webdriver 元素定位
selenium python官方文档: https://python-selenium-zh.readthedocs.io/zh_CN/latest/
1. 元素定位
元素定位应该是自动化测试的核心,要想测试一个元素,首先需要定位这个元素。
webdriver 提供一系列的定位的方式
- id 唯一
- name 唯一
- class name
- link text
- partial link text
- tag name
- xpath
1.1 id和name定位
案例:打开百度页面,输入selenium 关键字,然后点击搜索按钮,查看搜索结果
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("https://www.baidu.com/") # driver.find_element_by_id('kw').send_keys("selenium 官网") driver.find_element_by_name('wd').send_keys("selenium 官网") driver.find_element_by_id('su').click() sleep(2) driver.quit()
1.2 tag_name定位
根据标签名称进行定位,比如:div form 等
案例:打开QQ邮箱页面,在用户名输入框输入 test
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome()
##网址应该是51自学网官网,百度的登录还有点问题 driver.get("http://www.baidu.com") # driver.find_element_by_tag_name('input').send_keys('test') #不建议采用这种方式,定位比较麻烦 driver.find_elements_by_tag_name('input')[0].send_keys('test') driver.find_elements_by_tag_name('input')[1].send_keys('111111') sleep(5) driver.quit()
1.3 class定位
根据标签对中属性class进行定位
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("https://www.baidu.com/") driver.find_element_by_class_name('s_ipt').send_keys('selenium 学习') driver.find_element_by_class_name('s_btn').click() sleep(3) print(driver.title) driver.quit()
1.4 link_text定位
根据网页的超链接进行定位
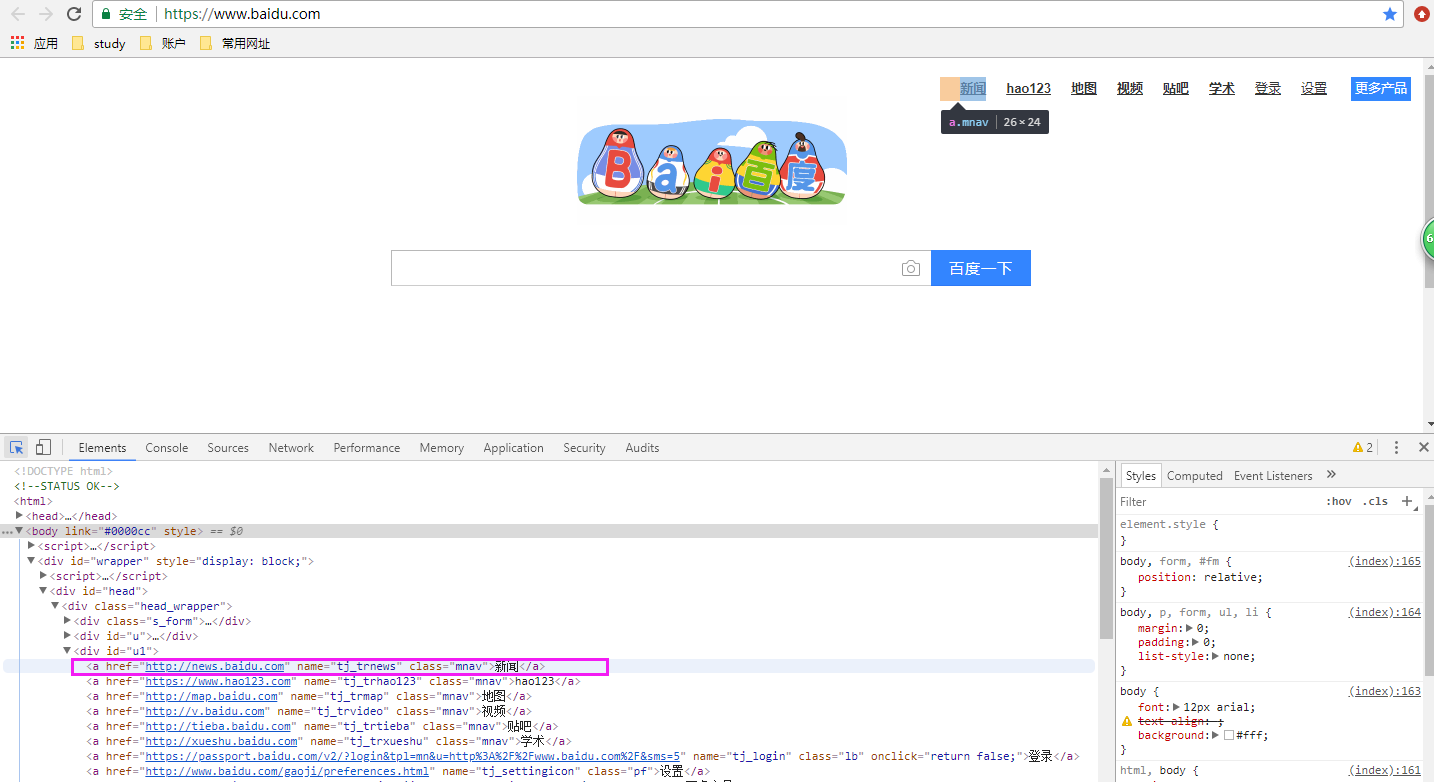
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get('https://www.baidu.com/') driver.find_element_by_link_text('新闻').click() # driver.find_element_by_name('tj_trnews') sleep(3) #模糊输入 driver.find_element_by_partial_link_text('端午佳节').click() sleep(3) driver.quit()
注意:输入的内容是 链接的内容,而不是网址
1.5 xpath定位
xpath 即为xml 路径语言,它是一种用来确定xml 中某部分位置的语言。xpath基于xml 的树状结构,提供在数据结构树中找寻节点的能力。
-
xpath 绝对与相对定位
一般不用绝对路径进行定位,可维护性差
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("https://www.baidu.com/") ##需要注意:当一个语句中出现多个"" 时,需要把每对区分开来,可以用'' "" 等,不然会报错 ##定位所有标签元素中,name 属性为 wd 的元素 driver.find_element_by_xpath("//*[@name='wd']").send_keys("selenium 官网") ##定位所有标签元素中,id 属性为kw 的元素 //表示当前页面,*表示所有标签元素 driver.find_element_by_xpath("//*[@id= 'su']").click() sleep(3) driver.quit()
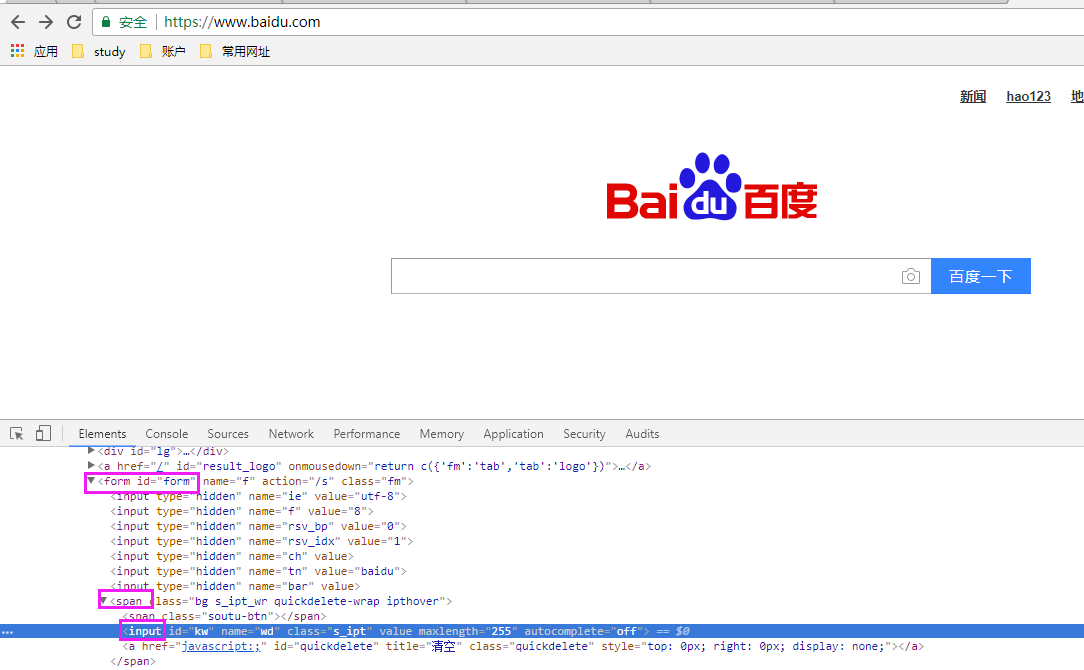
相对路径的xpayh 取值: 打开浏览器的开发者模式,点击下图按钮后,将鼠标放到要定位元素的位置,就可以定位到对应的代码路径,然后右键-copy - copy xpath 即可
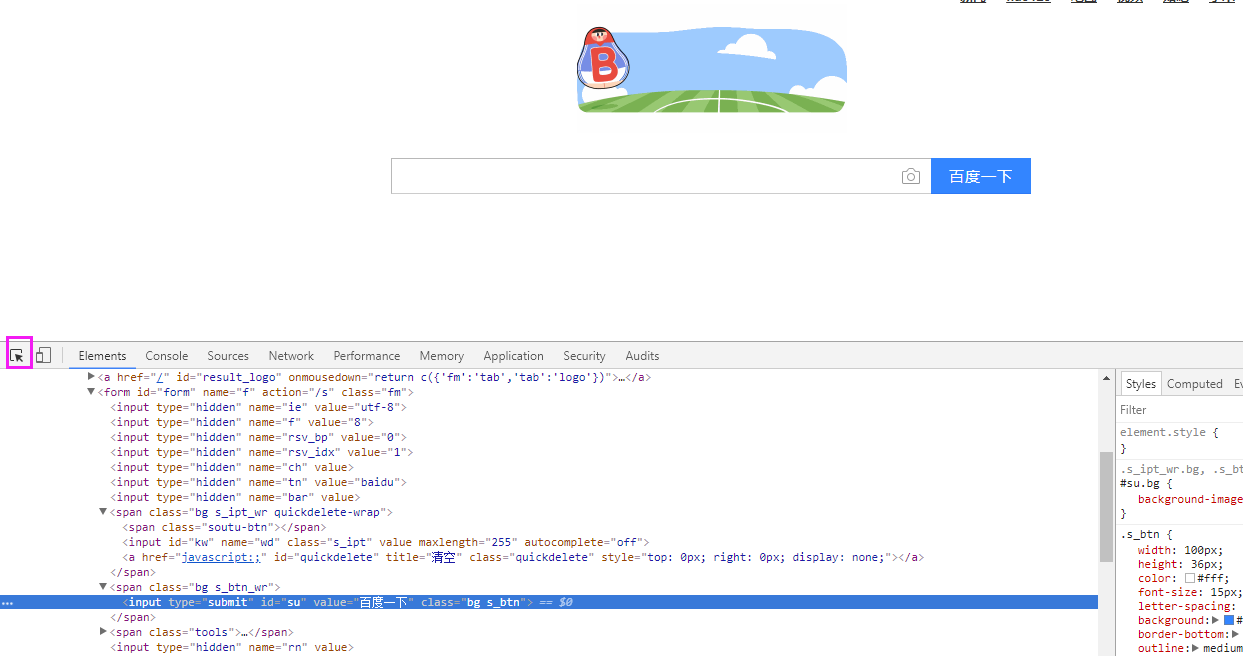
再比如:定位新闻可以如下:
driver.find_element_by_link_text('新闻').click(); driver.find_element_by_xpath('//*[@id="u1"]/a[1]').click(); driver.find_element_by_xpath('//*[@id="u1"]/a[@name="tj_trnews"]').click();
- 缺点:慢
- 使用范围:appium selenium xpath
- 语法: / 绝对路径、子元素 // 相对路径、子孙路径等
| 表达式 | 结果 |
| /bookstore/book[1] | 选取属于bookstore自元素的第一个book元素 |
| /bookstore/book[last()] | 选取属于bookstore子元素的最后一个book元素 |
| /bookstore/book[last()-1] | 选取属于bookstore子元素的倒数第二个book元素 |
| /bookstore/book[position()<3] | 选取最前面的两个属于bookstore元素的子元素的book元素 |
| //title[@lang='eng'] | 选取所有的title元素,且这些元素拥有值为eng的lang属性 |
| /bookstore/book[@price>20.00] | 选取bookstore元素的所有book元素,且其中的price元素的值必须大雨20.00 |
| /bookstore/book[@price>20.00]/title | 选取bookstore元素的所有book元素的所有title元素,且其中的price元素的值必须大雨20.00 |
| 表达式 | 结果 |
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选的当前节点选择文档中的节点,子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
举例:对百度页面的定位
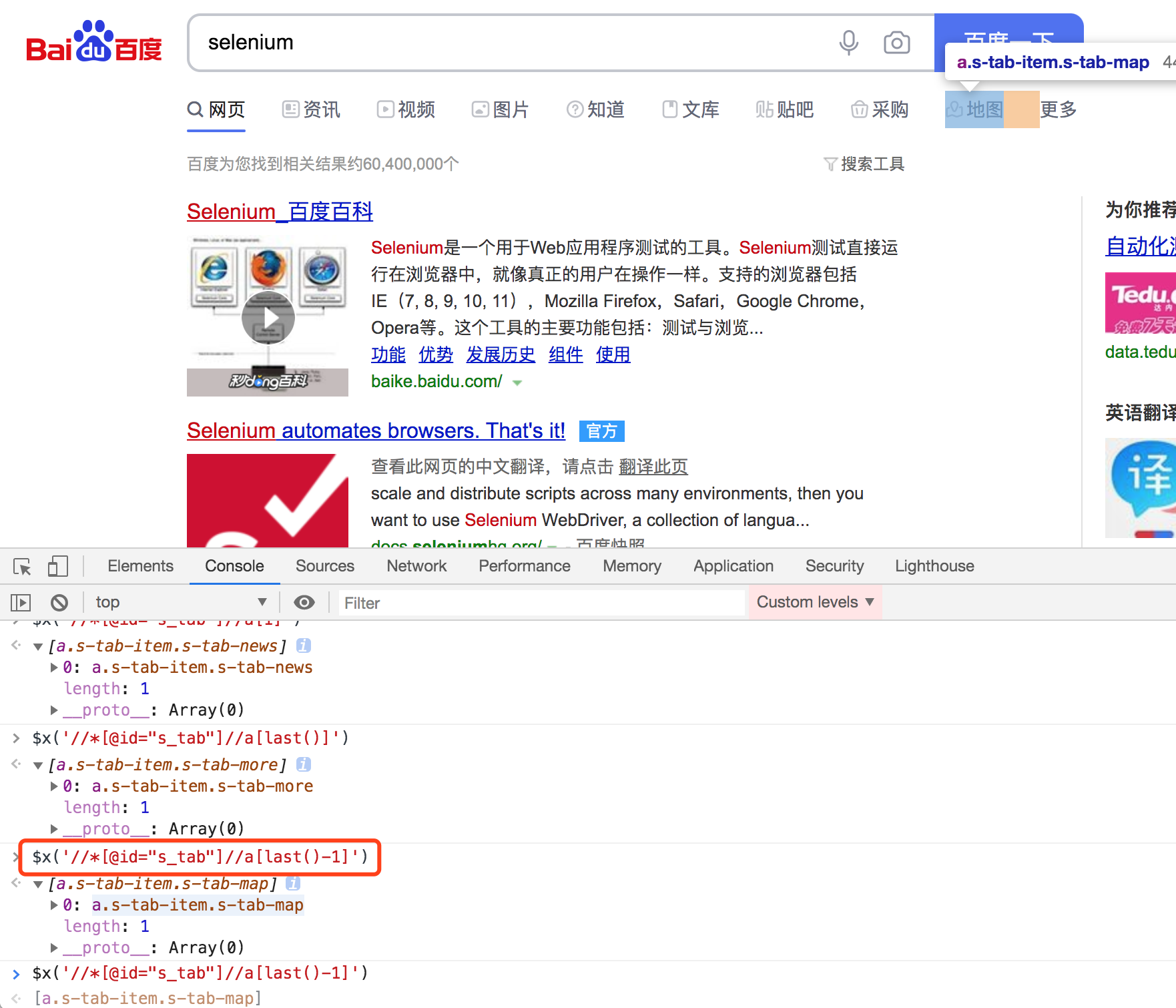
在控制台console中进行元素定位的校验:
- $x('//*[@id="s_tab"]//a[last()-1]') 说明:在浏览器开发者模式下 $x() 代表xpath语言,//* 选取所有元素,[@id="s_tab"] 是一个条件,属性是什么,// 从父元素中找子孙元素,a[last()-1] a标签中倒数第二个
- $x('//*[@name="wd"]') 说明:在所有元素中,找name="wd" 属性的
- $x('//*[@id="s-top-left"]/a[@href="http://news.baidu.com"]') 说明: 选择所有id = "s-top-left"的元素,且其子元素a元素有个属性值href="http://news.baidu.com"
1.5.2 xpath逻辑与层级定位
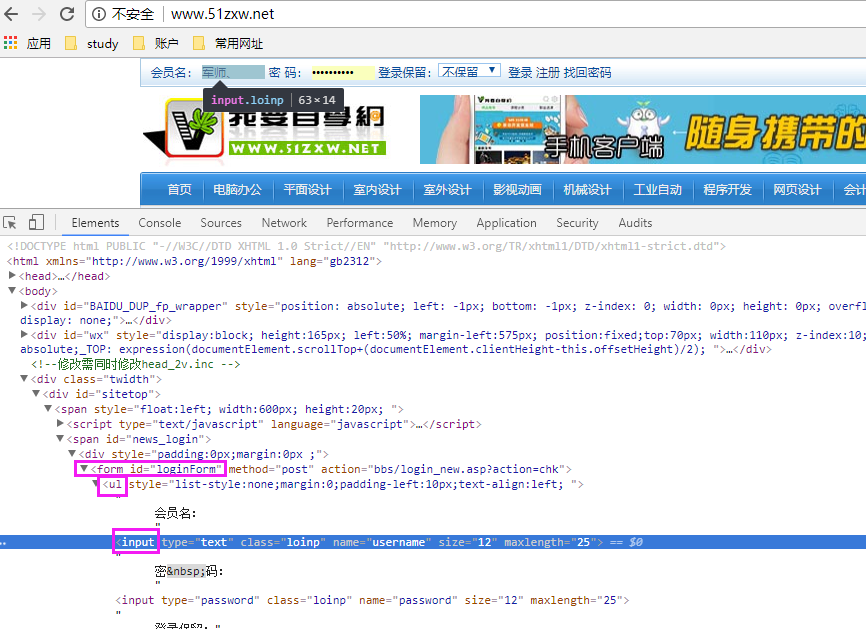
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("http://www.baidu.com") #层级和属性结合定位(仅供演示) driver.find_element_by_xpath("//form[@id='loginForm']/ul/input[1]").send_keys('test') driver.find_element_by_xpath("//form[@id ='loginForm']/ul/input[2]").send_keys('111111') sleep(3) #逻辑运算组合定位(仅供演示)
driver.find_element_by_xpath("//input[@class = 'loinp' and @name = 'username']").send_keys('111111') driver.quit()
1.6 Css定位
css 定位比xpayh定位更加简洁快速
css常用定位方法
- find_element_by_css_selector()
- #id id选择器根据id属性进行定位元素
- .class class 选择器根据class属性进行定位元素
- element > element 根据元素层级来定位 父层级>子层级
- [attribute = 'value'] 根据属性定位元素
CSS缺点:不能定位手机端原生的,但可以定位到手机中的H5页面
应用范围:selenium appium(部分)
CSS使用样式定位,Xpath从头到尾遍历,所以CSS比较快
CSS选择器常用语法:
| 选择器 | 例子 | 描述 |
| .class | .s_ipt | class选择器,选择class='s_ipt'的所有元素 |
| #id | #kw | id选择器,选择id='kw'的所有元素 |
| * | * | 选择所有元素 |
| element | input | 选择所有<input>元素 |
| element>element | div > input | 选择所有父元素<div>的所有<input>子元素 |
| element+element | div+input | 选择紧接在<div>元素之后的所有<p>元素 |
| [attribute=value] | [target="_blank"] | 选择[target="_blank"]的所有元素 |
- element>element : 类似于xpath中的 / (> 代表子)
- element element 类似于xpath中的 // (空格代表子孙)
| 选择器 | 例子 | 例子描述 |
| [attribute] | [target] | 选择带有target属性的所有元素 |
| :nth-child(n) | p:nth-child(2) | 选择属于其副元素的第二个子元素的每个<p>元素 |
| element1~element2 | p~ul | 选择前面由<p>元素的每个<ul>元素 |
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("https://www.baidu.com/") # #根据id 来定位 # driver.find_element_by_css_selector('#kw').send_keys('selenium 官网') #通过属性来定位 driver.find_element_by_css_selector('[autocomplete = "off"]').send_keys('selenium 官网') #根据class 来定位 # driver.find_element_by_css_selector('.s_btn').click() #通过元素层级来定位 form#form(#后面对应的是 标签的id值) driver.find_element_by_css_selector('form#form>span>input').click() sleep(3) driver.quit()
层级定位的取值方式:
!!!对于CSS,我们也可以通过F12来copy - copy selector获取!!!
举例:
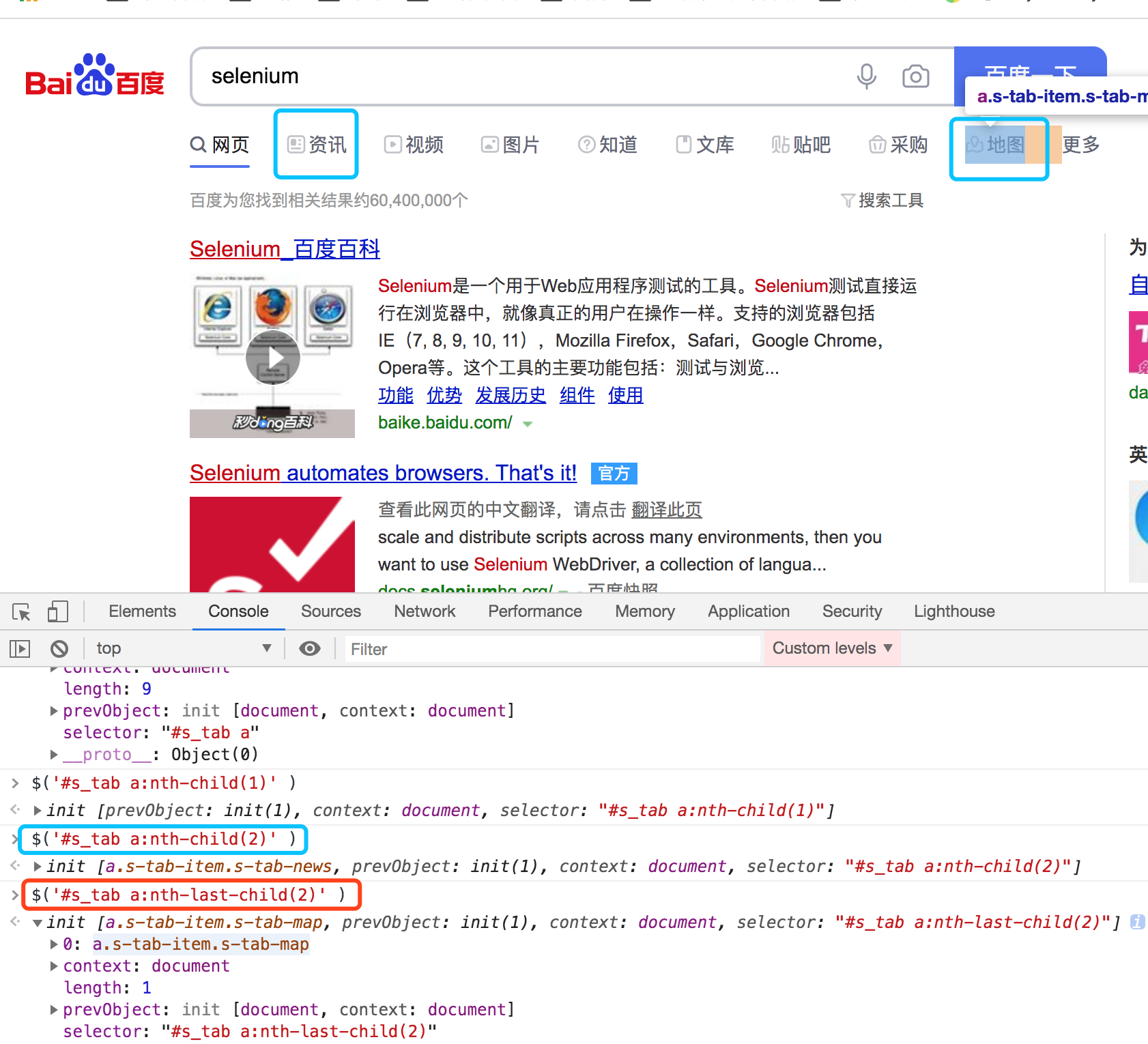
在浏览器开发者模式下使用$() 进行CSS定位校验
- $('#s_tab a:nth-child(2)' ) : #s_tab 标签内容,a 是#s_tab的子孙 a标签父类的第二个孩子
- $('#s_tab a:nth-last-child(2)' ) : a标签父类的倒数第二个孩子
1.7 下拉框菜单元素定位
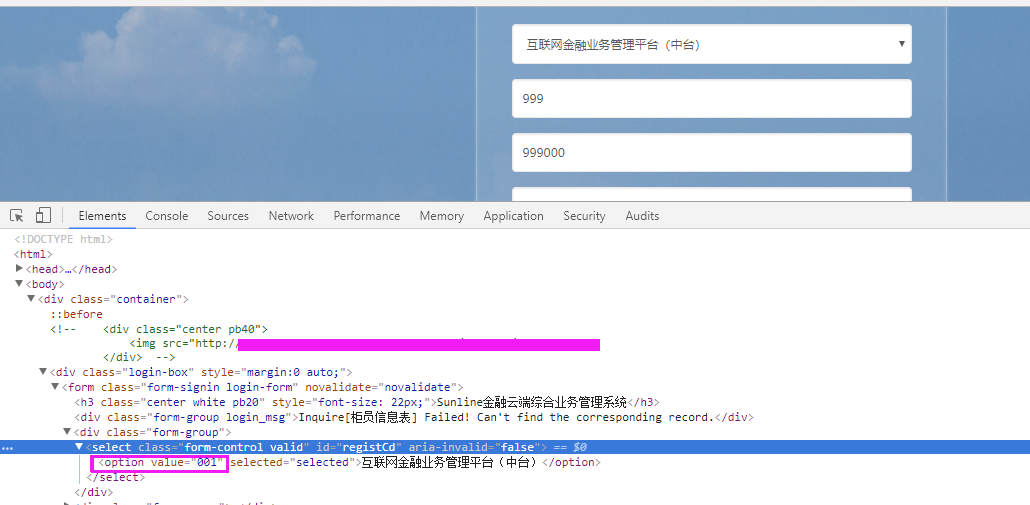
#/usr/bin python #-*- coding:UTF-8 -*- from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get("http://10.22.10.51:8080/sump/path/auth/login") #根据option标签定位 # driver.find_elements_by_tag_name('option')[0].click() driver.find_element_by_css_selector('[value = "001"]').click() driver.find_element_by_css_selector('#corpno').send_keys('999') # driver.find_element_by_css_selector('.valid').send_keys('999000') driver.find_element_by_id('brchno').send_keys('999000') driver.find_element_by_id('username').send_keys('admin') driver.find_element_by_id('password').send_keys('111111') driver.find_element_by_id('submit').click() sleep(5) driver.quit()
1.8 定位的另一种方式
- find_element(By.ID,"loginName")
- find_element(By.NAME,"SubjectName")
- find_element(By.CLASS_NAME,"u-btn-levred")
- find_element(By.TAG_NAME,"input")
- find_element(By.LINK_TEXT,"退出")
- find_element(By.PARTIAL_LINK_TEXT,"退")
- find_element(By.XPATH,".//*[@id='Title")
- find_element(By.CSS_SELECTOR,"[type=submit]")
from selenium import webdriver from selenium.webdriver.common.by import By from time import sleep driver=webdriver.Chrome() driver.get("http://www.baidu.com/") driver.implicitly_wait(5) driver.find_element(By.ID,'kw').clear() driver.find_element(By.NAME,'wd').send_keys("Selenium ") driver.find_element(By.CLASS_NAME,'s_ipt').send_keys("自学网 ") driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("自动化测试") sleep(3) driver.find_element(By.ID,'su').click() sleep(3) driver.quit()
1.9 实用
真实环境中遇到的DOM往往很复杂的多,下面我们来分析一下可能会遇到的几种情况
1.分级定位:复杂环境可以先定位父级元素,然后再定位子元素,例如parentElement.findElement(By.***)
2.ID定位是最快速最准确的,但实际上需要开发人员的友好配合才能有唯一且确定的id可用,真实环境中往往会出现没有id,id重复或者动态id(extjs和query都是动态id);若动态id有规律我们还能考虑使用正则表达式,否则只能老老实实另谋出路了。
3.定位数组元素:实际使用中className和tagName经常被用来定位数组元素,例如driver.findElements(by.tagName(“**”))或driver.findElements(by.className(“**”))
例如,打开www.baidu.com,运行List<WebElement> Els= driver.findElements(by.tagName(“a”));看看是不是得到了一个元素数组
4.className不允许使用复合类名做参数
真实环境中元素往往使用复合类名(即多个class用空格分隔),使用className定位时要注意了,className的参数只能是一个class。
例如,打开http://hao.360.cn/,我们要使用className定位这个元素
<a class="tab-item news" data-page="http://sh.qihoo.com/daohang/index1.html" hidefocus="false"href="./brother.html#!news">新闻头条</a>
1)执行driver.findElements(by.className("news")),成功定位到元素
2)执行driver.findElements(by.className("tab-item news")),定位失败,报错信息:Compound class names not permitted,意思是不允许使用复合类名称
分析:className的参数仅允许是一个class,此处class="tab-item news"是复合类名,直接使用会报错 ,但是可以选择复核类名中的和其他类名不同的部分进行定位,这样也可以成功
5.linkText与partialLinkText
遇到文字链接元素,首先考虑使用linkText定位,那它与partialLinkText有什么区别与特性呐?
1) linkText=链接文字,表示精准匹配链接文字;partialLinkText=部分链接文字,表示模糊匹配链接文字。例如定位一下元素
<a target="_blank" title="" href="http://www.nuomi.com/?cid=bdsywzl">劳动节不劳动,吃喝玩乐5.1元起!</a>
- driver.findElement(By.linkText("劳动节不劳动,吃喝玩乐5.1元起!"));
- driver.findElement(By.partialLinkText("吃喝玩乐"));
2.都对大小写敏感
6. 下拉框定位!!!!
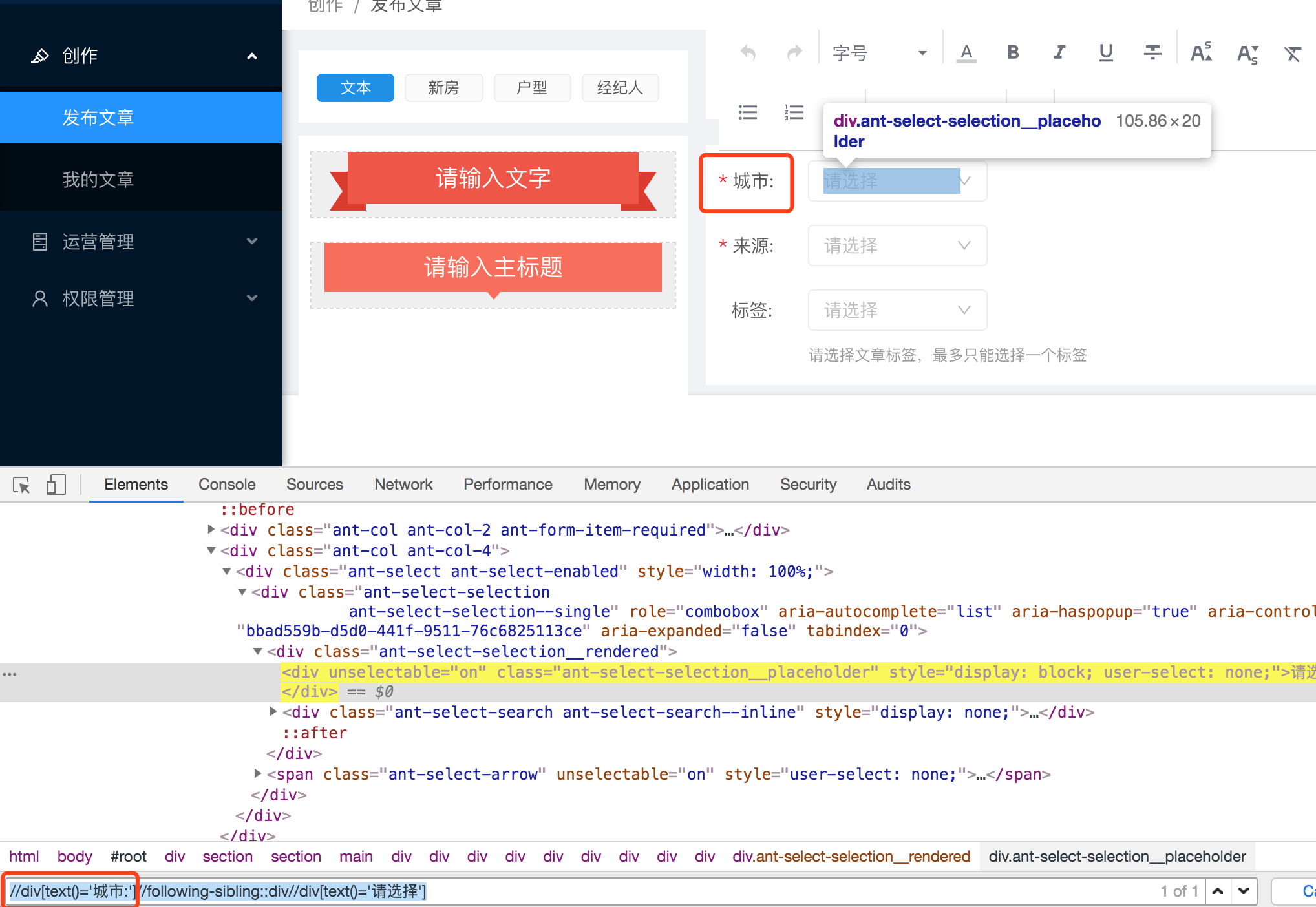
//div[text()='城市:']//following-sibling::div//div[text()='请选择']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号