性能检测诊断(来自全栈性能测试修炼宝典Jmeter实战)
1、操作系统性能分析介绍
操作系统是管理和控制计算机硬件和软件的计算机程序。它的功能包括管理计算机软件、硬件及数据资源,控制程序运行,改善人机界面等。
响应时间RT(response time):从服务器接收到请求到该请求的相应处理完毕,并把对应数据发送至客户端。
用户响应时间=服务器响应时间 + 网络时间
2、系统性能分析思路
总体来说,我们可以从以下几块来分析: 整体系统CPU利用率;内存利用率;磁盘I/O利用率;网络利用率
2.1 系统性能分析因素--CPU
命令查看CPU占用情况: top、free、uptime、sar等
一般我们期望:系统平均可用的CPU不少于20%
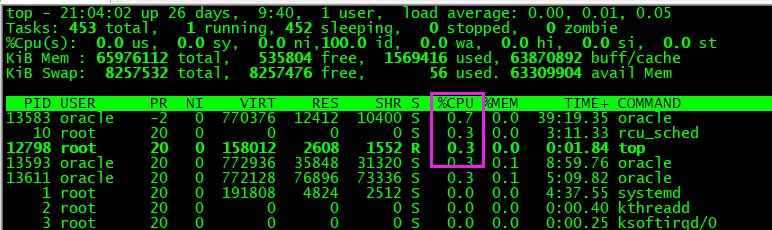
上图为top命令运行的结果,可以看出当前应用Oracle占用内存最高,且为0.7%
2.2 系统性能分析因素--内存
关于内存的分析,一般情况下,我们希望内存要做够大,目前基本上都要求在8G以上,而32位的寻址范围有限,可能无法使用这么大的内存,所以就要求用64位操作系统。
命令查看内存的使用情况:
top

free:

Mem: used 使用的物理内存总量;free:空闲的内存总量;buff/cache: 缓冲的内存总量;
Swap:total 交换区总量;used: 使用的交换区总量;free:空闲的交换区总量
2.3 系统性能分析因素--网络
在系统中,我们要考虑对应网络是否可达、防火墙是否开启、端口的访问、带宽是否有被限制、路由寻址、网络时延等问题
2.4 系统性能分析因素--I/O
由于CPU处理频率比磁盘的物理操作快几个数量级,所以当I/O比较频繁(读写操作比较频繁)时,如果I/O得不到满足就会导致应用阻塞。
针对I/O场景模型,我们要考虑的有 I/O的TPS、平均I/O数据、平均队列长度、平均服务时间、平均等待时间、IO利用率等指标
2.5 系统性能分析因素--总结
很多时候,系统性能因素之前相互依赖,任何一个高负载的状态下,都可能影响其他资源。
在进行系统性能分析时,最重要的就是,我们需要确定应用的类型,理解并分析当前系统的特点,多数系统对应的应用类型主要分为以下两种:
IO范畴:一般这类应用都是高负荷的内存使用及存储系统,IO类型的应用就是一个大量数据处理的过程。IO范畴应用通常使用CPU资源都是为了产生IO请求及进入到内核调度sleep状态。通常数据库软件(Oracle MySQL等)被认为是IO范畴的应用类型
CPU范畴:在这个范畴的应用,一般都是高负荷的CPU占用。CPU范畴的应用就是一个批量处理CPU请求及数学计算的过程。通常 web server及其他类型的服务被认为是CPU范畴的应用。
3、瓶颈阈值分析思维导图及手册
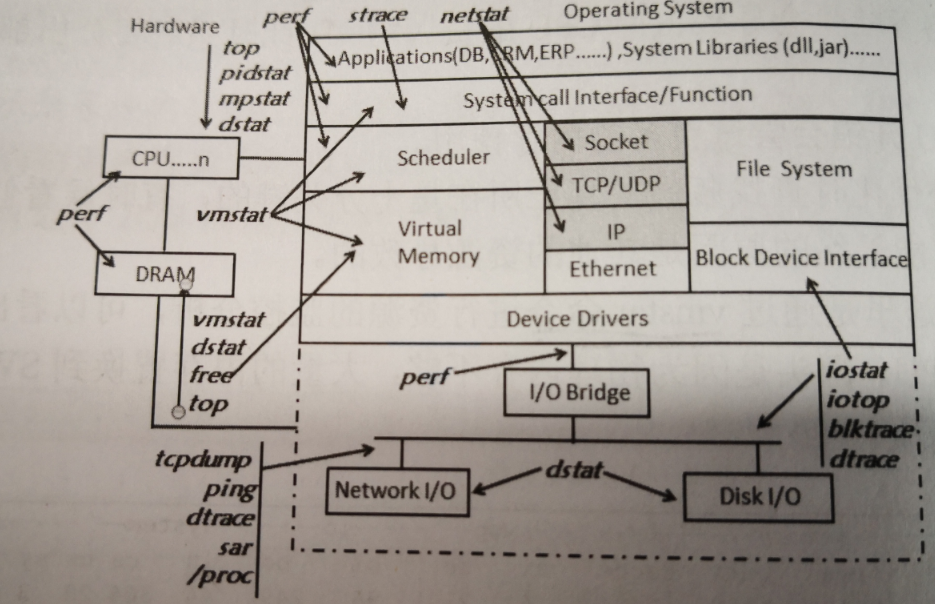
3.1 CPU定位分析
一般而言,在系统的CPU分析定位过程中,当CPU利用率大于50%时,就需要注意了;当大于70%时,就需要密切关注;当大于90%时,情况就比较严重。
监测CPU的命令:vmstat、sar、dstat、mpstat、top、ps 等
3.2 内存定位分析
一般而言,在系统的内存分析定位过程中,当内存利用率大于50%时,就需要注意了;当大于70%时,就需要密切关注;当大于80%时,情况就比较严重。
监测内存的命令:vmstat、sar、dstat、free、top、ps 等
3.3 网络定位分析
衡量网络使用情况的命令:ifconfig、sar、netstat 等,通过查看发现收发包吞吐速率达到网卡的最大上限,网络数据报文有因为这类原因而引发的丢包、阻塞等现象都证明当前网络可能存在瓶颈。在运行性能测试时,为了减小网络的影响,一般都是在局域网中进行测试。
3.4 IO定位分析
衡量系统IO的使用情况,我们使用sar,iostat,iotop等命令。当发现IO利用率大于40%时,就需要注意了;当大于60%时,则处于警告阶段;大于80%IO就出现阻塞
注意:该模块需要看书,会详解各命令的度量方式及标准。
4、linux系统性能分析思路与实践
4.1 系统负载监控分析实践
在系统开始运行的时候,CPU处理核数已经是一个固定的值,它的大小决定同一时刻,系统可以承受的最大负载。当超过这个负载时,就会出现阻塞。可以用uptime、top等命令来分析系统的负载。
uptime: 主要用于获取主机运行时间和查询Linux的系统负载(一段时间的平均值)等。

分别代表:当前系统时间、主机已运行时间、当前登录用户数、过去1分钟的平均负载、过去5分钟的平均负载、过去15分钟平均负载
经验总结:(1)uptime存活时间越长,意味着系统越稳定,也可以用这个命令查看系统最近是否重启过。
(2)通过uptime可知道当前登录用户数,w命令也可更好的显示这个功能:

(3)平均负载:在特定时间段内运行队列中的平均进程数。一般系统建议每个CPU内核的当前活动进程数最好不要大于0.8,证明系统是正常的;大于1且不大于3的时候,如果系统的其他资源正常,也还可以接受;但如果任务数大于5的话,那性能就有问题了。
(4) 统计过去一分钟(五分钟、十五分钟)的负载: uptime |awk '{print$(NF-2)}' uptime |awk '{print$(NF-1)}' uptime |awk '{print$NF}'
4.2 系统监控分析实践
top 类似于Windows系统的任务管理器工具。它对所有正在运行的进程和系统载荷提供不断更新的概览信息,包括:系统负载、CPU分布情况、内存使用、每个进程的内存使用情况等信息。
top命令运行总览:

top详解:
任务队列信息:
可以看出,当前系统时间:19:04:39 ;当前系统运行up 27 days, 7:41;当前有1个用户登录;此时的系统负载0.00,0.01,0.05 ,都不大
当前系统运行时间,可反映当前系统的存活时间,对于要求7*24高可用性的系统,该参数意义重大
进程状态信息:
在Linux操作系统中,我们一般可以看到五种状态的进程信息。
R:运行中
S:睡眠中
T:被跟踪或已停止
Z:僵尸态
D:不可中断的睡眠态
CPU信息:
我们一般关注:us、sy、hi、si、id、wa这6个数值(us:用户空间使用率;sy:内核空间占用CPU百分比;hi :硬中断占用CPU百分比;si:软中断占用CPU百分比;id:空闲CPU百分比;wa:等待输入输出的CPU时间百分比)
需要注意:(1)CPU(s):当前CPU的平均值,如果按下1键,可以显示各颗逻辑CPU的使用情况
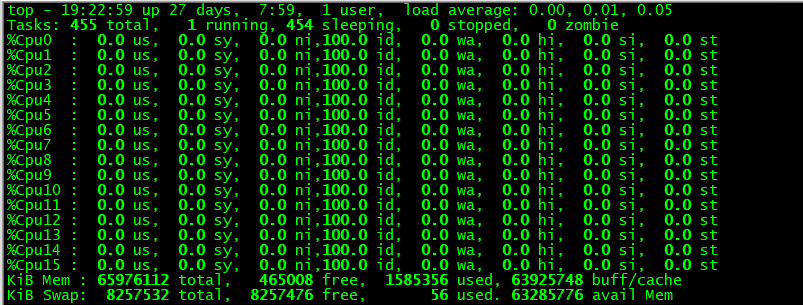
(2)统计使用CPU的利用率可以通过:1-%id获取 (因为:%id代表的是空闲CPU占比)
(3)wa:使用率过高时,要考虑IO的性能是否瓶颈,可以用iostat,sar进一步分析
(4)hi:过高时,表示当前硬件中断占用很大比例,
(5)si:过高时,表示当前软件中断占用很大比例,常见的软中断一般与网络相关。
(6)ni:代表用户进程空间内改变优先级的进程占用CPU百分比
内存信息:
主要包括:Mem used :使用的物理内存总量;free:空闲的内存总量;buffers:用做内核缓存的内存量;cached:缓冲的交换区总量;
Swap total:交换区总量;used:使用的交换区总量;free:空闲的交换区总量
分析: (1)buff 和cache 的作用是缩短I/O系统调用的时间,比如读写等。
(2)Swap区的内存总数 : Swap_total = used + free
进程信息:
主要包括:进程号(PID),进程所有者(USER),优先级(PR),nice值(NI,负代表高优先级,正代表低优先级),进程使用的虚拟内存(VIRT),实际物理内存(RES),共享内存(SHR),上次更新到现在的CPU时间占用百分比(CPU),进程使用的物理内存百分比(%MEM),命令行(COMMAND)等信息
分析: (1)进程实际使用的内存是查看 RES 这一列,VIRT 代表的是进程使用的虚拟内存的数据,SHR 代表共享内存的信息
(2)TIME+ :进程使用的CPU时间总计,而非进程的存活时间。
(3) %CPU:进程所占用的CPU百分比,通过这个可以得出进程的CPU占用率
tips: (1)top间隔刷新:输入top后,按下d进入间隔刷新设置,输入间隔秒数即可。
(2)top的更多命令参数可参考 http://www.cnblogs.com/fanpl/articles/8618891.html
(3)top 监控日志如需重定向到文本中的话,一定要带上参数 -b ,否则会乱序 : top -b -d 1 -n 3 > top.log (-d 参数用来设置刷新频率;-n 退出前监控的次数)
5、JVM监控
以下为几个常见的监控命令和一个可视化监控工具(JvisualVM)
5.1 jps
jps 返回当前系统中Java的进程号
参数: -l :返回Java进程全路径
-q:仅显示进程ID
-v:返回JVM参数,比如堆大小(此命令方便我们查看JVM大小)

5.2 jstat
JVM内存不够用、内存溢出是通过监控JVM HEAP 信息来分析的,jstat可以用来查询JVM堆的统计信息。
比如:jstat统计类信息
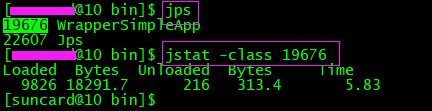
分别为: 加载类的数目、加载类的大小(Byte)、卸载类的数目、卸载类的size(Byte)、加载和卸载类花费的时间
更多详情参考:https://docs.oracle.com/javase/1.5.0/docs/tooldocs/share/jstat.html
5.3 jmap
分析程序内存占用实际上是分析堆(heap)内存,堆快照使用jmap获取
5.4 JvisualVM
JvisualVM 是JDK提供的JVM可视化监控工具,它能为您提供强大的分析能力,可以使用JvisualVM监控堆内存变化的情况、线程状态、CPU使用情况、分析线程死锁等。
详情:第九章JVM监控

 浙公网安备 33010602011771号
浙公网安备 33010602011771号