[RL Tutorial] 强化学习 - 李宏毅
Reforce Learning Tutorial
课程主页
Book Reading Easy-RL蘑菇书
2025video
2019video,多了PPO与Q-Learning
讲师:李宏毅
课程内容
基本概念
概念:
actor: RL训练的模型
environment:外部环境的状态s,给actor提供观测
reward: actor看到某个观测s,通过policy(策略)采样到某个动作a之后,所获取到的奖励
policy: 状态空间(State Space)到动作空间(Action Space)的映射,决定了智能体在任意状态 s 下如何选择动作 a
episode: 整个游戏结束称为一个episode
定义:
蒙特卡洛回报\(G_t\)
从时刻t的实际累积奖励:\(G_t = \sum_{k=t}^T \gamma^{k-t} r_k\)
状态价值函数\(V^\pi(s)\)
状态s 的长期回报期望:\(V^\pi(s) = \mathbb{E}_\pi[G_t \mid s_t = s]\)
状态动作价值函数$Q^\pi(s,a) $
在s执行a后的长期回报: \(Q^\pi(s,a) = \mathbb{E}_\pi[G_t \mid s_t = s, a_t = a]\)
优势函数\(A(s,a)\):动作比策略平均好多少
$A = Q^\pi(s,a) - V^\pi(s) $
分类:主要分为policy-based、value-based两大类 (actor-critic为两者的融合)
Policy Gradient - 方案演进
不同RL方法对于A(advantage function)有不同定义

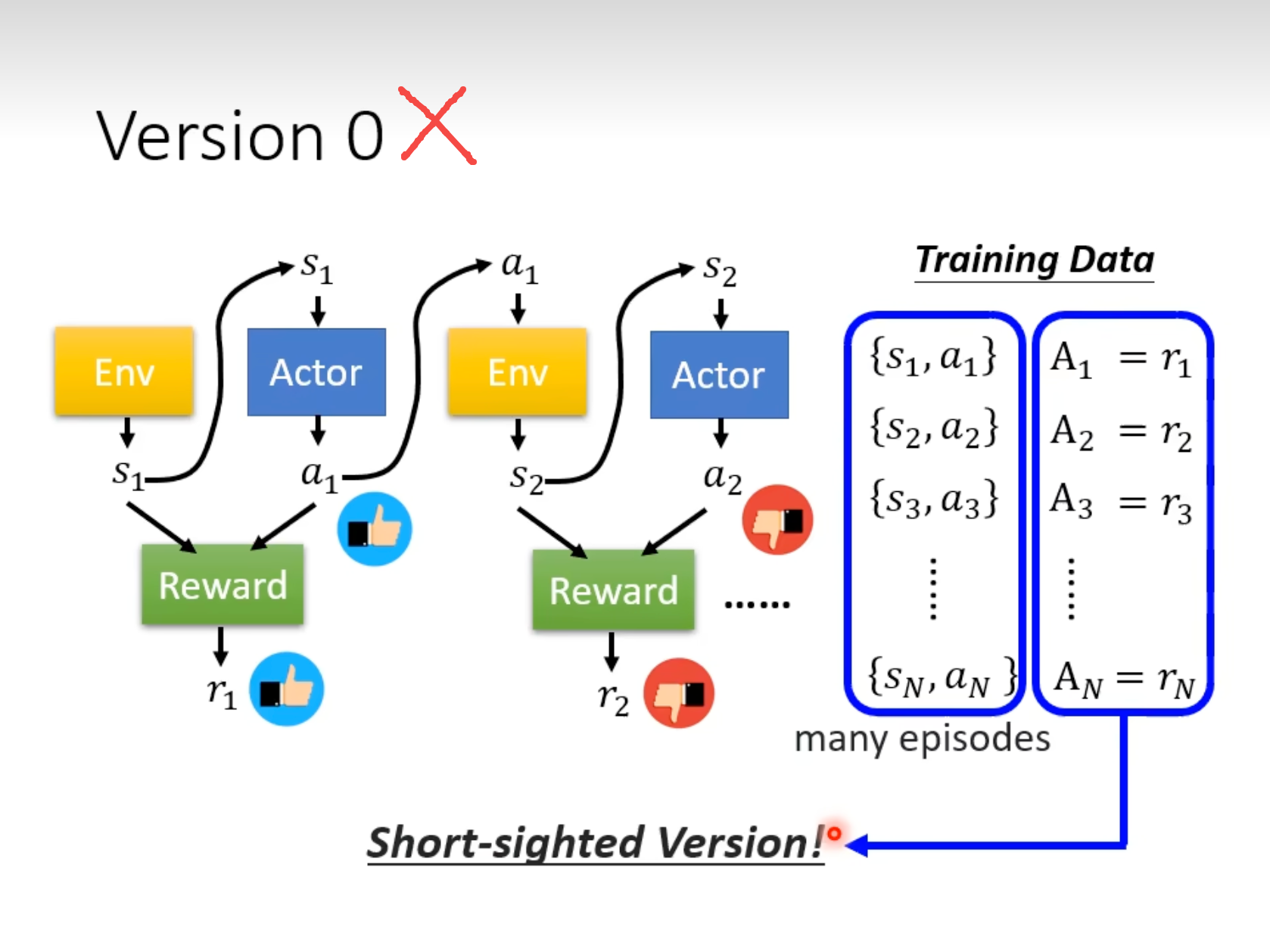
Version0
错误版本:会使Actor更加“短视”
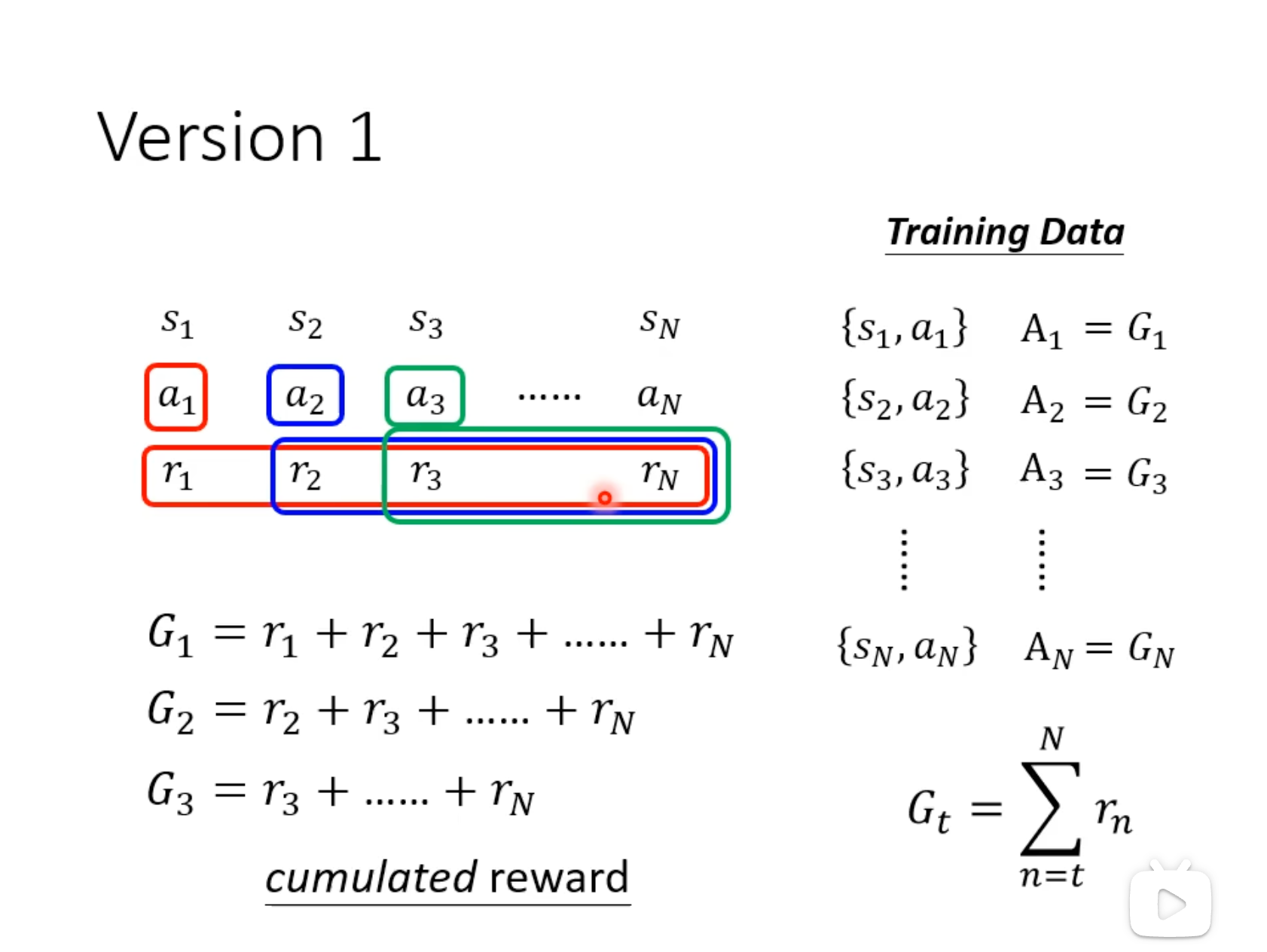
Version1
优于Version0,但所有时间的r都是等权重的,不合理
Version2
降低未来更远时刻的reward的权重,但Reward使用绝对score

Version3
所有reward减去baseline b,更新后的reward是相对的

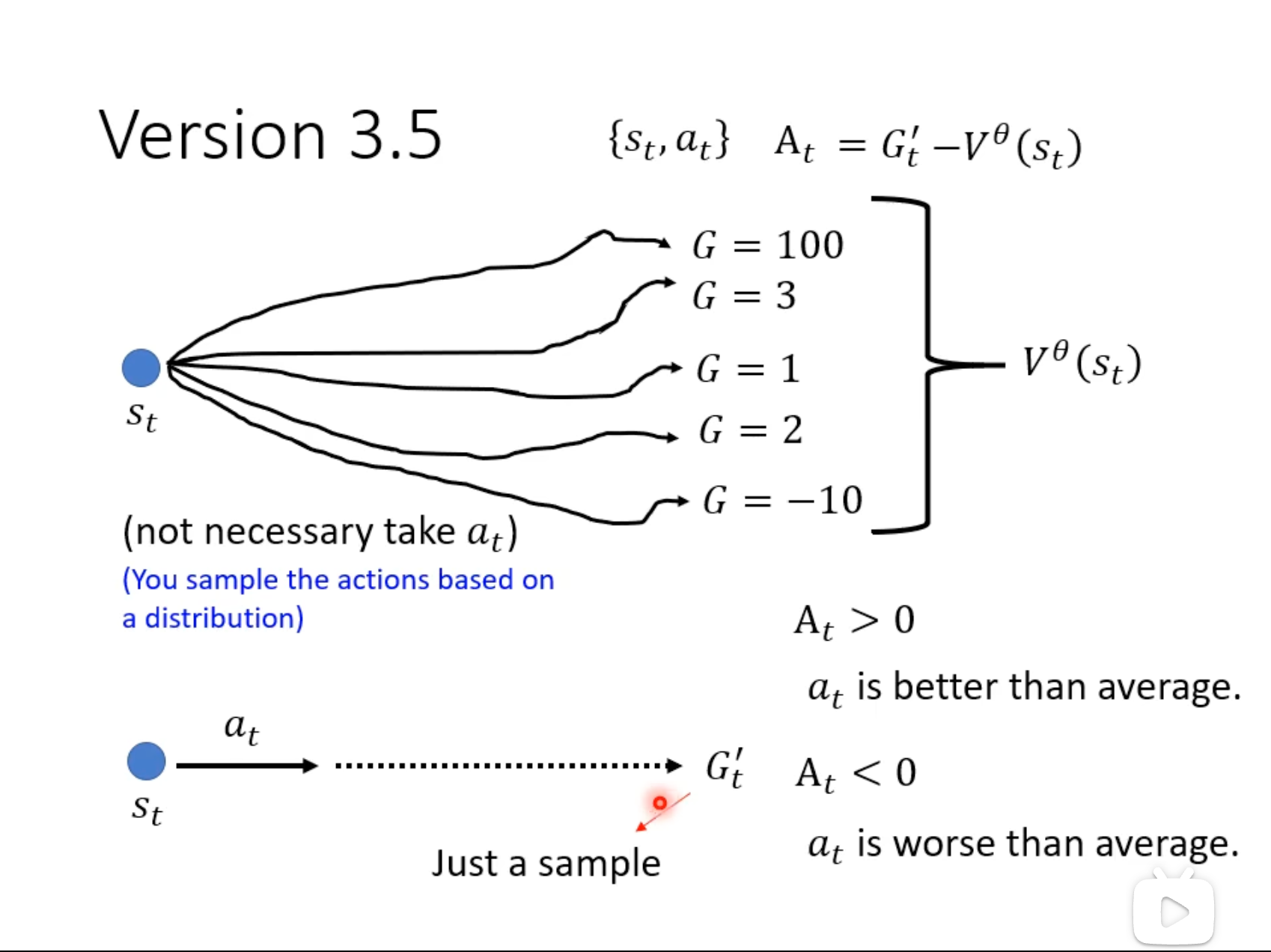
Version3.5
将version3的baseline替换为critic预测结果V(状态价值函数)
含义:
\(A_t\) > 0 => 执行\(a_t\)比随便执行action的期望要高。
Version4
Adbantage Actor-Critic(A2C)

相对于Version3,baseline换为\(V\)从定义上更合理,价值函数\(V\)由critic模型来估计,详情参考下面A2C部分介绍,可以看出Policy后续的演进版本主要是将Q-Learning的元素融入进来,但模型数据也相应变多,训练难度变大。
Policy Gradient - On-policy Vs Off-policy
On-policy
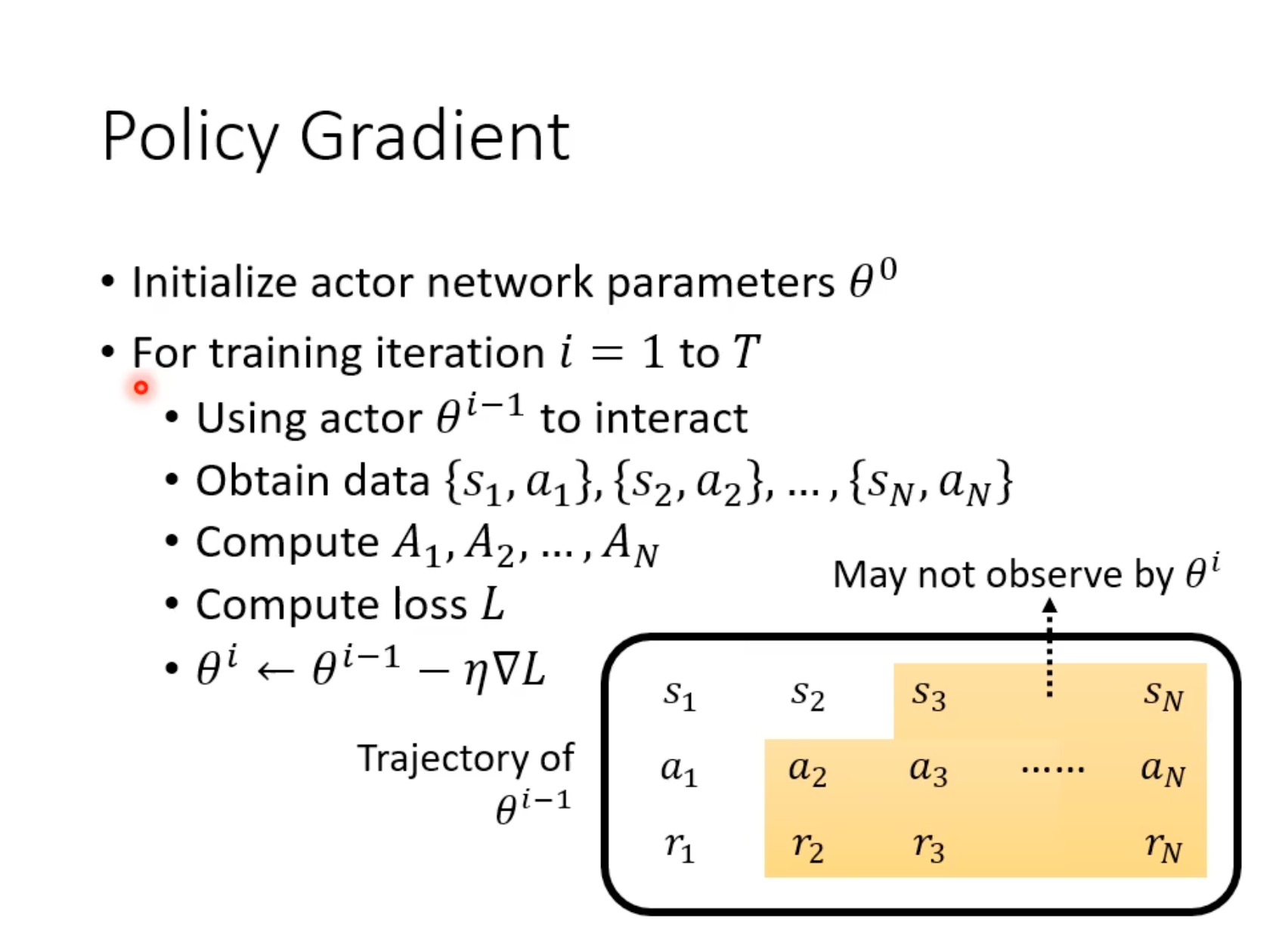
必须用自己的经验来学习
每个iteration需要收集完整espisode的trajectory,用于训练\(\theta_{i-1}\),但不能训练\(\theta{i}\)。(因为对于曾经的“自己”有用的经验,现在不一定有用)。
Off-policy
看别人或者历史的自己经验也可以学习
\(\theta_{i-1}\)的数据可以用于训练\(\theta_{i}\),经典方法为PPO。详情参考下面专门介绍的一小节。
Actor-Critic
Actor-Critic属于policy-based与value-based方法的融合。相对于policy-based方法引入critic。
critic的职能:对某actor,输入观测s后,预估它将得到价值V(折扣reward的总和 的期望)。

Advantage Actor-Critic(A2C)
如上述Version4介绍,将baseline替换为价值函数V,\(G_t\)是\(Q^{\pi}(s, a)\)的无偏估计,所以将其替换为\(Q^{\pi}(s, a)\),但这么做V与Q总共需要两个Network来给Policy网络学习提供Loss。经如下推导后变为仅依赖于\(V\)提供Loss,所以仅需要训练\(V\)与\(\pi\)两个Network即可,实际操作由于两个网络输入都为s,可以共享backbone一些参数。

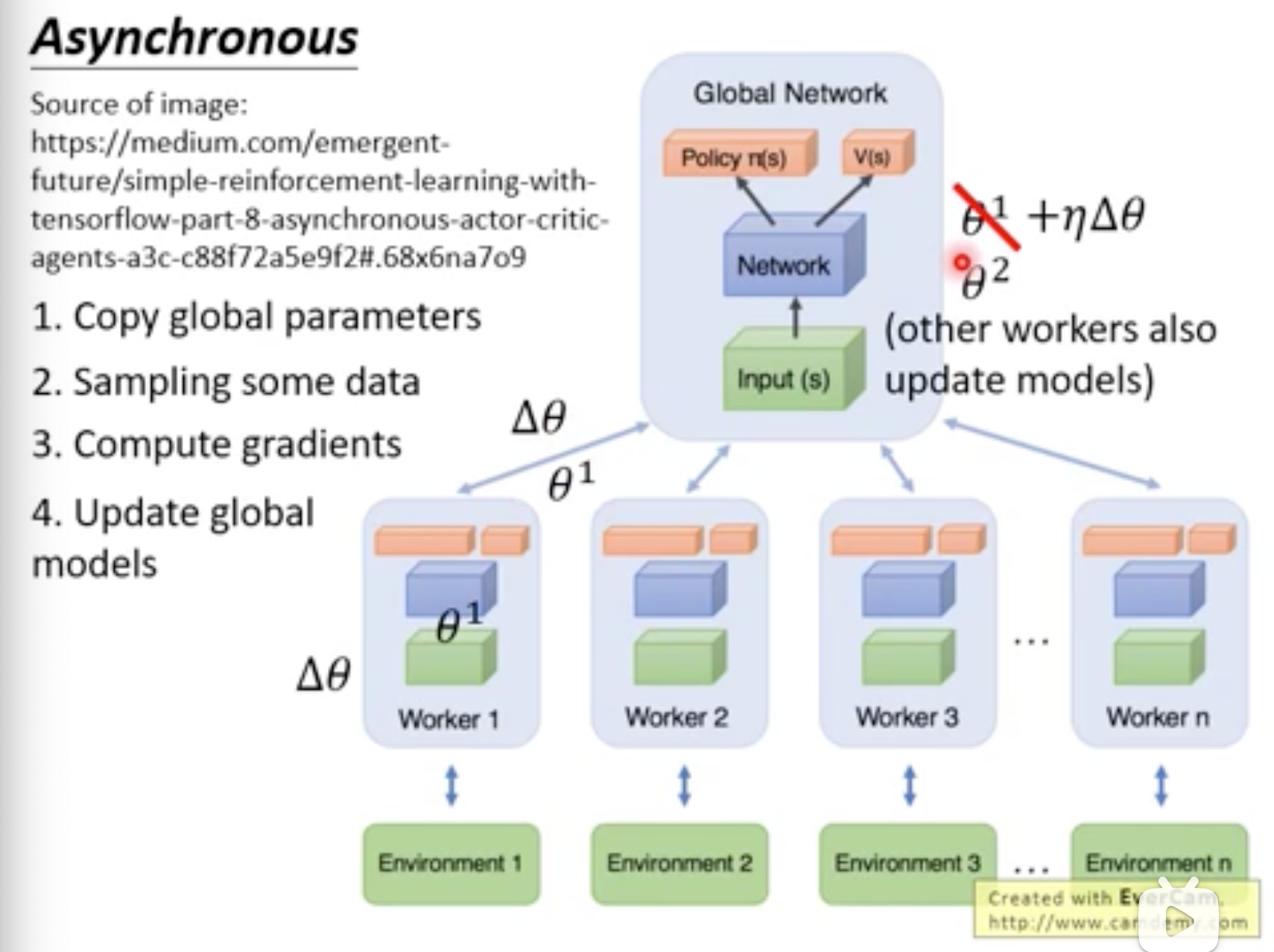
Asynchronous Advantage Actor-Critic(A3C)
Actor开了多个“影分身network”算出梯度给本体update参数。
PPO
属于actor-critic类的方法。没有p(x) => 无法求E => 构造q(x),通过q(x)间接计算E。这里的q(x)即为历史数据分布,PPO允许旧数据有限复用,但需要:
- 使用重要性权重,修正动作概率分布差异;
- 限制更新幅度,平衡数据复用和训练稳定性;
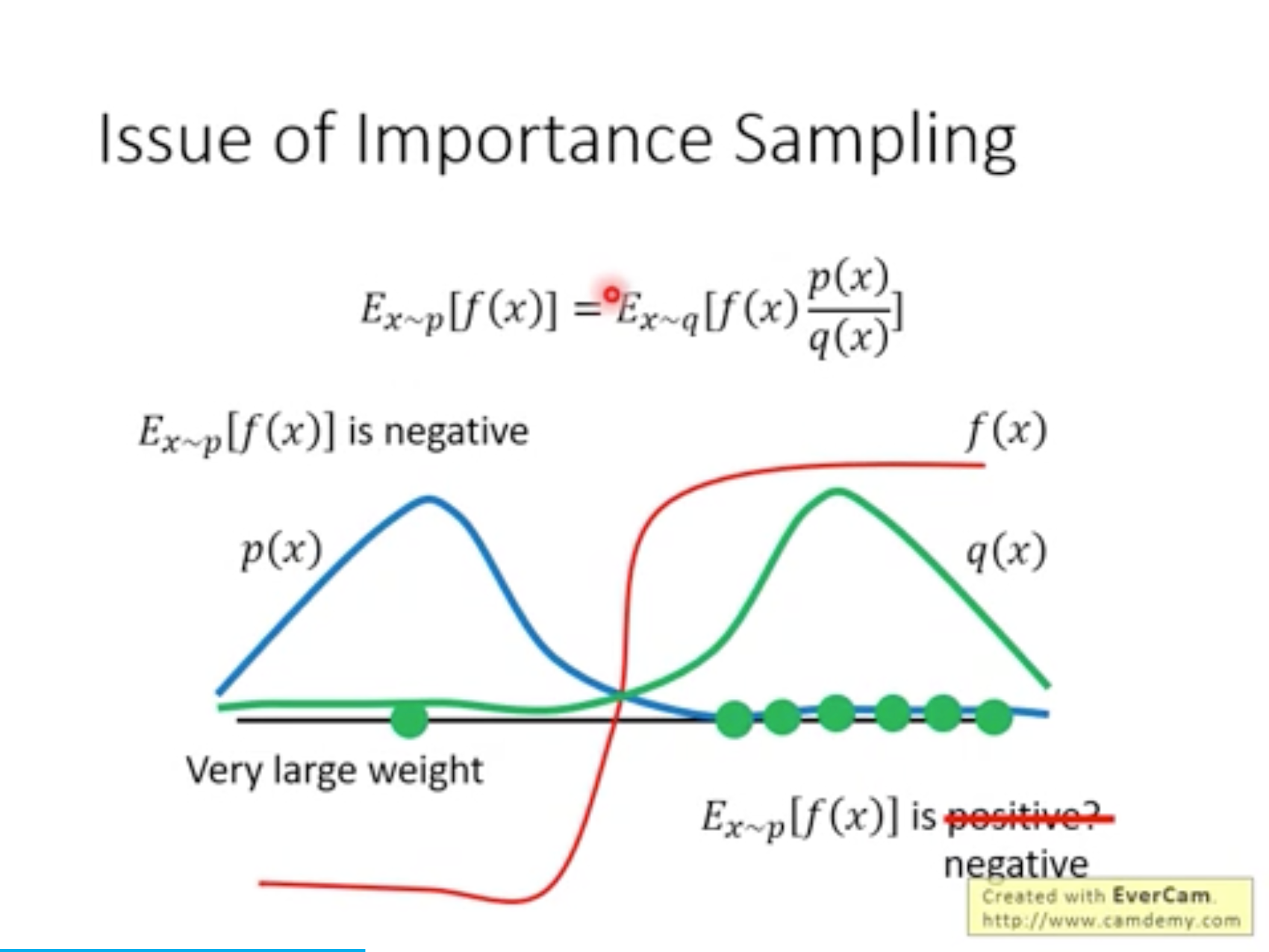
Importance Sampling
重要性采样:,但需约束分布差异(PPO通过裁剪实现)。

需要sample很多次,并且p与q不能差太多,才能实际保证期望是等价的。

PPO/TRPO
核心思想保证是\(\theta\)与\(\theta'\)两者的行为尽量一致,TRPO通过约束方式确保这一点,而PPO直接将两者行为distribution距离加入Loss中。

PPO Algorithm
- \(\theta'\)或者说\(\theta^k\)与环境互动的数据可以多次更新\(\theta\);
- 根据KL与预设阈值相对关系,动态调整KL所占用权重;
- 改进版本:裁剪策略更新幅度(Clipping)替代KL约束
![image]()
![image]()

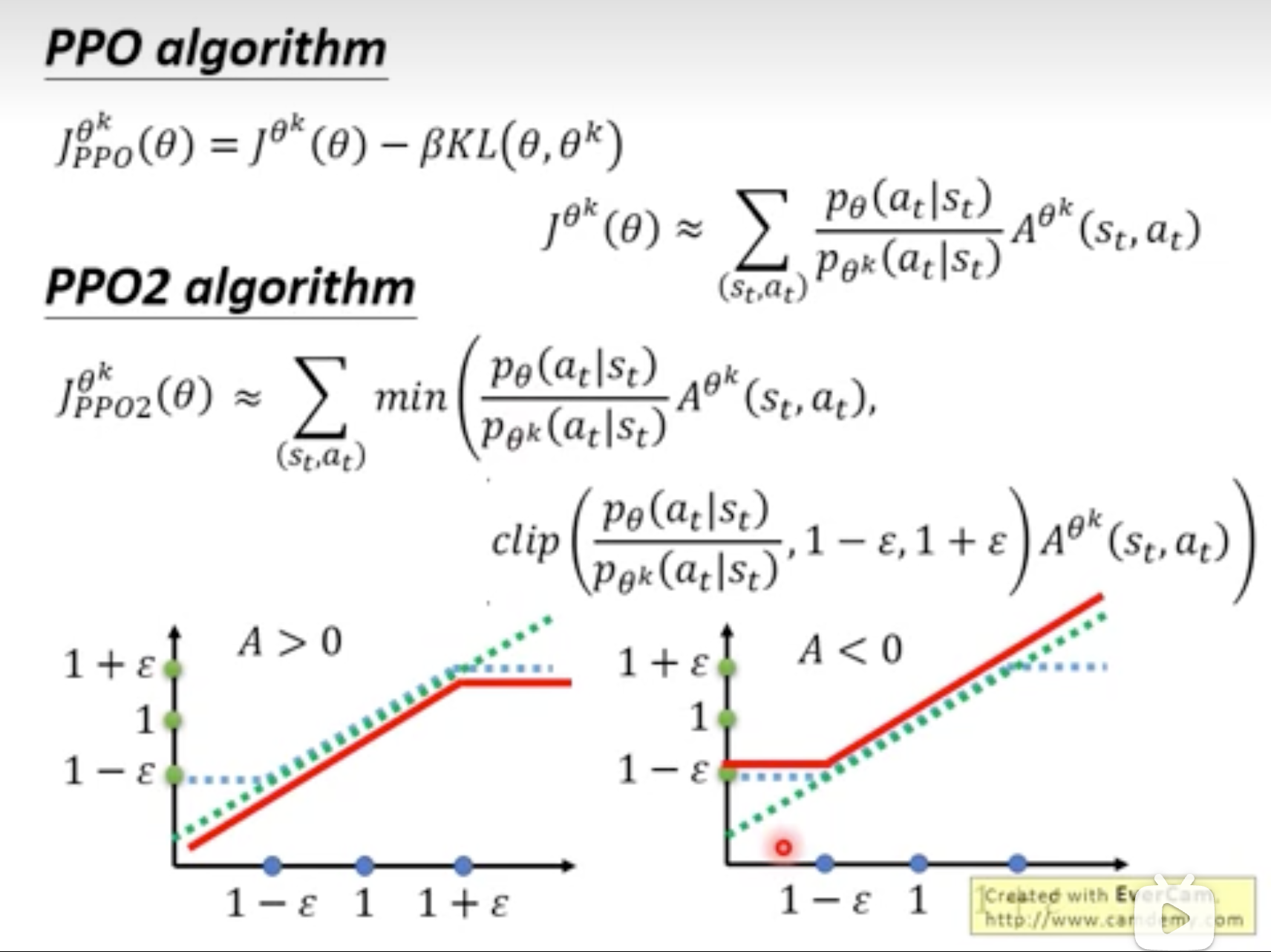
如何理解PPO中梯度函数?
只需要理解重要性采样系数与优势函数即可,min与clip用来截断梯度,防止policy模型与old模型偏离太远,使得经验数据失效。
当 A > 0时,系数过大会触发\(1 + \epsilon\)截断;
当 A < 0时,系数过小会触发\(1 - \epsilon\)截断;
PPO in LLM中,如何计算优势函数?
通常GAE (广义优势函数来计算)
其中,\(δ_t = r_t + γV(s_{t+1}) - V(s_t)\) 是TD误差。
超参数λ用来平衡方差与偏差:
当 λ=0:退化为单步 TD 误差(低方差,高偏差)。
当 λ=1:退化为蒙特卡洛回报(高方差,低偏差)。
从GAE公式可看出,计算每个token的优势函数都需要未来每时刻对应的r与V,实际实现过程通常先生成完整文本序列,再倒序计算每个token时刻的优势。
def compute_gae(rewards, values, gamma=0.99, lambda_=0.95):
deltas = rewards + gamma * values[1:] - values[:-1] # δ_t = r_t + γV(s_{t+1}) - V(s_t)
advantages = []
advantage = 0
for delta in reversed(deltas): # 从后向前计算
advantage = delta + gamma * lambda_ * advantage
advantages.append(advantage)
return list(reversed(advantages)) # 反转回正常顺序
如何Train Critic?
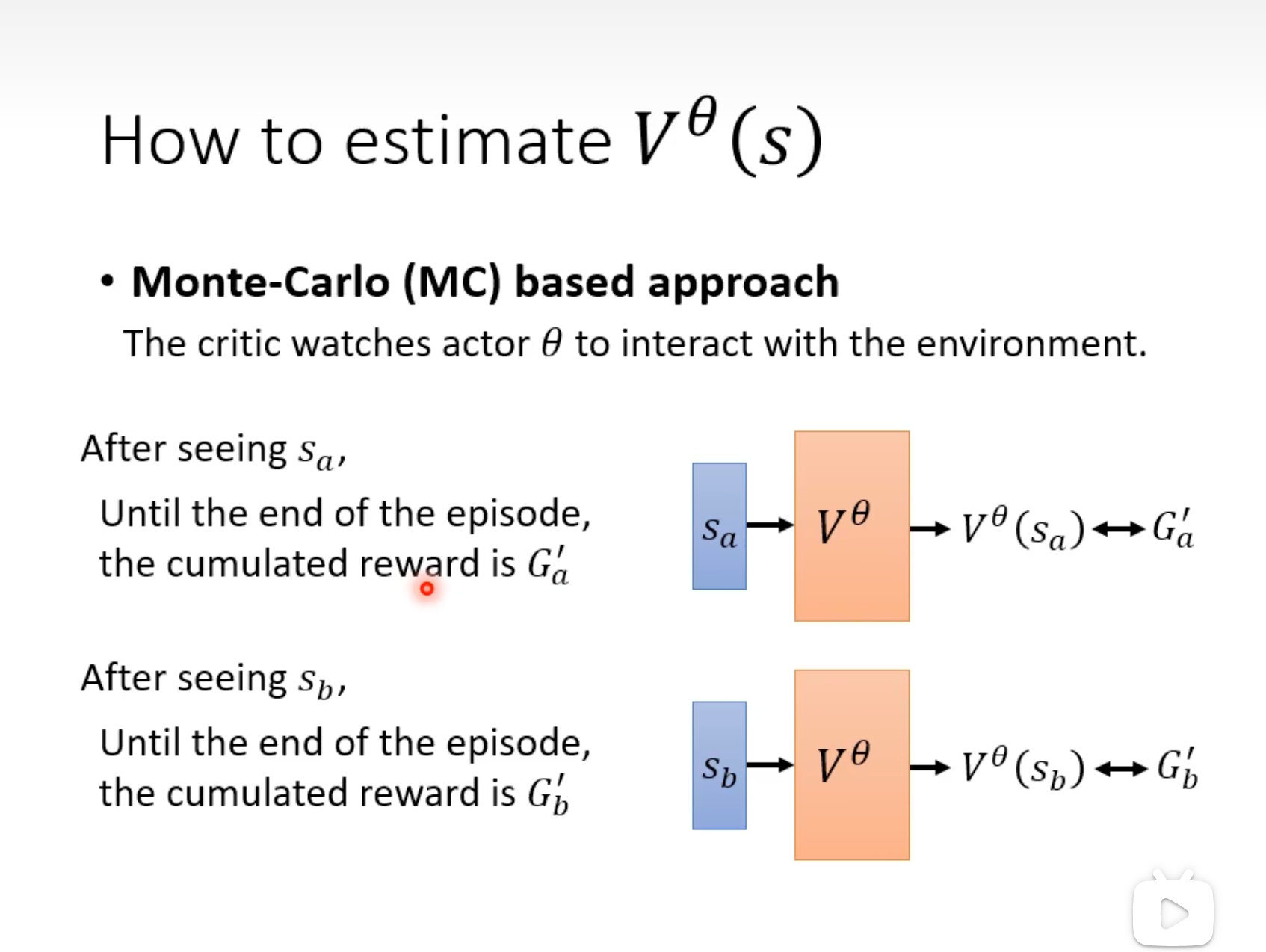
MC(Monte-Carlo)
每个episode之后,都可收集到训练数据。
TD(Temporal-Difference)
如果游戏很长,甚至一直不结束,则需要TD方法。
=> 如何不用完整episode就能训练呢?
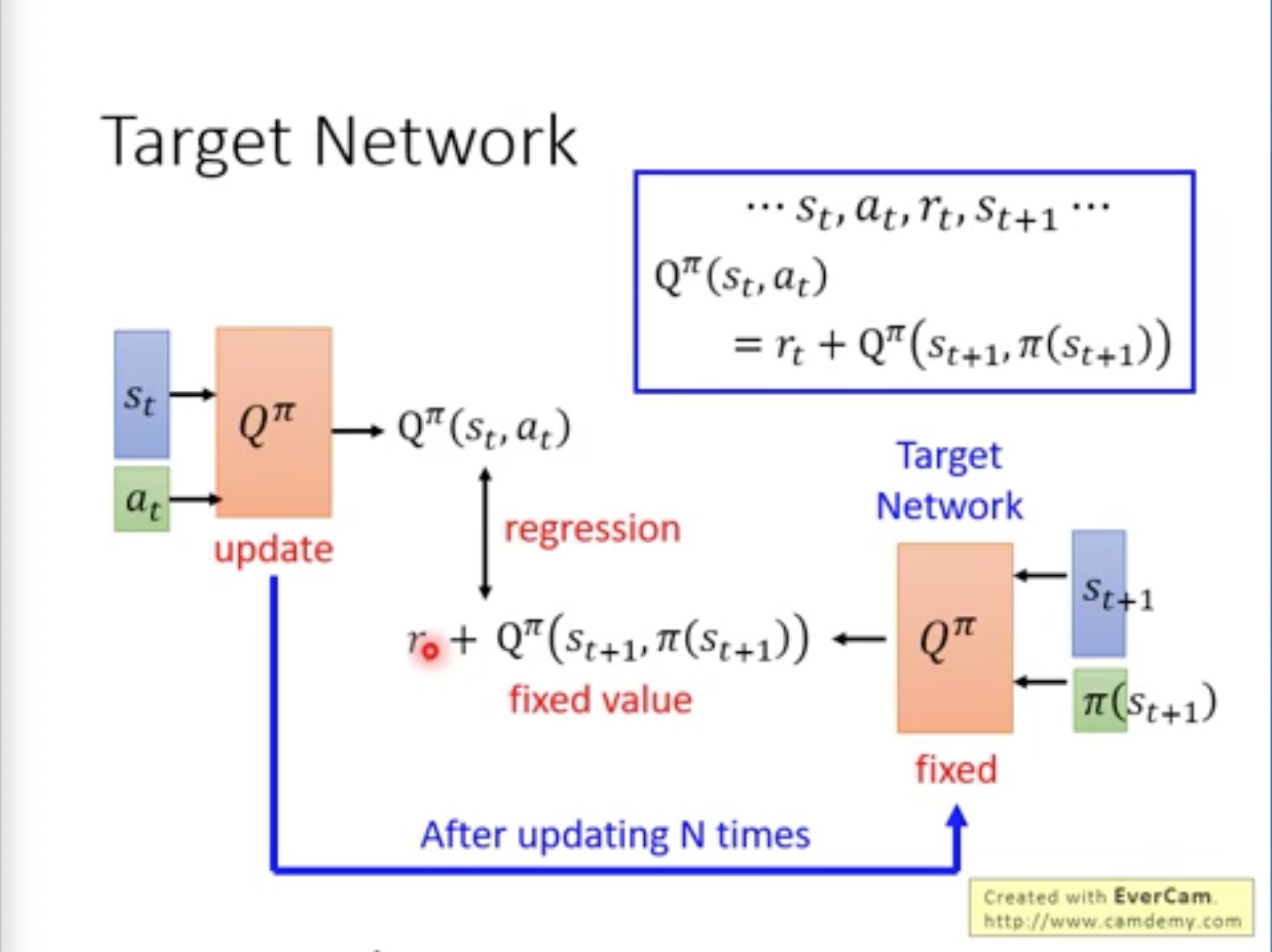
=> 已知\(s_t\), \(a_t\), \(r_t\), \(s_{t+1}\),应当Critic预测的应当满足如下递归公式约束。

MC vs TD
同样数据,MC与TD计算结果可能不同(MC -> 0; TD -> 3/4)

Q-Learning
假设已有actor \(\pi\),预测价值,属于value-based方法。早期用得比较多,但后来PPO出现后actor-critic方法开始流行。
分为value function \(V^{\pi}\),与state-action value function(s)\(Q^{\pi}(s, a)\): 假设在state s,强制采取action a (虽然最终不一定采取a ),对应的value function。
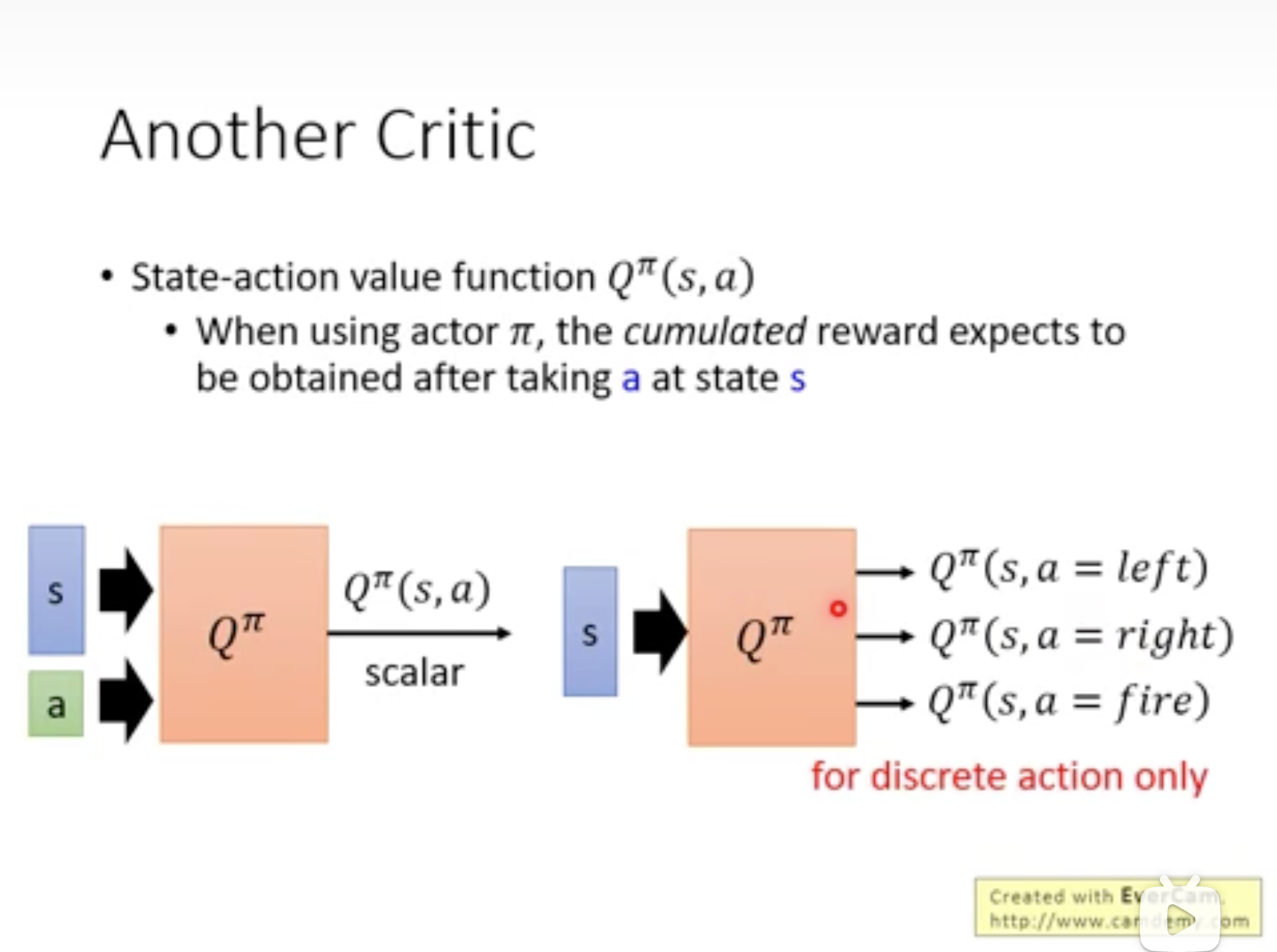

实战经验1:Target Network
将Target Network的参数固定
实战经验2:Exploration
Actor需要具备随机性,才能采样出多样的Trajectory,Actor才能收集到更好的经验。=> 专门设2一些随机性。

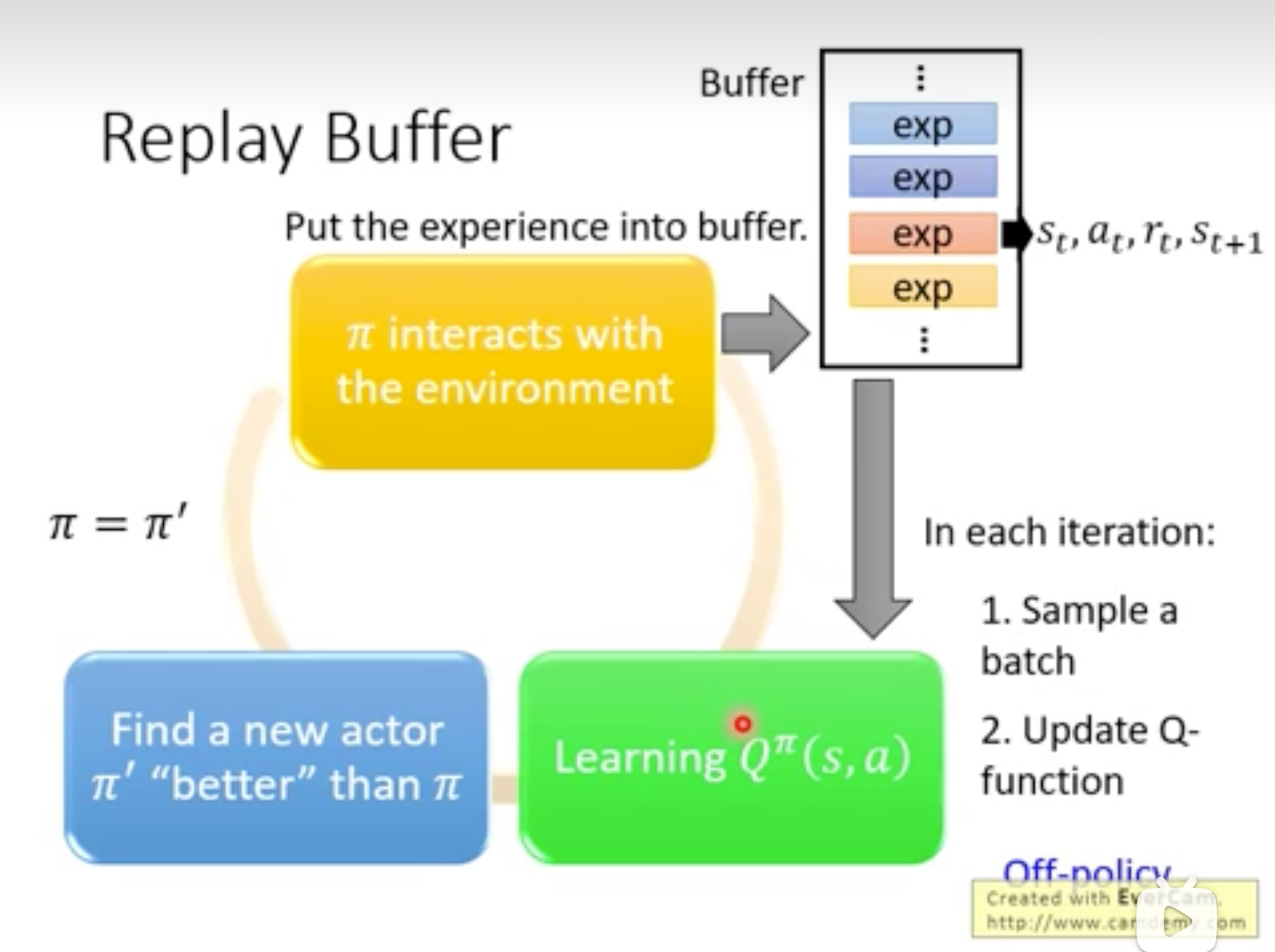
实战经验3:Replay Buffer
本来\(Q^{\pi}\)与\(\pi\)关联,但Buffer中实际上有其它policy的数据,虽然从理论上不符合定义,但这些历史数据可能增加Training数据的多样性。
Q-Learning Algorithm

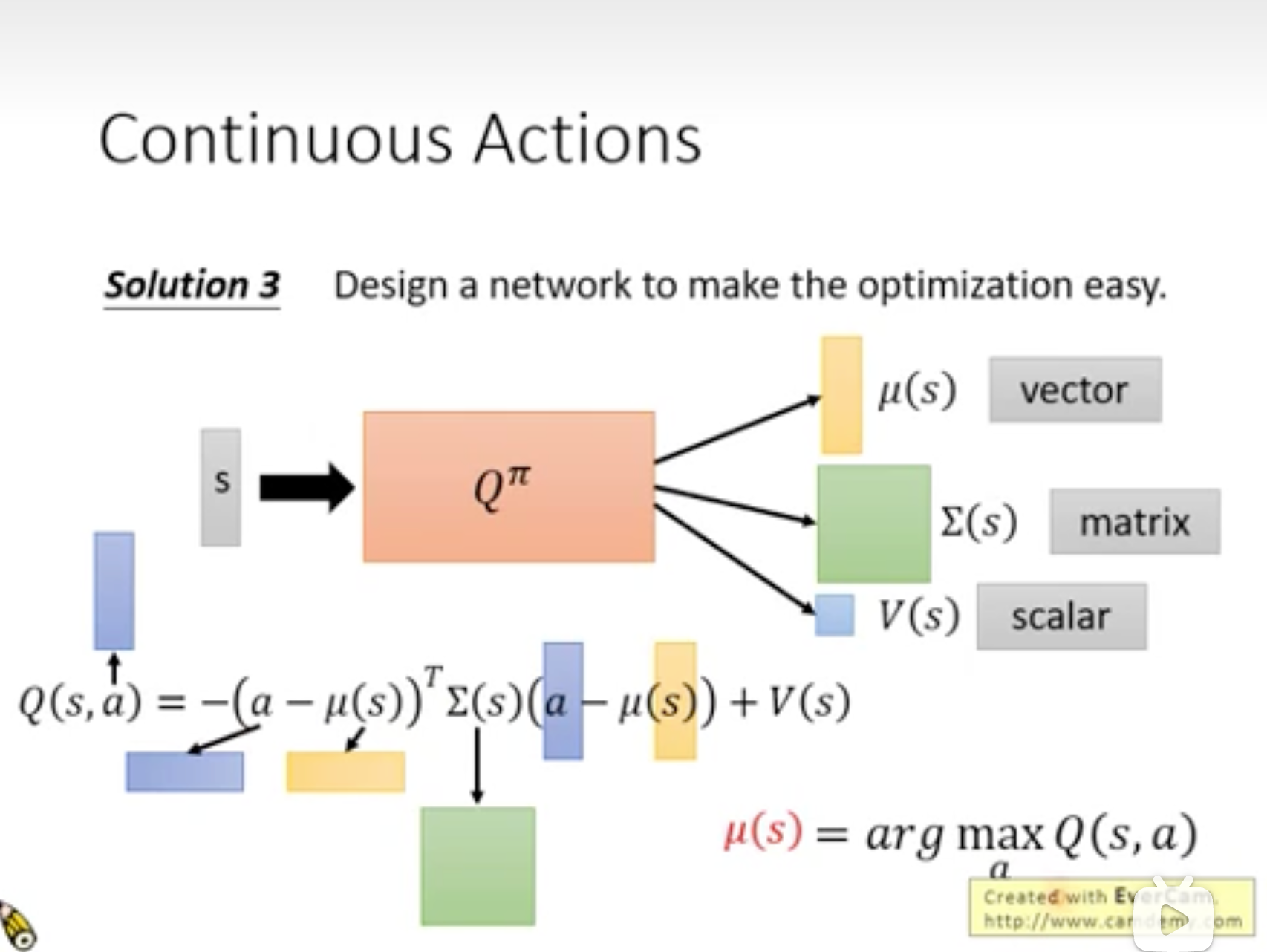
Continuous Actions
上述介绍action通常是离散动作,但很多场景action是continus,比如方向盘转多少度。
解决:1.采样;2.求最优a;

解决3:仅预测分布,让该分布的mean与a接近。
RL训练技巧
Reward Shaping
Sparse Reward问题:大部分情况没有Reward,如果episode之后才有Reward,例如 下围棋、RL初期冷启动。
=> 定义额外Reward -> 称为Reward Shaping
Curiosity
给agent加上好奇心,如果它发现有意义的新发现,就给额外奖励。
No Reward
很多真实场景无法定义Reward,也无法定义出明确的“额外Reward”。
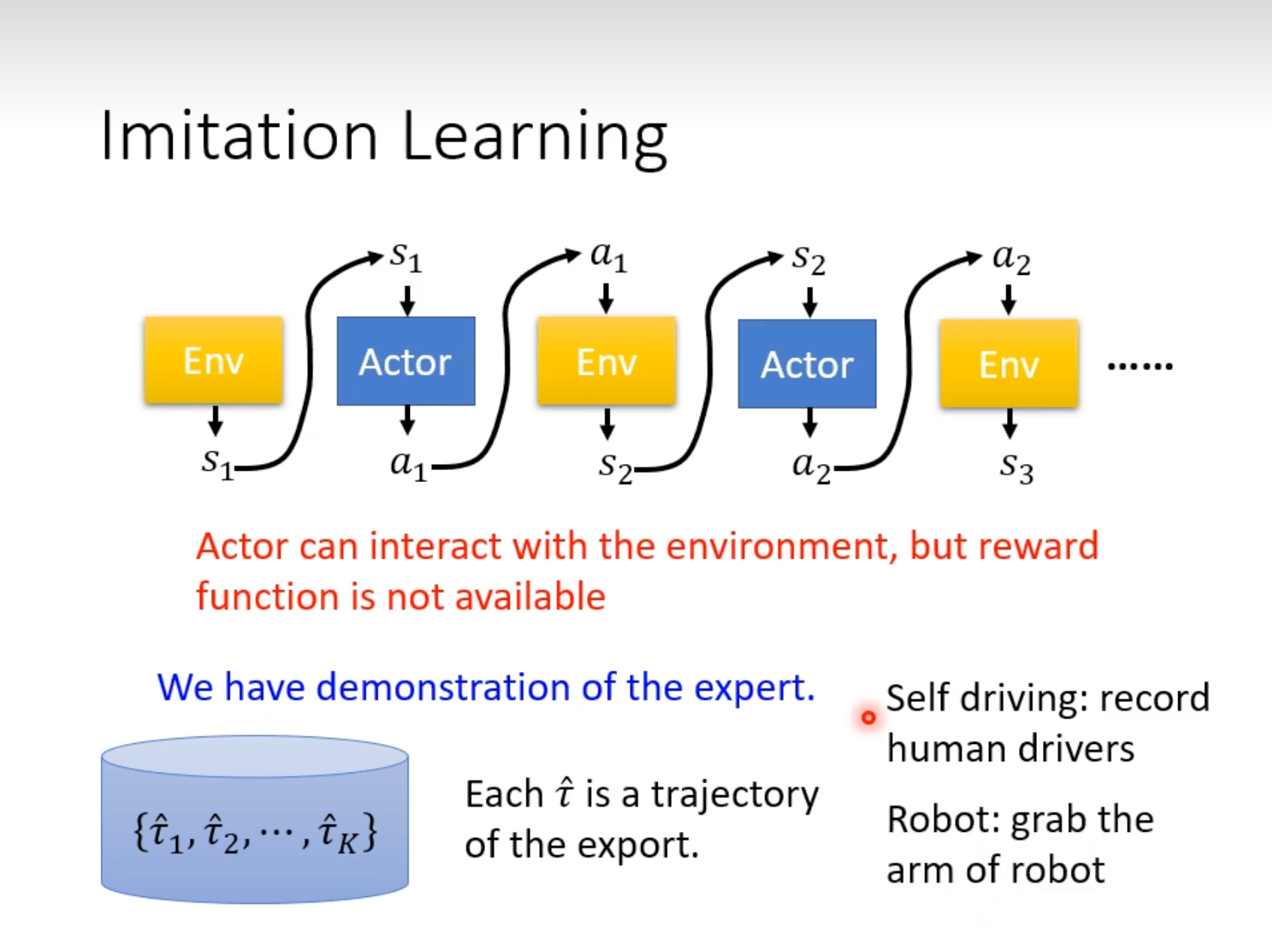
Imitation Learning
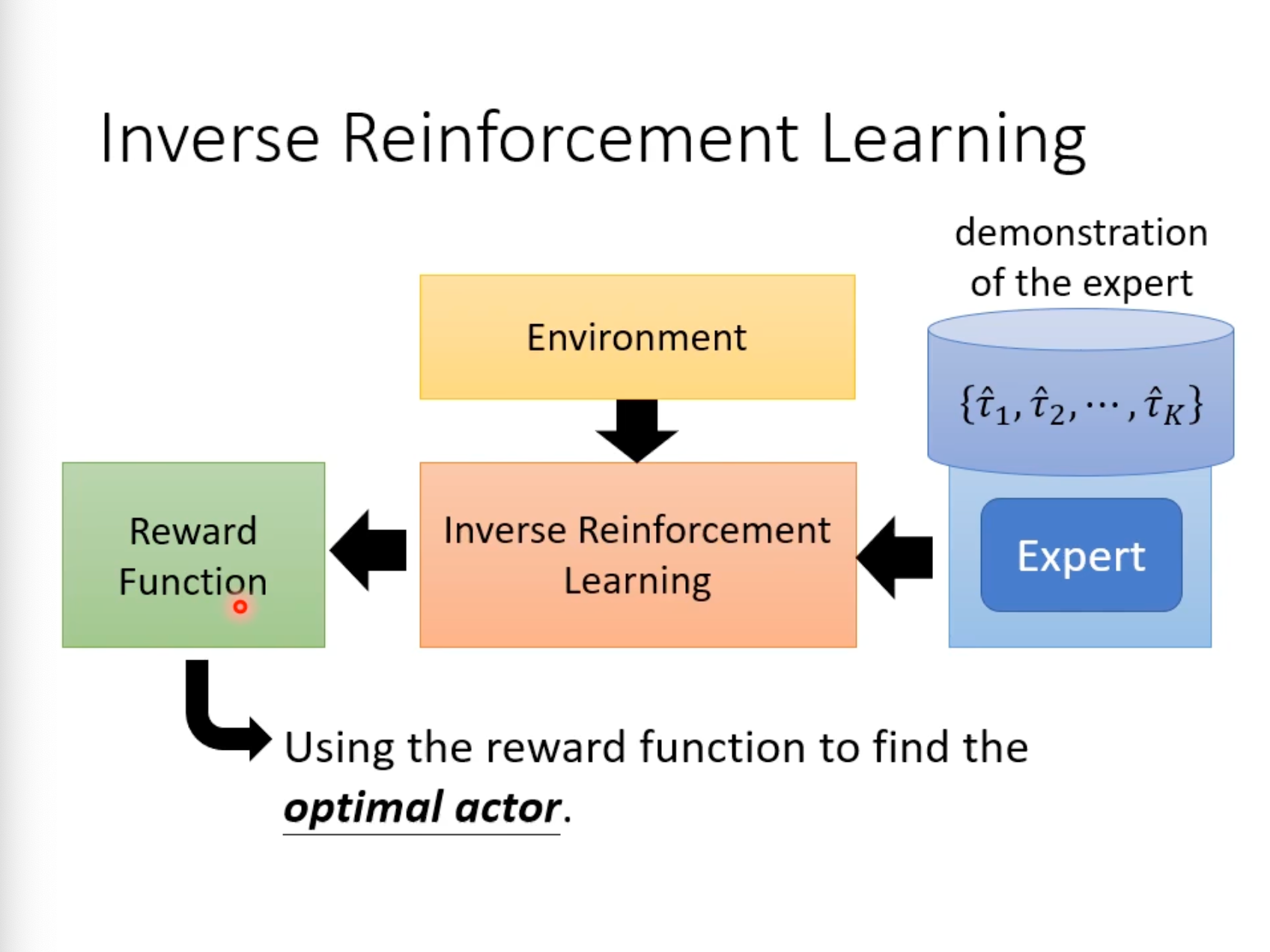
Inverse Reinforcement Learning
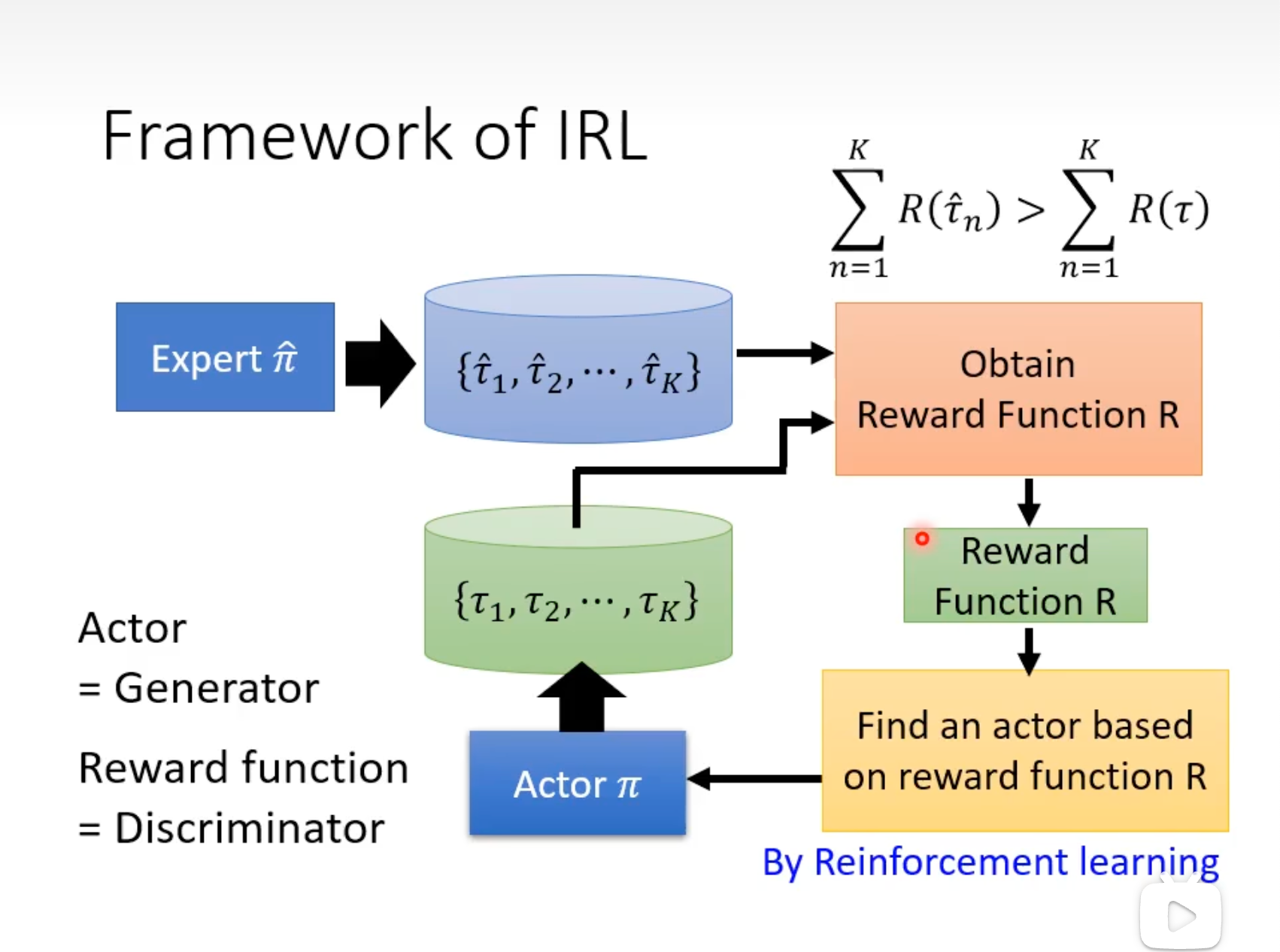
利用收集到的Expert经验,用IRL学出Reward Function,就可以用来训练Actor了。与GAN的工作机制比较像。
IRL的训练:
Q&A
Q: 纯policy-based与actor-critic方法的区别?
A:
| 维度 | Policy-Based | Actor-Critic |
|---|---|---|
| 是否依赖价值函数 | 纯策略梯度 | 必须用Critic模型预测 V(s) |
| 梯度信号来源 | 蒙特卡洛回报 Gt | 价值函数 A(s,a) |
| 方差 vs 偏差 | 高方差,无偏差 | 低方差,可能引入偏差 |
| 样本效率 | 低(需大量轨迹) | 高(复用经验) |
| 典型算法 | REINFORCE | PPO、A3C、SAC |
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18964118

 浙公网安备 33010602011771号
浙公网安备 33010602011771号