应的文本描述。 - 专有数据(Proprietary Data)
团队内部收集和标注的数据,通常用于弥补公开数据在特定领域或场景下的不足。 - 合成数据(Synthetic Data)
- 基础模型:利用现成的先进模型,如,Grounding DINO(用于开放词汇检测)、SAM(用于精准分割)对海量无标注图像进行自动标注,生成初步的边界框/轮廓和粗略描述。
- 数据增强技术:采用Copy-Paste Augmentation等技术,将物体实例从一个图像复制并粘贴到另一个背景图像中,从而低成本地创造大量新的、多样化的训练样本。
OCR Data
主要靠合成
Video Data
通过帧率下采样来动态控制FPS,同时每帧记录了 秒 或者 hour-minute-second-frame 格式的时间戳信息。
Agent Data
- 数据来源与采集: 原始数据获取(屏幕截图、Log日志、),场景多样性(移动端APP、通用网页)
- 使用方式:可以SFT也可以RL使用。训练数据集中已经包含了大量(截图,指令,正确动作) 的三元组样本。模型的学习目标非常简单直接:给定截图和指令,预测出那个唯一正确的动作。这是一个标准的条件生成任务,使用交叉熵损失进行训练。
![image]()
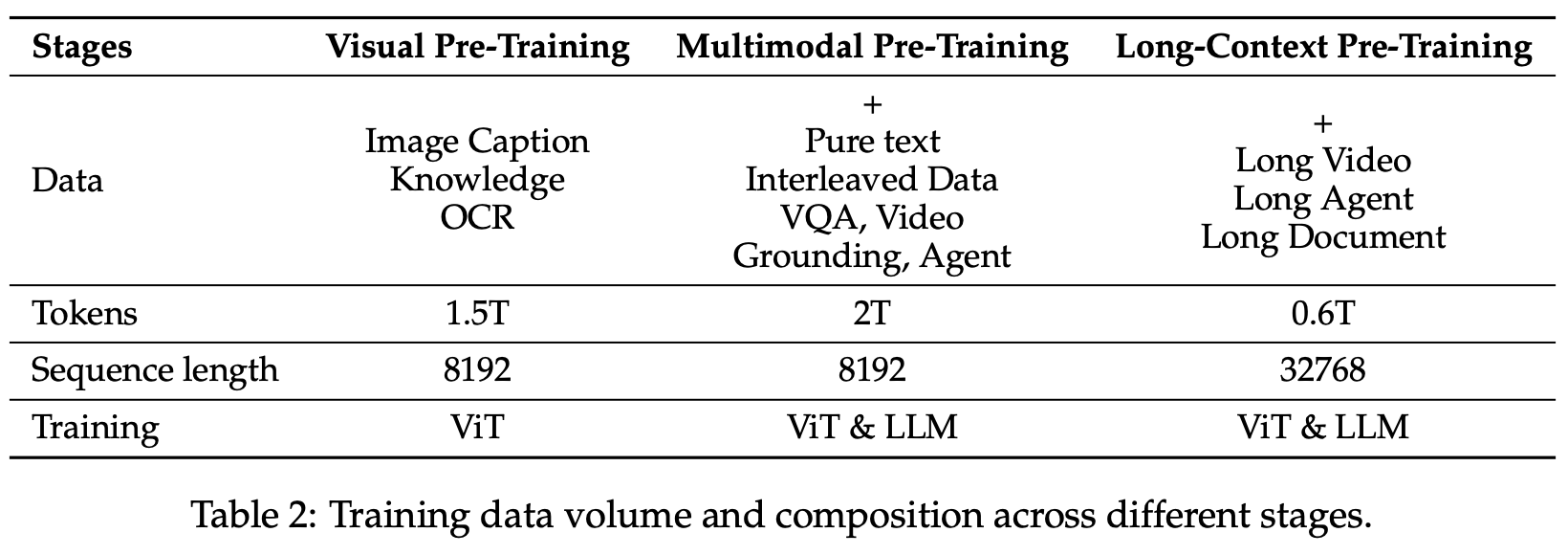
训练流程
Pretrain
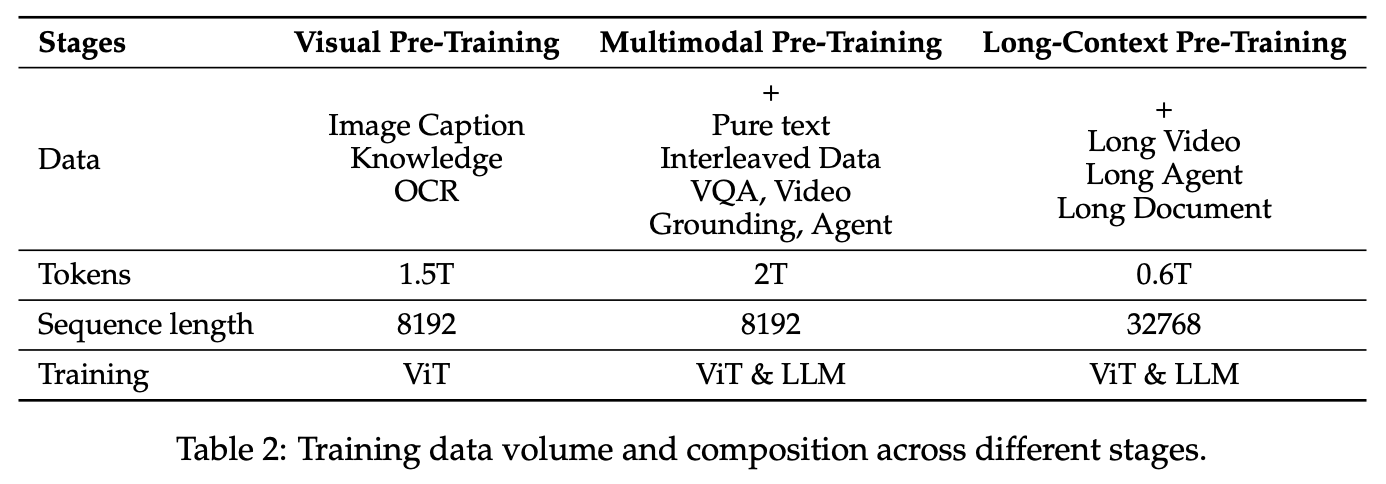
PostTrain
数据清洗Pipeline
阶段一:领域特定分类(Domain-Specific Categorization)
使用专门的分类模型Qwen2-VL-Instag(基于Qwen2-VL-72B)对问答对(QA pairs)进行分层分类。
QA对被组织成8个主要领域(如Coding、Planning等),并进一步细分为30个精细子类别(例如,Coding领域包括Code_Debugging、Code_Generation等)。这种分层结构允许针对每个领域和子类别的特点实施定制化的过滤策略,从而提升SFT数据集的质量和相关性。
阶段二:领域定制过滤(Domain-Tailored Filtering)
该阶段结合了基于规则和基于模型的过滤方法,以全面增强数据质量。针对不同领域(如,文档处理、光学字符识别OCR、视觉定位),采用独特的过滤策略:
- 基于规则的过滤(Rule-Based Filtering):使用预定义启发式规则去除低质量条目。具体包括:
识别并移除重复模式,防止模型学习过程被扭曲。
排除不完整、截断或格式错误的响应(常见于合成数据集和多模态上下文)。
丢弃不相关或可能导致有害输出的查询和答案,以确保数据符合伦理准则和任务特定要求。 - 基于模型的过滤(Model-Based Filtering):利用基于Qwen2.5-VL系列训练的奖励模型对多模态QA对进行多维度评估:
- 查询评估:基于复杂性和相关性,仅保留具有适当挑战性和上下文相关性的样本。
- 答案评估:基于正确性、完整性、清晰度、查询相关性和帮助性进行评分。
Rejection Sampling for Enhanced Reasoning
- 生成多个候选 阶段
采样策略:采用多样性采样(如核采样、温度缩放),确保候选答案覆盖不同解题路径。
- 自我评估筛选 阶段
输入:问题 Q+ 候选答案 \({A_i}\) + 人工标注的高质量参考答案
评估指令:
对比候选答案与参考样本,评估其逻辑严谨性、计算正确性和语言清晰度(1-5分)
- 将筛选后的 {Q, \(A_{selected}\)}加入训练集,替换原始SFT数据中的低质量样本。
Q&A
Q:Grounding与目标检测有什么关系?

CodeReading
代码仓链接:https://github.com/QwenLM/Qwen3-VL
Model
Qwen2_5_VLForConditionalGeneration
继承[Qwen2_5_VLPreTrainedModel、GenerationMixin]
Qwen2_5_VLForConditionalGeneration的核心代码
def __init__(self, config):
# 视觉Encoder定义:由patch_embed与ViT Transformer构成,最后有个Qwen2_5_VLPatchMerger用来减少visual token数量进而减少计算量
self.visual = Qwen2_5_VisionTransformerPretrainedModel._from_config(config.vision_config)
# Qwen2_5_VLModel是LLM的定义:
# self.embed_tokens:nn.Embedding将input_ids转为input_embed
# self.layers有一些Qwen2_5_VLDecoderLayer,Attention的核心实现在里面
self.model = Qwen2_5_VLModel(config)
self.vocab_size = config.vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
pixel_values: Optional[torch.Tensor] = None,
pixel_values_videos: Optional[torch.FloatTensor] = None,
image_grid_thw: Optional[torch.LongTensor] = None,
video_grid_thw: Optional[torch.LongTensor] = None,
rope_deltas: Optional[torch.LongTensor] = None,
cache_position: Optional[torch.LongTensor] = None,
second_per_grid_ts: Optional[torch.Tensor] = None,
) -> Union[Tuple, Qwen2_5_VLCausalLMOutputWithPast]:
# text通过self.model.embed_tokens抽出tokens
inputs_embeds = self.model.embed_tokens(input_ids)
# image通过self.visual抽出tokens
image_embeds = self.visual(pixel_values, grid_thw=image_grid_thw)
# 两者通过下面mask融合成多模态tokens
image_embeds = image_embeds.to(inputs_embeds.device, inputs_embeds.dtype)
outputs = self.model(
input_ids=None,
position_ids=position_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
cache_position=cache_position,
)
hidden_states = outputs[0]
# 最后再过self.lm_head预测logits
logits = self.lm_head(hidden_states)
GenerationMixin的核心代码
封装了所有与自回归生成(AR)相关的逻辑,将文本生成的核心方法通过Mixin注入到子类。
Mixin是一种设计模式(和多重继承类似,只不过mixin父类定义了与子类或其它父类不冲突的方法,将其注入到子类)。
核心是调用generate函数,代码简化如下:
tokenizer = kwargs.pop("tokenizer", None) # Pull this out first, we only use it for stopping criteria
...
generation_config, model_kwargs = self._prepare_generation_config(
generation_config, use_model_defaults, **kwargs
)
# 3. Define model inputs
inputs_tensor, model_input_name, model_kwargs = self._prepare_model_inputs(
inputs, generation_config.bos_token_id, model_kwargs
)
...
# 让模型永远有 mask 可用,且格式最优
model_kwargs["attention_mask"] = self._prepare_attention_mask_for_generation(
inputs_tensor, generation_config, model_kwargs
)
...
input_ids = inputs_tensor if model_input_name == "input_ids" else model_kwargs.pop("input_ids")
# 提前把 KV 缓存的容器准备好,尺寸一步到位
self._prepare_cache_for_generation(
generation_config, model_kwargs, assistant_model, batch_size, max_cache_length, device
)
# 8. determine generation mode
generation_mode = generation_config.get_generation_mode(assistant_model)
# 9. prepare logits processors and stopping criteria
# 把 temperature、top-k、top-p、重复惩罚等全部排好队,等着改 logits
prepared_logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_length,
encoder_input_ids=inputs_tensor,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
device=inputs_tensor.device,
model_kwargs=model_kwargs,
negative_prompt_ids=negative_prompt_ids,
negative_prompt_attention_mask=negative_prompt_attention_mask,
)
# 告诉循环什么时候该 break
prepared_stopping_criteria = self._get_stopping_criteria(
generation_config=generation_config, stopping_criteria=stopping_criteria, tokenizer=tokenizer, **kwargs
)
# ... Qwen-VL推理时生成方式为Greedy,训练时是并行计算“每个位置都看到正确答案的前缀,然后只预测下一个 token”
elif generation_mode in (GenerationMode.SAMPLE, GenerationMode.GREEDY_SEARCH):
# 11. expand input_ids with `num_return_sequences` additional sequences per batch
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_return_sequences,
is_encoder_decoder=self.config.is_encoder_decoder,
**model_kwargs,
)
# 12. run sample (it degenerates to greedy search when `generation_config.do_sample=False`)
result = self._sample(
input_ids,
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
generation_config=generation_config,
synced_gpus=synced_gpus,
streamer=streamer,
**model_kwargs,
)
Data
通过make_supervised_data_module调用LazySupervisedDataset与DataCollatorForSupervisedDataset两个类组成,分别用来。。。
LazySupervisedDataset
def __init__(self, processor, data_args):
super(LazySupervisedDataset, self).__init__()
dataset = data_args.dataset_use.split(",")
dataset_list = data_list(dataset)
...
list_data_dict = []
for data in dataset_list:
file_format = data["annotation_path"].split(".")[-1]
# 加载每条数据
if file_format == "jsonl":
annotations = read_jsonl(data["annotation_path"])
else:
annotations = json.load(open(data["annotation_path"], "r"))
sampling_rate = data.get("sampling_rate", 1.0)
if sampling_rate < 1.0:
annotations = random.sample(
annotations, int(len(annotations) * sampling_rate)
)
rank0_print(f"sampling {len(annotations)} examples from dataset {data}")
else:
rank0_print(f"dataset name: {data}")
for ann in annotations:
if isinstance(ann, list):
for sub_ann in ann:
sub_ann["data_path"] = data["data_path"]
else:
ann["data_path"] = data["data_path"]
list_data_dict += annotations
...
random.shuffle(list_data_dict) # Randomly shuffle the data for training
...
# 在init中并把所有数据内容都加载进来了,除了图像、视频、音频等占用巨大内存的模态在后面preprocess_qwen_visual中的apply_chat_template才实际加载(因为该函数是在get_item中根据sample出的index才调用的)。
self.list_data_dict = list_data_dict
if data_args.data_packing:
# 处理source列表
self.item_fn = self._get_packed_item
else:
# 处理单个source样本
self.item_fn = self._get_item
def _get_item(self, sources) -> Dict[str, torch.Tensor]:
# 该函数负责将对话消息转换为模型训练格式,包括tokenization和标签生成。
data_dict = preprocess_qwen_visual(
sources,
self.processor,
)
...
# 在数据加载阶段预先计算位置编码,与Qwen2_5_VLForConditionalGeneration模型定义的get_rope_index函数实现几乎相同,只不过_get_item中的用于训练过程生成位置编码,而模型定义中的get_rope_index用于在推理或者测试的时候生成位置编码。
position_ids, _ = self.get_rope_index(
self.merge_size,
data_dict["input_ids"],
image_grid_thw=torch.cat(grid_thw, dim=0) if grid_thw else None,
video_grid_thw=(
torch.cat(video_grid_thw, dim=0) if video_grid_thw else None
),
second_per_grid_ts=second_per_grid_ts if second_per_grid_ts else None,
)
data_dict["position_ids"] = position_ids
data_dict["attention_mask"] = [seq_len]
return data_dict
实际加载图像/视频的操作在apply_chat_template函数中执行
def preprocess_qwen_visual(
sources,
processor,
) -> Dict:
# 提取数据路径并构建消息格式,包含图像/视频路径信息
source = sources[0]
base_path = Path(source.get("data_path", ""))
messages = _build_messages(source, base_path)
# 加载图像/视频文件(从路径到像素数据);应用聊天模板格式;进行tokenization;返回包含输入张量的字典
full_result = processor.apply_chat_template(
messages, tokenize=True, return_dict=True, return_tensors="pt"
)
input_ids = full_result["input_ids"]
...
labels = torch.full_like(input_ids, IGNORE_INDEX)
input_ids_flat = input_ids[0].tolist()
L = len(input_ids_flat)
pos = 0
while pos < L:
# 77091:这是Qwen模型中标记助手回答开始的特殊token
if input_ids_flat[pos] == 77091:
ans_start = pos + 2
ans_end = ans_start
# 151645:这是标记助手回答结束的特殊token
while ans_end < L and input_ids_flat[ans_end] != 151645:
ans_end += 1
if ans_end < L:
# 只对助手回答的部分设置真实标签
labels[0, ans_start : ans_end + 2] = input_ids[
0, ans_start : ans_end + 2
]
# 一个sample中可能存在多轮对话情况,继续找有没有助手后续回答的内容
pos = ans_end
pos += 1
full_result["labels"] = labels
full_result["input_ids"] = input_ids
return full_result
DataCollatorForSupervisedDataset
这个类是一个数据整理器(Data Collator),用于将多个训练样本组合成一个批次(batch)作为模型输入。
@dataclass
class DataCollatorForSupervisedDataset(object):
"""Collate examples for supervised fine-tuning."""
tokenizer: transformers.PreTrainedTokenizer
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
...
batch = dict(
input_ids=input_ids,
labels=labels,
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
)
batch["pixel_values"] = concat_images # 拼接后的图像像素值
batch["image_grid_thw"] = grid_thw # 图像时空网格信息
batch["pixel_values_videos"] = concat_videos # 拼接后的视频像素值
batch["video_grid_thw"] = video_grid_thw # 视频时空网格信息
batch["position_ids"] = position_ids # 位置ID信息
return batch
可以看到DataLoader返回的字段较少,所有上面Model forward中传入的参数很多都是None。
Q:为什么有position_ids还需要传入image_grid_thw?
A:两者用来作不同事情:position_ids用来编码token的时空位置信息;image_grid_thw用来标记visual_token之间Window划分关系,方便后续计算WindowAttention。
Q&A
Q:position_ids,input_ids与attention_mask三者分别是什么,有什么关系?
- input_ids是文本的数字化表示,position_ids为每个token提供位置信息(在多模态中考虑时空维度),attention_mask标识有效token与填充位置。
- 三者形状相同且一一对应,共同构成模型输入:input_ids提供内容,position_ids提供位置感知,attention_mask控制注意力范围,确保模型正确处理序列。
Q:Attention与CausalAttention有什么区别?
A:
- 标准Attention:允许所有位置之间相互关注,适用于编码器
- CausalAttention:使用因果掩码,每个位置只能关注当前位置及之前的位置,防止信息泄露,适用于自回归生成任务
在Qwen3-VL中,语言解码器使用CausalAttention确保生成过程的因果性,而视觉编码器可能使用标准Attention或者WindowAttention。
Q:为什么Qwen2.5VL的模型核心代码被放到了transformers的库里,而非Qwen2.5的代码仓里面?
- 标准化集成:Hugging Face transformers是业界标准,便于用户直接使用
- 维护效率:避免重复实现基础组件,专注于核心创新
里面LoRA是如何实现的?
Qwen中所使用的flash attention2与普通的flash attention有什么区别?
Experiment
72B大模型相对于7B/3B小模型强了不少
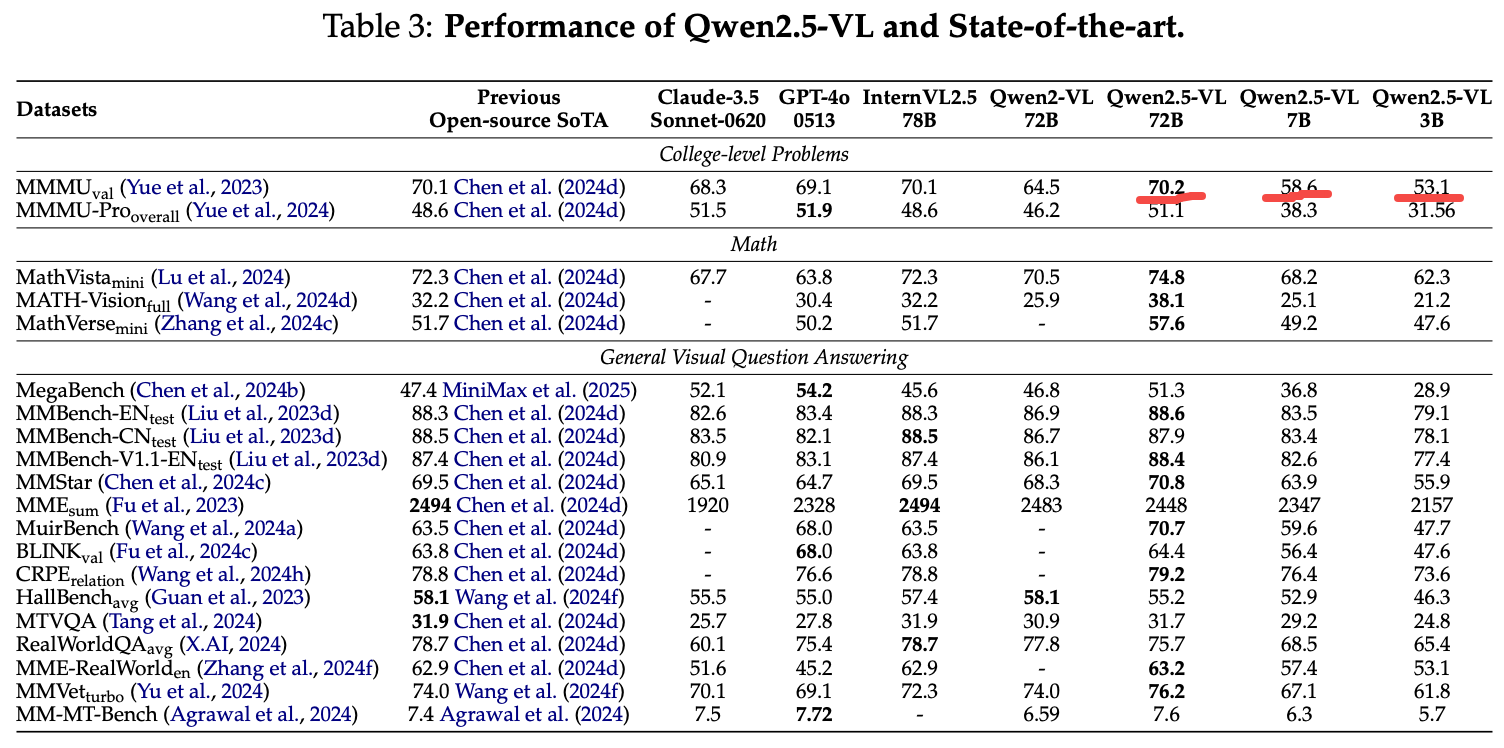
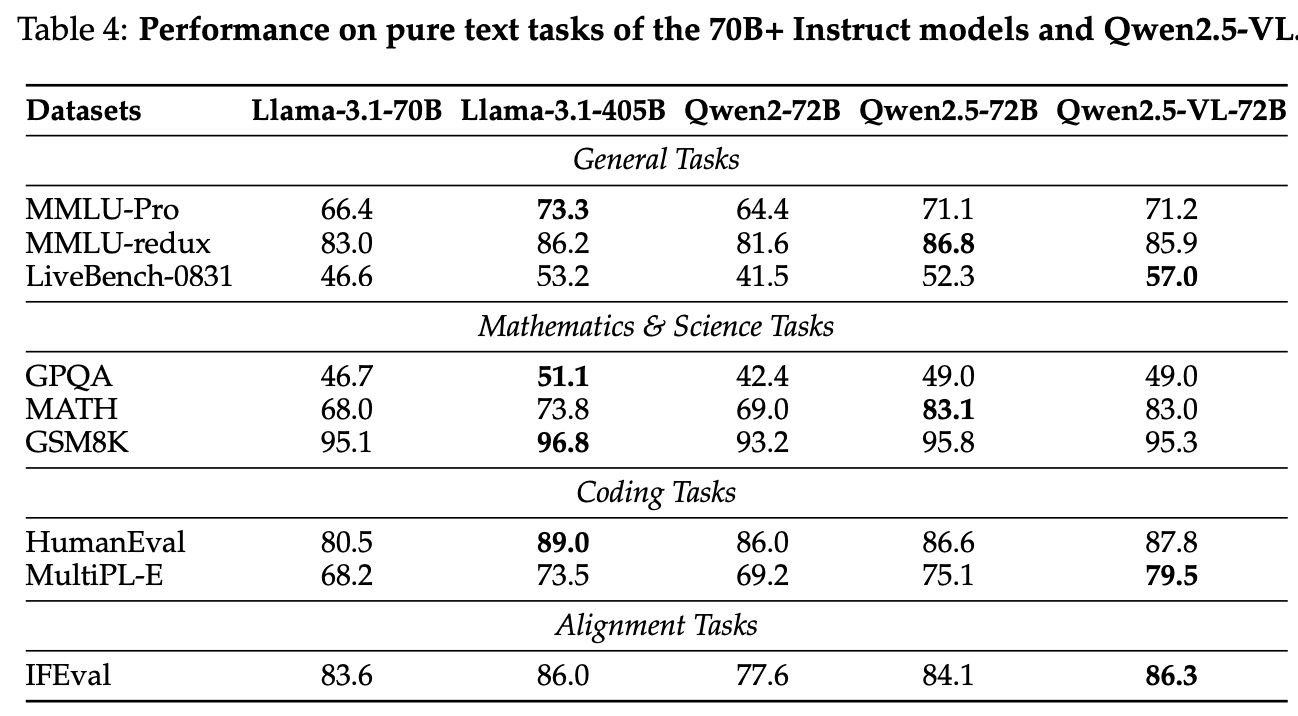
保留了较强纯文本能力
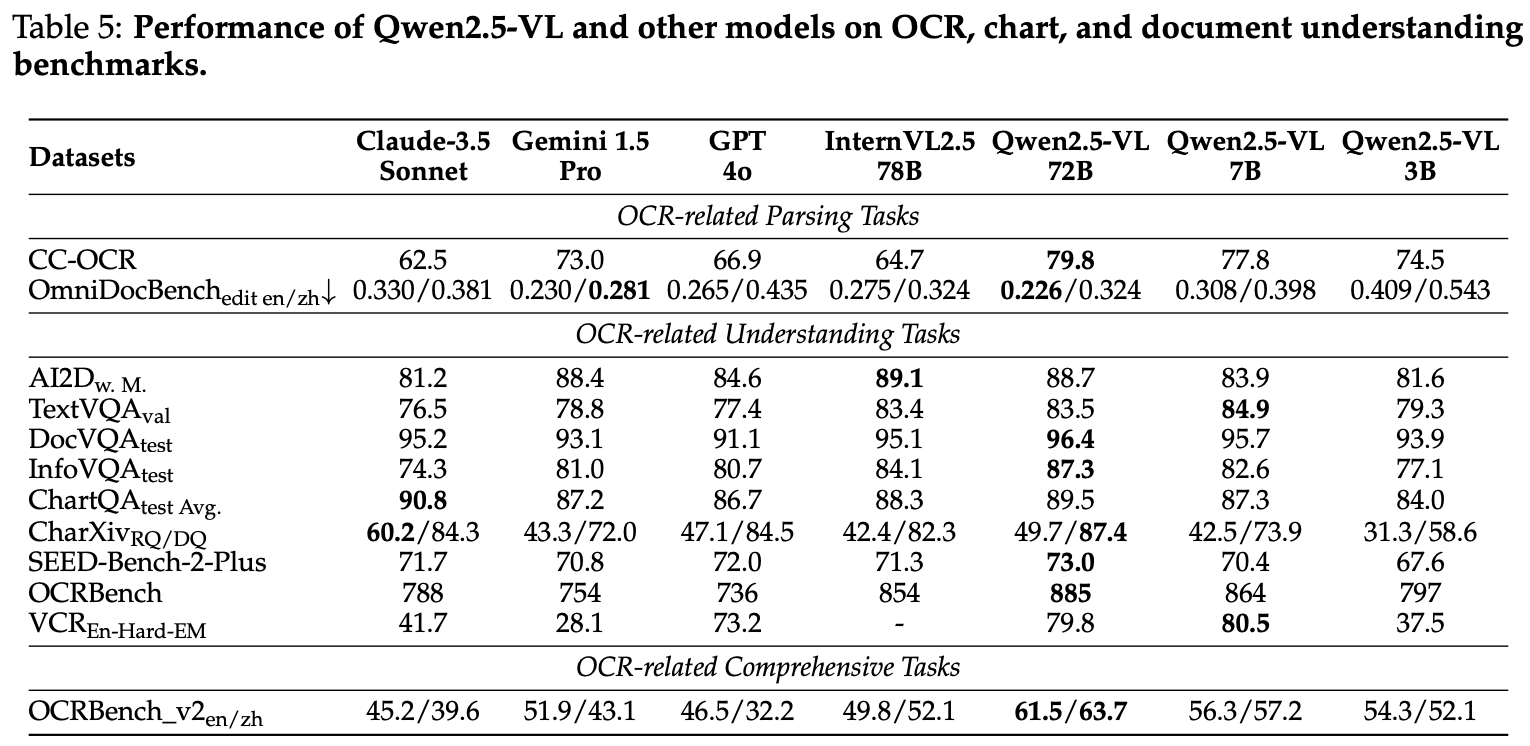
比GPT4o/InternVL2.5等模型OCR能力更强
总结与思考
主要印象:
- 数据上做了较多工作
- Window Attention降低计算量同时支持了动态分辨率
- MRoPE编码绝对时间信息
相关链接
https://zhuanlan.zhihu.com/p/1927463592279671080
https://zhuanlan.zhihu.com/p/1917173869510373470
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19108786

 浙公网安备 33010602011771号
浙公网安备 33010602011771号