[PaperReading] FoundHand: Large-Scale Domain-Specific Learning for Controllable Hand Image Generation
目录
FoundHand: Large-Scale Domain-Specific Learning for Controllable Hand Image Generation
link
时间:24.12
单位:

相关领域:
作者相关工作:
- 二作:GenHeld手物交互抓取工作
- 三作:Linguang Zhang:UmeTrack、Stegotype的作者
被引次数:0
主页:https://ivl.cs.brown.edu/research/foundhand.html
TL; DR;
利用公开数据集构建首个10M大规模2D keypoints + mask的数据集,利用该数据训练FoundHand模型,用来生成repose hands、appearance transfer以及合成新视角。
Method
数据
所有数据使用原2D关节点生成虚拟相机内参,使用使用VIT跑出mano参数,投下来之后这样所有手都有对应的mask及skeleton了。
训练过程
- 学习的目标是生成给target latent feature所叠加的噪声$ \varepsilon_{\iota} $
- latent特征图 + 2D关节点编码成heatmap + Mask concat之后,由embedder抽为spatially-aligned feature patches
- style transfer: 固定skeleton,通过不同appearance特征的refer_image与target_image对来训练
- 训练过程通过数据增强,使得refer_image与target_image的mask不输入也能正常工作
推理过程
- pose transformations: 其输入skeleton不一定与ref_image有前后帧关系,是用户指定的skeleton(例如手动标注或从其他图像提取)
- view transformation: 新view的skeleton通过pose estimation估计出3D skeleton,再投影至新view编码为heatmap作为几何控制
- 通过给出参数y=1 or 0来决定训练与推理模式为 pose transformtions(时序上pose变换) 还是 view transformtions (新视角变换)
![]()

Experiment
Sytle Transfer

View Transformations

Pose Transformations
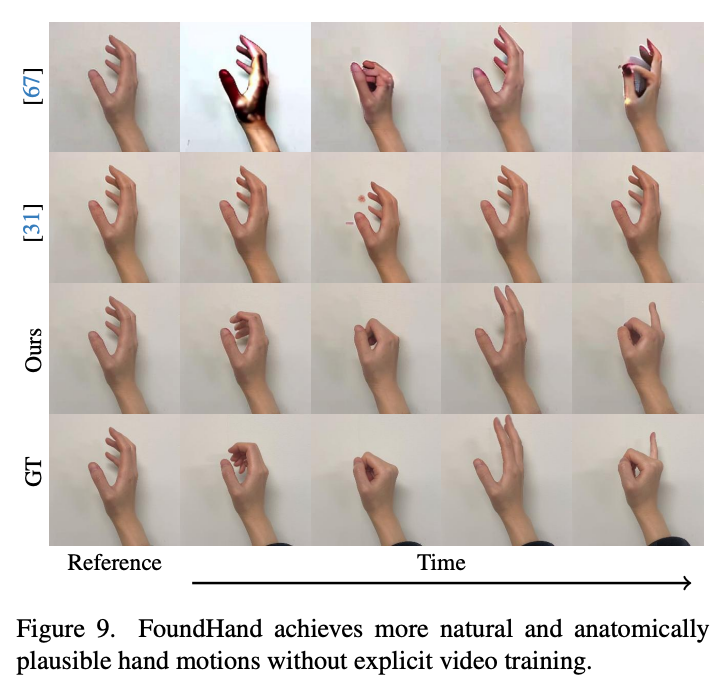
总结与思考
Contribution
公开数据集整合、ref_image + new skeleton(几何控制) => 新图像。new skeleton的来源分成了不同任务:
pose transformation:用户指定新skeleton
view transformation:新skeleton与ref_image中的skeleton具有相机几何映射关系
style transfer:训练时refer_image与target_image的风格一致;推理时控制refer_image风格来做style transfer
下游任务的拆分设计让该模型的应用价值得到体现
写作
- 数据集与Method整体合并为同一章来写
- 可视图比多,但定量实验不多
- 从页数来看,不是投CV顶会,仅用来刷影响力
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18889405

 浙公网安备 33010602011771号
浙公网安备 33010602011771号