



xml 文件概述
xml语言,即可扩展标记语言,它用来标记数据,定义数据类型,是一种允许用户对自己标记语言进行标记的源语言
从结构上来看,很像html 超文本标记语言。但是他们被设计的目的是不相同的,如下:
XML:被用来传输和存储数据
html:被设计用来显示数据
XML 特征
由标签对组成:<aaa></aaa>
标签可以有属性:<aaa id = '123'></aaa>
标签对可以嵌入数据:<aaa>哈哈</aaa>
标签可以嵌入子标签:(具有层级关系)
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <flowtran id="bxprop" longname="各渠道备付金监控" kind="1" package="cn.sunline.ltts.busi.lntran.trans.bx" xsi:noNamespaceSchemaLocation="ltts-model.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <description><![CDATA[各渠道备付金监控]]></description> <interface package="cn.sunline.ltts.busi.lntran.trans.bx.intf"> <input packMode="true"> <field id="instdt" type="BaseType.U_DATE08" required="false" multi="false" array="false" longname="放款日期"/> <field id="prodcd" type="BaseType.U_CHAR20" required="false" multi="false" array="false" longname="产品号"/> </input> <output asParm="true" packMode="true"> <field id="infos" alias="金额输出" type="LnCashLoanComplex.selQuDaoBalInfo" required="false" multi="true" array="false" longname="金额输出"/> </output> <property packMode="false"/> <printer packMode="false"/> </interface> <flow> <method method="selsheQuDaoInfo" id="selsheQuDaoInfo" longname="查询各渠道金额" desc="查询各渠道金额"/> </flow> </flowtran>
XML文本结构
xml文档形成一种树结构,从根部开始,扩展到枝叶
第一行是xml声明,定义xml的版本及编码格式
DOM文档对象模型
对xml中的值,进行增删改查

直接修改title值
document.title = '18282'
创建xml文件
创建一个Class.xml文件,用来存储班级学生(姓名,年龄),班主任(姓名,年龄),教务账号(学生和老师的账户,密码)等信息
<?xml version="1.0" encoding="UTF-8"?> <class> <student> <name>小明</name> <city>beijing</city> </student> <student> <name>小花</name> <city>beijing</city> </student> <teacher> <name>MM</name> <city>beijing</city> </teacher> <account> <login username = "student" passwd = "111111"></login> <login username = "teacher" passwd = "111111"></login> </account> </class>
XML节点
- 元素节点
- 文本节点
- 属性节点
每个节点都拥有着包含节点某些信息的属性,这些属性是:
- nodeName(节点名称)
- nodeValue(节点值)
- nodeType(节点类型)
读取元素节点
查看Class.xml文件中Class节点的属性(节点名称,节点值,节点类型)
from xml.dom import minidom #加载xml文件 dom = minidom.parse('Class.xml') #加载dom对象元素 root = dom._get_documentElement() #打印节点信息 print(root.nodeName) print(root.nodeType) print(root.nodeValue)
- nodeName:节点名称
- nodeValue:返回文本节点的值
- nodeType:属性值返回以数值返回指定节点的节点类型
- 如果节点是元素节点,则返回1
- 如果节点是属性节点,则返回2
输出结果:
读取文本节点的值
分别打印出Class.xml文件中学生和老师的详细信息
#/usr/bin python #-*- coding:UTF-8 -*- from xml.dom import minidom #####################################获取标签对的值############################################# #打开文件 dom = minidom.parse('Class.xml') #获取文档对象元素 root = dom._get_documentElement() #根据标签名称获取标签对象 names = root.getElementsByTagName('name') citys = root.getElementsByTagName('city') #分别打印显示xml文档标签对立面的内容 for i in range(3): print(names[i].firstChild.data) print(citys[i].firstChild.data)
输出结果: 
读取属性节点的值
案例:分别读取老师学生的账号密码
#/usr/bin python #-*- coding:UTF-8 -*- from xml.dom import minidom #####################################读取属性节点的值############################################# #打开文件 dom = minidom.parse('Class.xml') #获取文档对象元素 root = dom._get_documentElement() logins = root.getElementsByTagName('login') #获取login标签的username属性 for i in range(2): username = logins[i].getAttribute('username') passwd = logins[i].getAttribute('passwd') print("username: %s" %username) print("passwd: %s" %passwd)
输出结果:
读取子节点信息
读取子节点student相关属性
- nodeName(节点名称)
- nodeValue(节点值)
- nodeType(节点类型)
#/usr/bin python #-*- coding:UTF-8 -*- from xml.dom import minidom #####################################读取子节点的属性############################################# #打开文件 dom = minidom.parse('Class.xml') #获取文档对象元素 root = dom._get_documentElement() tags = root.getElementsByTagName('student') print(tags[0].nodeName) print(tags[0].tagName) print(tags[0].nodeType) print(tags[0].nodeValue)
输出结果: 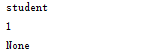
python获取xml文件方法集合
-
引入模块处理xml文件
from xml.dom.minidom import parse -
打开xml文档,
DOMTree = xml.dom.minidom.parse(data_path) -
根据xml文档,得到文档元素的对象
data = DOMTree.documentElement -
获取节点列表
nodelist = data.getElementsByTagName(大类名称) -
获取第一个节点的子节点列表
childlist = nodelist[0].childNodes -
获取XML节点属性值
node.getAttribute(AttributeName) -
获取XML节点对象集合
node.getElementsByTagName(TagName) -
返回子节点列表
node.childNodes -
获取XML节点值
node.childNodes[index].nodeValue -
访问第一个节点
node.firstChild,等价于pagexml.childNodes[0] -
访问元素属性 例如:
Node.attributes["id"]a.name #就是上面的 "id"a.value #属性的值


 浙公网安备 33010602011771号
浙公网安备 33010602011771号