[PaperReading] DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
link
时间:25.03
单位:

作者相关工作:yuqiying
https://scholar.google.com/citations?user=eFFssJYAAAAJ&hl=en&oi=sra
被引次数:294
主页:https://dapo-sia.github.io/
TL;DR
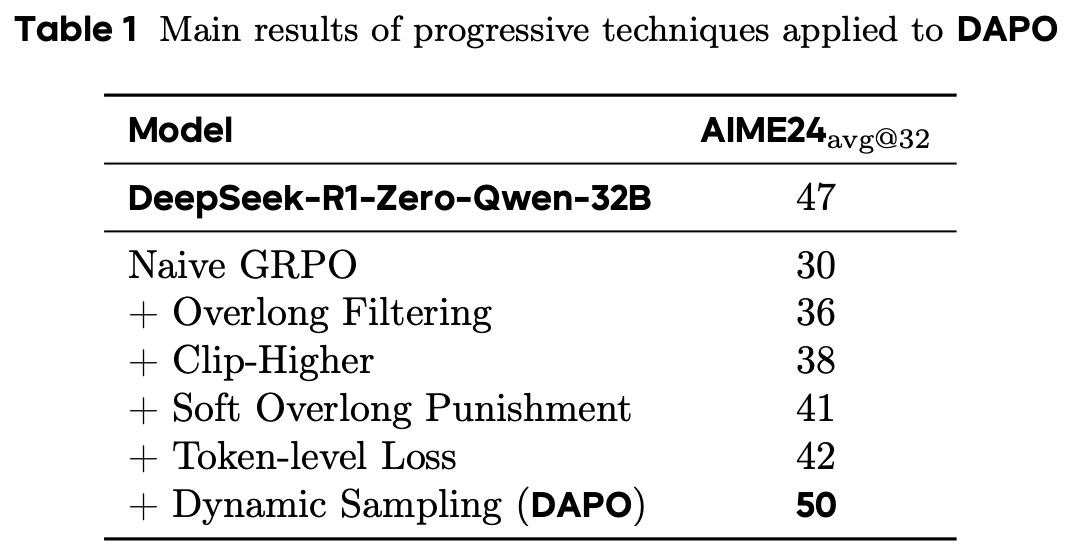
针对GRPO一些问题进行改进,增加Clip-Higher、Dynamic Sampling、Overlong Reward Shaping等Trick,写作易懂、实验扎实,效果上将GRPO的基线由30刷新到50,对于RL in LLM的研究有很大的帮助。
Background
GRPO

Method
Framework


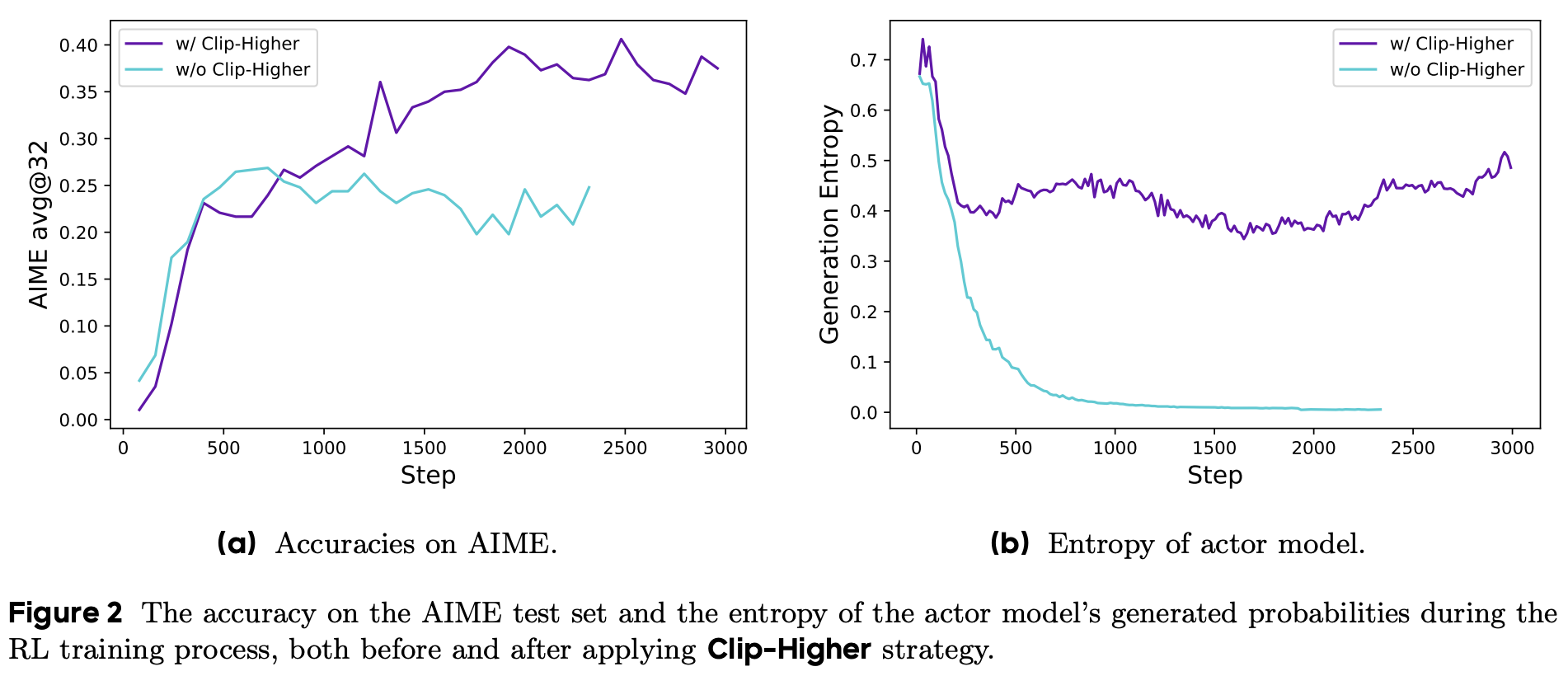
Clip-Higher
\(\varepsilon_{low}\)保持不变,增大\(\varepsilon_{high}\)。当优势函数\(A > 0\)时,\(1 + \varepsilon_{high}\)为\(\pi/\pi_{old}\)的比值,增加该比值上限意味着policy model \(\pi\)可以更大幅度脱离参考模型\(\pi_{old}\),则policy可以“探索”出更多样的轨迹,从而缓解训练过程熵太低的问题。
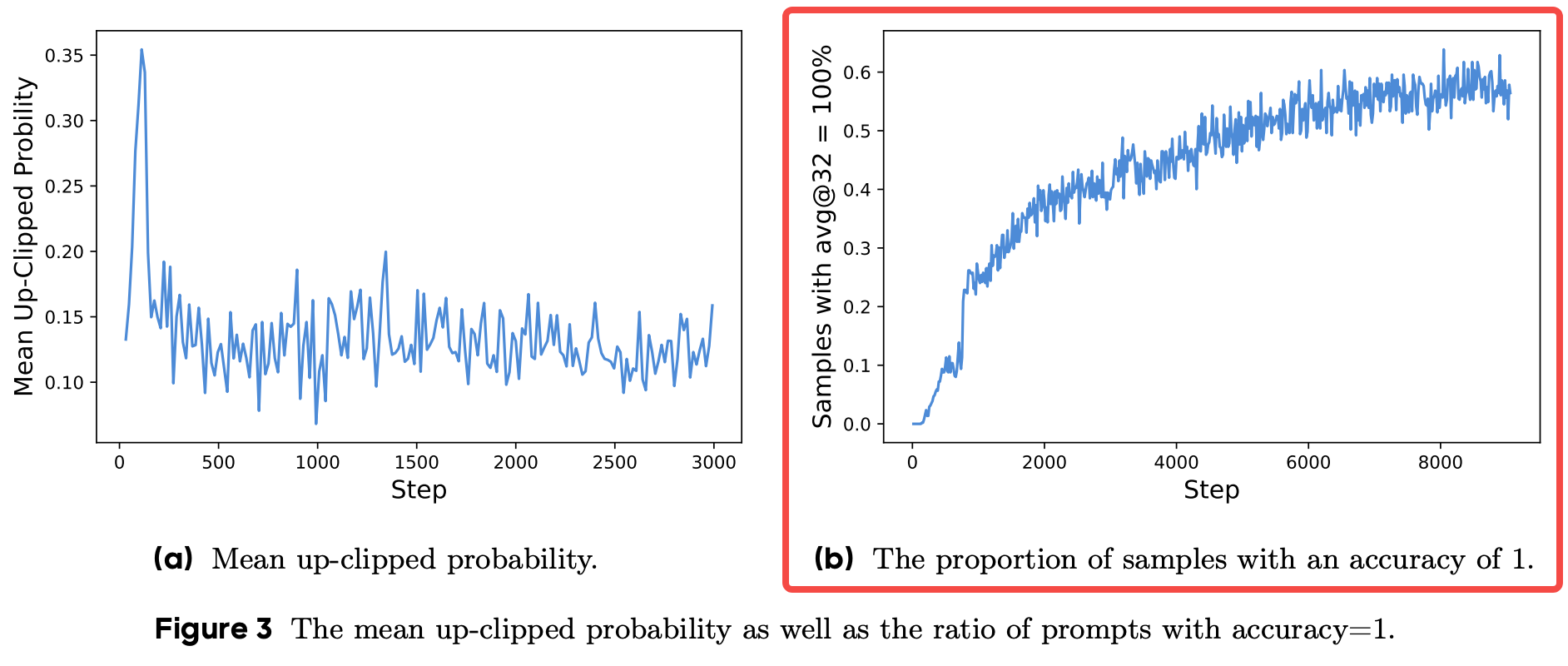
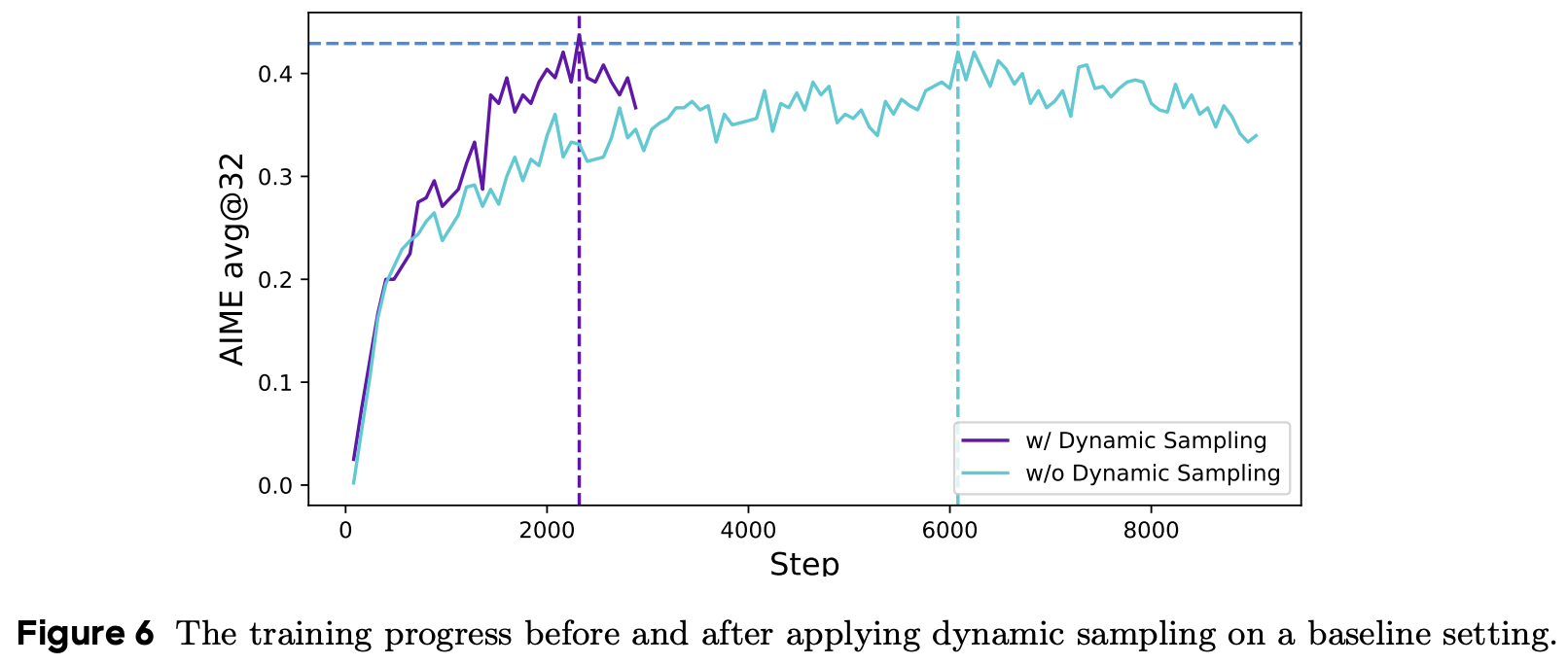
Dynamic Sampling
根据GRPO中优势函数计算公式来看,当某个prompt的g个output获得相同的reward,比如全对或者全错,那么优势函数为0,对于整个batch的梯度带来不稳定。并且从Figure 3(b)来看,随着训练的持续进行,这种accuracy全1的情况会越发明显,对于训练后期的提升非常不利。
解决办法:over-sample and filter out prompts with the accuracy equal to 1 and 0
- 根据已采样出output的有效数量动态增加采样次数
- 过滤掉全对或者全错的训练prompts
以上两种措施都是为了达到下面这个约束的目标
\(0 < {oi | is_equivalent(a, oi)} < G\)
Overlong Reward Shaping
问题:在RL训练过程,通常会设置最大生成长度,如果某次生成结果是合理的,但达到最大长度也会被异常阶段,这种本来结果可以是对的,但由于截断获得很低reward的情况对于模型学习推理能力会有困惑。
解决:
- Overlong Filtering:将这种达到最大长度阶段的output直接过滤不产生loss,也好过它产生noise reward
- Soft Overlong Punishment: 在\(L_{max}\)之前先设置\(L_{cache}\)的阈值,超过该阈值先产生小幅度惩罚,达到\(L_{max}\)再完全惩罚。

Experiment
ablation study
训练过程监控指标
response length、reward score、entropy、mean prob
entropy: 太低的entropy意味着模型输出结果非常单一,不利于“探索”出更高reward的output;太高的entropy通常表明模型正在过度“探索”,此时通常会输出“胡言乱语”的结果。
**mean prob:与entropy相反,过高表明模型的输出非常"sharp",但该结果不一定正确;mean prob较低:→ 模型对每个token的预测信心不足 -> 倾向于生成更多探索性token -> 生成质量较低、长度增加、熵增加。(注意:这里的mean prob是每个prompt生成多个output的平均score,而非一次output多个token的平均score)
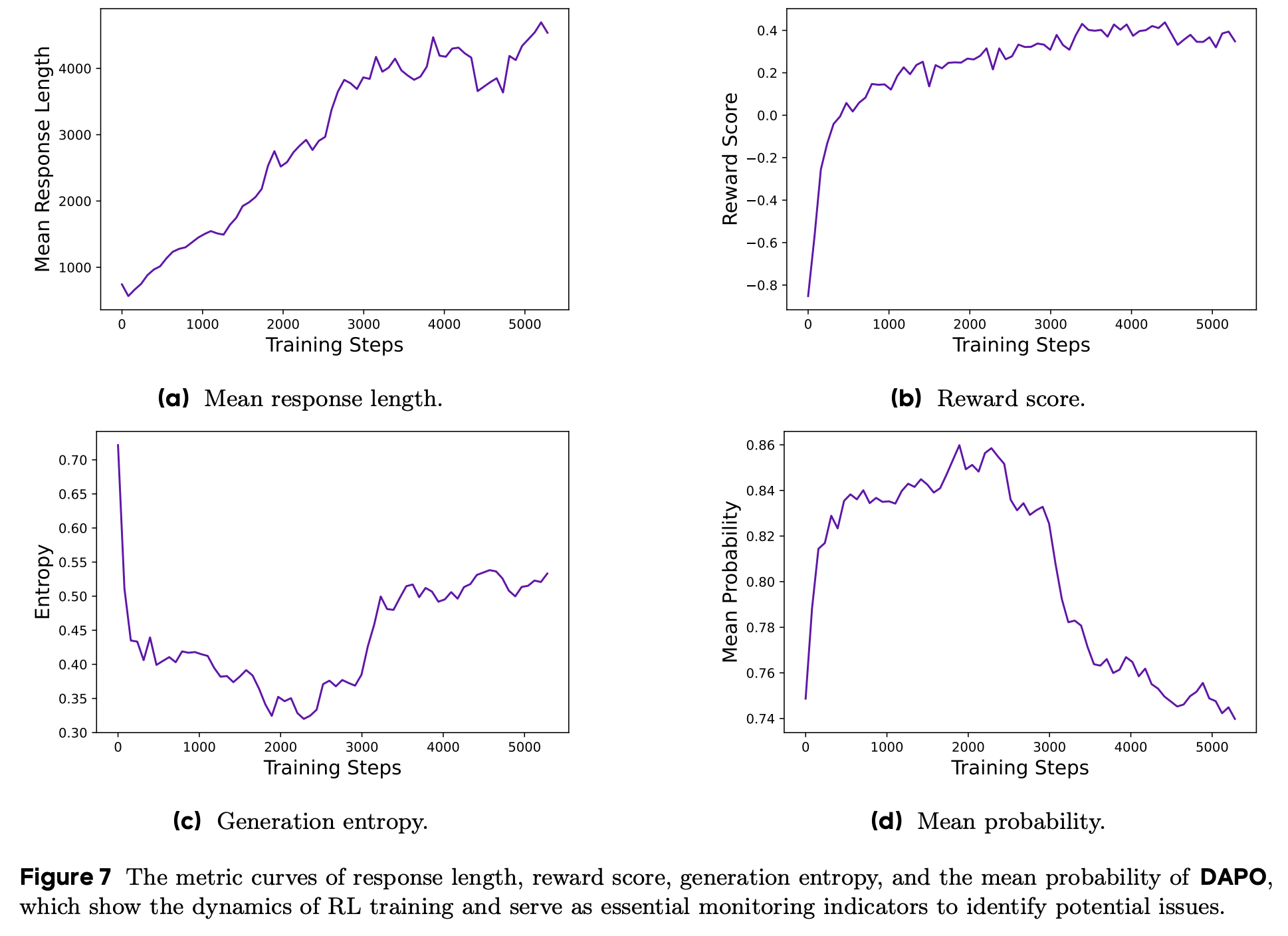
总结与思考
对于GRPO做了很详细的实验分析,各方面都有对应的改进,比较高质量的工作。
相关链接
DAPO全是已有的小trick,为什么这么火?
https://zhuanlan.zhihu.com/p/1886955155527815959
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18994330

 浙公网安备 33010602011771号
浙公网安备 33010602011771号