[Paper Reading] HOIDiffusion: Generating Realistic 3D Hand-Object Interaction Data
HOIDiffusion: Generating Realistic 3D Hand-Object Interaction Data
link
时间:24.03
作者与单位:

主页:
https://mq-zhang1.github.io/HOIDiffusion/
TL;DR
一种使用文本与手物3D结构作为输入,对应生成图像的生成算法。
Method
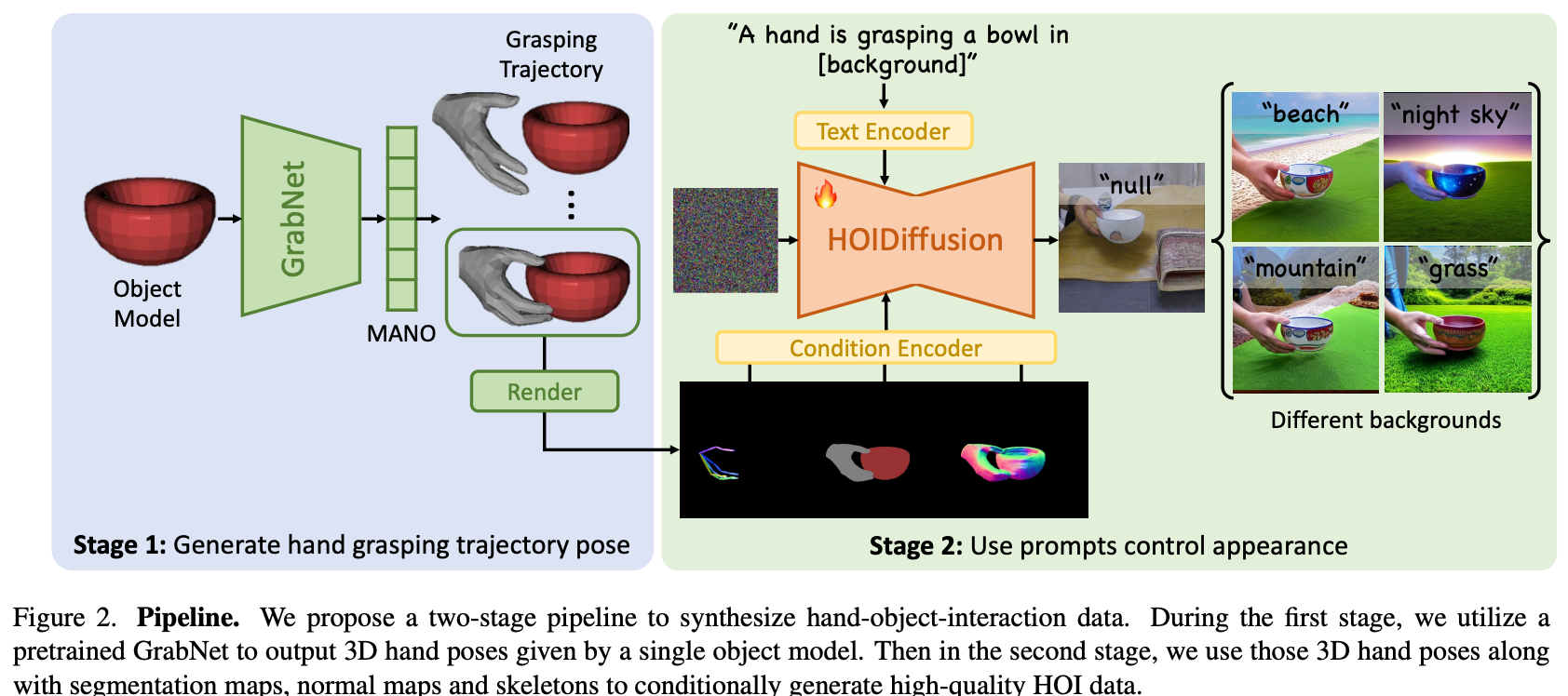
如上图所示,整个过程分为两阶段。
阶段一
将物体3D模型输入GrabNet中生成抓持物体对应的ManoPose轨迹
阶段二
利用轨迹得到的手物3D模型渲染出segmentation map、skeleton map、norm map输入到Diffusion中,再加上Text信息作为Prompt生成各种图像。
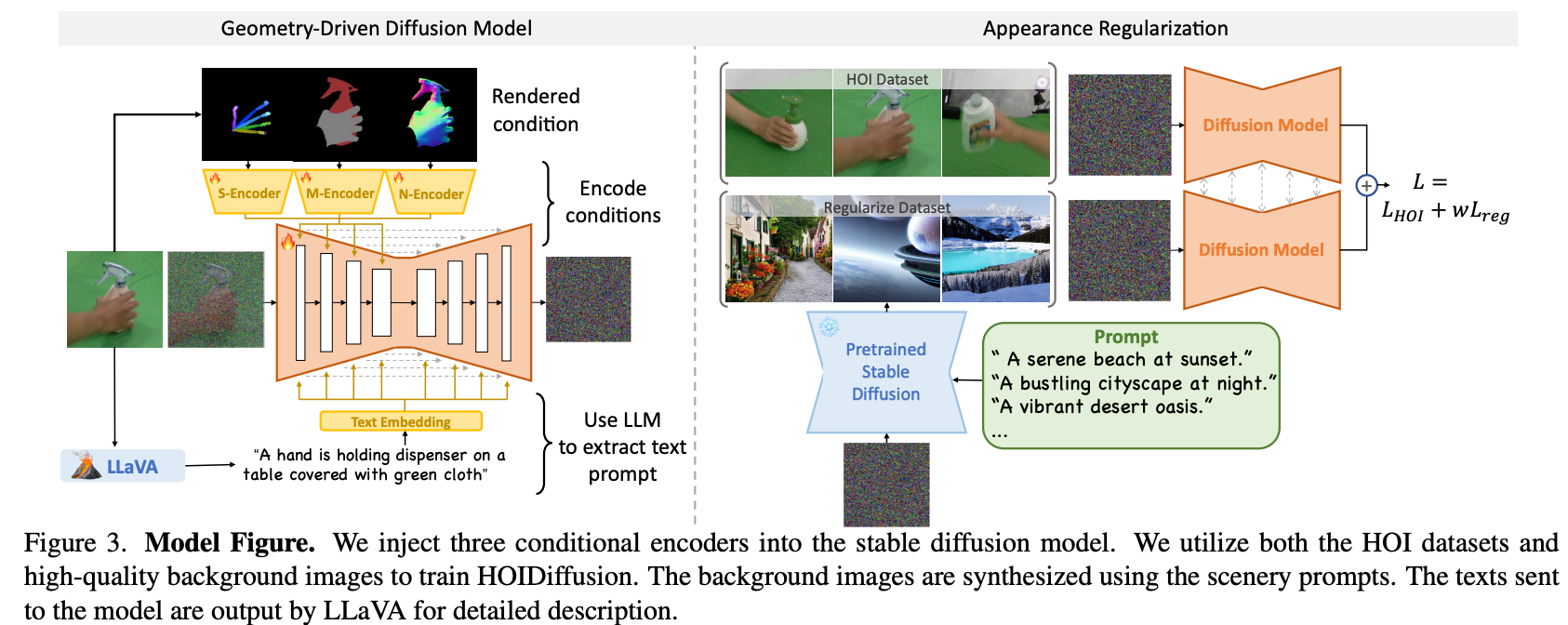
Training
既有3D手物模型、又有实际真实背景手物交互图像的HOI数据集太少,直接Finetune容易过拟合。本文在此基础上,使用ChatGPT生成了在各种背景下的"background buffer"(类似下面的Prompt),再将这些"background buffer"的text信息使用现成的text2image算法生成背景。通过这种方式扩充训练时的纯背景数据量,降低过拟合的可能性。
”A hand is grasping a bowl in [background]”
Code
参考配置:https://github.com/Mq-Zhang1/HOIDiffusion/blob/main/configs/train_dex.yaml
从config来看,HOIDiffusion是基于LDM的改进版,而非基于ControlNet的改进版
与LDM的区别
外挂CoAdapter抽几何控制特征融合至LDM UNet中联合训练
与ControlNet的区别
- ControlNet相对于LDM额外做的操作都没做
- 几何控制直接由外挂CoAdapter提取特征注入UNet中
- 相对ControlNet的control特征提取过程而言,未加入x_t, t等输入信息
因为没有额外复制出UNet,所以不用输入这些,但强行输入是否有额外效果->未知
算法实现
核心架构变动未配置于config yaml中,需要看train_dex.py,主要改动:
- 增加CoAdapter提取skeleton/mask/normal的特征,CoAdapter与SD模型是解耦开的两个模型,Loss计算与反传在main中整体零散实现;
- 将抽取的控制特征通过kwargs方式输入LatentDiffusion,再间接的输入到UNet中,UNet是经过改进的,但名称未变;
- Normal图是通过MiDas单目深度估计,再转换出来的Normal图(而非使用ManoMesh);
CoAdapter
由三个Adaptor组成,提取到的特征线性组合后返回。而Adapter是由conv组成的特征提取器。
UNetModel
与原UNet几乎一致,主要区别看forward函数,从LatentDiffusion中间接拿到的features_adapter特征通过与UNet中间特征相加的方式进行融合,参见代码。
Experiment
The entire training process costs approximately 12 hours on eight A100 GPUs.
10min, 效果怎么样?哪些分析实验有启发意义?
Q:表2中PCK的含义?
Furthermore, to evaluate the reinference accuracy, we estimate the MANO parameters of hands in images through a widely used single-view hand pose estimator [48], from which we derive the predicted hand joint positions. The percentage of correct keypoints(PCK) is used to measure the accuracy of predicted keypoints representing the hand poses in our data.
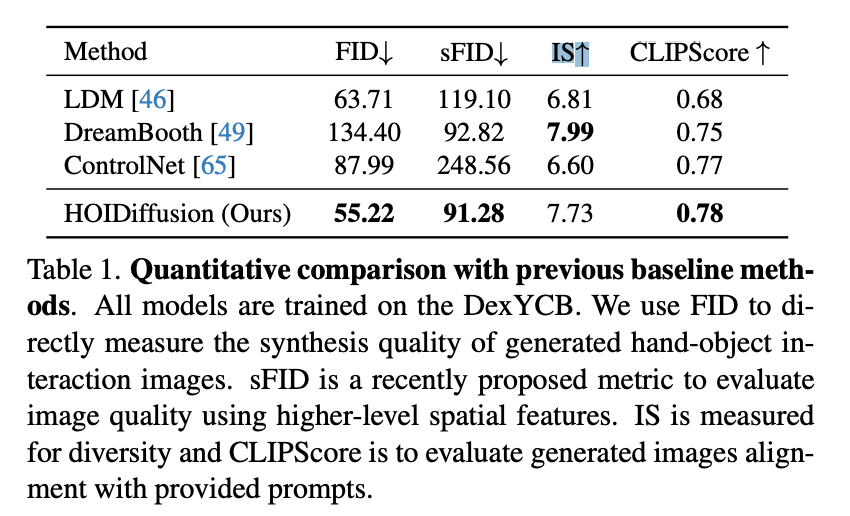
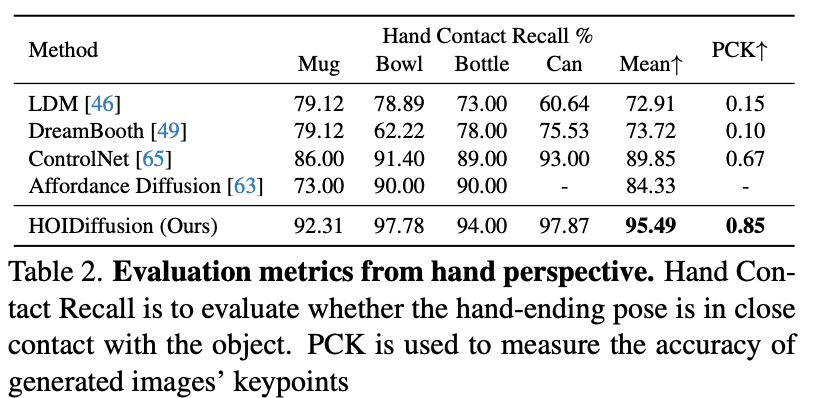
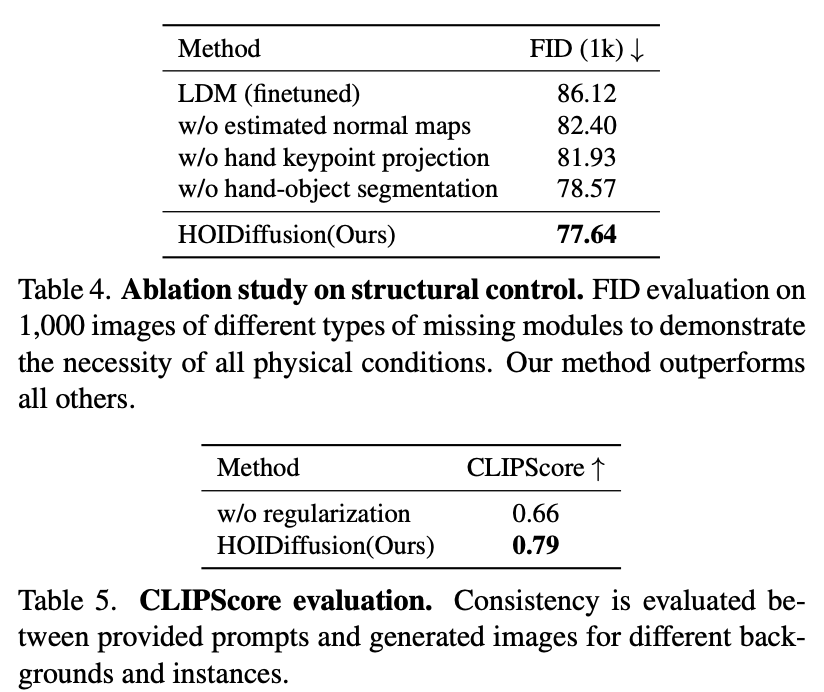
效果可视化


总结与发散
从合成效果来看,保真度还不错,可用来扩充数据丰富度
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18496227

 浙公网安备 33010602011771号
浙公网安备 33010602011771号