[PaperReading] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
link
时间:23.08
单位:Qwen
相关领域:多模态理解
作者相关工作:
被引次数:
项目主页:
https://github.com/QwenLM/Qwen-VL
TL;DR
以Qwen-LM作为基座模型,设计 visual receptor、 input-output interface 以及 3-stage training pipeline以及 多语言多模态语料库 来增加视觉能力。通过对齐image-caption-box三者之间的pair关系,能够实现grounding与text阅读能力。实验结果在多个与视觉相关的任务上(VQA、Image Caption、Visual Grounding)都打破了记录。

Method
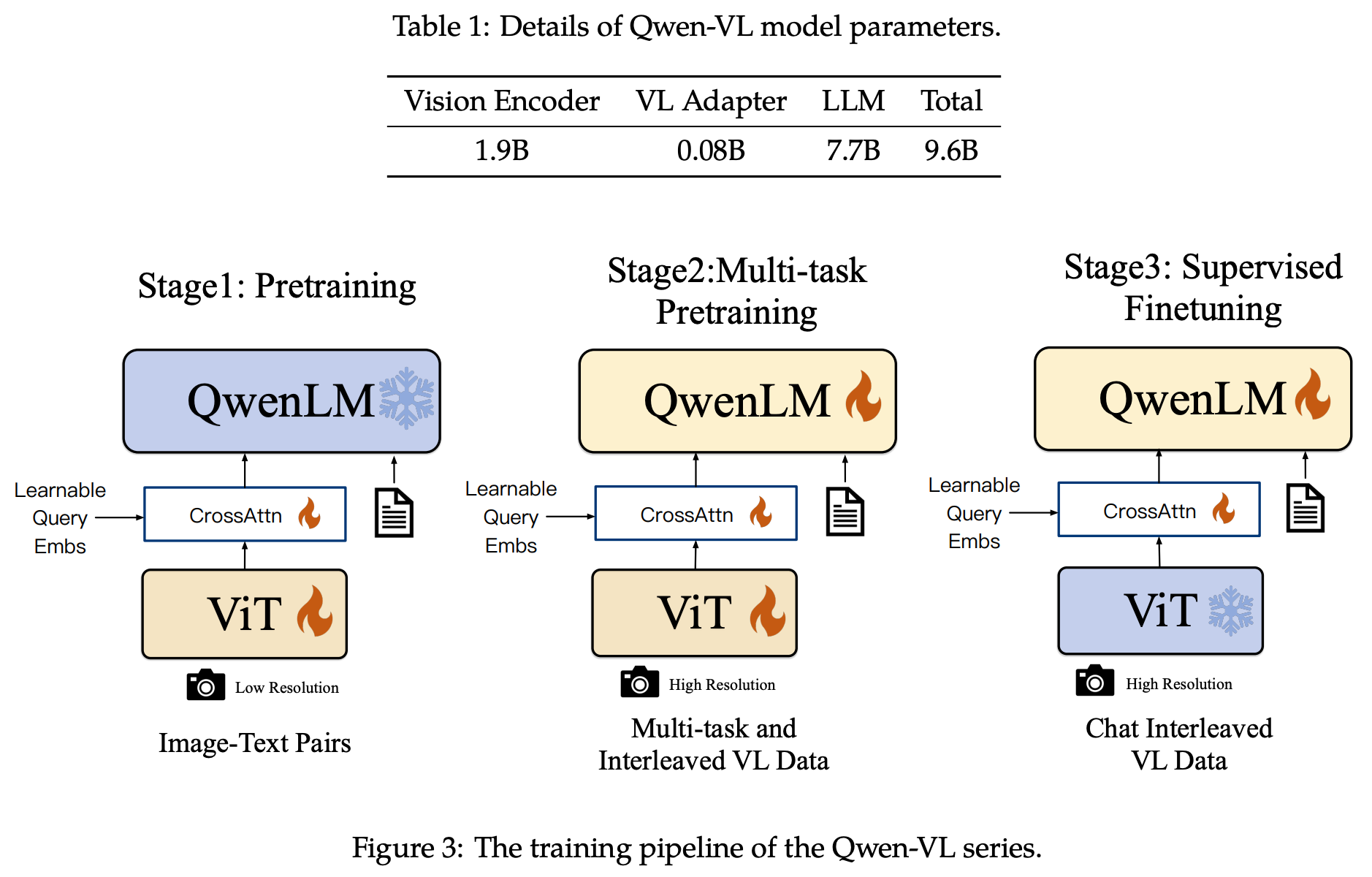
Image Input: 用 and 来标识image feature的开始与结束。
bbox string: two special tokens (
special tokens: and 来用mark框里面的内容。
Pretraining
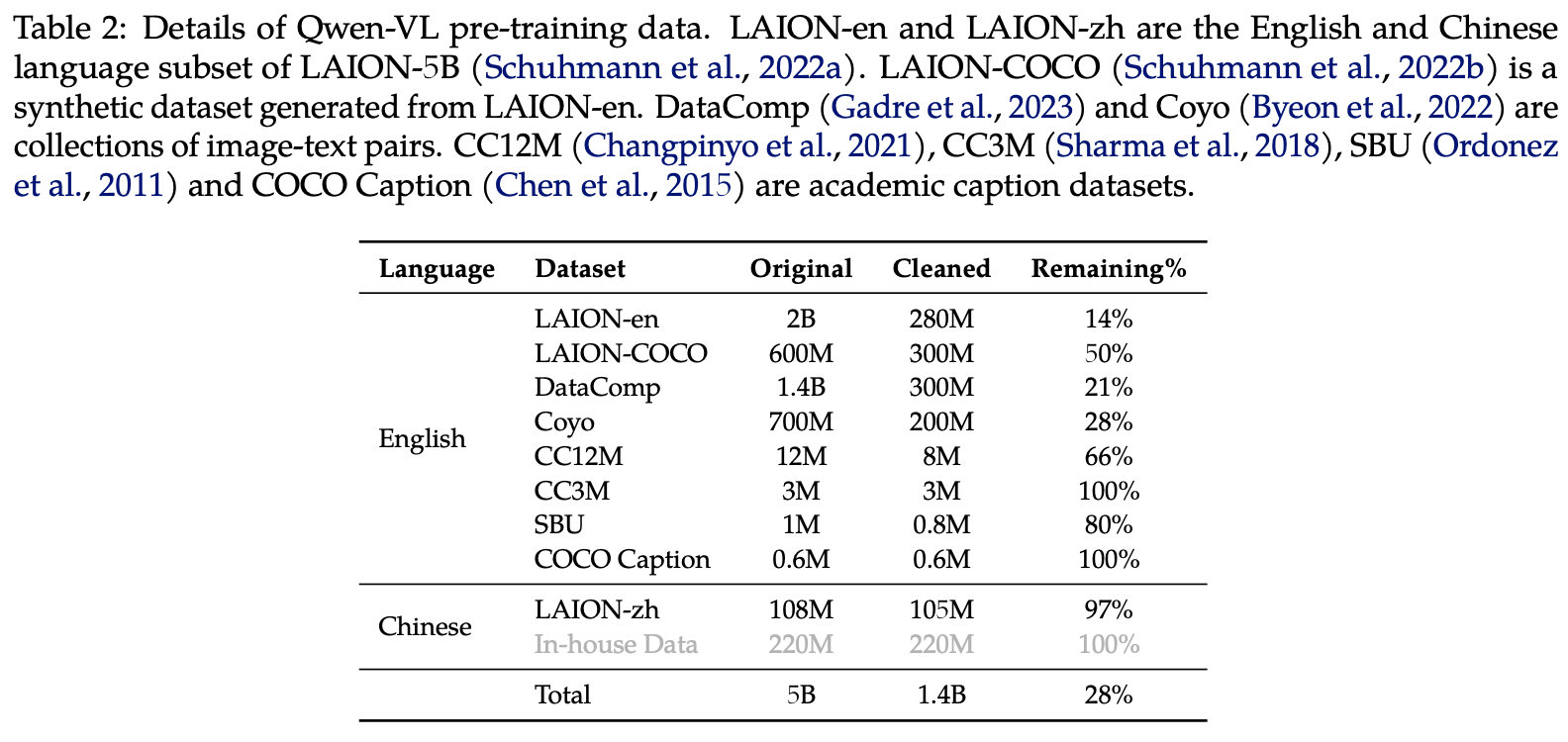
从若干个公开数据中清洗出来,原始数据集5B,清洗后1.4B图文样本,英文77.3%,中文22.7%。输入图片Resize至224x224,总共需要训练5W步。
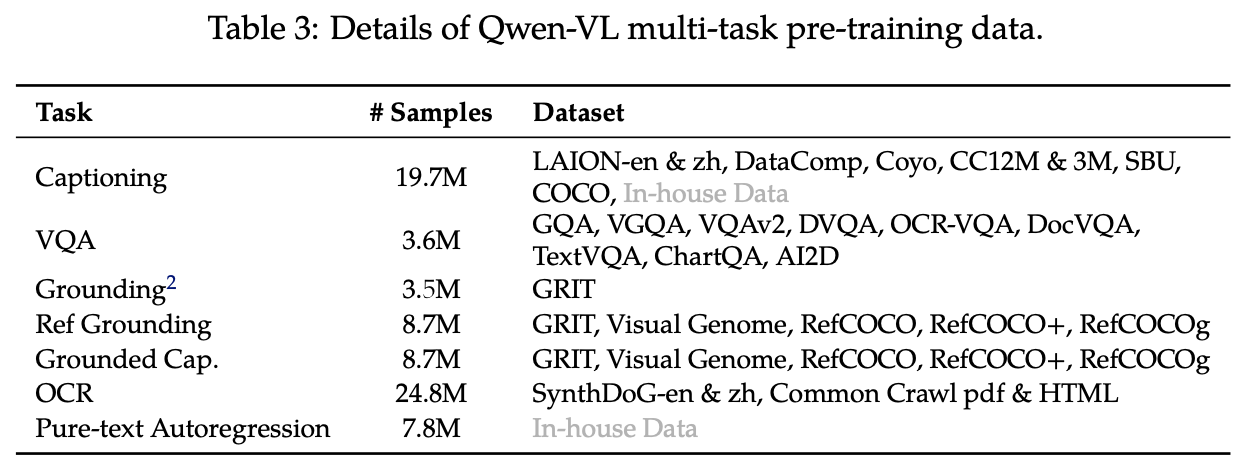
MultiTask PreTraining
- 训练时所有模块都打开训;
- 增加了特定任务数据如下表;
![image]()
Supervised Fine-tuning
- 视觉Encoder Freeze,将Adapter与LM模型放开训练;
- 构造数据据,扩充训练数据中“定位能力”和“多图像理解能力”;
- 混合了纯文本的对话数据,以保持LLM在纯文本任务上语言能力;
Experiment
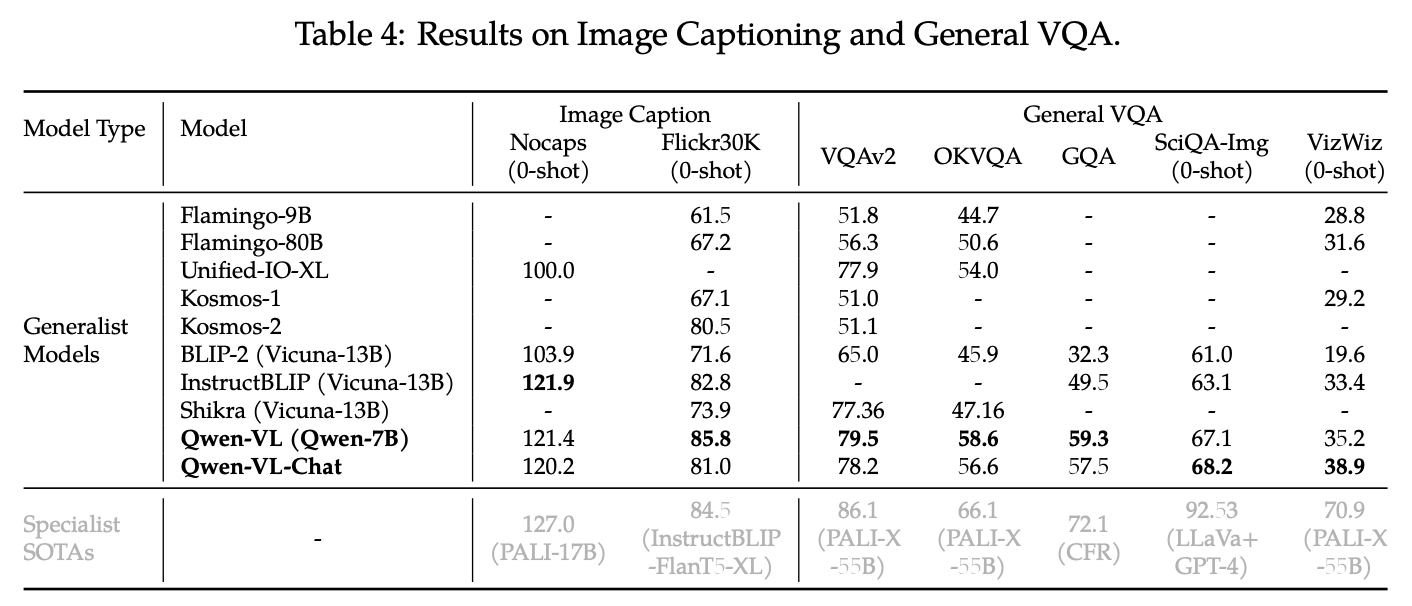
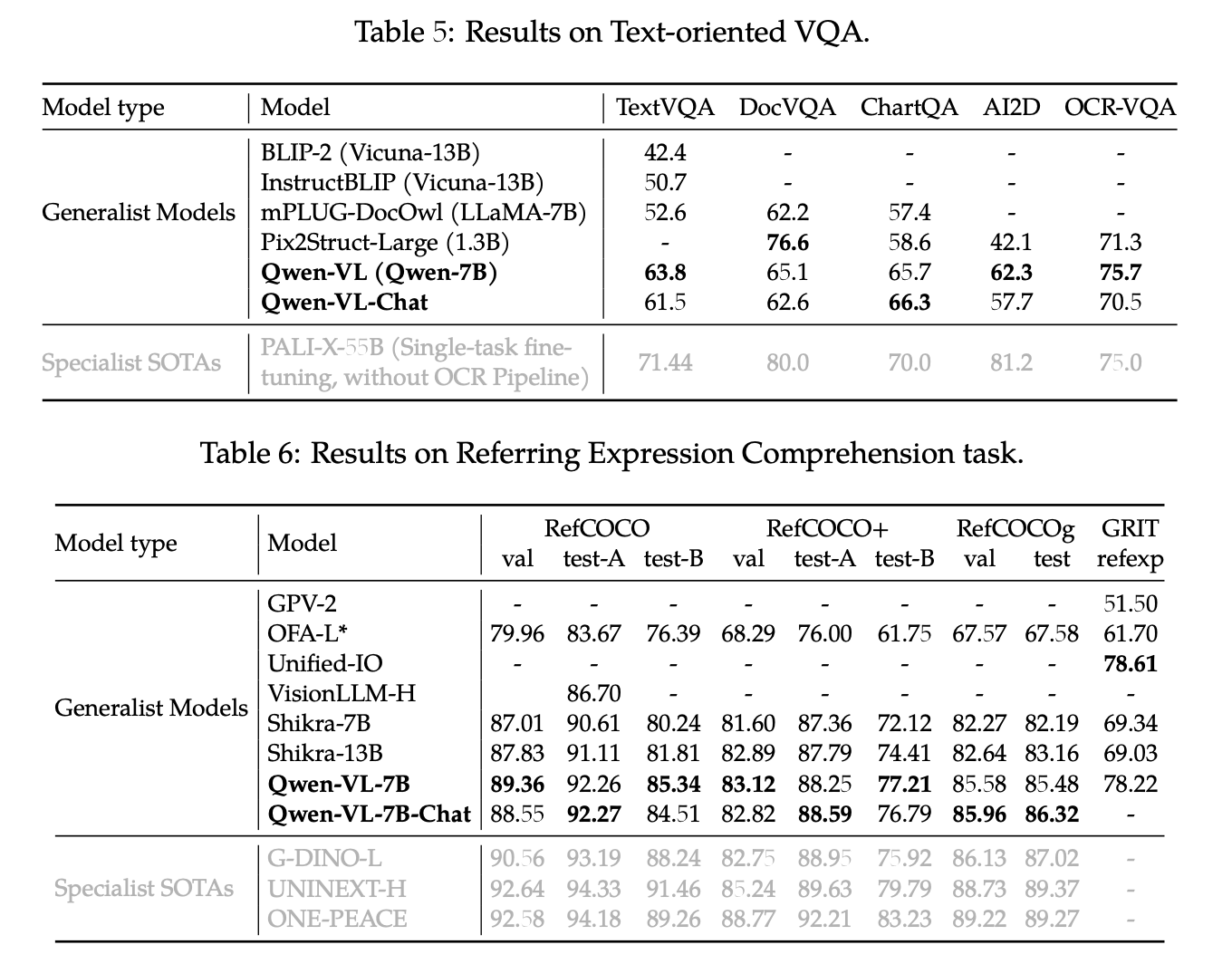
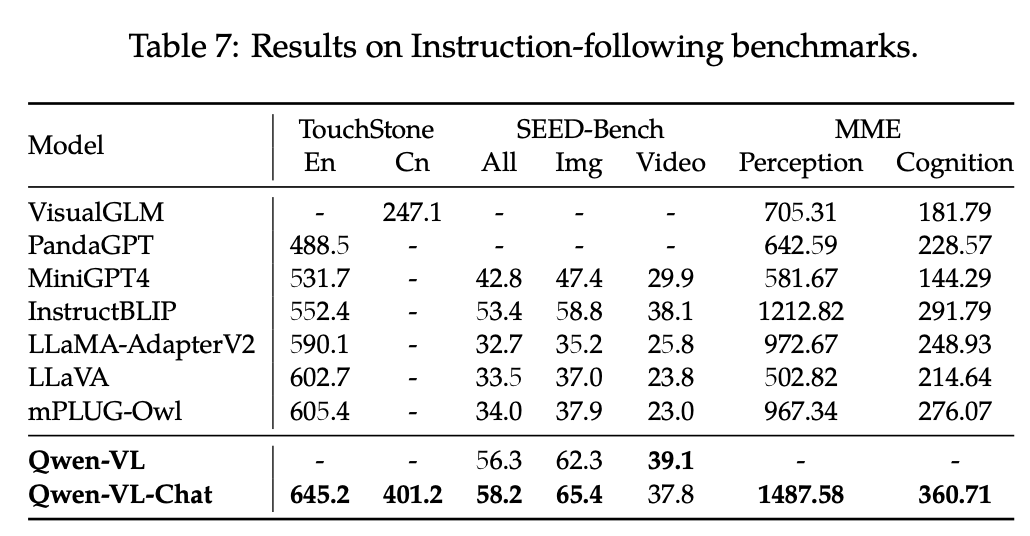
Q: 什么Text-oriented VAQ?
A:Text-oriented VQA,文本导向视觉问答:需要模型理解并识别图像中文本信息来回答问题的任务,比如问 运动员球衣上的数字。
Q: Instruction-following是什么任务?
A:模型需根据多模态输入(如图像和文本指令)生成符合意图的响应,体现其交互性和实用性。例如根据用户要求描述图像、比较多图或定位物体。
总结与思考
视觉仅占20%参数量;
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19101734

 浙公网安备 33010602011771号
浙公网安备 33010602011771号