编写Web测试用例---discover
随着功能的不断增加,对应的测试用例也呈现指数级的增了,对于实现十几个功能程序来讲,对应的单元测试用例可能就会达到上百个,对于这种情况 test.py 文件会变得异常臃肿,我们不得不将这些用例进行划分,分散到不同的文件中,这样更便于维护。
TestLoader该类根据各种标准负责加载测试用例,并它们返回给测试套件。正常情况下没有必要创建这个类的实例。unittest 提供了可以共享了 defaultTestLoader 类,可以使用其子类和方法创建实例,所以我们可以使用其下面的 discover()方法来创建一个实例。
discover(start_dir,pattern='test*.py',top_level_dir=None)
找到指定目录下所有测试模块,并可递归查到子目录下的测试模块,只有匹配到文件名才能被加载。
如果启动的不是顶层目录,那么顶层目录必须要单独指定。
start_dir :要测试的模块名或测试用例目录。
pattern='test*.py' :表示用例文件名的匹配原则。星号“*”表示任意多个字符。
top_level_dir=None:测试模块的顶层目录。如果没顶层目录(也就是说测试用例不是放在多级目录中),默认为 None。
将前面学到的web端的测试和单元测试整合到一起,写一个完整的案例
案例:百度搜索关键词:“Selenium自学网” 并打开课程页面。
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep import unittest class TestBaidu(unittest.TestCase): def setUp(self): print("baidu test ……") self.driver = webdriver.Chrome() self.driver.get("https://www.baidu.com/") def test_driver(self): self.driver.find_element_by_id('kw').clear() self.driver.find_element_by_id('kw').send_keys('Selenium 官网') self.driver.find_element_by_id('su').click() sleep(3) def tearDown(self): print("baidu end!!!!") self.driver.quit() if __name__ == "__main__": unittest.main()
执行案例的脚本
#/usr/bin python #-*- coding:UTF-8 -*- import unittest test_dir='./' discover=unittest.defaultTestLoader.discover(test_dir,pattern="web_baidu.py") if __name__ == '__main__': runer=unittest.TextTestRunner() runer.run(discover)
关于文件路径的思考
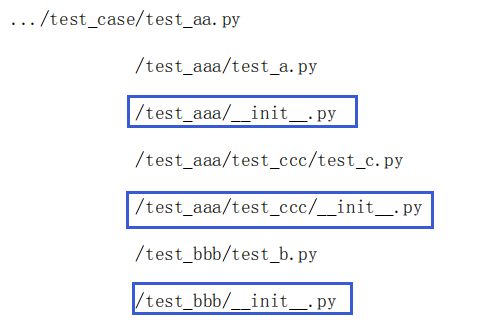
当test_dir 路径下的既有.py文件又有文件夹+.py或者 文件夹+文件夹+.py文件时,test_dir='./test_case/' 这种写法就只会运行该路径下的.py 文件,而无法运行二级三级文件夹下的py文件

解决办法:在目录下添加__init__.py 文件,结果如图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号