[PaperReading] QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
QWENLONG-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
link
时间:2025/05
单位:Ali Tongyi Lab
作者相关工作:
https://scholar.google.com/citations?hl=en&user=AeS1tmEAAAAJ&view_op=list_works&sortby=pubdate
被引次数:
主页:https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B
TL;DR
将之前大模型推理能力的突破归纳为shot-context reasoning,本文开创性解决long-context reasoning问题,解决该问题两个卡点难题suboptimal training efficiency与unstable optimization process。使用了progressive context scaling思路来解决。效果上在7个long-context benchmarks上超过OpenAI-o3-mini与Qwen3-235B-A22B。
Motivation
Q: 什么是long-context language reasoning?
A: 作者先提交了一个文档(如paper, ppt等),再针对该文档进行提问,数据建模如下:

Q:直接使用short-context RL训练long-context数据存在什么问题?
A:相对于long-context训练,作者观察到以下现象,总结为suboptimal training efficiency与unstable optimization process。
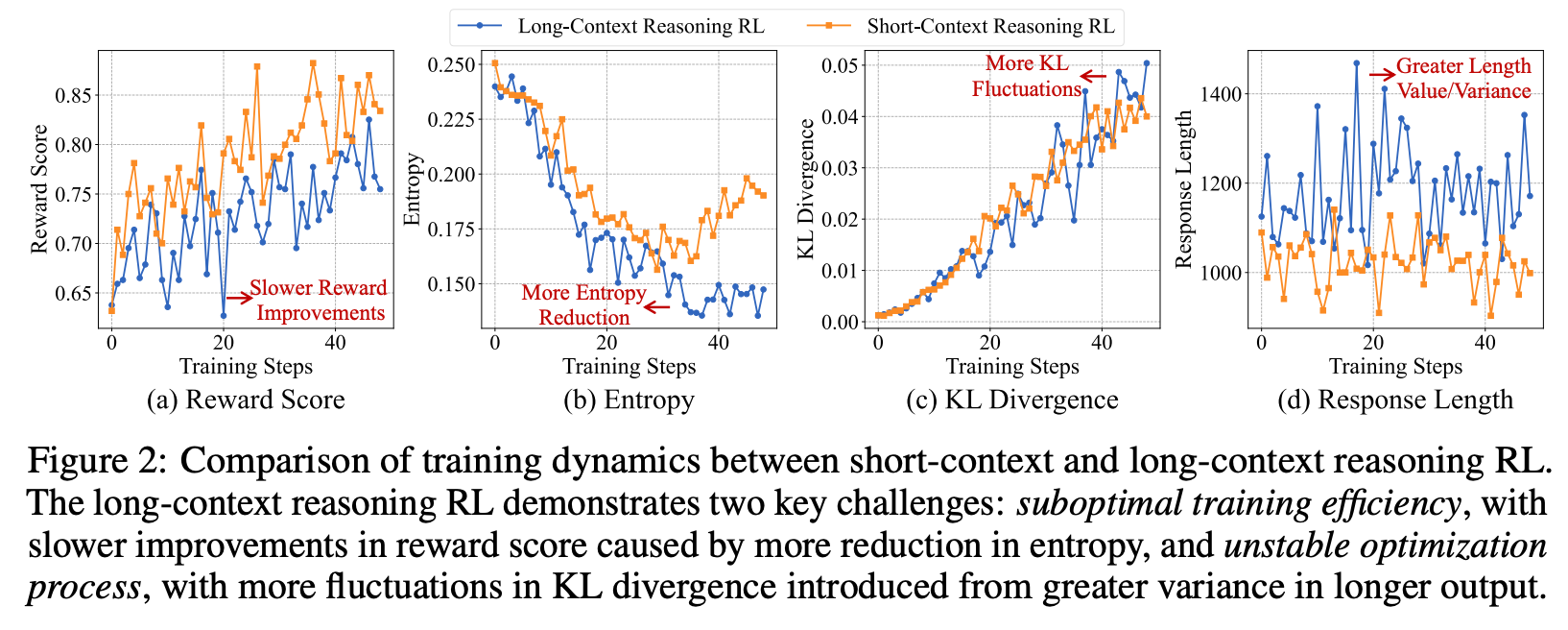
suboptimal training efficiency
Figure2 (a): 作者观察到long-context训练相对于short-context的奖励收敛缓慢;
Figure2 (b): 作者观察到long-context训练predict context的信息熵更低(意为着结果多样性更单一,进一步说明模型倾向于"利用"而不敢于"探索");
unstable optimization process
Figure2 (c)、Figure2 (d)是作者观察到训练过程KL与输出长度两个关键指标都波动较大,体现了训练过程的不稳定性。
Method
架构图
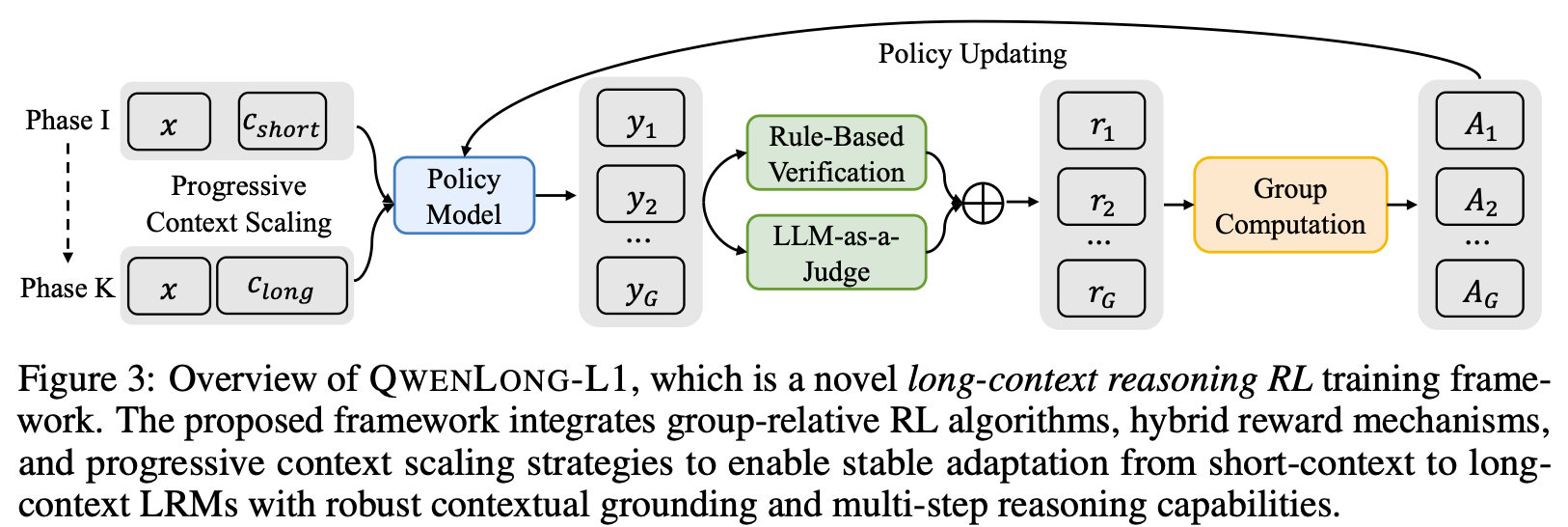
Progressive Context Scaling
Warm-Up Supervised Fine-Tuning
使用teacher LRM蒸馏一个高质量demonstrations \(D_{SFT}\)数据集,使用该数据集SFT训练初始policy model。
Curriculum-Guided Phased Reinforcement Learning
RL为了K个阶段,每个阶段文档长度c加prompt x的总长度逐步增加。
![]()
Difficulty-Aware Retrospective Sampling
根据难度系数来采样训练数据,难度系数根据之前阶段模型的reward来计算,reward越低认为样本难度越大。
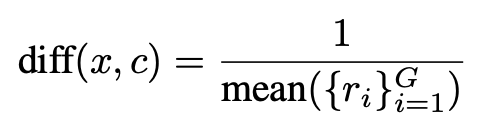
Hybrid Reward Mechanisms
如“Method架构图”中绿色模块所示,RL训练过程Reward是通过Rule-Based Verification与LLM-as-Judge混合产生的。
![]()
备注:下面的\(y_gold\)是通过人工或者规则验证的预存的基准答案。
Rule-Based Verification
通过正则表达式等规则提出输出模型预测结果,对比\(y_{gold}\)进行验证计算Reward \(r_{rule}\)。
LLM-as-Judge
将预测结果与\(y_{gold}\)输入Qwen2.5-1.5B-Instruct小模型,使用该小模型验证结果是否一致,产生Reward \(r_{LLM}\)

Experiment
数据集分布

竞品对比
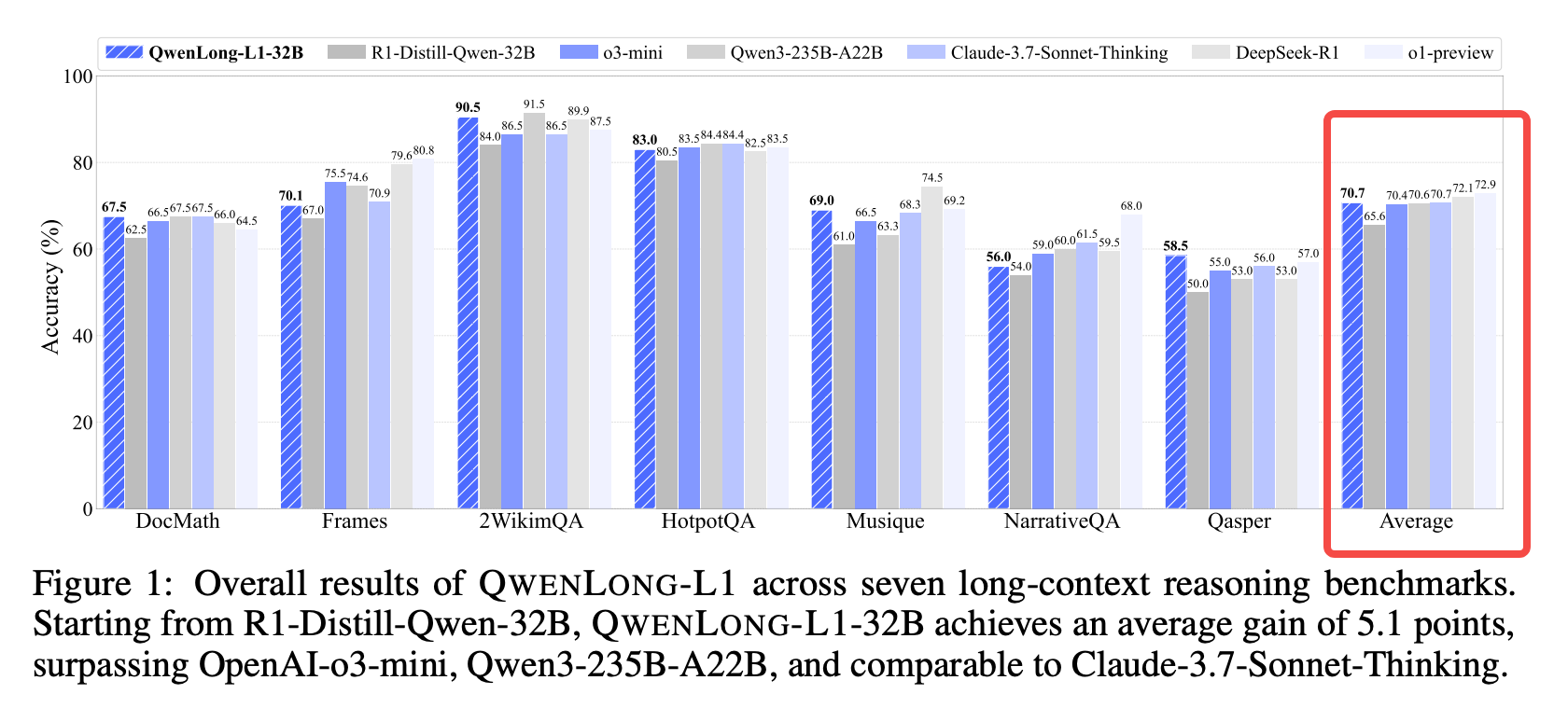
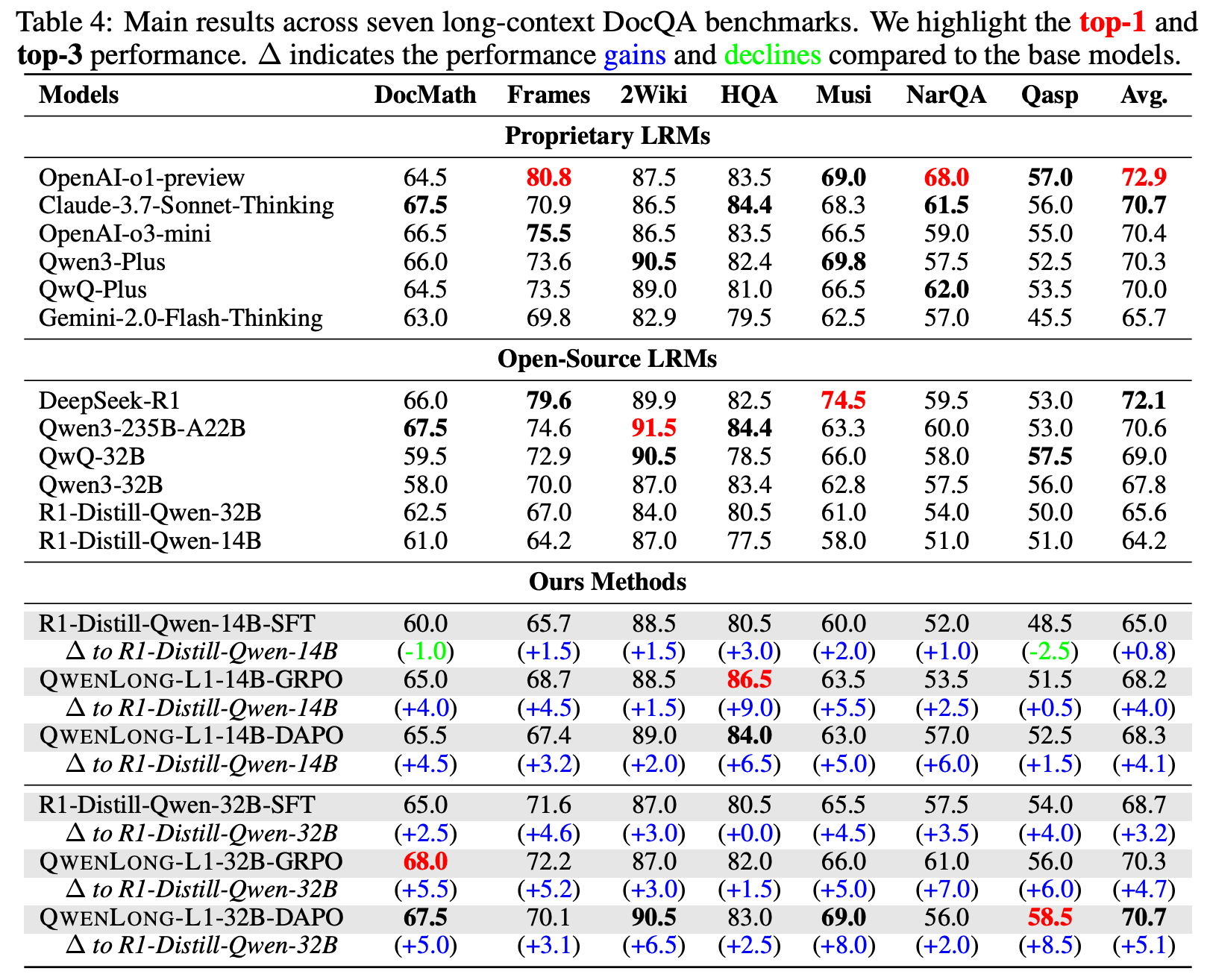
main results
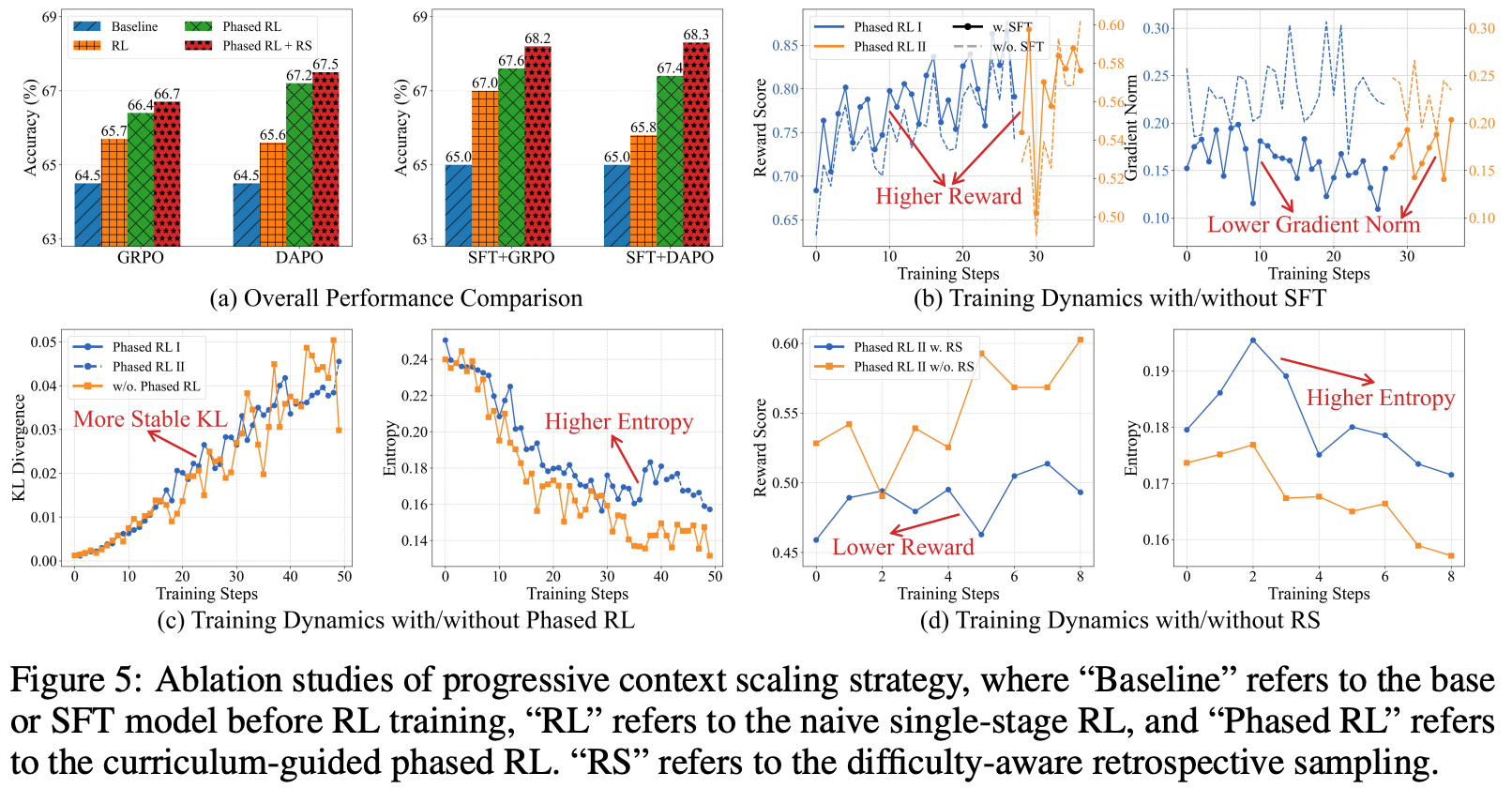
ablation study
Q&A
Q: 什么长度属于Long-context,什么长度属于short-context?
A: 文中举例子说short-context是4K tokens, long-context是120K tokens。实际应用中long-context指得是给定文档,再进行提问的场景。
总结与思考
long-context这种场景确实值得关注,我在使用LLM时,很多时候也是先upload一个文档,再进行问答。
相关链接
https://www.zhihu.com/question/1911028222537228762/answer/1912248554845607757
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18994019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号