线上服务挂掉的原因排查过程(springboot服务突然不可用)
今天中午生产环境的springboot项目突然挂掉,排查挂掉的过程
现状:CPU使用率不高,内存使用率不高,日志无打印,gc正常
参考下下面的博客
Springboot服务突然不可用的几点可能原因
转载自:https://blog.csdn.net/qq447142862/article/details/130296866
前言
写代码时间长了难免会碰上几次线上服务突然不可用的状况,今天就简单来说说几个原因。
一 出现ECONNREFUSED
如果是接口调用时出现ECONNREFUSED,那么大概率是java进程挂了,在服务器上执行jps -v -l 命令看看进程是否在。
如果进程不在,那么应该是系统内存不足,被linux杀掉,查看系统杀进程的命令如下
sudo egrep -i -r 'killed process' /var/log
这个情况我在测试环境碰上几次,原因是同一个机器上跑了几个应用,其中一个应用有时占用大量内存,然后系统把内存最大的应用给杀了。
二 出现ECONNRESET
如果是接口调用返时出现ECONNRESET,那么应该是监听端口的全连接队列满了,系统无法接受新的TCP连接了。可以执行命令netstat -ano|grep 端口|grep LISTEN 查看全连接队列的数量。

第二列是全连接队列Recv-Q,如果队列满的时候这个值是100,这个值是springboot启动监听端口时设置的,取自server.tomcat.accept-count,默认为100。
按正常流程来看,Recv-Q的每一条记录都会被服务应用立即读取出来,放进connection队列中,再用工作线程处理数据,这里的connection队列默认最大值是10000。
所以会出现ECONNRESET的原因可能是此时系统的并发数已经超过10000+100。
三 接口无响应
如果是接口调用时响应很久都没返回,那么可以用top命令查看cpu使用率,如果java进程的cpu使用率高居不下,那大概率是GC线程是拼命运行中,可以用以下步骤验证。
执行命令top -Hp 进程id查看哪些线程占用cpu
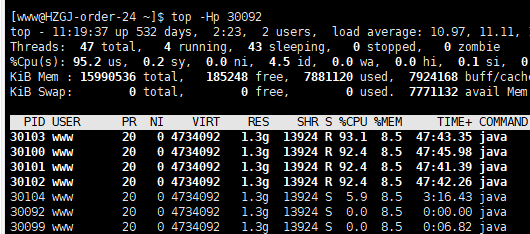
把占用率高的线程tid换成十六进制,如30100转成7594,执行命令jstack 进程id|grep 7594

如果看到是带GC字眼的线程,那么就可以确定是因为不断GC导致接口无法响应。如果用命令jstat -gc 进程id查看fullgc次数还在不断的上升。这个时候可以用jmap -dump:format=b,file=heapDump 进程id打印堆,再用Java VisualVM等工具解析,结合接口调用日志基本就可以定位问题所在了。而在这种情况出现前,还会有类似GC overhead limit exceeded的报错。
通常这种情况会在用户不停在做大量数据导出操作时出现。
四 接口无响应
接口调用时响应很久都没返回,还有一种现象是,出现out of memory错误后,应用占用cpu低,用jstat -gc 进程id查看GC也没有异常,看起来一切都正常,但偏偏无法响应请求。这种情况有可能是Tomcat的acceptor线程被杀掉,acceptor线程负责从操作系统的全连接队列提取socket连接,执行命令看看进程是否存在
jstack 进程id|grep Acceptor
排查问题的过程
集中监控服务无法访问问题分析
分析步骤
1、检查进程状态和cpu、内存使用情况;分析结果:正常,进程还在
2、查看集中监控日志,只打印redis连接开始和结束的日志;分析结果:后台没有收到请求,没有日志记录
3、查看集中监控服务对redis的连接情况(netstat -anp |grep 8085|grep 6380),没有redis连接阻塞
4、手动执行白名单接口(集中监控接口),访问超时504;分析结果:普通接口也无法访问,进程处于僵死状态
5、检查集中监控进程connection队列连接情况(netstat -ano | grep 8085|grep LISTEN),第二列Recv-Q的值为101;分析结果:请求连接超过了默认的10000,队列阻塞无法接收新的请求
定位结论:集中监控服务请求连接数(并发数),超过最大值10000+100,当队列(acceptCount)已满时,任何的连接请求都将被拒绝。
解决方案:
从服务高可用角度:
1、增加服务自监控,当服务不可用时,重启服务
2、使用负载均衡,降低单台服务的压力,可以使用f5或者增加一台nginx代理
从服务本身优化角度
1、对redis、第三方接口的请求都应该设置超时连接,调用26s后超时,一是要增加这一块后台接口的请求超时时间,二是要检查这块接口为什么查询没有返回
2、基于当前服务器的配置,可以调整connection队列,建议把默认的10000调整成20000
3、控制服务的线程数量,特别是高并发的地方需要进行控制,避免雪崩。
复习一下上次生产环境springboot服务假死的排查情况
集中监控服务无法访问问题分析
分析步骤
1、检查进程状态和cpu、内存使用情况;分析结果:正常,进程还在
2、查看集中监控日志,只打印redis连接开始和结束的日志;分析结果:后台没有收到请求,没有日志记录
3、查看集中监控服务对redis的连接情况(netstat -anp |grep 8085|grep 6380),没有redis连接阻塞
4、手动执行白名单接口(集中监控接口),访问超时504;分析结果:普通接口也无法访问,进程处于僵死状态
5、检查集中监控进程connection队列连接情况(netstat -ano | grep 8085|grep LISTEN),第二列Recv-Q的值为101;分析结果:请求连接超过了默认的10000,队列阻塞无法接收新的请求
定位结论:集中监控服务请求连接数(并发数),超过最大值10000+100,当队列(acceptCount)已满时,任何的连接请求都将被拒绝。
解决方案:
从服务高可用角度:
1、增加服务自监控,当服务不可用时,重启服务
2、使用负载均衡,降低单台服务的压力,可以使用f5或者增加一台nginx代理
从服务本身优化角度
1、基于当前服务器的配置,可以调整connection队列,建议把默认的10000调整成20000
2、控制服务的线程数量,特别是高并发的地方需要进行控制,避免雪崩。
上次的结论误区
以为生产环境的springboot端口并发数满了导致的,结果今天测试环境也发生了同样的情况,因此可以下结论:不是高并发的原因。
重新开始排查
1、检查springboot并发数上限:已经上限
https://blog.csdn.net/qq447142862/article/details/130296866
2、检查mysql是否死锁:没有死锁
https://blog.csdn.net/zy103118/article/details/125796483
https://blog.csdn.net/wufagang/article/details/125554792
3、检查mysql连接数是否上限:没有上限
https://blog.csdn.net/weixin_45827976/article/details/131081083
4、检查redis连接数是否上限:没有上限
https://blog.csdn.net/hefeng_aspnet/article/details/130554461
5、检查springboot服务的CPU占用情况和内存使用率情况:均正常
6、检查springboot服务的垃圾回收情况:非正常,堆各个区域的占用内存一尘不变
7、检查springboot的堆栈信息:线程无限等待,线程挂起(TIMED_WAITING)
7(1)打印堆栈信息到文件,jstack -l pid > test.log
7(2)置顶test.log 找到TIMED_WAITING状态的线程起始位置
发现WebSocketServer类在onOpen创建会话时频繁出现TIMED_WAITING线程挂起状态
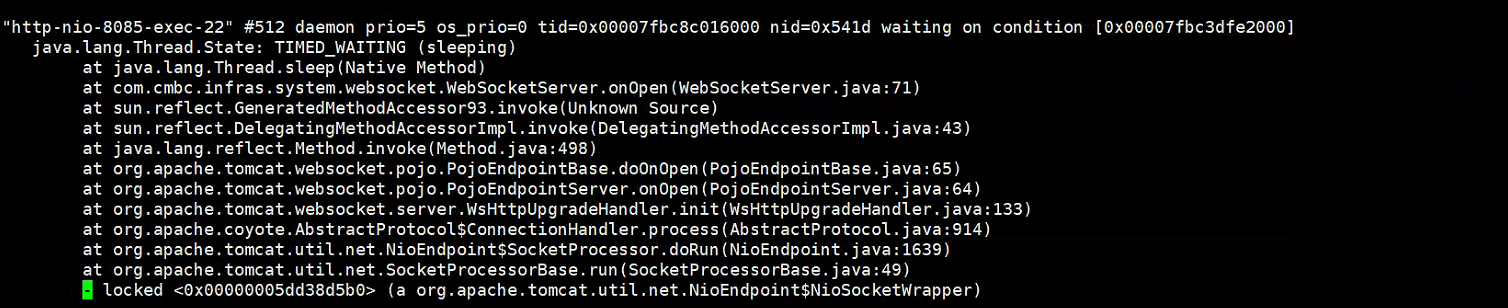
经过了特别多的TIMED_WAITING线程挂起状态之后,往下继续观察,从而又导致了其他的线程等待
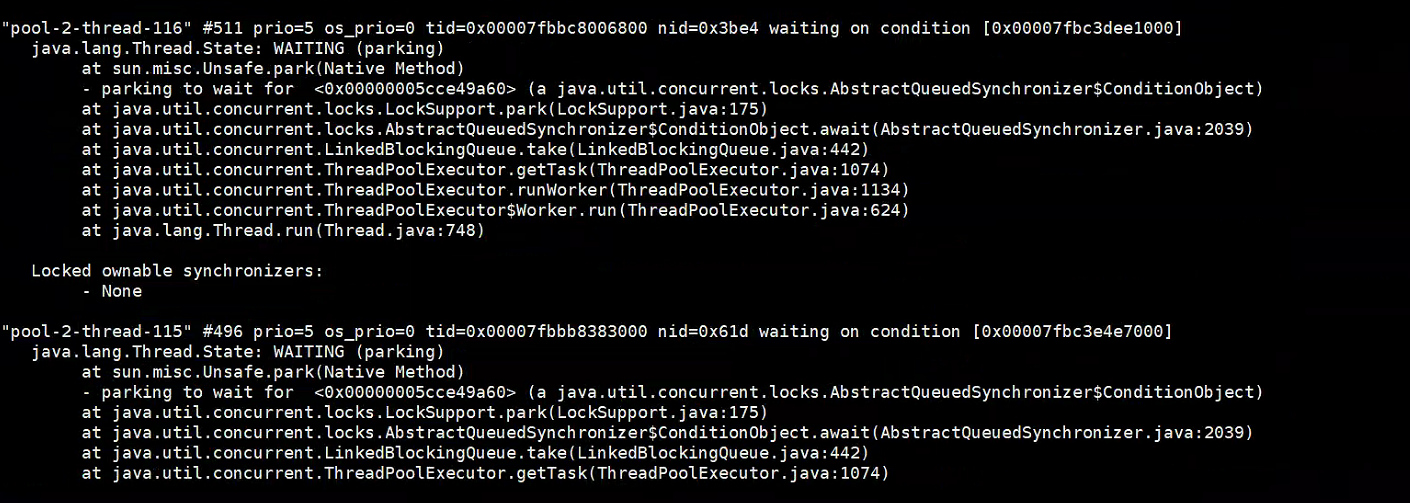
定位到WebSocketServer的onOpen创建会话的代码处,查看代码逻辑,每次onOpen时会从redis中获取token,如果redis中的token不存在,则调用接口获取token,并存入redis,如果没有取到缓存,则循环睡眠N秒,再次重新获取。
经过分析得出结论
结合上次排查生产环境的日志和各种情况重新得出以下结论
- CPU/内存使用率不高(因为所有线程挂起,不消耗CPU时间片,故不高)
- GC情况 堆各个区域的占用内存一尘不变(系统拒绝所有请求,没有做任何处理,故内存保持不变)
- 频繁打印与redis建立连接和释放连接的日志(redis没有阻塞,正常工作,而且springboot中的业务在不断的和redis建立和释放连接,说明一直在查询redis库的数据)
- 定位到上面的堆栈信息和具体代码后,推断可以坐实了,由于线程没有获取到缓存,线程状态处于TIMED_WAITING,如果大部分线程状态都处于TIMED_WAITING,超过了springboot的线程数上限,则资源全部占用完,将直接拒绝掉新的请求处理线程
- 分析为何线程没有获取到缓存
- 原因一:redis服务异常(很明显,redis是正常的,直接pass)
- 原因二:调用接口失败(八九不离十就是这个问题了)
至于调用接口失败的问题分析
这个接口是HttpRequest发起的远程调用接口,服务部署之后的前段时间是运行正常的,接口正常调用的,过若干天之后,接口就调不通了,状态码400,基于对400错误的理解,就是服务调用方出现了问题,经过百度得出结论
原来http在发送get请求的时候,会对cookie进行叠加,长时间的运转呢,导致cookie越来越长,最终出现header超长的400错误
解决办法:确认服务双端对cookie没有业务需求的处理,服务调用方禁用cookie 即可
HttpRequest.get(url).disableCookie().timeout(3000).execute().body();
禁用cookie之后,接口调用应该就没问题了(实测就是没问题了)
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号