
JDK成长记13:(深度好文)你能从3个层面分析volatile底层原理么?(上)

前几节你应该学习到了Thread和ThreadLocal的底层原理,在接下来的几节中,让我们一起来探索volatile底层原理吧!
不知道你有没有这样的感受:有很多工程师都很难说清楚volatile这个关键字的作用或者原理。比如有的人压根不知道volatile的作用、应用场景;比如有的人也不知道什么是有序性,可见性,原子性,比如有的人可能能说上来它的作用是什么“保证有序性,可见性,无法保证原子性。”但是大多数人很难说清楚为什么能保证有序性,可见性,不能保证原子性;比如在面试的时候,你经常被面试官问到volatile的时候,回答的支支吾吾的,没有一个清晰的思路,答不出一个满意的答案。诸如此类的场景有很多等等……
要想弄明白这些,可不是简单的事情。所以在接下来的《JDK源码成长记-并发篇》中,就一步一步带领你来探索volatile的奥秘,来解决这些尴尬的场景,可以熟练运用和理解volatile关键字。
Hello Volatile
Hello Volatile
首先你要了解的第一点就是,什么时候使用volatile。这里你要记住以下两点就可以了:
1、 多个线程对同一个变量有读有写的时候
2、 多个线程需要保证有序性和可见性的时候
让我们分别来看看这两点:
volatile第一个使用场景:多个线程对同一个变量有读有写的时候。你可以通过一个Hello Volatile的例子来理解这一点。
代码如下:
public class HelloVolatile {
//可见性举例
private static volatile boolean shouldRunning = true;
//一个线程修改后,另一个线程无法读到修改后的值,线程之间的内存数据不可见
// private static boolean shouldRunning = true;
public static void main(String[] args) {
new Thread(()-> {
System.out.println("读取到变量shouldRunning="+HelloVolatile.shouldRunning);
while(HelloVolatile.shouldRunning) {
}
System.out.println("运行结束,读取到变量shouldRunning="+HelloVolatile.shouldRunning);
}).start();
new Thread(()-> {
try {
System.out.println("修改变量");
Thread.sleep(1000);
HelloVolatile.shouldRunning = false;
} catch (InterruptedException e) {
}
}).start();
}
}
上面的代码很明显可以看出来,两个线程。线程1在while循环中使用shouldRunning判断是否改跳出循环,线程2修改了shouldRunning。这就是典型的一读一写的场景。
画张图让大家更好的理解下:
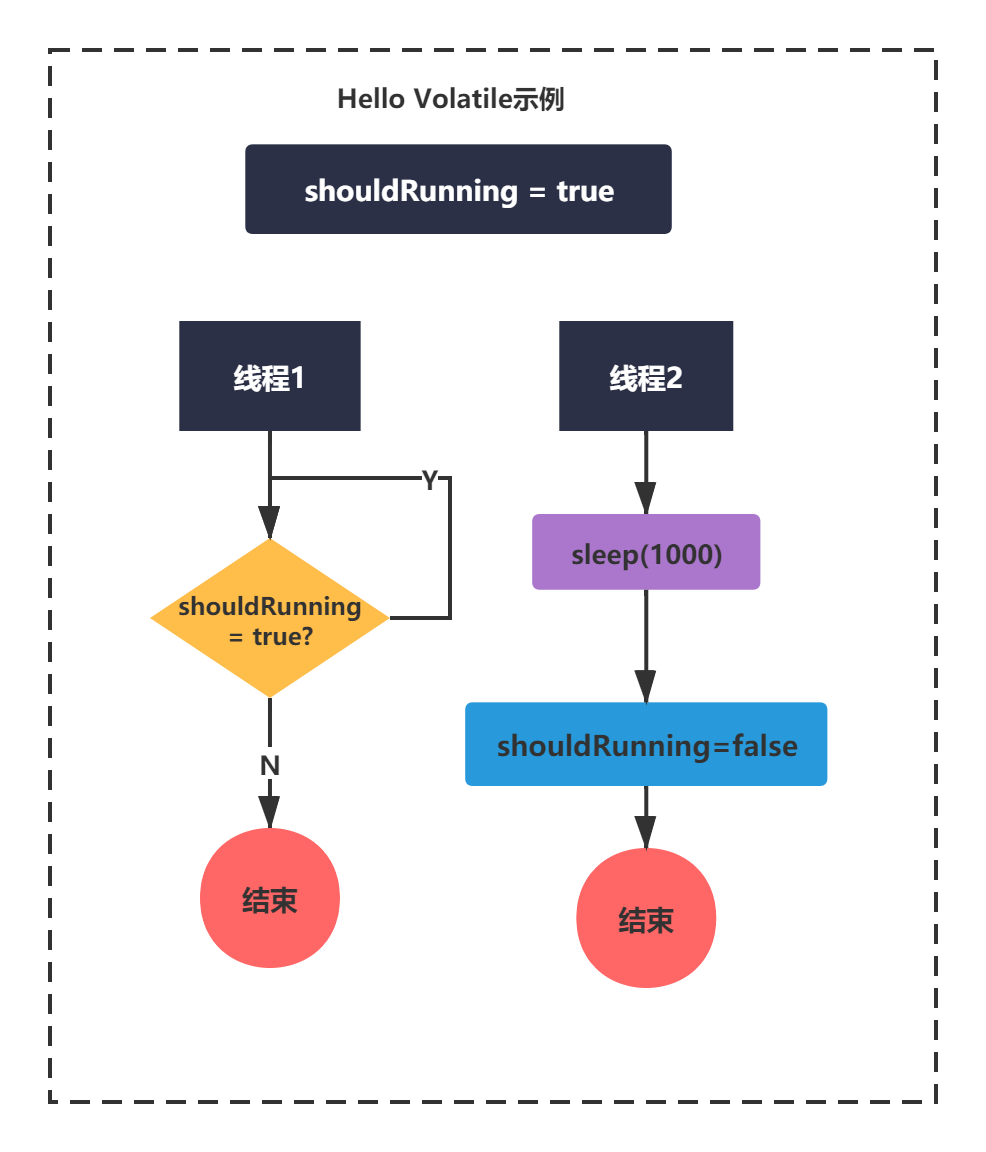
这种用法看上去很简单,但是其实在很多开源框架的底层,对线程执行控制都是通过这种方式控制的。等学完volatile之后,我会给大家举几个例子的。
volatile第二个使用场景:需要保证有序性和可见性的时候。后面我们会逐渐研究这两点。
上面的例子中,如果不加volatile修饰shouldRunning变量,线程2修改了值后,线程1是不可见的,也就不会跳出循环。
如果要想理解有序列性,这里给大家也给大家举一个经典的例子,在线程安全的单例(DLC-double check lock)的场景下,volatile很重要的作用就是保证有序性。
还有一点要提到的是,volatile既保证了有序性,也保证了可见性。并不是说HelloVolatile中没有有序性保证。
我给大家找了SpringCloud Eureka组件中的配置管理器创建,就是使用了DCL的单例。
代码如下:
public class ConfigurationManager {
static volatile AbstractConfiguration instance = null;
public static AbstractConfiguration getConfigInstance() {
if (instance == null) {
synchronized (ConfigurationManager.class) {
if (instance == null) {
instance = getConfigInstance(Boolean.getBoolean(DynamicPropertyFactory.DISABLE_DEFAULT_CONFIG));
}
}
}
return instance;
}
}
等学完volatile之后,我们在回头看下这个DCL使用volatile保证有序性的。这里大家有个印象就行。
什么是有序性、可见性、原子性?
什么是有序性、可见性、原子性?
前文提到了有序性、可见性、原子性。可能有人不太清楚他们是什么意思。更不理解怎么保证的,原理是什么。
而你要想理解volatile如何保证有序性和可见性,首先需要明白有序性、可见性、原子性分别是什么。这里我先不深入讲解,先用一句话大白话简单给大家概况下。
- 可见性,一句话讲就是多个线程中有读有写操作同一个变量的时候,线程间可以互相知道,可见的意思。
- 有序性,一句话讲就是由于代码执行顺序可能被重排序,volatile可以保证代码行数按顺序执行。
- 原子性,一句话讲就是当多个线程进行同时写同一个变量的时候,只能有一个线程进这一操作。
你可能看了上面三句话,还不是很明白,没关系,最后学习完volatile了,你可以回来再看看这三句话。
下面我们从浅入深来探索下这三点。主要层次有如下几个级别:
1、JVM内存模型和Java内存模型(JMM) 层面
2、JVM指令层面和JVM中的C++源码层面
3、CPU缓存模型+硬件结构原理+CPU指令层面
JVM内存结构和JMM的概念回顾
JVM内存结构和JMM的概念回顾
简单的讲,一句话:就是刷新主内存,强制过期其他线程的工作内存。
这句话中的主内存和工作内存是Java内存模型中的概念,要想理解Java内存模型(JMM),一定要知道JVM的内存结构(运行时内存区域)。下面通过几张图,让你回顾下JVM内存结构和JMM的概念。
首先回顾一下,JVM的内存结构,如下图所示:
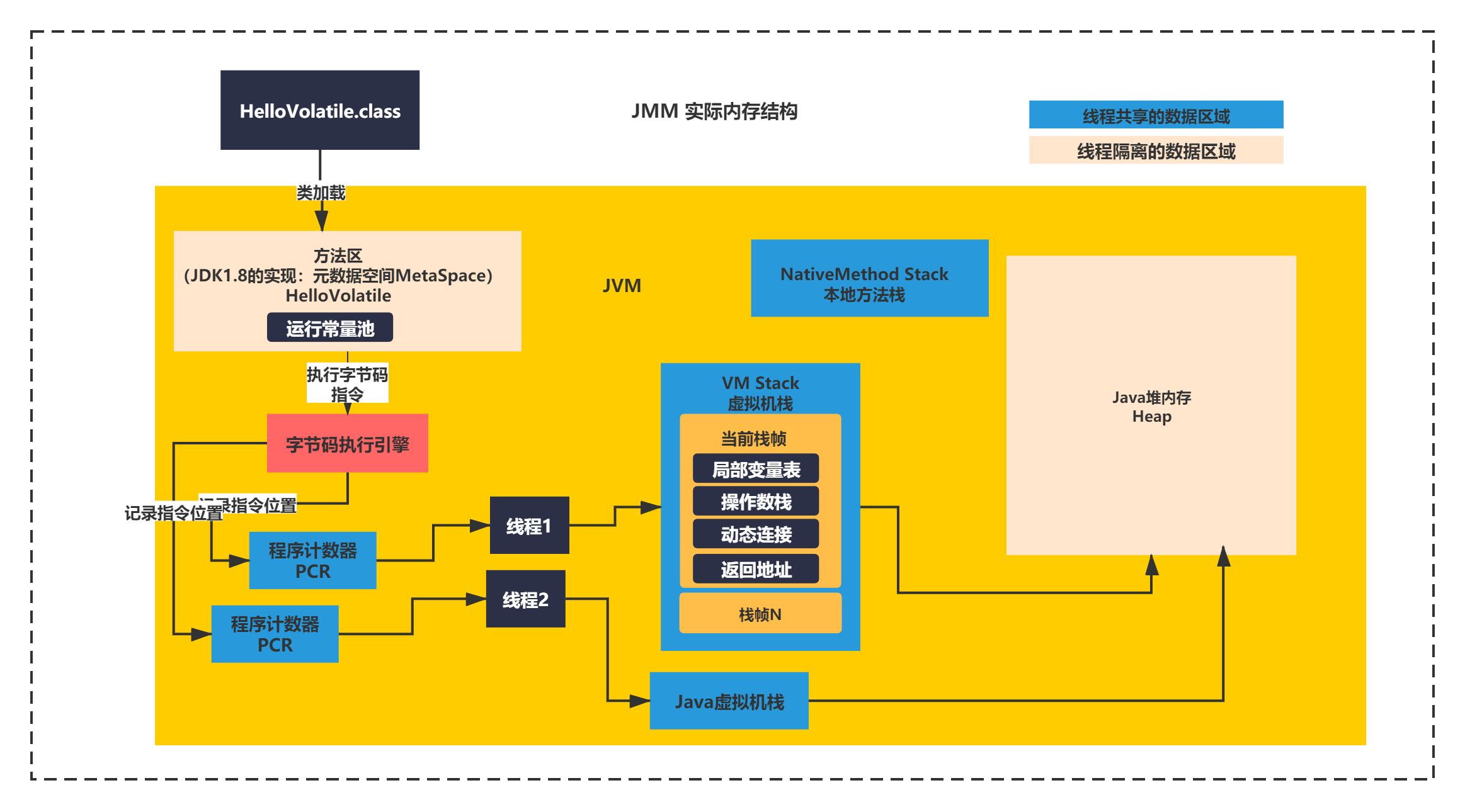
上面的这个图如果了解过JVM的同学,一定很熟悉了,不了解的也没有关系。这里简单介绍下,你就可以了解了:
JVM的内存区域,或者说是运行时数据区,简单地来说分为堆和栈两种区域每个线程共享的区域除了堆内存,还有一个方法区的概念。不同JVM版本的方法区实现不同,JDK1.8方法区的实现叫MetaSpace元数据空间,用于存放加载到JVM内存中的类的基本信息和数据。堆内存就是创建的Java对象一般都会分配到堆内存,Heap区域。这2个公共内存区域可以被所有的线程访问到的。它们具体作用如下:
- 堆(Heap):线程共享。所有的对象实例以及数组都要在堆上分配。回收器主要管理的对象。
- 方法区(Method Area):线程共享。存储类信息、常量、静态变量、即时编译器编译后的代码。
- 方法栈(JVM Stack):线程私有。存储局部变量表、操作栈、动态链接、方法出口,对象指针。
- 本地方法栈(Native Method Stack):线程私有。为虚拟机使用到的Native 方法服务。如Java使用c或者c++编写的接口服务时,代码在此区运行。
- 程序计数器(Program Counter Register):线程私有。有些文章也翻译成PC寄存器(PC Register),同一个东西。它可以看作是当前线程所执行的字节码的行号指示器。指向下一条要执行的指令。
从颜色上可以看出,除了线程共享的内存区域,每个线程有自己的独有内存区域,比如程序计数器、本地方法栈,Java方法虚拟机栈。这个是线程独有的内存区域,不会被其他线程所访问到的。
下面给大家简单介绍下JMM。它逻辑模型如下图所示:
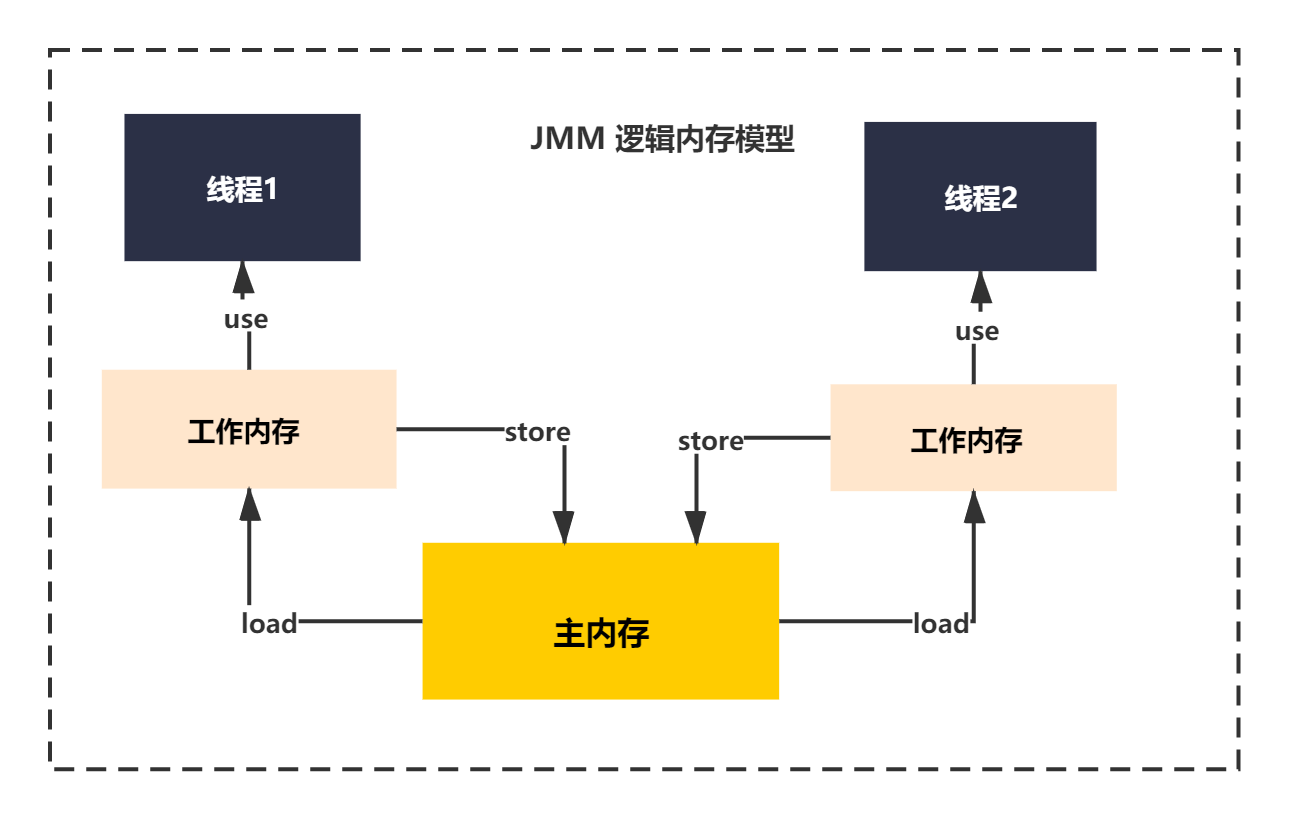
上面的这个图可以看出来比较抽象,这是因为JMM本身就是一种内存模型的抽象,并不是实际存在的结构,而是有一种对应的具体实现和具体结构。
大家都知道很多事情在计算机层面,都会进行一层抽象。比如网络的分层模型等等。而在Java中,准确说是JVM在内存这块的抽象概念是JMM,即Java内存模型。
这个抽象可以对应到具体JVM组件或者具体的硬件组件。对应关系可以理解为下图所示:
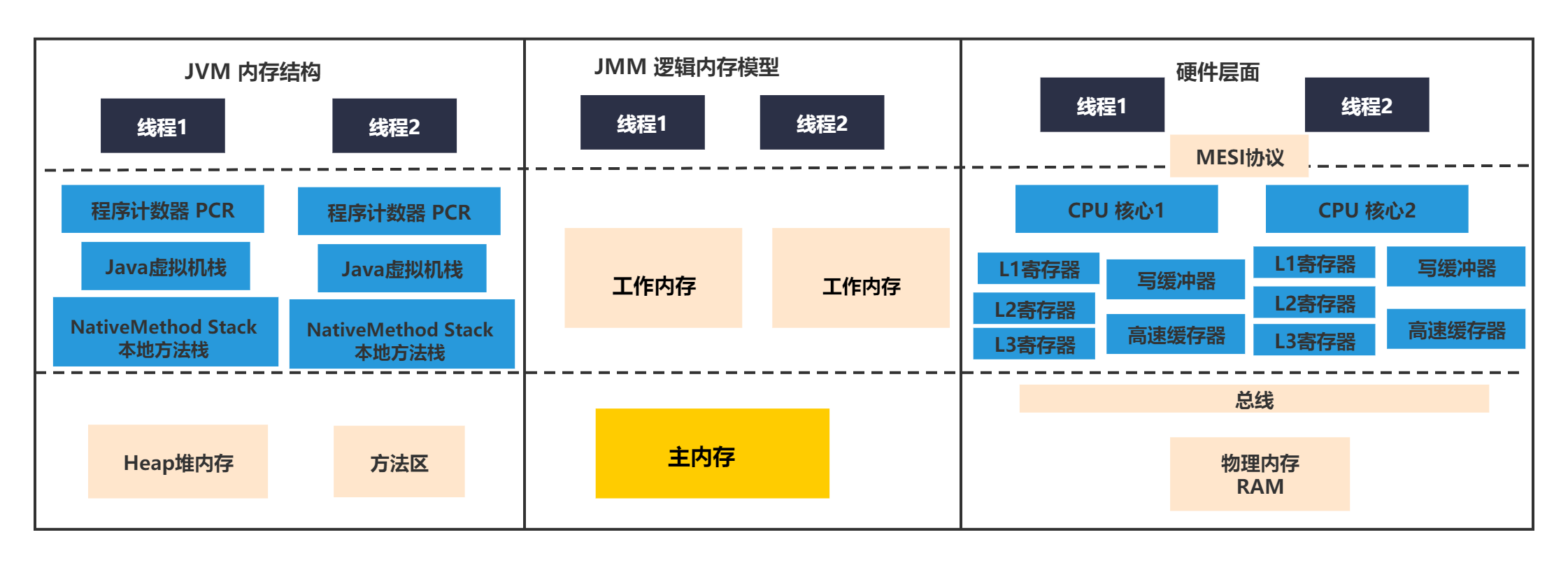
上面的提到的JVM内存结构,实际就是图中左边,表示和JVM的对应关系是,堆和元数据空间可以看做是主内存,Java方法虚拟机栈、程序计数器等可以看做是自己的工作内存。
而对应右边的其实可以对应到CPU的L1-L3的缓存、高速缓存区、写缓冲器等可以看做JMM中每个线程的工作内存,而实际的物理内存这些可以看做是JMM中的主内存,线程共用的区域。
从JMM层面看,volatile怎么保证可见性?
从JMM层面看,volatile怎么保证可见性?
回顾了JVM内存结构和JMM内存模型后,我们来分别从这两个层面分析volatile怎么保证的可见性。
首先是JMM层面。在JMM中,定义一些操作和规则来保证可见性。这里我们深入的讲JMM的知识,只是讲下我们会用到的知识。
首先说下操作,JMM规定了8中原子性操作,用来描述主内存和工作存在的操作动作和操作原则。
JMM的指令
-
lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
-
unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
-
read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
-
load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
-
use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
-
assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
-
store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
-
write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
JMM的指令使用规则
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
上面的规则看上去很多,其实简单的来说,可以总结如下几句话:
必须按这个执行,不允许缺失或乱序 read-->load-->use 、assign-->store-->write; 一个个变量的lock操作,在同一时间内只允许一个线程重复执行多次,并且只有执行相同次数的unlock该变量才能被释放;释放锁unlock之前将最新数据写入主内存,进入锁lock之前将最新数据读入工作内存。
注意这8个操作,实际在CPU和JVM实现的指令层面并不完全对应,后面我们分析到JVM指令的时候会看到。他们这些。
JMM内存模型解释Hello Volatile如下图所示:
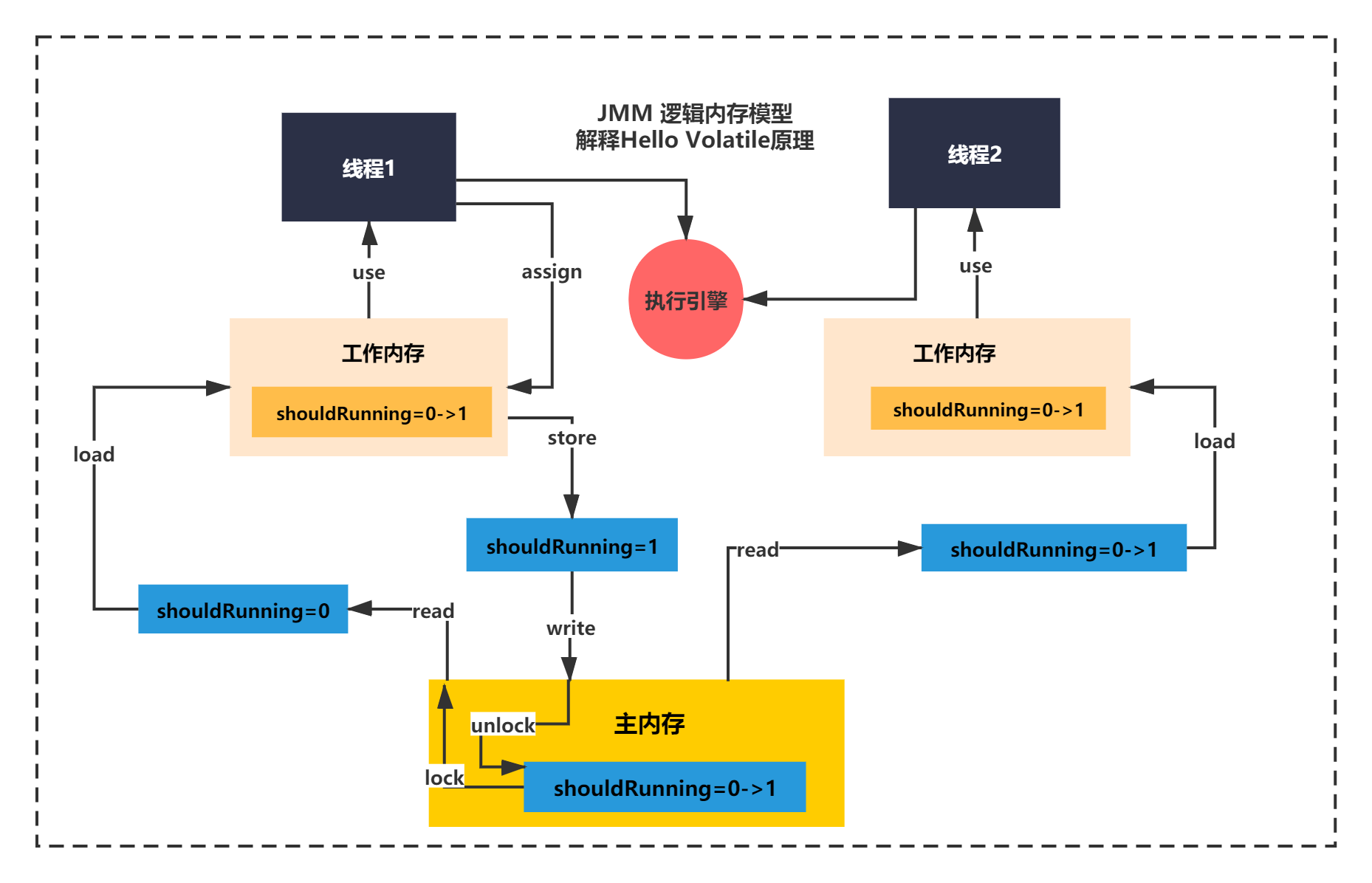
通过JMM的一些操作和原则,使用volatile就能保证不同线程的工作内存发送读写时候的变量可见性。
volatile保证可见性的原理,还是之前总结的一句话:写入主内存数据时,刷新主内存值之后,强制过期其他线程的工作内存,底层是因为lock、unlock操作的原则导致的,其他线程读取变量的时候必须重新加载主内存的最新数据,从而保证了可见性。
好了,到这里你应该了解了volatile的基本作用和可见性的原理,了解了JMM和JVM和volatile之间的关系。
下一节我们继续深入研究下,在JVM指令层面和C++代码层面,如何通过内存屏障、CPU的lock前缀指令,保证可见性和有序性的。
本文由博客群发一文多发等运营工具平台 OpenWrite 发布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号