
docker和k8s原理及源码解析-非原创
原理及源码解析
该部分为帮助学者更好的理解和使用
Docker基础
容器是怎么隔离的
进程:一些数据加上代码本身的二进制文件,放在磁盘上,就是我们平常所说的一个“程序”,也叫代码的可执行镜像(executable image)。
程序运起来后的计算机执行环境的总和,就是:进程。
“程序”运行起来,就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。
静态的表现是程序,动态的表现是进程,容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
Cgroups 技术是用来制造约束的主要手段,而Namespace 技术则是用来修改进程视图的主要方法。
Cgroups :其名称源自控制组群(control groups)的简写,是Linux内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。
在Linux启动一个容器
$ docker run -it busybox /bin/sh
/ #
docker run:启动容器
-it:分配一个文本输入/输入环境,也就是TTY,这样就可以和容器交互
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
10 root 0:00 ps
注释:执行ps指令,我们在Docker 里最开始执行的 /bin/sh,就是这个容器内部的第 1 号进程(PID=1),而这个容器里一共只有两个进程在运行。这就意味着,前面执行的 /bin/sh,以及我们刚刚执行的 ps,已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。
这种技术,就是 Linux 里面的 Namespace 机制。
在 Linux 系统中创建线程的系统调用是 clone(),创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
除了 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
IPC:隔离System V IPC和POSIX消息队列。 Network:隔离网络资源。 Mount:隔离文件系统挂载点。每个容器能看到不同的文件系统层次结构。 PID:隔离进程ID。 UTS:隔离主机名和域名。 User:隔离用户ID和组ID。
这,就是 Linux 容器最基本的实现原理,容器,其实就是一种特殊的进程。
关于namespace
namespace的API包括clone()、setns()以及unshare(),还有/proc下的部分文件。为了确定隔离的到底是哪种namespace,在使用这些API时,通常需要指定以下六个常数的一个或多个,通过|(位或)操作来实现。这六个参数分别是CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER和CLONE_NEWUTS。
- 通过clone()创建新进程的同时创建namespace
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
参数child_func传入子进程运行的程序主函数。
参数child_stack传入子进程使用的栈空间
参数flags表示使用哪些CLONE_*标志位
参数args则可用于传入用户参数
clone()实际上是传统UNIX系统调用fork()的一种更通用的实现方式,它可以通过flags来控制使用多
少功能。一共有二十多种CLONE_*的flag(标志位)参数用来控制clone进程的方方面面(如是否与父
进程共享虚拟内存等等)。
- 通过setns()加入一个已经存在的namespace
在进程都结束的情况下,也可以通过挂载的形式把namespace保留下来,保留namespace的目的自然是
为以后有进程加入做准备。通过setns()系统调用,你的进程从原先的namespace加入我们准备好的新
namespace,使用方法如下:
int setns(int fd, int nstype)
参数fd表示我们要加入的namespace的文件描述符。上文已经提到,它是一个指向/proc/[pid]/ns目录
的文件描述符,可以通过直接打开该目录下的链接或者打开一个挂载了该目录下链接的文件得到。
参数nstype让调用者可以去检查fd指向的namespace类型是否符合我们实际的要求。如果填0表示不检查。
复制代码
- 通过unshare()在原先进程上进行namespace隔离
后要提的系统调用是unshare(),它跟clone()很像,不同的是,unshare()运行在原先的进程上,
不需要启动一个新进程,使用方法如下:
int unshare(int flags);
调用unshare()的主要作用就是不启动一个新进程就可以起到隔离的效果,相当于跳出原先的
namespace进行操作。这样,你就可以在原进程进行一些需要隔离的操作。Linux中自带的
unshare命令,就是通过unshare()系统调用实现的。
如下Docker源码,呈现了namespace的创建过程。

虚拟机和容器的对比图

Hypervisor:是虚拟机最主要的部分。它通过硬件虚拟化功能,模拟出了运行一个操作系统需要的各种硬件,比如 CPU、内存、I/O 设备等等。然后,它在这些虚拟的硬件上安装了一个新的操作系统,即 Guest OS。
有种对比图是这样的

但是这样并不严谨,Docker Engine不像 Hypervisor 那样对应用进程的隔离环境负责,也不会创建任何实体的“容器”,真正对隔离环境负责的是宿主机操作系统本身。
用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的 Namespace 参数。而 Docker 项目在这里扮演的角色,更多的是旁路式的辅助和管理工作。
这样的架构也解释了为什么 Docker 项目比虚拟机更受欢迎的原因。
虚拟机里面必须运行一个完整的 Guest OS 才能执行用户的应用进程。这就不可避免地带来了额外的资源消耗和占用。一般情况下虚拟机自己就需要占用 100~200 MB 内存。
深入理解容器镜像
挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件:
$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)。
这样,一个完整的容器就诞生了。当然内核还是共享宿主机操作系统的内核。正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性。
这种深入到操作系统级别的运行环境一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
问题:那么开发一个应用,或者升级一下现有的应用,都要重复制作一次 rootfs 吗?我在rootfs装了python环境,部署了python应用,我的其它同事想发布python应用时,当然希望用到我的python环境,而不是他也需要部署一遍。
而docker镜像的设计中,引入了层(layer)的概念,也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。docker使用的rootfs往往由多个“层”组成:
$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
上面的镜像实际由五个层组成。这五个层就是五个增量 rootfs,每一层都是 Ubuntu 操作系统文件与目录的一部分;
而在使用镜像时,Docker 会把这些增量联合挂载在一个统一的挂载点上。这个挂载点就是 /var/lib/docker/aufs/mnt/,这个目录下面就是一个完整的Ubuntu 操作系统
$ ls /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
这五个层的信息记录在 AuFS 的系统目录 /sys/fs/aufs 下面,查看挂载信息找到这个目录对应的 AuFS 的内部 ID(也叫:si):
$ cat /proc/mounts| grep aufs
none /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufs rw,relatime,si=972c6d361e6b32ba,dio,dirperm1 0 0
通过ID在 /sys/fs/aufs 下查看被联合挂载在一起的各个层的信息:
$ cat /sys/fs/aufs/si_972c6d361e6b32ba/br[0-9]*
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh
/var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh
/var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh
/var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh
/var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh
/var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh
镜像的层都放置在 /var/lib/docker/aufs/diff 目录下,然后被联合挂载在 /var/lib/docker/aufs/mnt 里面。
从这个结构可以看出,这个容器的rootfs由下图的三个部分组成:

我们可以通过docker commit和push指令,保存被修改过的可读写层,并上传到Docker Hub上,供其它人增强使用;且原先的只读层里的内容不会有任何改变;这就解决了刚刚的问题。
Kubernetes基本概念
初识Pod
WHAT:它只是一个逻辑概念、是一种编排思想、k8s中最小编排单位,k8s处理的还是宿主机上Linux的Namespace和Cgrous
WHY:
- 一些容器更适合放在一起紧密协作
- 容器的日志收集
Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
对与上面的容器的日志收集,举例:有一个应用,需要不断地把日志文件输出到容器的 /var/log 目录,这时我们把一个 Pod 里的 Volume 挂载到应用容器的 /var/log 目录上。然后在这个Pod里运行一个 sidecar 容器,也声明挂载同一个 Volume 到自己的 /var/log 目录上。sidecar 容器就只需要做一件事儿,就是不断地从自己的 /var/log 目录里读取日志文件,转发到 MongoDB 或者 Elasticsearch 中存储起来。一个最基本的日志收集工作就完成了。
实际工作中:当你需要把一个运行在虚拟机里的应用迁移到 Docker 容器中时,一定要仔细分析到底有哪些进程(组件)运行在这个虚拟机里。
然后,你就可以把整个虚拟机想象成为一个 Pod,把这些进程分别做成容器镜像,把有顺序关系的容器,定义为 Init Container。这才是更加合理的、松耦合的容器编排诀窍,也是从传统应用架构,到“微服务架构”最自然的过渡方式。
Pod中几个重要字段的含义和用法
凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的。
HostAliases:定义了 Pod 的 hosts 文件(比如 /etc/hosts)里的内容,用法如下:
apiVersion: v1
kind: Pod
...
spec:
hostAliases:
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
...
shareProcessNamespace=true:在这个 Pod 里的容器共享 PID Namespace
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
shareProcessNamespace: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: tru
上面的YAML文件中,还定义了两个容器:一个是 nginx 容器,一个是开启了 tty 和 stdin 的 shell 容器。在 Pod 的 YAML 文件里声明开启它们俩,其实等同于设置了 docker run 里的 -it(-i 即 stdin,-t 即 tty)参数。
tty:Linux 给用户提供的一个常驻小程序,用于接收用户的标准输入,返回操作系统的标准输出
stdin:为了能够在 tty 中输入信息,还需要同时开启 stdin(标准输入流)。
这个 Pod 被创建后,你就可以使用 shell 容器的 tty 跟这个容器进行交互了。
容器要共享宿主机的 Namespace,也一定是 Pod 级别的定义
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
hostNetwork: true
hostIPC: true
hostPID: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
在这个 Pod 中,定义了共享宿主机的 Network、IPC 和 PID Namespace。这就意味着,这个 Pod 里的所有容器,会直接使用宿主机的网络、直接与宿主机进行 IPC 通信、看到宿主机里正在运行的所有进程。
Container是Pod中最重要的字段
-
ImagePullPolicy:定义了镜像拉取的策略
- 默认是 Always,即每次创建 Pod 都重新拉取一次镜像。
- 可以定义为 Never 或者 IfNotPresent,则意味着 Pod 永远不会主动拉取这个镜像,或者只在宿主机上不存在这个镜像时才拉取。
-
Lifecycle:定义的是 Container Lifecycle Hooks。在容器状态发生变化时触发一系列“钩子”。如下例子:
apiVersion: v1 kind: Pod metadata: name: lifecycle-demo spec: containers: - name: lifecycle-demo-container image: nginx lifecycle: postStart: exec: command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"] preStop: exec: command: ["/usr/sbin/nginx","-s","quit"]**postStart **:在容器启动后,立刻执行一个指定的操作。
- 该操作虽然是在 Docker 容器 ENTRYPOINT 执行之后,但它并不严格保证顺序。也就是说,在 postStart 启动时,ENTRYPOINT 有可能还没有结束。
- 执行超时或者错误,Kubernetes 会在该 Pod 的 Events 中报出该容器启动失败的错误信息,导致 Pod 也处于失败的状态。
preStop:preStop 发生的时机,则是容器被杀死之前(比如,收到了 SIGKILL 信号)。preStop 操作的执行,是同步的,它会阻塞当前的容器杀死流程,直到这个 Hook 定义操作完成之后,才允许容器被杀死
Pod的几种状态
- Pending:这个状态意味着,Pod 的 YAML 文件已经提交给了 Kubernetes,API 对象已经被创建并保存在 Etcd 当中。但是,这个 Pod 里有些容器因为某种原因而不能被顺利创建。比如,调度不成功。
- Running:这个状态下,Pod 已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中。
- Succeeded:这个状态意味着,Pod 里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。
- Failed:这个状态下,Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。
- Unknown:这是一个异常状态,意味着 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题。
水平扩展和滚动升级
举个例子,如果你更新了 Deployment 的 Pod 模板(比如,修改了容器的镜像),那么 Deployment 就需要遵循一种叫作“滚动更新”(rolling update)的方式,来升级现有的容器。
这个能力的实现,依赖的是 Kubernetes 项目中的一个非常重要的概念(API 对象):ReplicaSet。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
它定义的 Pod 副本个数是 3(spec.replicas=3)。
一个 ReplicaSet 对象,其实就是由副本数目的定义和一个 Pod 模板组成的。“水平扩展 / 收缩”只需要把这个值3改成4或者4改成3。而将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程(去掉旧的增加新的),就是“滚动更新”。
RBAC:基于角色的权限控制
三个基本概念:
- Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
- Subject:被作用者,既可以是“人”,也可以是“机器”,也可以使你在 Kubernetes 里定义的“用户”。
- RoleBinding:定义了“被作用者”和“角色”的绑定关系。
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: mynamespace
name: example-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
...
secrets:
- name: example-sa-token-vmfg6
Role 对象指定了它能产生作用的 Namepace 是:mynamespace。
rules:定义权限规则
verbs:赋予用户 example-user 的权限
secrets:对应的、用来跟 APIServer 进行交互的授权文件,我们一般称它为:Token,它以一个 Secret 对象的方式保存在 Etcd 当中。
Operator 工作原理
WAHT:一个相对更加灵活和编程友好的管理“有状态应用”的解决方案
以Etcd为例:
Etcd Operator 的使用方法非常简单,只需要两步即可完成:
第一步,将这个 Operator 的代码 Clone 到本地:
$git clone https://github.com/coreos/etcd-operator
第二步,将这个 Etcd Operator 部署在 Kubernetes 集群里。
$example/rbac/create_role.sh
上述脚本为 Etcd Operator 定义了如下所示的权限:
- 对 Pod、Service、PVC、Deployment、Secret 等 API 对象,有所有权限;
- 对 CRD 对象,有所有权限;
- 对属于 etcd.database.coreos.com 这个 API Group 的 CR(Custom Resource)对象,有所有权限。
Etcd Operator 本身,其实就是一个 Deployment,它的 YAML 文件如下所示:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: etcd-operator
spec:
replicas: 1
template:
metadata:
labels:
name: etcd-operator
spec:
containers:
- name: etcd-operator
image: quay.io/coreos/etcd-operator:v0.9.2
command:
- etcd-operator
env:
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
...
使用上述的 YAML 文件来创建 Etcd Operator
kubectl create -f example/deployment.yaml
tcd Operator 的 Pod 进入了 Running 状态,就有一个 CRD 被自动创建了出来,如下所示:
$kubectl get pods
NAME READY STATUS RESTARTS AGE
etcd-operator-649dbdb5cb-bzfzp 1/1 Running 0 20s
$kubectl get crd
NAME CREATED AT
etcdclusters.etcd.database.coreos.com 2018-09-18T11:42:55Z
这个 CRD 名叫etcdclusters.etcd.database.coreos.com 。你可以通过 kubectl describe 命令看到它的细节,如下所示:
kubectl describe crd etcdclusters.etcd.database.coreos.com
...
Group: etcd.database.coreos.com
Names:
Kind: EtcdCluster
List Kind: EtcdClusterList
Plural: etcdclusters
Short Names:
etcd
Singular: etcdcluster
Scope: Namespaced
Version: v1beta2
...
这个 CRD 相当于告诉了 Kubernetes:接下来,如果有 API 组(Group)是
etcd.database.coreos.com、API 资源类型(Kind)是“EtcdCluster”的 YAML 文件被提交上来,你可一定要认识啊。
所以说,通过上述两步操作,实际上是在 Kubernetes 里添加了一个名叫 EtcdCluster 的自定义资源类型。而 Etcd Operator 本身,就是这个自定义资源类型对应的自定义控制器。
当 Etcd Operator 部署好之后,接下来在这个 Kubernetes 里创建一个 Etcd 集群的工作就非常简单了。你只需要编写一个 EtcdCluster 的 YAML 文件,然后把它提交给 Kubernetes 即可,如下所示:
$kubectl apply -f example/example-etcd-cluster.yaml
这个 example-etcd-cluster.yaml 文件里描述的,是一个 3 个节点的 Etcd 集群。我们可以看到它被提交给 Kubernetes 之后,就会有三个 Etcd 的 Pod 运行起来,如下所示:
$kubectl get pods
NAME READY STATUS RESTARTS AGE
example-etcd-cluster-dp8nqtjznc 1/1 Running 0 1m
example-etcd-cluster-mbzlg6sd56 1/1 Running 0 2m
example-etcd-cluster-v6v6s6stxd 1/1 Running 0 2m
以上就完成了Etcd集群
Operator 的工作原理,实际上是利用了 Kubernetes 的自定义 API 资源(CRD),来描述我们想要部署的“有状态应用”;然后在自定义控制器里,根据自定义 API 对象的变化,来完成具体的部署和运维工作。
kubernetes技能图谱

Kubernetes调度机制
Kubernetes的资源模型与资源管理
所有跟调度和资源管理相关的属性都是属于 Pod 对象的字段,其中最重要的部分,就是 Pod 的 CPU 和内存配置,如下所示
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
在Kubernetes 中
- CPU称为 “可压缩资源” ,可压缩资源不足时,Pod只会“饥饿”,不会退出
- 内存称为“不可压缩资源”,不可压缩资源不足时,Pod会因为OOM(Out-Of-Memory)被内核杀掉
- Pod 可以由多个 Container 组成,所以 CPU 和内存资源的限额,是要配置在每个 Container 的定义上的,而Pod整体资源配置,就由这些 Container 的配置值累加得到
limits 和 requests 的区别很简单在调度的时候,kube-scheduler 只会按照 requests 的值进行计算。而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置。
requests+limits 的做法,其实是Borg的思想,即,实际场景中,大多数作业使用到的资源其实远小宇它所请求的资源限额,基于这种假设,用户可以声明一个相对小的requests值供调度器使用,而Kubernetes 真正设置给容器 Cgroups 的,则是相对较大的 limits 值。
QoS 模型
三个级别,衔接上面
- Guaranteed:Pod 里的每一个 Container 都同时设置了 requests 和 limits,并且 requests 和 limits 值相等的时候,这个 Pod 就属于 Guaranteed 类别
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
- Burstable:当 Pod 不满足 Guaranteed 的条件,但至少有一个 Container 设置了 requests。那么这个 Pod 就会被划分到 Burstable 类别
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits
memory: "200Mi"
requests:
memory: "100Mi"
- BestEffort:如果 Pod 既没有设置 requests,也没有设置 limits,那么它的 QoS 类别就是 BestEffort
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
namespace: qos-example
spec:
containers:
- name: qos-demo-3-ctr
image: nginx
QoS 划分的主要应用场景,是当宿主机资源紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。当Eviction发生时,kubelet 具体会挑 Pod 进行删除操作,按如下级别
BestEffort < Burstable < Guaranteed
并且,Kubernetes 会保证只有当 Guaranteed 类别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态时,Guaranteed 的 Pod 才可能被选中进行 Eviction 操作。
cpuset 的设置
一个实际生产中非常有用的特性,衔接上面
在使用容器时,可以通过设置 cpuset 把容器绑定到某个 CPU 的核上,而不是像 cpushare 那样共享 CPU 的计算能力,这样CPU之间进行上下文切换的次数大大减少,容器里应用的性能会得到大幅提升
实现方法
- Pod 必须是 Guaranteed 的 QoS 类型
- 将 Pod 的 CPU 资源的 requests 和 limits 设置为同一个相等的整数值
如下例子
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
这样,该Pod就会绑定在2个独占的CPU核上,具体是哪两个CPU,由kubelet 分配
基于上面的情况,建议将DaemonSet(亦或者类似的)的 Pod 都设置为 Guaranteed 的 QoS 类型,否则一旦被资源紧张被回收,又立即会在宿主机上重建出来,这样资源回收的动作就没有意义了
Kubernetes默认的调度策略

调度机制的工作原理示意图
默认的几种调度策略
- 第一种类型,GeneralPredicates:这一组过滤规则,负责的是最基础的调度策略,计算的就是宿主机的 CPU 和内存资源等是否够用。
- 第二种类型,与 Volume 相关的过滤规则:这一组过滤规则,负责的是跟容器持久化 Volume 相关的调度策略。
- 第三种类型,是宿主机相关的过滤规则:这一组规则,主要考察待调度 Pod 是否满足 Node 本身的某些条件。比如,PodToleratesNodeTaints,负责检查的就是我们前面经常用到的 Node 的“污点”机制。
- 第四种类型,是 Pod 相关的过滤规则:这一组规则,跟 GeneralPredicates 大多数是重合的。而比较特殊的,是 PodAffinityPredicate。这个规则的作用,是检查待调度 Pod 与 Node 上的已有 Pod 之间的亲密(affinity)和反亲密(anti-affinity)关系
在具体执行的时候, 当开始调度一个 Pod 时,Kubernetes 调度器会同时启动 16 个 Goroutine,来并发地为集群里的所有 Node 计算 Predicates,最后返回可以运行这个 Pod 的宿主机列表。
Goroutinego语言的“线程”,比传统线程对资源的占用更合理
在 Predicates 阶段完成了节点的“过滤”之后,Priorities 阶段的工作就是为这些节点打分。这里打分的范围是 0-10 分,得分最高的节点就是最后被 Pod 绑定的最佳节点。
Priorities 里最常用到的一个打分规则,是 LeastRequestedPriority。它的计算方法,可以简单地总结为如下所示的公式
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
这个算法实际上就是在选择空闲资源(CPU 和 Memory)最多的宿主机。
与 LeastRequestedPriority 一起发挥作用的,还有 BalancedResourceAllocation。它的计算公式如下所示
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
每种资源的 Fraction 的定义是 Pod 请求的资源 / 节点上的可用资源。而 variance 算法的作用,则是计算每两种资源 Fraction 之间的“距离”。而最后选择的,则是资源 Fraction 差距最小的节点。
也就是调度完成后,所有节点里各种资源分配最均衡的那个节点,从而避免一个节点上 CPU 被大量分配、而 Memory 大量剩余的情况
此外,还有 NodeAffinityPriority、TaintTolerationPriority 和 InterPodAffinityPriority 这三种 Priority。这里就不一一介绍了,除了默认的调度策略,还有很多默认不会开启的策略,可以通过为 kube-scheduler 指定一个配置文件或者创建一个 ConfigMap ,来配置哪些规则需要开启、哪些规则需要关闭。并且,还可以通过为 Priorities 设置权重,来控制调度器的调度行为。
调度器的优先级与强制机制
工作中我们也需要一些Pod有优先级和抢占机制,比如Pod调度失败后,会被“搁置”,知道Pod被更新或集群状态发生变化,调度器才会对Pod进行重新调度,我们希望高优先级的Pod调度失败后不被搁置,而“挤走”某些低优先级的。
1.11版本后这个特性已经是Beta,用法如下
先在Kubernetes里提交一个PriorityClass,如下:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."
这个YAML文件名为high-priority
value:值越大代表优先级越高(最大1000000000/10亿)
globalDefault:声明使用该PriorityClass的Pod拥有值为1000000 的优先级,没有声明则为0。 true 的话,那就意味着这个 PriorityClass 的值会成为系统的默认值
然后我们在Pod就可以声明使用,如下
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
提交后,Kubernetes 的 PriorityAdmissionController 就会自动将这个 Pod 的 spec.priority 字段设置为 1000000
调度器里维护着一个调度队列,高优先级的 Pod 就可能会比低优先级的 Pod 提前出队,从而尽早完成调度过程。这个过程,就是“优先级”这个概念在 Kubernetes 里的主要体现。
而当一个高优先级的 Pod 调度失败的时候,调度器的抢占能力就会被触发。这时,调度器就会试图从当前集群里寻找一个节点,使得当这个节点上的一个或者多个低优先级 Pod 被删除后,待调度的高优先级 Pod 就可以被调度到这个节点上。这个过程,就是“抢占”这个概念在 Kubernetes 里的主要体现。
kubelet
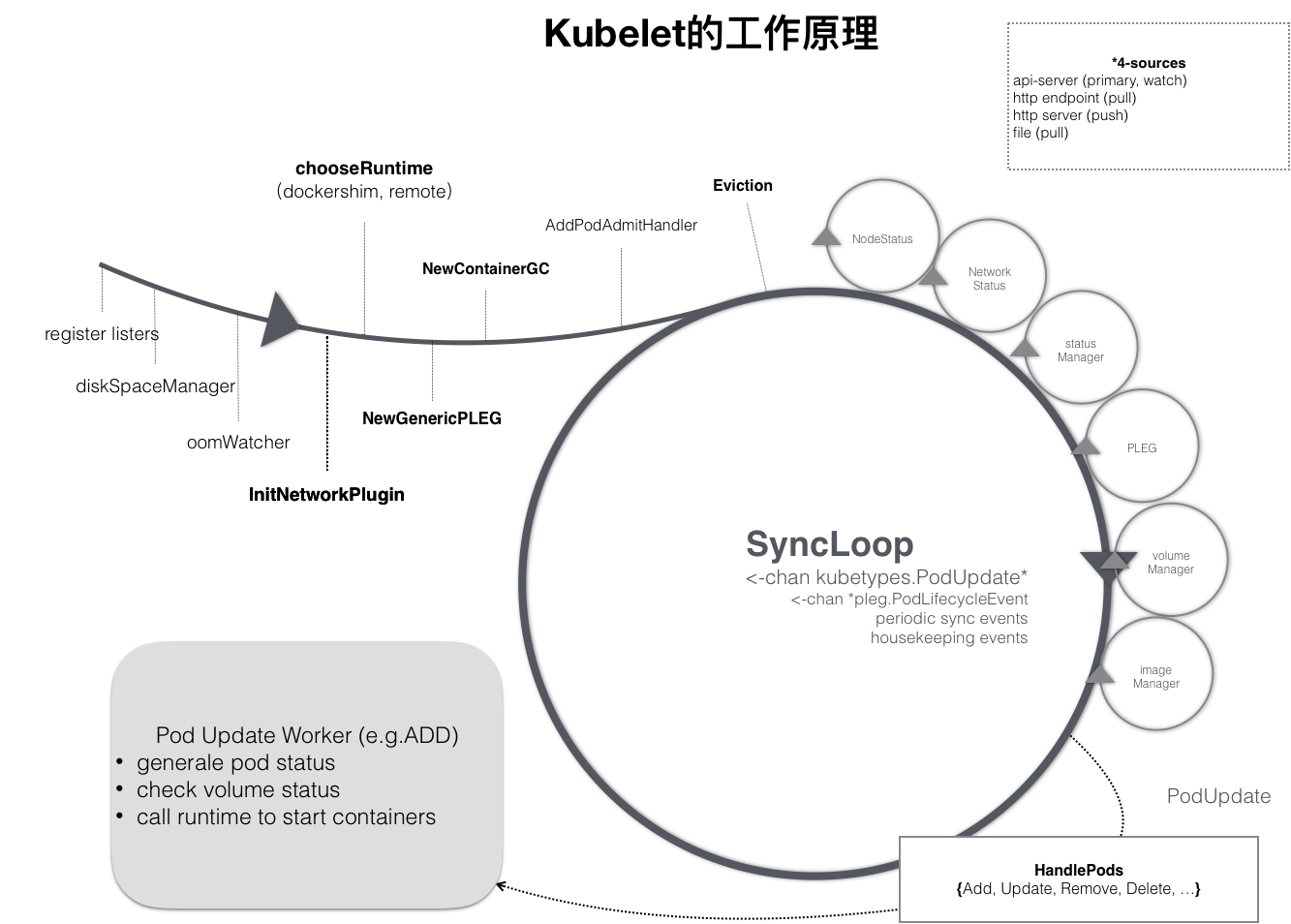
kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的。为什么由CRI来间接执行是关乎历史原因,搭配CRI之后,Kubernetes 以及 kubelet 本身的架构,就可以用如下所示的一幅示意图来描述。

可以看到,当 Kubernetes 通过编排能力创建了一个 Pod 之后,调度器会为这个 Pod 选择一个具体的节点来运行,比如创建一个Pod。此时,kubelet 实际上就会调用一个叫作 GenericRuntime 的通用组件来发起创建 Pod 的 CRI 请求。如果使用容器项目是 Docker 的话,那么负责响应这个请求的就是一个叫作 dockershim 的组件。它会把 CRI 请求里的内容拿出来,然后组装成 Docker API 请求发给 Docker Daemon。
CRI 这个接口的定义如下图

- 第一组,是 RuntimeService。它提供的接口,主要是跟容器相关的操作。比如,创建和启动容器、删除容器、执行 exec 命令等等。
- 而第二组,则是 ImageService。它提供的接口,主要是容器镜像相关的操作,比如拉取镜像、删除镜像等等。
CRI 设计的一个重要原则,就是确保这个接口本身,只关注容器,不关注 Pod
第一,Pod 是 Kubernetes 的编排概念,而不是容器运行时的概念。所以,我们就不能假设所有下层容器项目,都能够暴露出可以直接映射为 Pod 的 API。
第二,如果 CRI 里引入了关于 Pod 的概念,那么接下来只要 Pod API 对象的字段发生变化,那么 CRI 就很有可能需要变更。而在 Kubernetes 开发的前期,Pod 对象的变化还是比较频繁的,但对于 CRI 这样的标准接口来说,这个变更频率就有点麻烦了。
所以,在 CRI 的设计里,并没有一个直接创建 Pod 或者启动 Pod 的接口。
Kubernetes相关生态
Prometheus、Metrics Server与Kubernetes监控体系
简介:Prometheus 项目与 Kubernetes 项目一样,也来自于 Google 的 Borg 体系,它的原型系统,叫作 BorgMon,是一个几乎与 Borg 同时诞生的内部监控系统
Prometheus 项目的作用和工作方式,官方示意图
Prometheus 项目工作的核心,是使用 Pull (抓取)的方式去搜集被监控对象的 Metrics 数据(监控指标数据),然后,再把这些数据保存在一个 TSDB (时间序列数据库,比如 OpenTSDB、InfluxDB 等)当中,以便后续可以按照时间进行检索。
Pushgateway:允许被监控对象以 Push 的方式向 Prometheus 推送 Metrics 数据
Alertmanager:可以根据 Metrics 信息灵活地设置报警
**Grafana **:对外暴露出的、可以灵活配置的监控数据可视化界面
Metrics 数据的来源
- 第一种 Metrics,是宿主机的监控数据
- 这部分数据的提供,需要借助一个由 Prometheus 维护的Node Exporter 工具,就是代替被监控对象来对 Prometheus 暴露出可以被“抓取”的 Metrics 信息的一个辅助进程。
- 第二种 Metrics,是来自于 Kubernetes 的 API Server、kubelet 等组件的 /metrics API
- 除了常规的 CPU、内存的信息外,这部分信息还主要包括了各个组件的核心监控指标。比如,对于 API Server 来说,它就会在 /metrics API 里,暴露出各个 Controller 的工作队列(Work Queue)的长度、请求的 QPS 和延迟数据等等。这些信息,是检查 Kubernetes 本身工作情况的主要依据。
- 第三种 Metrics,是 Kubernetes 相关的监控数据
- 这部分数据,一般叫作 Kubernetes 核心监控数据(core metrics)。这其中包括了 Pod、Node、容器、Service 等主要 Kubernetes 核心概念的 Metrics。
- 这里提到的 Kubernetes 核心监控数据,其实使用的是 Kubernetes 的一个非常重要的扩展能力,叫作 Metrics Server。在社区的定位,是用来取代Heapster。
在具体的监控指标规划上,建议你遵循业界通用的 USE 原则和 RED 原则
USE 原则指的是,按照如下三个维度来规划资源监控指标(原则是主要关注“资源”)
- 利用率(Utilization),资源被有效利用起来提供服务的平均时间占比;
- 饱和度(Saturation),资源拥挤的程度,比如工作队列的长度;
- 错误率(Errors),错误的数量。
RED 原则指的是,按照如下三个维度来规划服务监控指标(原则是主要关注“服务”)
- 每秒请求数量(Rate);
- 每秒错误数量(Errors);
- 服务响应时间(Duration)。
日志收集与管理
Kubernetes 中对容器日志的处理方式,都叫做 cluster-level-logging,即这个日志处理系统,与容器、Pod 以及 Node 的生命周期都是完全无关的。这种设计当然是为了保证,无论是容器挂了、Pod 被删除,甚至节点宕机的时候,应用的日志依然可以被正常获取到。
第一种,在 Node 上部署 logging agent,将日志文件转发到后端存储里保存起来,架构图如下

这里的核心在于 logging agent ,它一般都会以 DaemonSet 的方式运行在节点上,然后将宿主机上的容器日志目录挂载进去,最后由 logging-agent 把日志转发出去。
优势:在 Node 上部署 logging agent,在于一个节点只需要部署一个 agent,并且不会对应用和 Pod 有任何侵入性。
不足:要求应用输出的日志,都必须是直接输出到容器的 stdout 和 stderr 里。即如果每秒日志量很大时,直接输出到容器的stdout和stderr,很容易就把系统日志配额用满,因为对系统默认日志工具是针对单服务(例如docker)而不是进程进行限额的,最终导致的结果就是日志被吞掉。解决办法一个是增加配额,一个是给容器挂上存储,将日志输出到存储上
stdout 和 stderrstdout是标准输出,stderr是错误输出
第二种,就是对这种特殊情况的一个处理,即当容器的日志只能输出到某些文件里的时候,我们可以通过一个 sidecar 容器把这些日志文件重新输出到 sidecar 的 stdout 和 stderr 上,这样就能够继续使用第一种方案了。架构图如下

不足:宿主机上实际上会存在两份相同的日志文件一份是应用自己写入的;另一份则是 sidecar 的 stdout 和 stderr 对应的 JSON 文件。这对磁盘是很大的浪费,除非万不得已或者应用容器完全不可能被修改,否则不要使用这个方案
第三种方案,就是通过一个 sidecar 容器,直接把应用的日志文件发送到远程存储里面去,架构图如下

优势:直接把日志输出到固定的文件里而不是 stdout,logging-agent 可以使用 fluentd,后端存储可以是 ElasticSearch。部署简单,对宿主机友好。
不足:这个 sidecar 容器很可能会消耗较多的资源,甚至拖垮应用容器。并且,由于日志还是没有输出到 stdout 上,所以你通过 kubectl logs 是看不到任何日志输出的。
最后,无论是哪种方案,都必须要及时将这些日志文件从宿主机上清理掉,或者给日志目录专门挂载一些容量巨大的远程盘。否则,一旦主磁盘分区被打满,整个系统就可能会陷入奔溃状态。
Kubernetes yaml文件
PV和PVC工作原理
PV:描述持久化存储数据卷,定义的是一个持久化存储在宿主机上的目录,比如一个 NFS 的挂载目录。通常由运维人员事先创建在 Kubernetes 集群里待用的。
PVC:是 Pod 所希望使用的持久化存储的属性,比如,Volume 存储的大小、可读写权限等等。通常由开发人员创建。
而创建的 PVC 要真正被容器使用起来,就必须先和某个符合条件的 PV 进行绑定。这里要检查的条件,包括两部分
- 第一个条件,当然是 PV 和 PVC 的 spec 字段。比如,PV 的存储(storage)大小,就必须满足 PVC 的要求。
- 而第二个条件,则是 PV 和 PVC 的 storageClassName 字段必须一样。
当然一个大规模的Kubernetes 集群里很可能有成千上万个 PVC,意味着运维人员必须得事先创建出成千上万个 PV。就不得不继续添加新的、能满足条件的 PV,否则新的 Pod 就会因为 PVC 绑定不到 PV 而失败。在实际操作中,这几乎没办法靠人工做到。
Dynamic Provisioning:自动创建 PV 的机制,机制工作的核心在于StorageClass (API对象)。
StorageClass:创建 PV 的模板,它会定义如下两个部分
- 第一,PV 的属性。比如,存储类型、Volume 的大小等等。
- 第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。
有了这样两个信息之后,Kubernetes 就能够根据用户提交的 PVC,找到一个对应的 StorageClass 了。然后,Kubernetes 就会调用该 StorageClass 声明的存储插件,创建出需要的 PV。
如下例子
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: block-service
provisioner: ceph.rook.io/block
parameters:
pool: replicapool
#The value of "clusterNamespace" MUST be the same as the one in which your rook cluster exist
clusterNamespace: rook-ceph
provisioner:是存储插件的名字
这样就定义了一个名叫block-service的StorageClass,有了 StorageClass 的 YAML 文件之后,运维人员就可以在 Kubernetes 里创建这个 StorageClass 了
kubectl create -f sc.yaml
而开发者,只需要在要运行的 PVC 里指定要使用的 StorageClass 名字即可,如下所示
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: block-service
resources:
requests:
storage: 30Gi
PVC 里添加了一个叫作 storageClassName 的字段,用于指定该 PVC 所要使用的 StorageClass 的名字是block-service。
这样Kubernetes 就会将 StorageClass 相同的 PVC 和 PV 绑定起来。

- PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
- PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
- 而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
也正是因为这套存储体系,使得使用者不需要类似挂载一样分配磁盘空间,也不会对已有的用户造成影响,PVC 的 YAML并没有任何改变,这个特性所有的实现只会影响到PV的处理,这就是“解耦”的好处。
Flannel工作原理
先说下传统数据中心网络面试的挑战

传统网络模型
- 虚拟机规模受网络设备表项规格的限制
- 对于同网段主机的通信而言,报文通过查询MAC表进行二层转发。服务器虚拟化后,数据中心中VM的数量比原有的物理机发生了数量级的增长,伴随而来的便是虚拟机网卡MAC地址数量的空前增加。MAC地址表项规模已经无法满足快速增长的VM数量。
- 传统网络的隔离能力有限
- VLAN作为当前主流的网络隔离技术,在标准定义中只有12比特,也就是说可用的VLAN数量只有4000个左右。对于公有云或其它大型虚拟化云计算服务这种动辄上万甚至更多租户的场景而言,VLAN的隔离能力显然不够
- 虚拟机迁移范围受限
- 虚拟机迁移,顾名思义,就是将虚拟机从一个物理机迁移到另一个物理机,但是要求在迁移过程中业务不能中断。要做到这一点,需要保证虚拟机迁移前后,其IP地址、MAC地址等参数维持不变。这就决定了,虚拟机迁移必须发生在一个二层域中。而传统数据中心网络的二层域,将虚拟机迁移限制在了一个较小的局部范围内。
目前Flannel 支持三种后端实现,分别是
- VXLAN;
- host-gw;
- UDP(性能较差);
VXLAN
即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。完全在内核态实现封装和解封装的工作,采用L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,可实现二层网络在三层范围内进行扩展,同时满足数据中心大二层虚拟迁移和多租户的需求。

VXLAN网络模型,出现了以下传统数据中心网络中没有的新元素
- VTEP(VXLAN Tunnel Endpoints,VXLAN隧道端点)
- VXLAN网络的边缘设备,是VXLAN隧道的起点和终点,VXLAN报文的相关处理均在这上面进行。它是VXLAN网络中绝对的主角,后面会讲到。
- VNI(VXLAN Network Identifier,VXLAN 网络标识符)
- 以太网数据帧中VLAN只占了12比特的空间,这使得VLAN的隔离能力在数据中心网络中力不从心。而VNI的出现,就是专门解决这个问题的。VNI是一种类似于VLAN ID的用户标示,一个VNI代表了一个租户,属于不同VNI的虚拟机之间不能直接进行二层通信。VXLAN报文封装时,给VNI分配了足够的空间使其可以支持海量租户的隔离。
- VXLAN隧道
- 就是将原始报文“变身”下,加以“包装”,好让它可以在承载网络(比如IP网络)上传输。“VXLAN隧道”便是用来传输经过VXLAN封装的报文的,它是建立在两个VTEP之间的一条虚拟通道。
VXLAN如何解决传统数据中心的一系列问题
- 隐形
- 前文提到MAC地址表项规模有限制,这时就需要VTEP,VTEP会将VM发出的原始报文封装成一个新的UDP报文,并使用物理网络的IP和MAC地址作为外层头,对网络中的其他设备只表现为封装后的参数。也就是说,网络中的其他设备看不到VM发送的原始报文。
- 如果服务器作为VTEP,那从服务器发送到接入设备的报文便是经过封装后的报文,这样,接入设备就不需要学习VM的MAC地址了,它只需要根据外层封装的报文头负责基本的三层转发就可以了。因此,虚拟机规模就不会受网络设备表项规格的限制了。
- 当然,如果网络设备作为VTEP,它还是需要学习VM的MAC地址。但是,从对报文进行封装的角度来说,网络设备的性能还是要比服务器强很多。
- 扩容
- 对于“传统网络的隔离能力有限”这个问题,VXLAN采用了“扩容”的解决方法,引入了类似VLAN ID的用户标示,也就是前文提到的VNI。一个VNI代表了一个租户,属于不同VNI的虚拟机之间不能直接进行二层通信。VTEP在对报文进行VXLAN封装时,给VNI分配了24比特的空间,这就意味着VXLAN网络理论上支持多达16M(即224-1)的租户隔离。相比VLAN,VNI的隔离能力得到了巨大的提升,有效得解决了云计算中海量租户隔离的问题。
- 迁移
- VXLAN网络模型有了VTEP的封装机制和VXLAN隧道后,所谓的 “二层域”就可以轻而易举的突破物理上的界限,也就是说,在IP网络中, 看起来传输的是跨越三层网络的UDP报文,实际却已经悄悄将源VM的原始报文送达目的VM。就好像在三层的网络之上,构建出了一个虚拟的二层网络,而且只要IP网络路由可达,这个虚拟的二层网络想做多大就做多大
- 更多详解内容请参考这篇文章
host-gw

host-gw示意图
假设现在,Node 1 上的 Infra-container-1,要访问 Node 2 上的 Infra-container-2。
当你设置 Flannel 使用 host-gw 模式之后,flanneld 会在宿主机上创建这样一条规则,以 Node 1 为例
$ip route
...
10.244.1.0/24 via 10.168.0.3 dev eth0
注释目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即dev eth0);并且,它下一跳地址(next-hop)是 10.168.0.3(即via 10.168.0.3)。
所谓下一跳地址就是如果 IP 包从主机 A 发到主机 B,需要经过路由设备 X 的中转。那么 X 的 IP 地址就应该配置为主机 A 的下一跳地址。
而从 host-gw 示意图中我们可以看到,这个下一跳地址对应的,正是我们的目的宿主机 Node 2。
一旦配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。显然,这个 MAC 地址,正是 Node 2 的 MAC 地址。
这样,这个数据帧就会从 Node 1 通过宿主机的二层网络顺利到达 Node 2 上。
而 Node 2 的内核网络栈从二层数据帧里拿到 IP 包后,会“看到”这个 IP 包的目的 IP 地址是 10.244.1.3,即 Infra-container-2 的 IP 地址。这时候,根据 Node 2 上的路由表,该目的地址会匹配到第二条路由规则(也就是 10.244.1.0 对应的路由规则),从而进入 cni0 网桥,进而进入到 Infra-container-2 当中。
可以看到,host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。
也就是说,这台“主机”(Host)会充当这条容器通信路径里的“网关”(Gateway)。这也正是“host-gw”的含义。
当然,Flannel 子网和主机的信息,都是保存在 Etcd 当中的。flanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。
注意在 Kubernetes v1.7 之后,类似 Flannel、Calico 的 CNI 网络插件都是可以直接连接 Kubernetes 的 APIServer 来访问 Etcd 的,无需额外部署 Etcd 给它们使用。
而在这种模式下,容器通信的过程就免除了额外的封包和解包带来的性能损耗。根据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右。
Flannel host-gw 模式必须要求集群宿主机之间是二层连通的。
总结基于上述原因,如果是在公有云上,由于宿主机网络本身比较“直白”,一般推荐更加简单的 Flannel host-gw 模式。(Calico项目也非常不错)
Service工作原理及实现模式
为什么使用Service,一方面是因为 Pod 的 IP 不是固定的,另一方面则是因为一组 Pod 实例之间总会有负载均衡的需求。
一个最典型的 Service 定义,如下所示
apiVersion: v1
kind: Service
metadata:
name: hostnames
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80
targetPort: 9376
selector:声明这个 Service 只代理携带了 app=hostnames 标签的 Pod
ports:这个Service的80端口,代理的是 Pod 的 9376 端口
对应的Deployment,如下所示
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: k8s.gcr.io/serve_hostname
ports:
- containerPort: 9376
protocol: TCP
这个应用的作用就是,就是每次访问 9376 端口时,返回它自己的 hostname
通过该 Service 的 VIP 地址 10.0.1.175,你就可以访问到它所代理的 Pod 了
$ kubectl get svc hostnames
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hostnames ClusterIP 10.0.1.175 <none> 80/TCP 5s
$ curl 10.0.1.175:80
hostnames-0uton
$ curl 10.0.1.175:80
hostnames-yp2kp
$ curl 10.0.1.175:80
hostnames-bvc05
这个 VIP 地址是 Kubernetes 自动为 Service 分配的。而像上面这样,通过三次连续不断地访问 Service 的 VIP 地址和代理端口 80,它就为我们依次返回了三个 Pod 的 hostname。这也正印证了 Service 提供的是 Round Robin 方式的负载均衡。对于这种方式,我们称为ClusterIP 模式的 Service。
关于Service的负载均衡,再Ingress部分做补充
实际上,Service 是由 kube-proxy 组件,加上 iptables 来共同实现的。
举个例子,对于我们前面创建的名叫 hostnames 的 Service 来说,一旦它被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则(你可以通过 iptables-save 看到它),如下所示
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
可以看到,这条 iptables 规则的含义是凡是目的地址是 10.0.1.175、目的端口是 80 的 IP 包,都应该跳转到另外一条名叫 KUBE-SVC-NWV5X2332I4OT4T3 的 iptables 链进行处理。
kube-proxy 通过 iptables 处理 Service 的过程,其实需要在宿主机上设置相当多的 iptables 规则。而且,kube-proxy 还需要在控制循环里不断地刷新这些规则来确保它们始终是正确的。
不难想到,当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。所以说,一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。
这是就需要 IPVS 模式的 Service,其工作原理当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作kube-ipvs0),并为它分配 Service VIP 作为 IP 地址,如下所示
# ip addr
...
73kube-ipvs0<BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.0.1.175/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。我们可以通过 ipvsadm 查看到这个设置,如下所示
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:80 rr
-> 10.244.3.6:9376 Masq 1 0 0
-> 10.244.1.7:9376 Masq 1 0 0
-> 10.244.2.3:9376 Masq 1 0 0
这三个 IPVS 虚拟主机的 IP 地址和端口,对应的正是三个被代理的 Pod。
这时候,任何发往 10.102.128.4:80 的请求,就都会被 IPVS 模块转发到某一个后端 Pod 上了。
而相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这一层上,理论上 IPVS 并没有显著的性能提升。但是,IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。这也正印证了我在前面提到过的,“将重要操作放入内核态”是提高性能的重要手段。
当然,IPVS 模块只负责上述的负载均衡和代理功能。而一个完整的 Service 流程正常工作所需要的包过滤、SNAT 等操作,还是要靠 iptables 来实现。只不过,这些辅助性的 iptables 规则数量有限,也不会随着 Pod 数量的增加而增加。
所以,在大规模集群里,非常建议为 kube-proxy 设置–proxy-mode=ipvs 来开启这个功能。它为 Kubernetes 集群规模带来的提升,还是非常巨大的。
Service 与 DNS 的关系
Service 和 Pod 都会被分配对应的 DNS A 记录(从域名解析 IP 的记录)
- ClusterIP 模式的 Service 比如上面的例子,它的 A 记录的格式是..svc.cluster.local。当你访问这条 A 记录的时候,它解析到的就是该 Service 的 VIP 地址。
- 指定了 clusterIP=None 的 Headless Service它的 A 记录的格式也是..svc.cluster.local。但是,当你访问这条 A 记录的时候,它返回的是所有被代理的 Pod 的 IP 地址的集合。当然,如果你的客户端没办法解析这个集合的话,它可能会只会拿到第一个 Pod 的 IP 地址。
外界连通Service与Service调试“三板斧”
Service 的访问信息在 Kubernetes 集群之外,其实是无效的。
这其实也容易理解所谓 Service 的访问入口,其实就是每台宿主机上由 kube-proxy 生成的 iptables 规则,以及 kube-dns 生成的 DNS 记录。而一旦离开了这个集群,这些信息对用户来说,也就自然没有作用了。
所以,在使用 Kubernetes 的 Service 时,一个必须要面对和解决的问题就是如何从外部(Kubernetes 集群之外),访问到 Kubernetes 里创建的 Service?
最常用的一种方式就是NodePort。例子
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: NodePort
ports:
- nodePort: 8080
targetPort: 80
protocol: TCP
name: http
- nodePort: 443
protocol: TCP
name: https
selector:
run: my-nginx
type=NodePort:声明它的类型
ports:声明了 Service 的 8080 端口代理 Pod 的 80 端口,Service 的 443 端口代理 Pod 的 443 端口。
这时候,要访问这个 Service,你只需要访问
< 任何一台宿主机的 IP 地址 >:8080
就可以访问到某一个被代理的 Pod 的 80 端口了。在 NodePort 方式下,Kubernetes 会在 IP 包离开宿主机发往目的 Pod 时,对这个 IP 包做一次 SNAT 操作,如下所示
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
这条规则设置在 POSTROUTING 检查点给即将离开这台主机的 IP 包,进行了一次 SNAT 操作,将这个 IP 包的源地址替换成了这台宿主机上的 CNI 网桥地址,或者宿主机本身的 IP 地址(如果 CNI 网桥不存在的话)。
如果一台宿主机上,没有任何一个被代理的 Pod 存在,使用 node 2 的 IP 地址访问这个 Service,请求会直接被 DROP 掉。
第二种方式,适用于公有云上的 Kubernetes 服务
可以指定一个 LoadBalancer 类型的 Service,如下所示
---
kind: Service
apiVersion: v1
metadata:
name: example-service
spec:
ports:
- port: 8765
targetPort: 9376
selector:
app: example
type: LoadBalancer
在公有云提供的 Kubernetes 服务里,都使用了一个叫作 CloudProvider 的转接层,来跟公有云本身的 API 进行对接。所以,在上述 LoadBalancer 类型的 Service 被提交后,Kubernetes 就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端。
第三种方式,是 Kubernetes 在 1.7 之后支持的一个新特性,叫作 ExternalName
举例
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
type: ExternalName
externalName: my.database.example.com
指定了一个 externalName=my.database.example.com 的字段
当通过 Service 的 DNS 名字访问它的时候,比如访问my-service.default.svc.cluster.local。那么,Kubernetes 返回的就是my.database.example.com。所以说,ExternalName 类型的 Service,其实是在 kube-dns 里为你添加了一条 CNAME 记录。这时,访问 my-service.default.svc.cluster.local 就和访问 my.database.example.com 这个域名是一个效果了。
实际上,在理解了 Kubernetes Service 机制的工作原理之后,很多与 Service 相关的问题,其实都可以通过分析 Service 在宿主机上对应的 iptables 规则(或者 IPVS 配置)得到解决。
举例当你的 Service 没办法通过 DNS 访问到的时候。你就需要区分到底是 Service 本身的配置问题,还是集群的 DNS 出了问题。一个行之有效的方法,就是检查 Kubernetes 自己的 Master 节点的 Service DNS 是否正常
# 在一个 Pod 里执行
$ nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
如果上面访问 kubernetes.default 返回的值都有问题,那你就需要检查 kube-dns 的运行状态和日志了。否则的话,你应该去检查自己的 Service 定义是不是有问题。
而如果你的 Service 没办法通过 ClusterIP 访问到的时候,你首先应该检查的是这个 Service 是否有 Endpoints
Endpoints:被 selector 选中的 Pod,就称为 Service 的 Endpoints,只有处于 Running 状态,且 readinessProbe 检查通过的 Pod,才会出现在 Service 的 Endpoints 列表里
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
需要注意的是,如果你的 Pod 的 readniessProbe 没通过,它也不会出现在 Endpoints 列表里。
而如果 Endpoints 正常,那么你就需要确认 kube-proxy 是否在正确运行。在我们通过 kubeadm 部署的集群里,你应该看到 kube-proxy 输出的日志如下所示
I1027 22:14:53.995134 5063 server.go:200] Running in resource-only container "/kube-proxy"
I1027 22:14:53.998163 5063 server.go:247] Using iptables Proxier.
I1027 22:14:53.999055 5063 server.go:255] Tearing down userspace rules. Errors here are acceptable.
I1027 22:14:54.038140 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns-tcp" to [10.244.1.3:53]
I1027 22:14:54.038164 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns" to [10.244.1.3:53]
I1027 22:14:54.038209 5063 proxier.go:352] Setting endpoints for "default/kubernetes:https" to [10.240.0.2:443]
I1027 22:14:54.038238 5063 proxier.go:429] Not syncing iptables until Services and Endpoints have been received from master
I1027 22:14:54.040048 5063 proxier.go:294] Adding new service "default/kubernetes:https" at 10.0.0.1:443/TCP
I1027 22:14:54.040154 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns" at 10.0.0.10:53/UDP
I1027 22:14:54.040223 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns-tcp" at 10.0.0.10:53/TCP
如果 kube-proxy 一切正常,你就应该仔细查看宿主机上的 iptables 了。而一个 iptables 模式的 Service 对应的规则,我在上一篇以及这一篇文章里已经全部介绍到了,它们包括
- KUBE-SERVICES 或者 KUBE-NODEPORTS 规则对应的 Service 的入口链,这个规则应该与 VIP 和 Service 端口一一对应;
- KUBE-SEP-(hash) 规则对应的 DNAT 链,这些规则应该与 Endpoints 一一对应;
- KUBE-SVC-(hash) 规则对应的负载均衡链,这些规则的数目应该与 Endpoints 数目一致;
- 如果是 NodePort 模式的话,还有 POSTROUTING 处的 SNAT 链。
通过查看这些链的数量、转发目的地址、端口、过滤条件等信息,你就能很容易发现一些异常的蛛丝马迹。
当然,还有一种典型问题,就是 Pod 没办法通过 Service 访问到自己。这往往就是因为 kubelet 的 hairpin-mode 没有被正确设置。
在 hairpin-veth 模式下,你应该能看到 CNI 网桥对应的各个 VETH 设备,都将 Hairpin 模式设置为了 1,如下所示
$ for d in /sys/devices/virtual/net/cni0/brif/veth*/hairpin_mode; do echo "$d = $(cat $d)"; done
/sys/devices/virtual/net/cni0/brif/veth4bfbfe74/hairpin_mode = 1
/sys/devices/virtual/net/cni0/brif/vethfc2a18c5/hairpin_mode = 1
而如果是 promiscuous-bridge 模式的话,你应该看到 CNI 网桥的混杂模式(PROMISC)被开启,如下所示
$ ifconfig cni0 |grep PROMISC
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
Service和Ingress
由于每个 Service 都要有一个负载均衡服务,所以这个做法实际上既浪费成本又高。作为用户,我其实更希望看到 Kubernetes 为我内置一个全局的负载均衡器。然后,通过我访问的 URL,把请求转发给不同的后端 Service。
这种全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的 Ingress 服务。所谓Ingress,就是Service的“Service”
一个 Ingress 对象的主要内容,实际上就是一个“反向代理”服务(比如Nginx)的配置文件的描述。而这个代理服务对应的转发规则,就是 IngressRule。
Ingress 只能工作在七层,而 Service 只能工作在四层。所以当你想要在 Kubernetes 里为应用进行 TLS 配置等 HTTP 相关的操作时,都必须通过 Ingress 来进行。
有了 Ingress 这个抽象,用户就可以根据自己的需求来自由选择 Ingress Controller。比如,如果你的应用对代理服务的中断非常敏感,那么你就应该考虑选择类似于 Traefik 这样支持“热加载”的 Ingress Controller 实现。
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号