
关于Iceberg数据湖的正确使用方式 转载大佬的博客就不声明了,在此标题处声明,非全原创,感谢!
实践数据湖iceberg 第一课 入门
实践数据湖iceberg 第二课 iceberg基于hadoop的底层数据格式
实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
实践数据湖iceberg 第四课 在sqlclient中,以sql方式从kafka读数据到iceberg(升级版本到flink1.12.7)
实践数据湖iceberg 第五课 hive catalog特点
实践数据湖iceberg 第六课 从kafka写入到iceberg失败问题 解决
实践数据湖iceberg 第七课 实时写入到iceberg
实践数据湖iceberg 第八课 hive与iceberg集成
实践数据湖iceberg 第九课 合并小文件
实践数据湖iceberg 第十课 快照删除
实践数据湖iceberg 第十一课 测试分区表完整流程(造数、建表、合并、删快照)
实践数据湖iceberg 第十二课 catalog是什么
实践数据湖iceberg 第十三课 metadata比数据文件大很多倍的问题
实践数据湖iceberg 第十四课 元数据合并(解决元数据随时间增加而元数据膨胀的问题)
实践数据湖iceberg 第十五课 spark安装与集成iceberg(jersey包冲突)
实践数据湖iceberg 第十六课 通过spark3打开iceberg的认知之门
实践数据湖iceberg 第十七课 hadoop2.7,spark3 on yarn运行iceberg配置
实践数据湖iceberg 第十八课 多种客户端与iceberg交互启动命令(常用命令)
实践数据湖iceberg 第十九课 flink count iceberg,无结果问题
实践数据湖iceberg 第二十课 flink + iceberg CDC场景(版本问题,测试失败)
实践数据湖iceberg 第二十一课 flink1.13.5 + iceberg0.131 CDC(测试成功INSERT,变更操作失败)
实践数据湖iceberg 第二十二课 flink1.13.5 + iceberg0.131 CDC(CRUD测试成功)
实践数据湖iceberg 第二十三课 flink-sql从checkpoint重启
实践数据湖iceberg 第二十四课 iceberg元数据详细解析
实践数据湖iceberg 第二十五课 后台运行flink sql 增删改的效果
实践数据湖iceberg 第二十六课 checkpoint设置方法
实践数据湖iceberg 第二十七课 flink cdc 测试程序故障重启:能从上次checkpoint点继续工作
实践数据湖iceberg 第二十八课 把公有仓库上不存在的包部署到本地仓库
实践数据湖iceberg 第二十九课 如何优雅高效获取flink的jobId
实践数据湖iceberg 第三十课 mysql->iceberg,不同客户端有时区问题
实践数据湖iceberg 更多的内容目录
- 一,安装hdfs(主要使用hdfs,yarn,hive组件)
- 二,Hive数仓整合iceberg(重点)
- 三,使用Flink连接hive/hadoop操作iceberg(非重点)
- 四,使用Trino连接hive/hadoop操作iceberg(重点)
- 五,遇到的问题
- 1,执行HIVE的创建表语句报错:Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535
- 2,执行HIVE的insert语句报错,或运行hadoop的mapreduce测试jar报错,查看日志:/bin/bash: /bin/java: No such file or directory
- 3,hiveserver2启动失败问题,启动不了端口10000解决过程
- 4,beeline操作iceberg表插入数据时报错:Permission denied: user=anonymous, access=EXECUTE, inode="/tmp/hadoop-yarn":root:supergroup:drwx------
- 5,beeline操作iceberg表插入数据时报错:User: root is not allowed to impersonate root (state=08S01,code=1)
- 6,beeline操作iceberg表插入数据时报错:Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask(state=08S01,code=2)
- 7,Hive任务执行报错:FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2)
Iceberg官方文档:https://iceberg.apache.org/docs/0.13.1/hive/
Trino官方文档:https://trino.io/docs/current/installation/deployment.html
一,安装hdfs(主要使用hdfs,yarn,hive组件)
参考文章:Hadoop分布式存储和计算MapReduce的使用以及Hive数据仓库等内容精讲
零碎知识点
centos修改主机名命令
hostnamectl set-hostname vmone
两台centos之间传送文件
scp -r /home/data root@192.168.1.33:/home/new-data
Linux在线安装jdk,会自动装在/usr/lib/jvm下
yum install -y java-1.8.0-openjdk-devel.x86_64
使用上面的博客进行安装hadoop环境,安装好之后继续
二,Hive数仓整合iceberg(重点)
1,前提
Hadoop的三个服务全部运行,并且Hive要和Hadoop安装在同一个机器上
环境:
hadoop 3.2.4
hive 3.1.2
iceberg 0.13.1
jdk 1.8
版本匹配很重要,切记!
2,下载安装mysql
参考:https://www.cnblogs.com/fantongxue/p/12443575.html
Hive可以使用mysql来存储元数据信息,这里使用Hive的默认derby数据库
3,下载安装Hive数仓
下载地址:https://dlcdn.apache.org/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
配置安装参考:https://www.cnblogs.com/fantongxue/p/14044521.html#十六hive数据仓库
4,在 Hive 中启用 Iceberg 支持
在 https://iceberg.apache.org/releases/ 下载iceberg-hive-runtime-0.13.1.jar
将 iceberg-hive-runtime-0.13.1.jar移到hive lib目录下,配置hive-site.xml, 添加如下配置
4.1 hive-site.xml的配置
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop:9083</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<!--
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2048</value>
</property>
-->
</configuration>
这里再展示一下其他的配置!
4.2 hadoop的core-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.2.4/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
4.3 hadoop的hdfs-site.xml配置
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9868</value>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>2097152</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>256m</value>
</property>
</configuration>
4.4 hadoop的yarn-site.xml配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!--
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1700</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1700</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>128</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value>
</property>
-->
</configuration>
4.5 hadoop的mapred-site.xml配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.4</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.4</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.4</value>
</property>
</configuration>
编辑conf/hive-env.sh,配置环境变量
export HADOOP_NAME=/usr/local/hadoop-3.2.4
export HIVE_CONF_DIR=/usr/local/apache-hive-2.3.9-bin/conf
export JAVA_HOME=/usr/local/jdk1.8.0_301
Hive的日志默认在/tmp/root下,监控日志查看操作过程 tail -f -n 200 /tmp/root/hive.log
启动hive的元数据服务,开启的目的是可以提供一个链接供其他(Flink,Spark,Trino等等)来访问元数据信息
./hive --service metastore &
启动server
./hive --service hiveserver2 -hiveconf hive.server2.thrift.port=10000 &
启动成功之后访问http://localhost:10002可以进入HiveServer2页面
初始化元数据
schematool --initSchema -dbType derby
连接hive服务(加上root权限,否则操作iceberg表时会报错,没有权限的错)
./beeline -u jdbc:hive2://hadoop:10000 -n root
[root@master bin]# ./beeline -u jdbc:hive2://hadoop:10000
Connecting to jdbc:hive2://master:10000
Connected to: Apache Hive (version 3.0.0)
Driver: Hive JDBC (version 3.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.0.0 by Apache Hive
0: jdbc:hive2://hadoop:10000> show databases;
INFO : Compiling command(queryId=root_20190110173600_9c92ad1f-b0ca-43a6-ae54-d52decee31af): show databases
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=root_20190110173600_9c92ad1f-b0ca-43a6-ae54-d52decee31af); Time taken: 1.392 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20190110173600_9c92ad1f-b0ca-43a6-ae54-d52decee31af): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20190110173600_9c92ad1f-b0ca-43a6-ae54-d52decee31af); Time taken: 0.053 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| default |
+----------------+
2 rows selected (2.019 seconds)
0: jdbc:hive2://hadoop:10000>
在beeline客户端进行以下操作:
每次客户端关闭并重新开启时,添加runtime包和注册HiveCatalog的过程都要重新来一遍,最好配置到配置文件中,不用重复在客户端设置。
命令配置/配置文件配置方式参考:https://segmentfault.com/a/1190000021116522/
添加runtime包到hive的classpath下
add jar /usr/local/iceberg-hive-runtime-0.13.1.jar;
注册一个HiveCatalog
SET iceberg.catalog.another_hive.type=hive;
SET iceberg.catalog.another_hive.uri=thrift://hadoop:9083;
SET iceberg.catalog.another_hive.clients=5;
SET iceberg.catalog.another_hive.warehouse=hdfs://hadoop:8020/warehouse;
直接创建Iceberg表
CREATE TABLE iceberg_test (
id int, name string
) PARTITIONED BY (
dept string
) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
插入数据
insert into iceberg_test values (1,'test','test2');
说明 如果写数据时,遇到异常提示return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask,应该找不到fb303相关类路径,可以在Hive命令行中手动执行命令 add jar /Users/XXX/cloudera/cdh5.7/hive/lib/libfb303-0.9.3.jar
查询数据
select * from iceberg_test;
查看HDFS文件系统

三,使用Flink连接hive/hadoop操作iceberg(非重点)
1,配置环境
参考博客:XXXXX
下载地址:Index of /dist/flink/flink-1.12.7 (apache.org)
下载iceberg的运行时环境,也就是一个jar包
Central Repository: org/apache/iceberg/iceberg-flink-runtime/0.12.1
安装时按照官网的推荐版本安装:Getting Started | Apache Iceberg
把下载好的jar包放在flink的lib目录下 lib目录下共需要两个jar包
/export/servers/flink-1.11.4/lib
iceberg-flink-runtime-0.12.1.jar
flink-shaded-hadoop-2-uber-2.8.3-7.0.jar
配置hadoop环境变量HADOOP_CONF_DIR,Flink执行sql-client.sh会在lib中找到iceberg的jar包,iceberg会找到HADOOP_CONF_DIR环境,直接操作HDFS。
为了使环境变量不影响其他环境变量,只在当前shell中有效,写一个脚本,每次让环境变量生效时,刷新一下使其生效即可。
vim tempProfile
# 添加环境变量,保存
export HADOOP_CONF_DIR=/export/servers/hadoop-3.2.2/etc/hadoop
# 然后刷新
source tempProfile
测试
echo $HADOOP_CONF_DIR
/export/servers/hadoop-3.2.2/etc/hadoop
启动flink的客户端之前,配置环境变量
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./bin/start-cluster.sh --jar /export/servers/iceberg-flink-runtime-0.12.1.jar
要在flink的sql-client创建iceberg的catalog
Catalog 可以连接外部系统的元数据,然后把元数据信息提供给 Flink,这样 Flink 可以直接去访问外部系统中已经创建好的表或者 database 等等
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs://vmone:8020',
'property-version'='1'
);
2,创建数据库并使用
create database test_db;
use test_db;
然后创建表
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hadoop_prod',
'catalog-type'='hadoop',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
四,使用Trino连接hive/hadoop操作iceberg(重点)
需要注意的是trino最低支持jdk11版本,而大部分大数据组件依赖的jdk都是1.8
1, 节点规划
| hostname | 节点用途 |
|---|---|
| hadoop200 | coordinator |
| hadoop201 | Worker |
| hadoop202 | Worker |
| hadoop203 | Worker |
2,安装jdk11
trino官方推荐的jdk11版本是Azul Zulu

下载地址:wget https://cdn.azul.com/zulu/bin/zulu11.56.19-ca-jdk11.0.15-linux_x64.tar.gz
然后解压,配置环境变量,此处省略
3,安装Trino
下载地址:wget https://repo1.maven.org/maven2/io/trino/trino-server/386/trino-server-386.tar.gz
分发到其他节点
cd /home/trino/
scp -r /home/trino/trino-server-386 trino@hadoop201:/home/trino/
scp -r /home/trino/trino-server-386 trino@hadoop202:/home/trino/
scp -r /home/trino/trino-server-386 trino@hadoop203:/home/trino/
3.1 配置coordinator节点的config.properties
此配置文件包括以下配置文件,没有就创建
# 编辑文件
vim /home/trino/trino-server-386/etc/config.properties
# 新增以下内容
coordinator=true
node-scheduler.include-coordinator=false # 单节点部署此处为true 是否允许coordinator节点同时也作为worker节点
http-server.http.port=8089
query.max-memory=3GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://hadoop200:8089
3.2 配置coordinator节点的jvm.config
# 编辑文件
vim /home/trino/trino-server-386/etc/jvm.config
# 新增以下内容
-server
-Xmx2G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
3.3 配置coordinator节点的node.properties
# 编辑文件
vim /home/trino/trino-server-386/etc/node.properties
# 新增以下内容
node.environment=production
node.id=trino-hadoop200
node.data-dir=/home/trino/trino-server-386/data/
3.4 配置worker节点的config.properties
# 编辑文件
vim /home/trino/trino-server-386/etc/config.properties
# 新增以下内容
coordinator=false
node-scheduler.include-coordinator=true
http-server.http.port=8090
query.max-memory=3GB
query.max-memory-per-node=1GB
discovery.uri=http://hadoop200:8090
3.5 配置worker节点的jvm.config
# 编辑文件
vim /home/trino/trino-server-386/etc/jvm.config
# 新增以下内容
-server
-Xmx32G
-XX:-UseBiasedLocking
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-Dpresto-temporarily-allow-java8=true
3.6 配置worker节点的node.properties
# 编辑文件
vim /home/trino/trino-server-386/etc/node.properties
# 新增以下内容
node.environment=production
#注意:node.id代表work节点的唯一标识,不同的节点标识不一样
# hadoop201 => trino-hadoop201
# hadoop202 => trino-hadoop202
# hadoop203 => trino-hadoop203
node.id=trino-hadoop201
node.data-dir=/home/trino/trino-server-386/data/
4,配置连接器
配置iceberg(3个节点) 配置 catalog/iceberg.properties,没有catalog文件夹就创建
# 编辑文件
vim /home/trino/trino-server-386/etc/catalog/iceberg.properties
# 新增以下内容
connector.name=iceberg
hive.metastore.uri=thrift://cdh192-56:9083,thrift://hadoop200:9083,thrift://hadoop201:9083
hive.config.resources=/home/trino/trino-server-386/etc/hadoop/core-site.xml,/home/trino/trino-server-386/etc/hadoop/hdfs-site.xml
配置完成后分发到其他2个节点。
注意:在hadoop集群是HA的模式下,需要用hive.config.resources指定core-site.xml和hdfs-site.xml。否则会报ns1找不到的问题
5,配置命令行模式
server和cli的版本要一致!
下载地址:https://repo1.maven.org/maven2/io/trino/trino-cli/386/trino-cli-386-executable.jar
编写启动脚本client.sh
./trino-cli-386-executable.jar --server hadoop200:8089
6,命令行操作
show catalogs; # 查询catalog

show schemas from hive;

show schemas from kafka;

use kafka.default;
show tables;

select * from "tablename" limit 10;

五,遇到的问题
1,执行HIVE的创建表语句报错:Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535
解决方式
登录mysql修改hive元数据库的编码方式
mysql -uroot -p123456
alter database metastore character set latin1;
2,执行HIVE的insert语句报错,或运行hadoop的mapreduce测试jar报错,查看日志:/bin/bash: /bin/java: No such file or directory
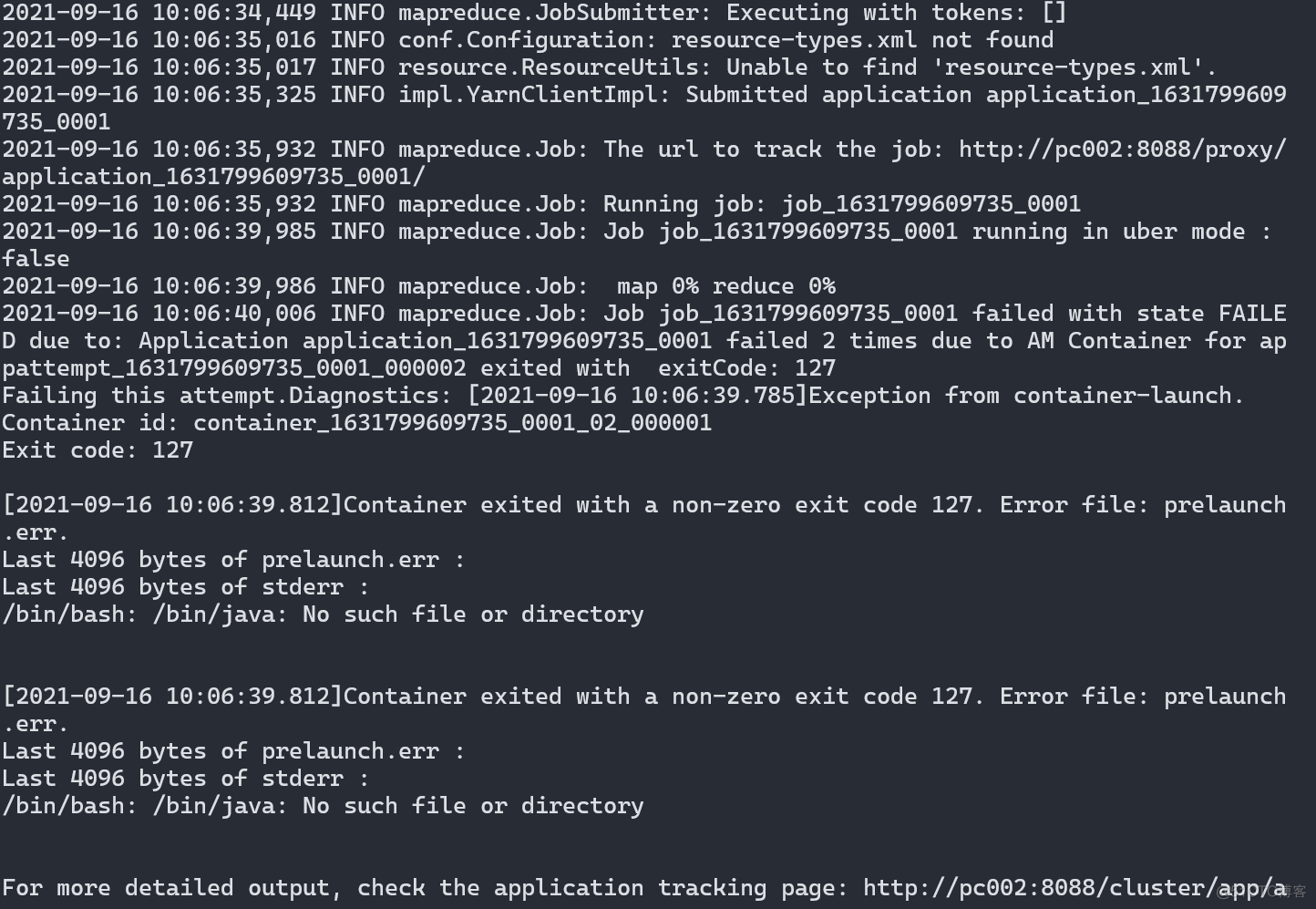
可以很明确的看到报错信息,/bin/java未生效,原因是我是用的配置环境的方式使用的jdk,未采用yum过进行安装jdk
解决措施:创建真实的jdk目录到/bin/java
创建软链接
ln -s /opt/software/jdk1.8.0_201/bin/java /bin/java
3,hiveserver2启动失败问题,启动不了端口10000解决过程
先启动metastore
nohup hive --service metastore &
再启动 hiveserver2
nohup hive --service hiveserver2 &
ps -ef|grep hive
发现两个都有进程
netstat -tunlp
只有9083 没有10000端口,那我的hive日志就在/tmp/root下面,监控日志
tail -f /tmp/root/hive.log
错误日志输出
2019-01-10T15:52:57,275 WARN [main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 1s. getCurrentNotificationEventId
org.apache.thrift.TApplicationException: Internal error processing get_current_notificationEventId
at org.apache.thrift.TApplicationException.read(TApplicationException.java:111) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:79) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_current_notificationEventId(ThriftHiveMetastore.java:5541) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_current_notificationEventId(ThriftHiveMetastore.java:5529) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.getCurrentNotificationEventId(HiveMetaStoreClient.java:2713) ~[hive-exec-3.0.0.jar:3.0.0]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_77]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_77]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_77]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_77]
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:212) ~[hive-exec-3.0.0.jar:3.0.0]
at com.sun.proxy.$Proxy34.getCurrentNotificationEventId(Unknown Source) ~[?:?]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_77]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_77]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_77]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_77]
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2763) ~[hive-exec-3.0.0.jar:3.0.0]
at com.sun.proxy.$Proxy34.getCurrentNotificationEventId(Unknown Source) ~[?:?]
。。。。。。
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_77]
at org.apache.hadoop.util.RunJar.run(RunJar.java:226) [hadoop-common-2.7.7.jar:?]
at org.apache.hadoop.util.RunJar.main(RunJar.java:141) [hadoop-common-2.7.7.jar:?]
Caused by: java.io.IOException: org.apache.thrift.TApplicationException: Internal error processing get_current_notificationEventId
at org.apache.hadoop.hive.metastore.messaging.EventUtils$MSClientNotificationFetcher.getCurrentNotificationEventId(EventUtils.java:75) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hadoop.hive.ql.metadata.events.NotificationEventPoll.<init>(NotificationEventPoll.java:103) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hadoop.hive.ql.metadata.events.NotificationEventPoll.initialize(NotificationEventPoll.java:59) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2.init(HiveServer2.java:267) ~[hive-service-3.0.0.jar:3.0.0]
... 10 more
Caused by: org.apache.thrift.TApplicationException: Internal error processing get_current_notificationEventId
解决方法
修改 hive-site.xml添加(我用的这个方式 问题解决)
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
或者
hadoop core-site.xml添加
hadoop.proxyuser.hive.hosts=HS2_HOST
hadoop.proxyuser.hive.groups=*
继续启动并监控日志,接着报错SessionNotRunning
2019-01-10T16:00:59,680 WARN [main] server.HiveServer2: Error starting HiveServer2 on attempt 1, will retry in 60000ms
java.lang.NoClassDefFoundError: org/apache/tez/dag/api/SessionNotRunning
at org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolSession$AbstractTriggerValidator.startTriggerValidator(TezSessionPoolSession.java:74) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolManager.initTriggers(TezSessionPoolManager.java:207) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolManager.startPool(TezSessionPoolManager.java:114) ~[hive-exec-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2.initAndStartTezSessionPoolManager(HiveServer2.java:831) ~[hive-service-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2.startOrReconnectTezSessions(HiveServer2.java:815) ~[hive-service-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2.start(HiveServer2.java:739) ~[hive-service-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2.startHiveServer2(HiveServer2.java:1014) [hive-service-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2.access$1800(HiveServer2.java:134) [hive-service-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2$StartOptionExecutor.execute(HiveServer2.java:1282) [hive-service-3.0.0.jar:3.0.0]
at org.apache.hive.service.server.HiveServer2.main(HiveServer2.java:1126) [hive-service-3.0.0.jar:3.0.0]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_77]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_77]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_77]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_77]
at org.apache.hadoop.util.RunJar.run(RunJar.java:226) [hadoop-common-2.7.7.jar:?]
at org.apache.hadoop.util.RunJar.main(RunJar.java:141) [hadoop-common-2.7.7.jar:?]
Caused by: java.lang.ClassNotFoundException: org.apache.tez.dag.api.SessionNotRunning
at java.net.URLClassLoader.findClass(URLClassLoader.java:381) ~[?:1.8.0_77]
at java.lang.ClassLoader.loadClass(ClassLoader.java:424) ~[?:1.8.0_77]
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331) ~[?:1.8.0_77]
at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ~[?:1.8.0_77]
... 16 more
额 我配置用的 spark engine,找tez类干什么,为什么
带着这个为什么,我仔细看日志发现了
2019-01-10T16:45:02,837 INFO [main] server.HiveServer2: HS2 interactive HA not enabled. Starting tez sessions..
2019-01-10T16:45:02,837 INFO [main] server.HiveServer2: Starting/Reconnecting tez sessions..
就是这个HS2 interactive HA not enabled,然后转向了启动 tez
解决方法
hive-site.xml追加配置,默认配置是false
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
再次启动
nohup hive --service hiveserver2 &
没有报错了
netstat -tunlp
tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 4112/java
tcp 0 0 0.0.0.0:10002 0.0.0.0:* LISTEN 4112/java
查看端口已启动,应该是解决了
4,beeline操作iceberg表插入数据时报错:Permission denied: user=anonymous, access=EXECUTE, inode="/tmp/hadoop-yarn":root:supergroup:drwx------
原因
beeline -u jdbc:hive2://doitedu01:10000
这种方式直接连接,没有指定用户名和密码,使用的是其实是anonymous(匿名的)这个用户没有hdfs上的/tmp 目录下的写权限,所以造成失败,加上用户名就可以了
beeline -u jdbc:hive2://doitedu01:10000 -n root
5,beeline操作iceberg表插入数据时报错:User: root is not allowed to impersonate root (state=08S01,code=1)
21/03/17 18:04:41 [main]: WARN jdbc.HiveConnection: Failed to connect to hadoop102:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://hadoop102:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: kuber is not allowed to impersonate kuber (state=08S01,code=0)
解决方法
这个问题网上很多解决办法,首先在hadoop/core-site.xml文件里面加上
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
这两段,然后重启hdfs和yarn,重启hiveserver,hiveserver2但是对我来说并没用。
随后,我在hive/conf/hive.site.xml里面加了下面一句
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
成功!
6,beeline操作iceberg表插入数据时报错:Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask(state=08S01,code=2)
如果写数据时,遇到异常提示return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask,应该找不到fb303相关类路径,可以在Hive命令行中手动执行命令
add jar /Users/XXX/cloudera/cdh5.7/hive/lib/libfb303-0.9.3.jar;
这个jar包通常在Hive的lib目录下,如果没有就下载一个。
7,Hive任务执行报错:FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2)
目前具体报错原因未知
解决一
可在执行sql语句前加上这句解决上面问题:
set hive.support.concurrency=false;
解决方法二
原因:yarn资源不足
该错误是YARN的虚拟内存计算方式导致,上例中用户程序申请的内存为1Gb,YARN根据此值乘以一个比例(默认为2.1)得出申请的虚拟内存的值,当YARN计算的用户程序所需虚拟内存值大于计算出来的值时,就会报出以上错误。调节比例值可以解决该问题。具体参数为:yarn-site.xml中的yarn.nodemanager.vmem-pmem-ratio
解决方法
调整hadoop配置文件yarn-site.xml中值
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>default value is 1024</description>
</property>
增加yarn.scheduler.minimum-allocation-mb 数量,从缺省1024改为2048;上述运行问题即刻得到解决
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号