[PaperReading] LLaVA: Visual Instruction Tuning
LLaVA: Visual Instruction Tuning
link
时间:23.12
单位:University of Wisconsin–Madison, Microsoft Research, Columbia University
相关领域:多模态
作者相关工作:
Haotian Liu
被引次数:8566
项目主页:https://llava-vl.github.io/
TL;DR
使用GPT4生成图文跟随数据集,并使用这些数据训练了首个端到端的图文理解大模型LLaVA(Large Language and Vision Assistant)。实验证明LLaVA在未见过场景表现出类似GPT4的智能效果,并且在指令跟随测试集上达到GPT4的85%的水平。
Data
instruction-following data的示例: 针对数据集中每张图片(例如COCO),会将Captions与Boxes等纯文本信息输入给GPT,让其生成三种不同类型的“指令-遵循”数据。
数据量:
15.8W图文对,其中5.8W是对话数据,2.3W是细节描述,7.7W是复杂推理。对比了ChatGPT与GPT4,发现GPT4的推理结果更准确。
Q: 如何保证GPT4在生成数据时不会生成不符合图片内容的数据?
A: 多条字幕(例如 COCO同一图片有5个Captions):从不同角度描述了同一场景,这为GPT-4提供了交叉验证的信息,形成了一个比较全面的场景理解。

ScienceQA多模态测试集
多模态 (Multimodal): 很多问题都包含视觉上下文 (Visual Context)。这意味着要正确回答问题,模型必须能够理解:
- 文本: 问题本身、背景知识描述。
- 图像: 科学图表、实验示意图、照片等。
例如,一个关于电路的物理题,会附带一张电路图。
丰富的注解与解释 (Rich Annotations & Explanations): 这是ScienceQA最关键、最独特的价值所在。对于每一道题,数据集不仅提供了正确答案,还提供了: - 详细的讲解 (Lecture): 解释这道题背后涉及的科学原理和背景知识。
- 解题思路 (Solution): 提供一个循序渐进、符合逻辑的思维链 (Chain-of-Thought, CoT),来展示如何一步步推导出正确答案。
广泛的学科覆盖 (Broad Subject Coverage):
数据集涵盖了3个主要学科: 自然科学 (Natural Science)、社会科学 (Social Science)、语言科学 (Language Science)。
细分到26个主题、127个类别和379种技能,覆盖了从小学到高中的知识范围。
Method
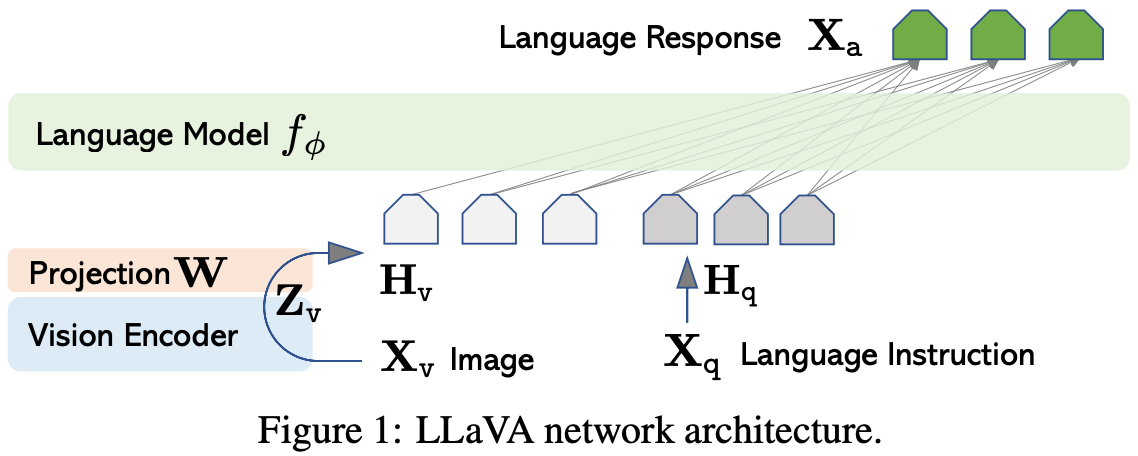
视觉Encoder:ViT-L/14
语言模型:Vicuna, 13B (一个基于 LLaMA 模型进行指令微调(Instruction Fine-tuned)而来的开源对话模型)
| 训练阶段 | 目的 | 视觉编码器 (Vision Encoder, CLIP) | 投影矩阵 (Projection Matrix, W) | 语言模型 (Language Model, LLM) |
|---|---|---|---|---|
| 第一阶段 | 特征对齐 | 冻结 (Frozen) | 训练 (Trainable) | 冻结 (Frozen) |
| 第二阶段 | 指令微调 | 冻结 (Frozen) | 训练 (Trainable) | 训练 (Trainable) |
训练数据
第一阶段:从CC3M数据集中过滤出的595K个图文对。使用“朴素扩展法”转换成单轮问答。
第二阶段:作者们使用GPT-4生成的158K条高质量、多样化的指令数据(包含对话、描述、推理)。
多轮对话
第一轮输入 图像\(X_v\)与文本信息\(X_q\),后续每轮只需输入\(X_q\)
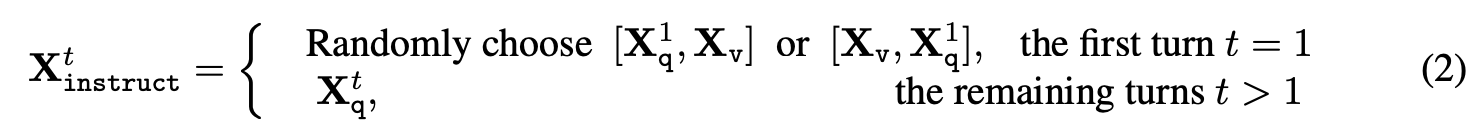
损失计算:
在训练时,模型被要求根据到当前为止的所有上下文(包括之前的问答和图片),来预测 Assistant: 后面的回答内容。
损失函数只计算 Assistant: 部分的预测误差。模型在预测 Human: 部分时是不计算损失的。这确保了模型只学习如何“扮演”好助手的角色。
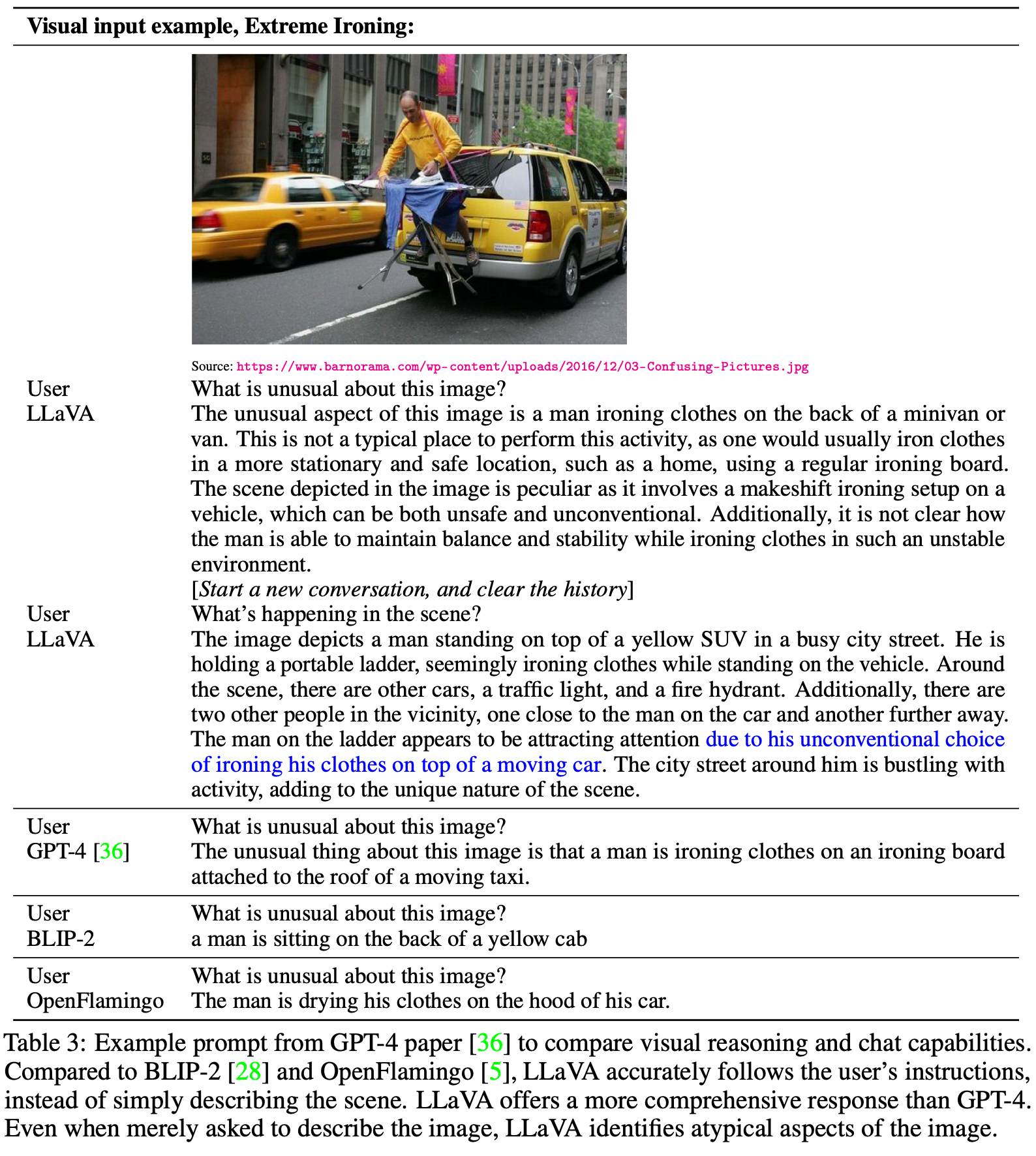
Experiment

效果可视化
总结与思考
无
相关链接
https://zhuanlan.zhihu.com/p/647782091
https://zhuanlan.zhihu.com/p/624071363
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/19053714

 浙公网安备 33010602011771号
浙公网安备 33010602011771号