JavaScrip 常用知识点总结
JavaScript 常见知识总结
- JavaScript 常见知识总结
- 1. 原始值和引用值类型及差别
- 2. 判断数据类型的常用方法
- 3. 类数组和数组的区别与转换
- 4. 数组常见的 API
- 5. bind, call, apply 的区别
- 6. new 的原理
- 7. this 的全面解析
- 8. 闭包及其作用
- 9. 原型与原型链
- 10. 继承
- 11. 对象的深拷贝与浅拷贝
- 12. 防抖与节流
- 13. 作用域和作用域链、执行期上下文
- 14. DOM 常见操作方法
- 15. 作用域、执行上下文、词法环境
- 16. 相等性判断
- 17. JavaScript 中的内存管理
- 18. 手写发布订阅模式 EventEmitter
- 19. 获取 url 参数
- 20. 手写 Promise
- 21. JS 事件循环
- 22. 对于函数式编程的理解
- 23. 性能优化
- 24. 词法作用域和动态作用域
- 25. 浮点数精度
- 26. Virtual DOM 的优势在哪里
- 27 类型转换
- 28. 比较箭头函数与普通函数
- 29. 模块加载方案
- 30. “use strict” 严格模式
- 31. WeakMap & WeakSet
- 32. JS V8 引擎下的数组底层实现
- 33. for in 与 for of 的区别
- 34. React 中为什么不建议采用数组遍历的 index 作为 key
- 35. javascript:void(0) 的含义
1. 原始值和引用值类型及差别
-
原始值 也叫基本类型,例如
null, undefined, string, number, boolean,可以通过typeof判断某数据是何简单数据类型,但是typeof null为objectconsole.log(typeof 10); // number console.log(typeof 'hello'); // string console.log(typeof false); // boolean console.log(typeof null); // object console.log(typeof undefined); // undefined typeof Symbol.for('dd'); // symbol -
引用值 如
Object, Function, Date, Array, RegExp// 引用值 var o = { name: "zxh", age: 24, }; console.log(o.name); // zxh -
区别
- 原始值存储在栈中,引用值存储在堆中
- 原始值是以值得拷贝进行赋值,值是不可变的;引用值是以引用的拷贝方式进行赋值,只是可变的
- 原始值的比较是值的比较,引用值得比较是引用的比较(比较引用的是否为同一对象)
2. 判断数据类型的常用方法
-
typeoftypeof进行类型判断的返回值有:undefined, string, number, boolean, object, symbol, function-
typeof null返回object这里历史原因在于
typeof判断数据类型是,是根据机器码低位来判断的,而null的机器码标识全为 0,而对象的机器码低位标识为000,因此,typeof null = Object
-
typeof 正则返回object
console.log(typeof 1); // number console.log(typeof true); // boolean console.log(typeof 'mc'); // string console.log(typeof Symbol) // function console.log(typeof Symbol('foo')) // symbol console.log(typeof function(){}); // function console.log(typeof console.log()); // undefined console.log(typeof []); // object console.log(typeof {}); // object console.log(typeof null); // object console.log(typeof undefined); // undefined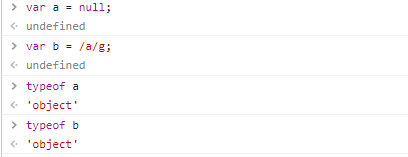
优点:能够快速区分基本数据类型
缺点:不能将Object、Array 和 Null 区分,都返回object
-
-
instanceof用于检测某个对象的原型链__proto__上是否存在另一个对象的prototypefunction instance(target, cons) { return cons.prototype.isPrototypeOf(target); }console.log(1 instanceof Number); // false console.log(true instanceof Boolean); // false console.log('str' instanceof String); // false console.log([] instanceof Array); // true console.log(function(){} instanceof Function); // true console.log({} instanceof Object); // true优点:能够区分Array、Object和Function,适合用于判断自定义的类实例对象
缺点:Number,Boolean,String 基本数据类型不能判断
-
Object.prototype.toString.call()在任何值上调用 Object 原生的toString()方法,返回一个[object NativeConstructorName]格式的字符串。每个类在内部都有一个 [[Class]] 属性,这个属性中就指定了上述字符串中的构造函数名。但是它 不能检测非原生构造函数的构造函数名。var toString = Object.prototype.toString; console.log(toString.call(1)); //[object Number] console.log(toString.call(true)); //[object Boolean] console.log(toString.call('mc')); //[object String] console.log(toString.call([])); //[object Array] console.log(toString.call({})); //[object Object] console.log(toString.call(function(){})); //[object Function] console.log(toString.call(undefined)); //[object Undefined] console.log(toString.call(null)); //[object Null]优点:精准判断数据类型
缺点:写法繁琐不容易记,推荐进行封装后使用
function type(obj) { return Object.prototype.toString.call(obj).split("").slice(8, -1).join("") } -
constructor指向该对象实例的
__proto__.constructorconstructor不能判断undefined和null,并且使用它是不安全的,因为contructor的指向是可以改变的
3. 类数组和数组的区别与转换
-
类数组 指的是可以 通过索引访问元素 并且 拥有
length属性的对象,如 arguments 对象、NodeList 对象等例如:
var arrLike = { 0: "my", 1: "name", 2: "is", 3: "zxh", length: 4, }; // 对应的数组对象为 var arr = ["my", "name", "is", "zxh"]; -
区别 类数组对象虽然可以通过数组下标取值,但是类数组对象不能调用数组原型上的方法
-
转换
Array.prototype.slice.call(arrLike, 0)Array.prototype.splice.call(arrLike, 0)Array.from(arrLike)var newArr = [... arrLike]
-
在类数组上使用数组的方法
- 通过
Function.callArray.prototype.push.call(arrLike, “hello”)
- 通过
Function.applyArray.prototype.push.apple(arrLike, [“hello”])
- 通过
-
arguments对象 函数体中定义了 Arguments 对象,包含函数的参数和length, callee属性callee属性指向函数自身,可以通过它来调用自身函数
4. 数组常见的 API
-
改变数组本身的方法
-
fill(value, start, end)用一个固定值填充一个数组中从起始索引到终止索引内的全部元素 -
pop从数组中删除最后一个元素,并返回该元素的值 -
push将一个或多个元素添加到数组的末尾,并返回该数组的新长度 -
reverse将数组中元素的位置颠倒,并返回该数组 -
shift从数组中删除第一个元素,并返回该元素的值 -
unshift将一个或多个元素添加到数组的头部,并返回该数组的新长度,是将整体插入到数组头部例如:
let arr = [] arr.unshift(1, 2, 3, 4) arr // [1, 2, 3, 4]
-
sort([compareFunction])对数组元素进行原地排序并返回此数组,如果省略compareFunction,元素按照转换为的字符串的各个字符的Unicode位点进行排序。let arr = ['你好', 'a', "11"] arr.forEach(a => console.log(a.charCodeAt())) // 20320 97 49 arr.sort() // ['11', 'a', '你好']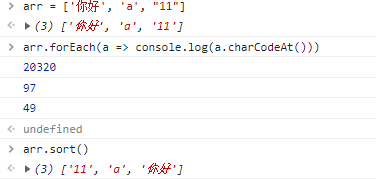
-
splice通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容
-
-
不改变自身的方法
concat(value1[, value2[, ...[, valueN]]])用于合并两个或多个数组。此方法不会更改现有数组,而是返回一个新数组includes(valueToFind, index)判断一个数组是否包含一个指定的值,如果包含则返回true,否则返回falsejoin将一个数组的所有元素连接成一个字符串并返回这个字符串sliceindexOf返回在数组中可以找到一个给定元素的第一个索引,如果不存在,则返回-1lastIndexOfflat([depth])按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回at(index)返回给定下标的数组元素,可以使用负下标
-
遍历方法
-
every(callback(element[, index[, array]])[, thisArg])如果回调函数的每一次返回都为 truthy 值,返回true,否则返回false -
some测试数组中是不是至少有一个元素通过了被提供的函数测试,返回的是一个Boolean类型的值。let i = 1; let arr = Array.from(Array(10), () => i++) // [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] arr.some(v=> !(v%2) && !(v%5)) // true 同时为2和5的倍数 -
map返回一个新数组,其结果是该数组中的每个元素是调用一次提供的函数后的返回值 -
reduce对数组中的每个元素执行一个由您提供的reducer函数(升序执行),将其结果汇总为单个返回值 -
forEach对数组的每个元素执行一次给定的函数,不会改变原有值 -
filter创建一个新数组, 其包含通过所提供函数实现的测试的所有元素let i = 1; let arr = Array.from(Array(10), () => i++) // [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] arr.filter(v => v&1) // [1, 3, 5, 7, 9] arr.filter(v => !(v&1)) // [2, 4, 6, 8, 10] -
find返回数组中满足提供的测试函数的第一个元素的值。否则返回undefined -
findIndex方法返回数组中满足提供的测试函数的第一个元素的索引。若没有找到对应元素则返回-1
-
-
Array 方法
-
from方法对一个类似数组或可迭代对象创建一个新的,浅拷贝的数组实例-
arrayLike想要转换成数组的伪数组对象或可迭代对象。
-
mapFn可选如果指定了该参数,新数组中的每个元素会执行该回调函数。
-
thisArg可选可选参数,执行回调函数
mapFn时this对象。
例如创建一个二维数组,可以使用
function createMultiDimentionArray(N = 4, M = 5, initial = 1) { let arr = Array.from(Array(N), () => new Array(M).fill(initial)); return arr; } let N = 5, M = 6, initial = 2; console.log(createMultiDimentionArray(N, M, initial));
-
-
of方法创建一个具有可变数量参数的新数组实例,而不考虑参数的数量或类型-
elementN
任意个参数,将按顺序成为返回数组中的元素。
-
-
isArray用于确定传递的值是一个Array
-
-
数组常用技巧
13-useful-javascript-array-tips-and-tricks-you-should-know
-
删除重复元素 使用 Set
-
替换具体下标的值 使用
splice -
Map array without .map() 使用
Array.from的第二个参数,为 mapfn 遍历函数var friends = [ { name: ‘John’, age: 22 }, { name: ‘Peter’, age: 23 }, { name: ‘Mark’, age: 24 }, { name: ‘Maria’, age: 22 }, { name: ‘Monica’, age: 21 }, { name: ‘Martha’, age: 19 }, ] var friendsNames = Array.from(friends, ({name}) => name); console.log(friendsNames); // returns [“John”, “Peter”, “Mark”, “Maria”, “Monica”, “Martha”] -
清空数组 之间将数组的
length置为 0 -
将数组转换为对象 使用
...操作符let colors = Array.from("rgba") // ['r', 'g', 'b', 'a'] let colorsObj = {...colors} // {0: 'r', 1: 'g', 2: 'b', 3: 'a'} -
填充数组 使用
fill -
合并数组 使用
...操作符var fruits = [“apple”, “banana”, “orange”]; var meat = [“poultry”, “beef”, “fish”]; var vegetables = [“potato”, “tomato”, “cucumber”]; var food = […fruits, …meat, …vegetables]; console.log(food); // [“apple”, “banana”, “orange”, “poultry”, “beef”, “fish”, “potato”, “tomato”, “cucumber”] -
两个数组的交集
- 并集
- 差集
// 8. 两个数组的交集 function intersection(arr1 = [], arr2 = []) { return [...new Set(arr1)].filter((item) => arr2.includes(item)); } console.log(intersection([1, 2, 3, 4, 5], [2, 3, 4, 5, 6])); // 8.5 两个数组的并集 function union(arr1 = [], arr2 = []) { return [...new Set([...arr1, ...arr2])]; } console.log(union([1, 2, 3, 4, 5], [2, 3, 4, 5, 6])); // 8.6 两个数组的差集 function difference(arr1 = [], arr2 = []) { return [...new Set(arr1)].filter((item) => !arr2.includes(item)); } console.log(difference([1, 2, 3, 4, 5], [2, 3, 4, 5, 6])) -
删除数组中的 falsy 值
function compact(arr = []) { return arr.filter((item) => item); // 或者 return arr.filter(Boolean); } console.log(compact([0, 1, false, 2, "", 3, "a", "e" * 23, NaN, "s", 34])); // [ 1, 2, 3, 'a', 's', 34 ] -
从数组中获取随机值
function sample(arr = []) { return arr[Math.floor(Math.random() * arr.length)]; } -
逆转数组
-
.lastIndexOf()
-
数组元素和
-
判断是否为数组
Array.isArray([])Object.prototype.toString.call([]).slice(8,-1)

-
判断对象是否为空
function isEmpty(obj = {}) { return Object.keys(obj).length === 0; } -
复制克隆数组 使用
slice() -
随机打乱数组
function shuffle(arr = []) { let _arr = [...arr]; for (let i = 0; i < _arr.length; i++) { let j = Math.floor(Math.random() * (i + 1)); [_arr[i], _arr[j]] = [_arr[j], _arr[i]]; } return _arr; } let arr = Array.from({ length: 10 }, (v, i) => i); console.log(shuffle(arr)); -
将字符串数组转换为Number数组,或者将 Number 数组转换为 string 数组
let original = ["1", "2", "3", "4", "5"]; let arrayOfNumbers = original.map(Number); console.log(arrayOfNumbers); // [1, 2, 3, 4, 5] let numbers = [1, 2, 3, 4, 5]; let arrayOfStrings = numbers.map(String); console.log(arrayOfStrings); // ['1', '2', '3', '4', '5']
-
5. bind, call, apply 的区别
-
call和apply都是为了改变某个函数运行时的上下文(context)而存在的,换句话说,就是为了改变函数体内部this的指向。 -
对于
apply、call二者而言,作用完全一样,只是接受参数的方式不太一样 call 一个参数参数的传递,apply 传递的是参数数组func.call(this, arg1, arg2); func.apply(this, [arg1, arg2])例如 定义一个
log方法,让它可以代理console.logfunction log(){ console.log.apply(console, arguments); // 参数不确定 };接下来的要求是给每一个
log消息添加一个"(app)"的前辍,比如:log("hello world"); //(app)hello worldfunction log(){ var args = Array.prototype.slice.call(arguments); // 类数组转换为标准数组 args.unshift('(app)'); console.log.apply(console, args); }; -
区别
-
当我们使用一个函数需要改变
this指向的时候才会用到call,apply,bind -
如果你要传递的参数不多,则可以使用
fn.call(thisObj, arg1, arg2 ...) -
如果你要传递的参数很多,则可以用数组将参数整理好调用
fn.apply(thisObj, [arg1, arg2 ...]) -
如果你想生成一个新的函数长期绑定某个函数给某个对象使用,则可以使用
const newFn = fn.bind(thisObj); newFn(arg1, arg2...) -
call,apply,bind 不传参数自动绑定在 window
-
-
实现
bindbind并不是立即执行,而是返回一个性函数,且此函数的this无法再次修改
bind作用:-
可以修改函数
this执行 -
bind返回一个绑定this的新函数boundFunction -
支持函数柯里化,返回
bound函数可以传递部分参数所谓函数柯里化其实就是在函数调用时只传递一部分参数进行调用,函数会返回一个新函数去处理剩下的参数
-
boundFunction的this无法再次修改,使用call, apply也不行
// bind 函数实现 Function.prototype.myBind = function (context) { // 1. 判断调用对象是否为函数 if (typeof this !== "function") { throw new TypeError("Error"); } // 2. 获取参数 类数组转换 var args = [...arguments].slice(1), fn = this; // 3. 返回绑定的函数 return function Fn() { // 根据调用方式,传入不同绑定值 return fn.apply( this instanceof Fn ? this : context, args.concat(...arguments) ); }; }; -
实现
call// call 函数实现 ...args Function.prototype.myCall = function (context) { // 1. 判断调用对象 if (typeof this !== "function") { console.error("type error"); } // 2. 获取参数 arguments 为类数组对象 需要使用 [...arguments] 转换为数组 let args = [...arguments].slice(1), result = null; // 3. 判断 context 是否传入,未传入则设置为 window (默认绑定) context = context || window; // 4. 将调用函数设置为对象的方法 context.fn = this; // 5. 调用函数 result = context.fn(...args); // 6. 将属性删除 delete context.fn; // 7. 返回函数执行结果 return result; }; -
实现
apply// apply 函数实现 [] Function.prototype.myApply = function (context) { // 1. 判断调用对象是否为函数 if (typeof this !== "function") { throw new TypeError("Error"); } let result = null; // 2. 判断 context 是否存在吗,如果未传入则为 window context = context || window; // 3. 将函数设为对象的方法 context.fn = this; // 4. 调用方法 if (arguments[1]) { result = context.fn(...[arguments[1]]); } else { result = context.fn(); } // 5. 将属性删除 delete context.fn; // 6. f return result; };
6. new 的原理
new 大概会执行以下四个步骤:
- 创建一个空对象
- 将空对象的原型链连接到另一个对象
- 执行构造函数中的代码并绑定 this 到这个对象
- 如函数没有返回值,则返回该对象
function _new() {
// 1. 创建一个空对象
let obj = {};
// 2. 将空对象的原型链链接到传入的对象
let [Con, ...args] = arguments;
obj.__proto__ = Con.prototype;
// 3. 执行函数并绑定 this
let res = Con.apply(obj, args);
// 4. 如果函数有返回值并且为 object,则返回函数的返回值,否则返回 obj
return res instanceof Object ? res : obj;
}
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.getName = function () {
return this.name;
};
let p = _new(Person, "sillywa", 23);
7. this 的全面解析
JavaScript 中的 this 实在运行时进行绑定的,并不是再编写时,他的上下文取决于函数调用的各种条件。this 的绑定和函数生命的位置没有任何关系,只取决于函数的调用方式。
-
函数是否在 new 中调用(new 绑定)?如果是的话,this 绑定的是新创建的对象。
function foo(a) { this.a = a; } var bar = new foo(2); console.log(bar.a); // 2 -
函数是否通过 call、apply 显示绑定或者硬绑定?如果是的话,this 绑定的是指定对象。
call, apply默认绑定为globafunction foo() { console.log(this.a); } var obj = { a:2 }; var a = 3 foo.call(obj); // 2 foo.call(); // 3 -
函数是否在某个上下文中调用(隐式绑定)?如果是的话,this 绑定的是那个上下文对象。
function foo() { console.log(this.a); } var obj = { a: 2, foo: foo }; obj.foo(); // 2 -
如果都不是,使用默认绑定。严格模式下绑定到 undefined,否则绑定到全局对象 。
// 隐式丢失 function foo() { console.log(this.a); } var obj = { a: 2, foo: foo }; var bar = obj.foo; // 函数别名! var a = "oops,global"; bar(); // "oops,global" -
箭头函数不使用 this 的四种标准规则,而是根据外层作用域来决定 this
function foo() { return a => { // this 来自 foo() console.log(this.a); } } var obj1 = { a: 2 }; var obj2 = { a: 3 }; var bar = foo.call(obj1); bar.call(obj2); // 2var obj2 = { name: "obj2", innerObj: { name: "innerObj", getName: () => { console.log(this, this.name); }, }, }; console.log(obj2.innerObj.getName());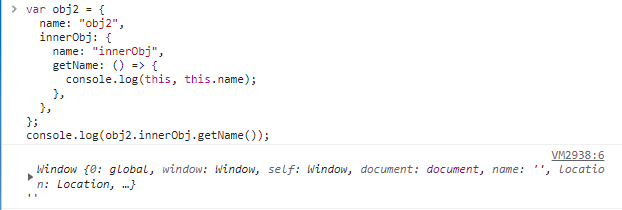
function Person(name) { this.name = name; this.obj2 = { name: "obj2", innerObj: { name: "innerObj", getName: () => { console.log(this, this.name); }, }, }; } let p1 = new Person("p1"); let p2 = new Person("p2"); console.log(p1.obj2.innerObj.getName()); console.log(p2.obj2.innerObj.getName());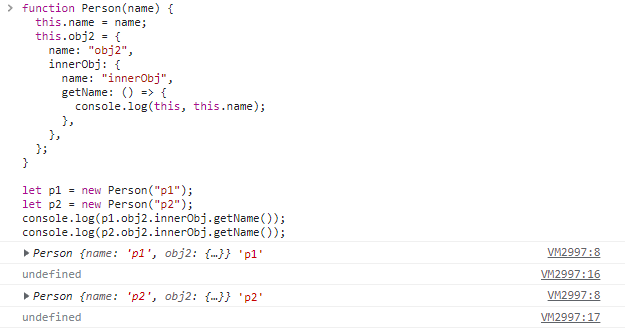
8. 闭包及其作用
一个函数有权访问另一个函数作用域中的变量,就形成闭包
ECMAScript中,闭包指的是:
-
从理论角度:所有的函数。因为它们都在创建的时候就将上层上下文的数据保存起来了。哪怕是简单的全局变量也是如此,因为函数中访问全局变量就相当于是在访问自由变量,这个时候使用最外层的作用域。
-
从实践角度:以下函数才算是闭包:
- 即使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
- 在代码中引用了自由变量
在这里再补充一个《JavaScript权威指南》英文原版对闭包的定义:
This combination of a function object and a scope (a set of variable bindings) in which the function’s variables are resolved is called a closure in the computer science literature.
闭包在计算机科学中也只是一个普通的概念,大家不要去想得太复杂。
闭包表现如下:
- 第一,闭包是一个函数,而且存在于另一个函数当中
- 第二,闭包可以访问到父级函数的变量,且该变量不会销毁
function fib() {
let n1 = 1,
n2 = 1;
return function () {
let result = n1 + n2;
n1 = n2;
n2 = result;
return result;
};
}
const f = fib();
f(); // 2
f(); // 3
f(); // 5
f(); // 8
f(); // 13
闭包的作用
- 隐藏变量,避免全局污染
- 以读取函数内部的变量
闭包缺点
- 导致变量不会被垃圾回收机制回收,造成内存消耗
- 不恰当的使用闭包可能会造成内存泄漏的问题
闭包应用
-
模仿块级作用域
for (var i = 0; i < 5; ++i) { (function (j) { setTimeout(() => { console.log(j); }, j * 1000); })(i); }上面可以使用闭包能使下面的代码按照我们预期的进行执行(每隔1s打印 0,1,2,3,4)
-
私有变量
function MyObject() { // 私有变量和私有函数 var privateVariable = 10; function privateFunction() { return false; } // 特权方法 this.publicMethod = function () { privateVariable++; return privateFunction; }; } -
静态私有变量
(function () { var name = ""; // Person = function (value) { name = value; }; Person.prototype.getName = function () { return name; }; Person.prototype.setName = function (value) { name = value; }; })(); kl;' i ' var person1 = new Person("xiaoming"); console.log(person1.getName()); // xiaoming person1.setName("xiaohong"); console.log(person1.getName()); // xiaohong var person2 = new Person("luckyStar"); console.log(person1.getName()); // luckyStar console.log(person2.getName()); // luckyStar上面代码通过一个匿名函数实现块级作用域,在块级作用域中 变量
name只能在该作用域中访问,同样的通过闭包(作用域链)的方式实现getName和setName来访问name, 而getName和setName又是原型对象的方法,所以它们成了Person实例的共享方法。
这种模式下,name就变成了一个静态的、由所有实例共享的属性。在一个实例上调用setName()会影响所有的实例。 -
模块模式
var singleton = function () { var privateVarible = 10; function privateFunction() { return false; } return { publicProperty: true, publicMethod: function () { privateVarible++; return privateFunction(); }, }; };模块模式使用了一个返回对象的匿名函数。在这个匿名函数内部,首先定义了私有变量和函数
9. 原型与原型链
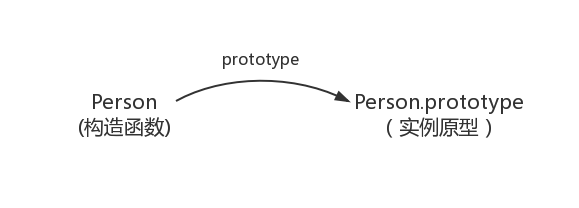
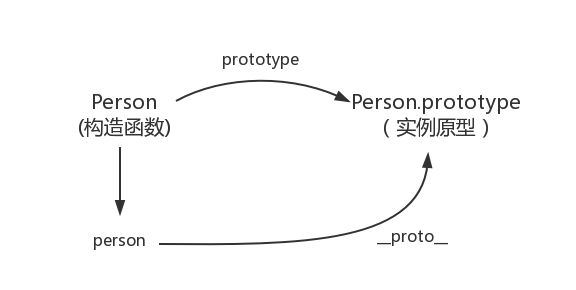
当访问一个对象的某个属性时,会先在这个对象本身属性上查找,如果没有找到,则会起它的 _proto_ 隐式原型上查找,即它的 构造函数 的prototype,如果还没找到,就会在构造函数的prototype的_proto_中查找,这样一层一层就会形成链式结构,称之为 原型链。
无论什么时候,只要创建了一个函数,就会根据为该 函数创建一个 prototype 属性,这个属性 指向函数的原型对象。在默认情况下,所有原型对象都会获得一个 constructor,该属性是一个指向 prototype 属性所在函数的指针。
原型链规定了对象如何查找属性,对于一个对象来说,如果它本身没有某个属性,则会沿着原型链一直向上查找,知道找到属性或者查找完整个原型链。
原型链是实现继承的主要方法,其 基本思想是利用原型链让一个引用类型继承另一个引用类型的属性和方法。
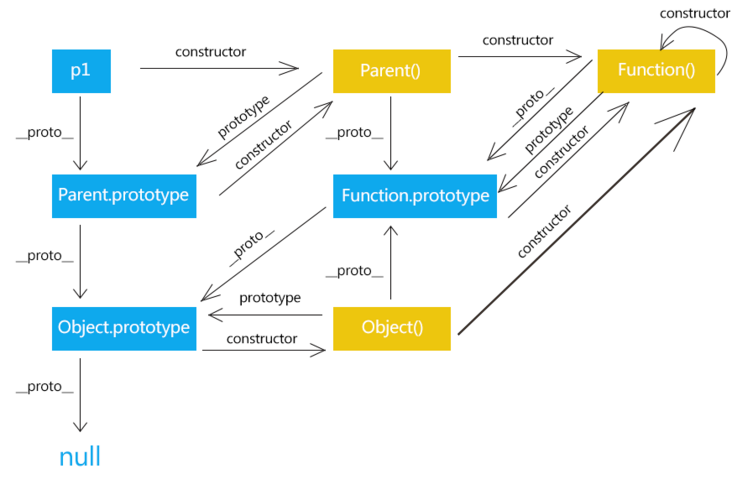
搞清楚这三个属性,__proto__、prototype、 constructor。
__proto__、constructor属性是对象除了null所独有的,这个属性会指向该对象的原型prototype属性是函数独有的- 函数同样也有属性
__proto__、constructor
-
prototype是函数独有的属性,从图中可以看到它从一个函数指向另一个对象,代表这个对象是这个函数的原型对象,这个对象也是当前函数所创建的实例的原型对象。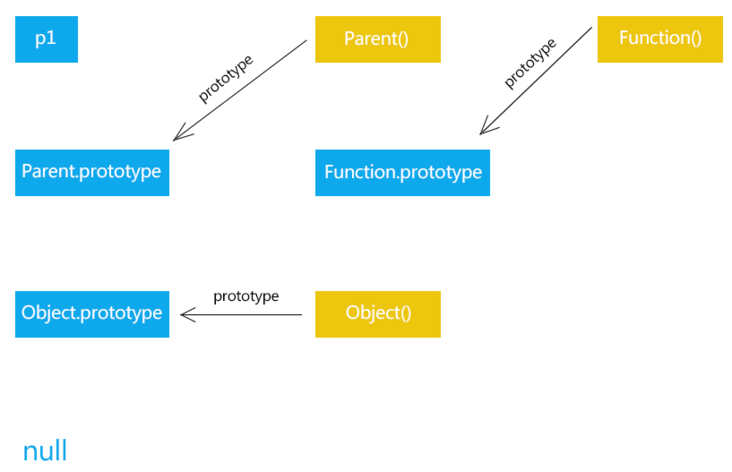
-
__proto__属性是对象(包括函数)独有的。从图中可以看到__proto__属性是从一个对象指向另一个对象,即从一个对象指向该对象的原型对象(也可以理解为父对象)。显然它的含义就是告诉我们一个对象的原型对象是谁绝大部分浏览器都支持这个非标准的方法访问原型,然而它并不存在于 Person.prototype 中,实际上,它是来自于 Object.prototype ,与其说是一个属性,不如说是一个 getter/setter,当使用 obj.proto 时,可以理解成返回了 Object.getPrototypeOf(obj)。

-
constructor是对象才有的属性,从图中看到它是从一个对象指向一个函数的。指向的函数就是该对象的构造函数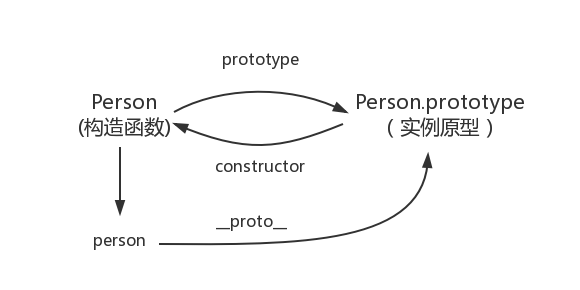
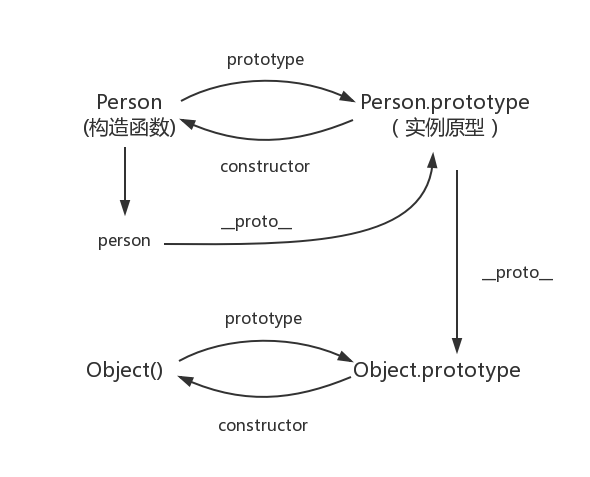
有意思的点:
Function.__proto__ === Function.prototype为trueFunction instanceof Object和Object instanceof Function都为true
10. 继承
关于继承,“每一个对象都会从原型‘继承’属性”,实际上,继承是一个十分具有迷惑性的说法,引用《你不知道的JavaScript》中的话,就是:
继承意味着复制操作,然而 JavaScript 默认并不会复制对象的属性,相反,JavaScript 只是在两个对象之间创建一个关联,这样,一个对象就可以通过委托访问另一个对象的属性和函数,所以与其叫继承,委托 的说法反而更准确些。****
-
原型继承
function SuperType() { this.name = "super"; } function SubType() {} // 利用原型链实现继承 SubType.prototype = new SuperType(); var instance1 = new SubType(); console.log(instance1.name); // super问题在于:
- 包含引用类型值的原型属性会被所有实例共享,在通过原型来实现继承时,原型实际上也会变成另一个类型的实例。
- 在创建子类类型的实例时,不能向超类类型的构造函数中传递参数。
-
盗用构造函数继承
function SuperType(age, name) { this.colors = ["blue", "red"]; this.age = age; this.name = name; } function SubType() { SuperType.call(this, ...arguments); } var instance1 = new SubType(23, "sillywa"); instance1.colors.push("yellow"); console.log(instance1.colors, instance1.name); var instance2 = new SubType(12, "xinda"); console.log(instance2.colors, instance2.name);缺点在于方法都只能在构造函数中定义,没有办法实现方法的复用
-
组合继承
组合继承结合了原型继承和借用构造函数继承的优点,其 背后的思想是,使用原型链实现对原型方法的继承,使用构造函数实现对实例属性的继承。
SuperType.prototype.sayName = function () { return this.name; }; function SubType(name, age) { // 通过 构造函数继承属性 SuperType.call(this, name); this.age = age; } // 通过原型继承方法 SubType.prototype = new SuperType(); // ** 重写了 SubType 的 prototype 属性,因此其 constructor 也被重写了,需要手动修正 ** SubType.prototype.constructor = SubType; // 定义子类自己的方法 SubType.prototype.sayAge = function () { return this.age; };组合继承最大的问题是,无论什么情况下都会调用两次超类的构造函数。
-
原型式继承
借助原型可以通过已有的对象创建新对象,同时还不必因此创建自定义类型
function create(o) { function F() {} F.prototype = o; return new F(); } // Object.create var person = { name: "sillywa", firends: ["Johe"], }; var person1 = create(person); person1.name = "coder"; person1.firends.push("Kobe"); var person2 = create(person); person2.firends.push("Cury"); console.log(person2.firends); // ["Johe", "Kobe", "Cury"] -
寄生式继承
寄生式继承的思路与继承构造函数和工厂模式类似,即创建一个仅用于封装继承过程的函数,该函数在内部以某种方式来增强对象,最后再像真正地是它做了所有工作一样返回对象。
function createAnother(original) { var clone = Object.create(original); clone.sayHi = function () { console.log("Hi"); }; return clone; } -
组合寄生式继承
function SuperType(name) { this.name = name; this.colors = []; } SuperType.prototype.sayName = function () { return this.name; }; function SubType(name, age) { // 第一次调用父类的构造函数 SuperType.call(this, name); this.age = age; } // 关键代码 SubType.prototype = Object.create(SuperType.prototype); SubType.prototype.constructor = SubType; SubType.prototype.sayAge = function () { return this.age; };
11. 对象的深拷贝与浅拷贝
11.1 浅拷贝的实现方法
// 1. 浅拷贝的实现
(function () {
// 遍历赋值
// for in
function clone1(obj) {
var cloneObj = {};
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
cloneObj[key] = obj[key];
}
}
return cloneObj;
}
// Object.keys()
function clone2(obj) {
var cloneObj = {};
for (const key of Object.keys(obj)) {
cloneObj[key] = obj[key];
}
return cloneObj;
}
// Object.entries
function clone3(obj) {
var cloneObj = {};
for (const [key, value] of Object.entries(obj)) {
cloneObj[key] = value;
}
return cloneObj;
}
// 2. Object.assign
function clone4(obj) {
return Object.assign(obj, {});
}
})();
11.2 深拷贝的实现方法
-
完全准确的深拷贝
Object.getOwnPropertyDescriptors
const deepClone = (obj) => Object.create( Object.getPrototypeOf(obj), Object.getOwnPropertyDescriptors(obj) ); -
使用
JSON.parse(JSON.stringfy(obj))function deepClone(obj) { return JSON.parse(JSON.stringify(obj)); } let obj = { name: "zxh", color: ["cyan", "light"], reg: /a/g, say: function () { console.log("fun say"); }, }; let obj2 = deepClone(obj);存在问题:遇到函数,undefined,Symbol,Date对象时会自动忽略,遇到正则时会返回空对象

-
使用递归
// 1. JSON.strinfy() 与 JOSN.parse() // 存在问题:遇到函数,undefined, // Symbol,Date对象时会自动忽略, // 遇到正则时会返回空对象 function deepClone(obj) { return JSON.parse(JSON.stringify(obj)); } // 2. 递归 // for in function deepClone1(obj) { // undefined 或者为 对象的时候 if (!obj || typeof obj !== "object") { return obj; } // 为正则表达式的时候 if (obj instanceof RegExp) { return new RegExp(obj); } // var cloneObj = new obj.constructor(); var cloneObj = {} for (const key in obj) { if (Object.hasOwnProperty.call(obj, key)) { cloneObj[key] = arguments.callee(obj[key]); } } return cloneObj; } function deepClone(obj) { if (!obj || typeof obj !== "object") return obj if (obj instanceof RegExp) return new RegExp(obj) // var o = new obj.contructor() var o = {} Object.entries(obj).forEach( ([key, value]) => { o[key]=arguments.callee(value) }) return o } // Object.keys 推荐写法 简洁 function deepClone2(obj) { if (!obj || typeof obj !== "object") { return obj; } if (obj instanceof RegExp) { return new RegExp(obj); } var cloneObj = new obj.constructor(); for (const key of Object.keys(obj)) { cloneObj[key] = arguments.callee(obj[key]); } return cloneObj; } // Object.entries function deepClone3(obj) { if (!obj || typeof obj !== "object") { return obj; } if (obj instanceof RegExp) { return new RegExp(obj); } var cloneObj = new obj.constructor(); for (const [key, value] of Object.entries(obj)) { cloneObj[key] = arguments.callee(value); } return cloneObj; } let obj = { name: "zxh", color: ["cyan", "light"], reg: /a/g, say: function () { console.log("fun say"); }, }; let obj2 = deepClone1(obj);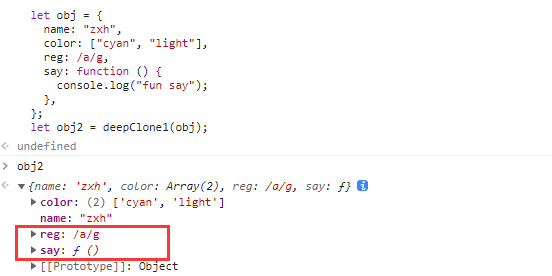
12. 防抖与节流
12.1 防抖
函数在指定时间内只会触发一次,具体实现方法:
- 第一次触发函数的时候,延迟delay时间执行,如果在delay时间段内再次触发该函数,则重新开始计时
- 如果delay时间段内没有触发该函数,则执行该函数
防抖的原理就是:你尽管触发事件,但是我一定在事件触发 n 秒后才执行,如果你在一个事件触发的 n 秒内又触发了这个事件,那我就以新的事件的时间为准,n 秒后才执行,总之,就是要等你触发完事件 n 秒内不再触发事件
function debounce(fn, delay) {
let timer = null;
return function () {
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(() => {
fn.apply(this, arguments);
}, delay);
};
}
function debounce5(func, wait, immediate) {
var timer, result;
var debounced = function () {
var context = this,
args = arguments;
if (timer) clearTimeout(timer);
if (immediate) {
var callNow = !timer;
timer = setTimeout(function () {
timer = null;
}, wait);
if (callNow) result = func.apply(context, args);
} else {
timer = setTimeout(function () {
func.apply(context, args);
}, wait);
}
return result;
};
debounced.cancel = function () {
clearTimeout(timer);
timer = null;
};
return debounced;
}
12.2 节流
节流的原理很简单:
如果你持续触发事件,每隔一段时间,只执行一次事件。
根据首次是否执行以及结束后是否执行,效果有所不同,实现的方式也有所不同。
我们用 leading 代表首次是否执行,trailing 代表结束后是否再执行一次。
关于节流的实现,有两种主流的实现方式,一种是使用时间戳,一种是设置定时器。
防抖的问题是,在短时间内不断触发事件,回调函数永远不会执行。
节流的思想:在短时间内不断触发事件,回调函数只会在指定间隔时间内执行。
// 使用定时器实现
function throttle(fn, delay) {
let timer = null;
return function () {
if (timer) {
return false;
}
timer = setTimeout(() => {
fn.apply(this, arguments);
timer = null;
}, delay);
};
}
// 使用时间戳实现
function throttle1(func, wait) {
var context, args;
var previous = 0;
return function () {
var now = +new Date();
context = this;
args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
};
}
13. 作用域和作用域链、执行期上下文
作用域是一套 规则,用于确定 在何处以及如何查找变量。作用域共有两种主要的工作模式,词法作用域 和动态作用域,大多数编程语言采用词法作用域,JavaScript也是基于词法作用域的。词法作用域意味着作用域是由书写代码时函数声明的位置来决定的。
在JavaScript每个函数有自己的函数作用域,当执行流进入到一个函数的时候,函数的环境就会被推入到一个 环境栈 中。而在函数执行之后,栈将其环境弹出。
当代码在一个环境中执行的时候,会 为该环境创建一个作用域链,保证对执行环境有权访问的所有变量的有序访问。作用域链的最前端始终是当前执行代码所在环境,在变量查找的过程中,会沿着作用域链一层一层向上查找,直到找到变量或者找不到变量。
14. DOM 常见操作方法
14.1 常用的查找方法
-
document.getElementById('id属性值'); 返回拥有指定id的对象的引用
-
document.getElementsByClassName('class属性值'); 返回拥有指定class的对象集合
-
document.getElementsByTagName('标签名'); 返回拥有指定标签名的对象集合
-
document.getElementsByName('name属性值'); 返回拥有指定名称的对象结合
-
document.element.querySelector('CSS选择器'); 仅返回第一个匹配的元素
-
document.element.querySelectorAll('CSS选择器'); 返回所有匹配的元素
-
document.documentElement; 获取页面中的HTML标签
-
document.body; 获取页面中的BODY标签
-
document.all['']; 获取页面中的所有元素节点的对象集合型
14.2 常用的新建节点方法
-
document.createElement('元素名');创建新的元素节点
-
document.createAttribute('属性名');创建新的属性节点
-
document.createTextNode('文本内容');创建新的文本节点
-
document.createComment('注释节点'); 创建新的注释节点
-
document.createDocumentFragment( ); 创建文档片段节点
14.3 常用的添加新节点方法
-
element.setAttribute( attributeName, attributeValue );给元素增加指定属性,并设定属性值
-
element.setAttributeNode( attributeName );给元素增加属性节点
-
如需向 HTML DOM 添加新元素,您必须首先创建该元素(元素节点),然后向一个已存在的元素追加该元素。
15. 作用域、执行上下文、词法环境
15.1 作用域
作用域就是一个 独立的区域,讲得具体点就是在我们的程序中定义变量的一个独立区域,它决定了当前执行代码对变量的访问权限。
在 JavaScript 中有两种作用域:
- 全局作用域
- 局部作用域
如果一个变量在函数外面,或者在代码块外也就是大括号{}外声明,那么就定义了一个 全局作用域,在ES6之前局部作用域只包含了函数作用域,ES6为我们提供的块级作用域,也属于 局部作用域。
function fun() {
//局部(函数)作用域
var innerVariable = "inner"
}
console.log(innerVariable)
// Uncaught ReferenceError: innerVariable is not defined
上面的例子中,变量 innerVariable 是在函数中,也就是在局部作用域下声明的,而在全局作用域没有声明,所以在全局作用域下输出会报错。
也就是说,作用域就是一个 让变量不会向外暴露出去的独立区域。作用域最大的用处就是 隔离变量,不同作用域下同名变量不会有冲突。
ES6 之前 JavaScript 没有块级作用域,只有全局作用域和函数(局部)作用域。块语句({}中间的语句),如 if 和 switch 条件语句或 for 和 while 循环语句,不像函数,它们 不会创建一个新的作用域。
15.1.1 全局作用域
在代码中任何地方都能访问到的对象拥有全局作用域,一般来说以下几种情形拥有全局作用域:
- 最外层函数和在最外层函数外面定义的变量拥有全局作用域
- 所有末定义直接赋值的变量(也称为意外的全局变量),自动声明为拥有全局作用域
- 所有 window 对象的属性拥有全局作用域
一般情况下,window对象的内置属性都拥有全局作用域,例如window.name、window.location、window.document、window.history等等。
全局作用域有个弊端:如果我们写了很多行 JS 代码,变量定义都没有用函数包括,那么它们就全部都在全局作用域中。
这样就会 污染全局命名空间, 容易引起命名冲突。
这就是为何 jQuery、Zepto 等库的源码,所有的代码都会放在(function(){....})()(立即执行函数)中。因为放在里面的所有变量,都不会被外泄和暴露,不会污染到外面,不会对其他的库或者 JS 脚本造成影响。这是函数作用域的一个体现。
15.1.2 局部作用域
和全局作用域相反,局部作用域一般只在固定的代码片段内可访问到。局部作用域分为函数作用域和块级作用域。
-
函数作用域 函数作用域,是指声明在函数内部的变量或函数。
作用域是分层的,内层作用域可以访问外层作用域的变量,反之则不行
-
块级作用域
ES5 只有全局作用域和函数作用域,没有块级作用域,这带来很多不合理的场景
ES6的块级作用域在一定程度上解决了这些问题。
块级作用域可通过新增命令let和const声明,所声明的变量在指定块的作用域外无法被访问。块级作用域在如下情况被创建:
- 在一个函数内部
- 在一个代码块(由一对花括号包裹)内部
let 声明的语法与 var 的语法一致。基本上可以用 let 来代替 var 进行变量声明,但会将变量的作用域限制在当前代码块中。块级作用域有以下几个特点:
- 声明变量不会提升到代码块顶部,即不存在变量提升
- 禁止重复声明同一变量
- 循环中的绑定块作用域的妙用
15.2 var && let && const
ES6之前创建变量用的是 var ,之后创建变量用的是 let/const
三者区别:
-
var定义的变量,没有块{}的概念,可以跨块访问, 不能跨函数访问。
let定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问。
const用来定义常量,使用时必须初始化(即必须赋值),只能在块作用域里访问,且不能修改。 -
var可以先使用,后声明,因为存在变量提升;let必须先声明后使用。
-
var是允许在相同作用域内重复声明同一个变量的,而let与const不允许这一现象。
-
在全局上下文中,基于let声明的全局变量和全局对象GO(window)没有任何关系 ;
var声明的变量会和GO有映射关系; -
会产生暂时性死区 TDZ Temporal Dead Zone,并且 let 和 const 声明的变量不会被提升到作用是定位,如果在声明之前访问这些变量,会导致报错:
var value = "global"; // 例子1 (function() { console.log(value); let value = 'local'; }()); // 例子2 { // TDZ 暂时性死区 console.log(value); const value = 'local'; };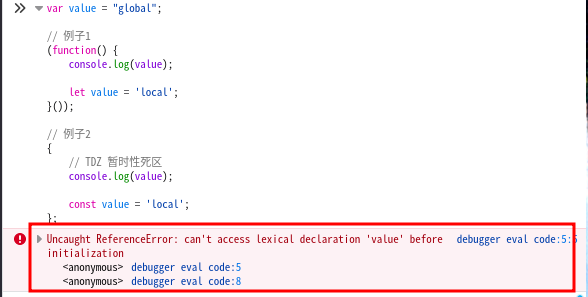
ES6 明确规定,如果区块中存在
let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。总之,在代码块内,使用
let命令声明变量之前,该变量都是不可用的。两个例子中,结果并不会打印 "global",而是报错
Uncaught ReferenceError: value is not defined,就是因为 TDZ 的缘故。暂时性死区是浏览器的bug:检测一个未被声明的变量类型时,不会报错,会返回undefined
如:console.log(typeof a) //undefined
而:console.log(typeof a)//未声明之前不能使用
let a暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
-
let /const/function会把当前所在的大括号(除函数之外)作为一个全新的块级上下文,应用这个机制,在开发项目的时候,遇到循环事件绑定等类似的需求,无需再自己构建闭包来存储,只要基于let的块作用特征即可解决
15.2.1 变量提升
-
function 也存在提升
例如:
f() function f(){ console.log('f') }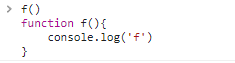
-
但是如果 函数名称和变量名称一样时,把
var f提升的时候,并不会用undefined覆盖函数声明console.log(f) var f = 2 function f(){ console.log('f') } console.log(f) var f = 1 f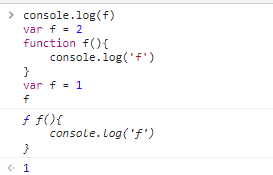
function x(){} var x x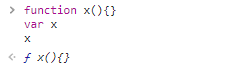
15.2.2 循环中的块级作用域
var funcs = [];
for (var i = 0; i < 3; i++) {
funcs[i] = function () {
console.log(i);
};
}
funcs[0](); // 3
一个老生常谈的面试题,解决方案如下:
var funcs = [];
for (var i = 0; i < 3; i++) {
funcs[i] = (function(i){
return function() {
console.log(i);
}
}(i))
}
funcs[0](); // 0
ES6 的 let 为这个问题提供了新的解决方法:
var funcs = [];
for (let i = 0; i < 3; i++) {
funcs[i] = function () {
console.log(i);
};
}
funcs[0](); // 0
可是问题在于, let 不提升,不能重复声明,不能绑定全局作用域等等特性,可是为什么可以正确打印 i 值呢 ?
如果是不重复声明,在循环第二次的时候,又用 let 声明了 i,应该报错呀,就算因为某种原因,重复声明不报错,一遍一遍迭代,i 的值
最终还是应该是 3 呀,还有人说 for 循环的设置循环变量的那部分是一个单独的作用域,就比如:
for (let i = 0; i < 3; i++) {
let i = 'abc';
console.log(i);
}
// abc
// abc
// abc
这个例子是对的,如果我们把 let 改成 var 呢?
for (var i = 0; i < 3; i++) {
var i = 'abc';
console.log(i);
}
// abc
为什么结果就不一样了呢,如果有单独的作用域,结果应该是相同的呀……
如果要追究这个问题,就要抛弃掉之前所讲的这些特性!这是因为 let 声明在循环内部的行为是标准中专门定义的,不一定就与 let 的不提升特性有关,其实,在早期的 let 实现中就不包含这一行为。
我们查看 ECMAScript 规范第 13.7.4.7 节:

我们会发现,在 for 循环中使用 let 和 var,底层会使用不同的处理方式。
那么当使用 let 的时候底层到底是怎么做的呢?
简单的来说,就是在 for (let i = 0; i < 3; i++) 中,即 圆括号之内建立一个隐藏的作用域,这就可以解释为什么:
for (let i = 0; i < 3; i++) {
let i = 'abc';
console.log(i);
}
// abc
// abc
// abc
然后每次迭代循环时都创建一个新变量,并以之前迭代中同名变量的值将其初始化。这样对于下面这样一段代码
var funcs = [];
for (let i = 0; i < 3; i++) {
funcs[i] = function () {
console.log(i);
};
}
funcs[0](); // 0
就相当于:
// 伪代码
(let i = 0) {
funcs[0] = function() {
console.log(i)
};
}
(let i = 1) {
funcs[1] = function() {
console.log(i)
};
}
(let i = 2) {
funcs[2] = function() {
console.log(i)
};
};
当执行函数的时候,根据词法作用域就可以找到正确的值,其实你也可以理解为 let 声明模仿了闭包的做法来简化循环过程。
15.2.3 循环中的 let 和 const
不过到这里还没有结束,如果我们把 let 改成 const 呢?
var funcs = [];
for (const i = 0; i < 10; i++) {
funcs[i] = function () {
console.log(i);
};
}
funcs[0](); // Uncaught TypeError: Assignment to constant variable.
结果会是报错,因为虽然我们每次都创建了一个新的变量,然而我们却在迭代中尝试修改 const 的值,所以最终会报错。
说完了普通的 for 循环,我们还有 for in 循环呢~
那下面的结果是什么呢?
var funcs = [], object = {a: 1, b: 1, c: 1};
for (var key in object) {
funcs.push(function(){
console.log(key)
});
}
funcs[0]() // c
结果是 'c';
那如果把 var 改成 let 或者 const 呢?
使用 let,结果自然会是 'a',const 呢? 报错还是 'a'?
结果是正确打印 'a',这是因为在 for in 循环中,每次迭代不会修改已有的绑定,而是会创建一个新的绑定。
在我们开发的时候,可能认为应该默认使用 let 而不是 var ,这种情况下,对于需要写保护的变量要使用 const。
然而另一种做法日益普及:默认使用 const,只有当确实需要改变变量的值的时候才使用 let。这是因为大部分的变量的值在初始化后不应再改变,而预料之外的变量之的改变是很多 bug 的源头。
15.3 执行上下文
行上下文(Execution context stack 简称 ECS)就是一个评估和执行JavaScript代码的环境的抽象概念。通俗地说,就是每当 Javascript 代码在运行的时候,它都是在执行上下文中运行。
JavaScript 中有三种执行上下文
- 全局执行上下文 — 这是默认或者说基础的上下文,任何不在函数内部的代码都在全局上下文中。它会执行两件事:创建一个全局的
window对象(浏览器的情况下),并且设置this的值等于这个全局对象。一个程序中只会有一个全局执行上下文。 - 函数执行上下文 — 每当一个函数被调用时, 都会为该函数创建一个新的执行上下文。每个函数都有它自己的执行上下文,不过是在函数被调用时创建的。函数上下文可以有任意多个。每当一个新的执行上下文被创建,它会按定义的顺序(将在后文讨论)执行一系列步骤。
- Eval 函数执行上下文 — 执行在
eval函数内部的代码也会有它属于自己的执行上下文,但由于 并不经常使用eval,所以在这里不作讨论。
执行上下文 的生命周期包括三个阶段:创建阶段→执行阶段→回收阶段
-
创建阶段
在
JavaScript代码执行前,执行上下文将经历创建阶段。在创建阶段会发生三件事:- this 值的决定,即我们所熟知的 This 绑定。
- 创建 词法环境 组件。(
LexicalEnvironment component) - 创建 变量环境 组件。(
VariableEnvironment component)
所以执行上下文用伪代码可以这样表示:
ExecutionContext = { // 执行上下文 ThisBinding = <this value>, // this绑定 LexicalEnvironment = { ... }, // 词法环境 VariableEnvironment = { ... }, // 变量环境 }-
this 绑定
在全局执行上下文中,
this的值指向全局对象。(在浏览器中,this引用Window对象)。 在函数执行上下文中,this的值取决于该函数是如何被调用的。如果它被一个引用对象调用,那么this会被设置成那个对象,否则this的值被设置为全局对象或者undefined(在严格模式下)。
-
执行阶段 执行变量赋值、代码执行。
注意 : 在执行阶段,如果 JavaScript 引擎不能在源码中声明的实际位置找到
let变量的值,它会被赋值为undefined。 -
回收阶段 执行上下文出栈等待虚拟机回收执行上下文
执行上下文栈
执行上下文栈(Execution Context Stack)(也称调用栈、执行栈),个人比较习惯叫调用栈,所以下文用调用栈来描述。它是一种拥有 LIFO(后进先出)数据结构的栈,被用来存储代码运行时创建的所有执行上下文。
当 JavaScript 引擎第一次遇到我们写的脚本时,它会创建一个全局的执行上下文并且压入当前调用栈。每当引擎遇到一个函数调用,它会为该函数创建一个新的函数执行上下文并压入栈的顶部。
引擎会执行那些执行上下文位于栈顶的函数。当该函数执行结束时,执行上下文从栈中弹出,控制流程到达当前栈中的下一个上下文。
让我们通过下面的代码示例来理解:
let a = 'Hello World!';
function first() {
console.log('Inside first function');
second();
console.log('Again inside first function');
}
function second() {
console.log('Inside second function');
}
first();
console.log('Inside Global Execution Context');

当上述代码在浏览器加载时,JavaScript 引擎创建了一个全局执行上下文并把它压入当前执行栈。当遇到 first() 函数调用时,JavaScript 引擎为该函数创建一个新的执行上下文并把它压入当前执行栈的顶部。
当从 first() 函数内部调用 second() 函数时,JavaScript 引擎为 second() 函数创建了一个新的执行上下文并把它压入当前执行栈的顶部。当 second() 函数执行完毕,它的执行上下文会从当前栈弹出,并且控制流程到达下一个执行上下文,即 first() 函数的执行上下文。
当 first() 执行完毕,它的执行上下文从栈弹出,控制流程到达全局执行上下文。一旦所有代码执行完毕,JavaScript 引擎从当前栈中移除全局执行上下文。
15.4 词法环境
官方定义:词法环境是一种规范类型,基于 ECMAScript 代码的词法嵌套结构来定义 标识符 和具体变量和函数的关联。一个词法环境由 环境记录器 和一个可能的 **引用外部词法环境的空值 **组成。
简单来说,词法环境是一种持有 标识符—变量的映射 的结构。(这里的 标识符 指的是变量/函数的名字,而 变量 是对实际对象[包含函数类型对象]或原始数据的引用)。
或者也可以这样说,词法环境就是指相应代码块内标识符与变量值、函数值之间的关联关系的一种体现。
**词法环境 **有两种类型:
- 全局环境(在全局执行上下文中)是没有外部环境引用的词法环境。全局环境的外部环境引用是 null。它拥有内建的
Object/Array等、在环境记录器内的原型函数(关联全局对象,比如window对象)还有任何用户定义的全局变量,并且this的值指向全局对象。 - 在 函数环境 中,函数内部用户定义的变量存储在 环境记录器 中。并且引用的外部环境可能是全局环境,或者任何包含此内部函数的外部函数。
在词法环境的 内部 有两个组件:
- 环境记录器:是存储变量和函数声明的实际位置。
- 外部环境的引用:意味着它可以访问其父级词法环境。
根据词法环境的两种类型,其内部的 环境记录器 也有两种类型:
- 声明式环境记录器(在函数环境中):存储变量、函数和参数。
- 对象环境记录器(在全局环境中):用来定义出现在 全局上下文 中的变量和函数的关系。
注意:对于 函数环境,声明式环境记录器 还包含了一个传递给函数的 arguments 对象(此对象存储索引和参数的映射)和传递给函数的参数的 length。
抽象地讲,词法环境在伪代码中看起来像这样:
GlobalExectionContext = { // 全局执行上下文
LexicalEnvironment: { // 词法环境
EnvironmentRecord: { // 环境记录器:存储变量和函数声明的实际位置 对象环境记录器
Type: "Object",
// 在这里绑定标识符
}
outer: <null> // 对外部环境的引用:可以访问其父级词法环境
}
}
FunctionExectionContext = { // 函数执行上下文
LexicalEnvironment: {
EnvironmentRecord: { // 声明式环境记录器
Type: "Declarative",
// 在这里绑定标识符
}
outer: <Global or outer function environment reference>
}
}
15.5 变量环境
变量环境同样是一个词法环境,其环境记录器持有 变量声明语句 在执行上下文中创建的绑定关系。
如上所述,变量环境也是一个词法环境,所以它有着上面定义的词法环境的所有属性。
之所以在 ES5 的规范里要单独分出一个变量环境的概念是为 ES6 服务的: 在 ES6 中,词法环境 组件和 变量环境 的一个不同就是前者被用来存储 函数声明 和变量(let 和 const)绑定,而后者只用来存储 var 变量绑定。
我们看点样例代码来理解上面的概念:
let a = 20;
const b = 30;
var c;
function multiply(e, f) {
var g = 20;
return e * f * g;
}
c = multiply(20, 30);
执行上下文看起来像这样:
GlobalExectionContext = {
ThisBinding: <Global Object>,
LexicalEnvironment: { // 词法环境
EnvironmentRecord: {
Type: "Object",
// 在这里绑定标识符
a: < uninitialized >, // let、const声明的变量
b: < uninitialized >, // let、const声明的变量
multiply: < func > // 函数声明
}
outer: <null>
},
VariableEnvironment: { // 变量环境
EnvironmentRecord: {
Type: "Object",
// 在这里绑定标识符
c: undefined, // var声明的变量
}
outer: <null>
}
}
FunctionExectionContext = {
ThisBinding: <Global Object>,
LexicalEnvironment: { // 词法环境
EnvironmentRecord: {
Type: "Declarative",
// 在这里绑定标识符
Arguments: {0: 20, 1: 30, length: 2}, // arguments对象
},
outer: <GlobalLexicalEnvironment>
},
VariableEnvironment: { // 变量环境
EnvironmentRecord: {
Type: "Declarative",
// 在这里绑定标识符
g: undefined // var声明的变量
},
outer: <GlobalLexicalEnvironment>
}
}
注意 — 只有遇到调用函数 multiply 时,函数执行上下文才会被创建。
可能你已经注意到 let 和 const 定义的变量并没有关联任何值,但 var 定义的变量被设成了 undefined。
这是因为在创建阶段时,引擎检查代码找出变量和函数声明,虽然函数声明完全存储在环境中,但是变量最初设置为 undefined(var 情况下),或者未初始化(let 和 const 情况下)。
这就是为什么你可以在声明之前访问 var 定义的变量(虽然是 undefined),但是在声明之前访问 let 和 const 的变量会得到一个引用错误。
这就是我们说的变量声明提升。
15.6 程序执行全过程
-
程序启动,全局执行上下文被创建,压入调用栈
- 创建全局上下文的 词法环境
- 创建 对象环境记录器 ,它用来定义出现在 全局上下文 中的变量和函数的关系(负责处理
let和const定义的变量) - 创建 外部环境引用,值为
null
- 创建 对象环境记录器 ,它用来定义出现在 全局上下文 中的变量和函数的关系(负责处理
- 创建全局上下文的 变量环境
- 创建 对象环境记录器,它持有 变量声明语句 在执行上下文中创建的绑定关系(负责处理
var定义的变量,初始值为undefined造成声明提升) - 创建 外部环境引用,值为
null
- 创建 对象环境记录器,它持有 变量声明语句 在执行上下文中创建的绑定关系(负责处理
- 确定
this值为全局对象(以浏览器为例,就是window)
- 创建全局上下文的 词法环境
-
函数被调用,函数执行上下文被创建,压入调用栈
- 创建函数上下文的 词法环境
- 创建 声明式环境记录器 ,存储变量、函数和参数,它包含了一个传递给函数的
arguments对象(此对象存储索引和参数的映射)和传递给函数的参数的 length。(负责处理let和const定义的变量) - 创建 外部环境引用,值为全局对象,或者为父级词法环境(作用域)
- 创建 声明式环境记录器 ,存储变量、函数和参数,它包含了一个传递给函数的
- 创建函数上下文的 变量环境
- 创建 声明式环境记录器 ,存储变量、函数和参数,它包含了一个传递给函数的
arguments对象(此对象存储索引和参数的映射)和传递给函数的参数的 length。(负责处理var定义的变量,初始值为undefined造成声明提升) - 创建 外部环境引用,值为全局对象,或者为父级词法环境(作用域)
- 创建 声明式环境记录器 ,存储变量、函数和参数,它包含了一个传递给函数的
- 确定
this值
- 创建函数上下文的 词法环境
-
进入函数执行上下文的执行阶段:
- 在上下文中运行/解释函数代码,并在代码逐行执行时分配变量值。
总结:
首先,JavaScript属于解释型语言,JavaScript的执行分为解释和执行两个阶段,这两个阶段所做的事并不一样:
解释阶段:
- 词法分析
- 语法分析
- 作用域规则确定
执行阶段:
- 创建执行上下文
- 执行函数代码
- 垃圾回收
JavaScript解释阶段便会确定作用域规则,因此作用域在函数定义时就已经确定了,而不是在函数调用时确定,但是执行上下文是函数执行之前创建的。执行上下文最明显的就是this的指向是执行时确定的。而作用域访问的变量是编写代码的结构确定的。
作用域和执行上下文之间最大的区别是: 执行上下文在运行时确定,随时可能改变;作用域在定义时就确定,并且不会改变。
一个作用域下可能包含若干个上下文环境。有可能从来没有过上下文环境(函数从来就没有被调用过);有可能有过,现在函数被调用完毕后,上下文环境被销毁了;有可能同时存在一个或多个(闭包)。同一个作用域下,不同的调用会产生不同的执行上下文环境,继而产生不同的变量的值。
最后的最后,简要概况一下作用域,词法环境,执行上下文这三者的概念:
- 作用域:作用域就是一个独立的区域,它可以让变量不会向外暴露出去。作用域最大的用处就是隔离变量。内层作用域可以访问外层作用域。一个作用域下可能包含若干个执行上下文。
- 词法环境:指相应代码块内标识符与变量值、函数值之间的关联关系的一种体现。词环境内部包含环境记录器和对外部环境的引用。环境记录器是存储变量和函数声明的实际位置,对外部环境的引用意味着可以访问父级词法环境。
- 执行上下文:JavaScript代码运行的环境。分为全局执行上下文,函数执行上下文和eval函数执行上下文(前两个较常见)。创建执行上下文时会进行this绑定、创建词法环境和变量环境。
16. 相等性判断
ES2015中有四种相等算法:
- 抽象(非严格)相等比较 (
==) - 严格相等比较 (
===):用于:Array.prototype.indexOf(),Array.prototype.lastIndexOf()和case-matching - 同值零:用于
%TypedArray%和ArrayBuffer构造函数、以及Map和Set操作,并将用于 ES2016/ES7中的String.prototype.includes() - 同值:用于所有其他地方
JavaScript提供三种不同的值比较操作:
- 严格相等比较 (也被称作"strict equality", "identity", "triple equals"),使用 === ,
- 抽象相等比较 ("loose equality","double equals") ,使用 ==
- 以及
Object.is(ECMAScript 2015/ ES6 新特性)
简而言之,在比较两件事情时,双等号将执行类型转换; 三等号将进行相同的比较,而不进行类型转换 (如果类型不同, 只是总会返回 false ); 而 Object.is的行为方式与三等号相同,但是对于NaN和-0和+0进行特殊处理,所以最后两个不相同,而Object.is(NaN,NaN)将为 true。(通常使用双等号或三等号将NaN与NaN进行比较,结果为false,因为IEEE 754如是说.) 请注意,所有这些之间的区别都与其处理原语有关; 这三个运算符的原语中,没有一个会比较两个变量是否结构
16.1 严格相等 ===
全等操作符比较两个值是否相等,两个被比较的值在比较前都不进行隐式转换。如果两个被比较的值具有不同的类型,这两个值是不全等的。否则,如果两个被比较的值类型相同,值也相同,并且都不是 number 类型时,两个值全等。最后,如果两个值都是 number 类型,当两个都不是 NaN,并且数值相同,或是两个值分别为 +0 和 -0 时,两个值被认为是全等的。
var num = 0;
var obj = new String("0");
var str = "0";
var b = false;
console.log(num === num); // true
console.log(obj === obj); // true
console.log(str === str); // true
console.log(num === obj); // false
console.log(num === str); // false
console.log(obj === str); // false
console.log(null === undefined); // false
console.log(obj === null); // false
console.log(obj === undefined); // false
在日常中使用全等操作符几乎总是正确的选择。对于除了数值之外的值,全等操作符使用明确的语义进行比较:一个值只与自身全等。对于数值,全等操作符使用略加修改的语义来处理两个特殊情况:第一个情况是,浮点数 0 是不分正负的。区分 +0 和 -0 在解决一些特定的数学问题时是必要的,但是大部分情况下我们并不用关心。全等操作符认为这两个值是全等的。第二个情况是,浮点数包含了 NaN 值,用来表示某些定义不明确的数学问题的解,例如:正无穷加负无穷。全等操作符认为 NaN 与其他任何值都不全等,包括它自己。(等式 (x !== x) 成立的唯一情况是 x 的值为 NaN)
16.2 非严格相等 ==
相等操作符比较两个值是否相等,在比较前将两个被比较的值转换为相同类型。在转换后(等式的一边或两边都可能被转换),最终的比较方式等同于全等操作符 === 的比较方式。 相等操作符满足交换律。
相等操作符对于不同类型的值,进行的比较如下图所示:
| 被比较值 B | |||||||
|---|---|---|---|---|---|---|---|
| Undefined | Null | Number | String | boolean | Object | ||
| Undefined | true | true | false | false | false | IsFalsy(B) | |
| Null | true | true | false | false | false | IsFalsy(B) | |
| 被比较值 B [B] | Number | false | false | A === B | A === ToNumber(B) | A === ToNumber(B) | A == ToPrimitive(B) |
| String | false | false | ToNumber(A) === B | A === B | ToNumber(A) === ToNumber(B) | ToPrimitive(B) == A | |
| Boolean | false | false | ToNumber(A) === B | ToNumber(A) === ToNumber(B) | A === B | ToNumber(A) == ToPrimitive(B) | |
| Object | false | false | ToPrimitive(A) == B | ToPrimitive(A) == B | ToPrimitive(A) == ToNumber(B) | A === B |
在上面的表格中,ToNumber(A) 尝试在比较前将参数 A 转换为数字,这与 +A(单目运算符+)的效果相同。ToPrimitive(A)通过尝试调用 A 的A.toString() 和 A.valueOf() 方法,将参数 A 转换为原始值(Primitive)。
一般而言,根据 ECMAScript 规范,所有的对象都与 undefined 和 null 不相等。但是大部分浏览器允许非常窄的一类对象(即,所有页面中的 document.all 对象),在某些情况下,充当效仿 undefined 的角色。相等操作符就是在这样的一个背景下。因此,IsFalsy(A) 方法的值为 true ,当且仅当 A 效仿 undefined。在其他所有情况下,一个对象都不会等于 undefined 或 null。
var num = 0;
var obj = new String("0");
var str = "0";
var b = false;
console.log(num == num); // true
console.log(obj == obj); // true
console.log(str == str); // true
console.log(num == obj); // true
console.log(num == str); // true
console.log(obj == str); // true
console.log(null == undefined); // true
// both false, except in rare cases
console.log(obj == null);
console.log(obj == undefined);
有些开发者认为,最好永远都不要使用相等操作符。全等操作符的结果更容易预测,并且因为没有隐式转换,全等比较的操作会更快。
16.3 同值相等
同值相等解决了最后一个用例:确定两个值是否在任何情况下功能上是相同的。(这个用例演示了里氏替换原则的实例。)当试图对不可变(immutable)属性修改时发生出现的情况:
// 向 Nmuber 构造函数添加一个不可变的属性 NEGATIVE_ZERO
Object.defineProperty(Number, "NEGATIVE_ZERO",
{
value: -0,
writable: false,
configurable: false,
enumerable: false
});
function attemptMutation(v)
{
Object.defineProperty(Number, "NEGATIVE_ZERO", { value: v });
}
Object.defineProperty 在试图修改不可变属性时,如果这个属性确实被修改了则会抛出异常,反之什么都不会发生。例如如果 v 是 -0 ,那么没有发生任何变化,所以也不会抛出任何异常。但如果 v 是 +0 ,则会抛出异常。不可变属性和新设定的值使用 same-value 相等比较。
同值相等由 Object.is 方法提供。
16.4 零值相等
与同值相等类似,不过会认为 +0 与 -0 相等。
16.5 理解相等比较的模型
在 ES2015 以前,你可能会说双等和三等是“扩展”的关系。比如有人会说双等是三等的扩展版,因为他处理三等所做的,还做了类型转换。例如 6 == "6" 。反之另一些人可能会说三等是双等的扩展,因为他还要求两个参数的类型相同,所以增加了更多的限制。怎样理解取决于你怎样看待这个问题。
但是这种比较的方式没办法把 ES2015 的 Object.is 排列到其中。因为 Object.is 并不比双等更宽松,也并不比三等更严格,当然也不是在他们中间。从下表中可以看出,这是由于 Object.is 处理 NaN 的不同。注意假如 Object.is(NaN, NaN) 被计算成 false ,我们就可以说他比三等更为严格,因为他可以区分 -0 和 +0 。但是对 NaN 的处理表明,这是不对的。 Object.is 应该被认为是有其特殊的用途,而不应说他和其他的相等更宽松或严格。
判等
| x | y | == |
=== |
Object.is |
|---|---|---|---|---|
undefined |
undefined |
true |
true |
true |
null |
null |
true |
true |
true |
true |
true |
true |
true |
true |
false |
false |
true |
true |
true |
"foo" |
"foo" |
true |
true |
true |
0 |
0 |
true |
true |
true |
+0 |
-0 |
true |
true |
false |
0 |
false |
true |
false |
false |
"" |
false |
true |
false |
false |
"" |
0 |
true |
false |
false |
"0" |
0 |
true |
false |
false |
"17" |
17 |
true |
false |
false |
[1,2] |
"1,2" |
true |
false |
false |
new String("foo") |
"foo" |
true |
false |
false |
null |
undefined |
true |
false |
false |
null |
false |
false |
false |
false |
undefined |
false |
false |
false |
false |
{ foo: "bar" } |
{ foo: "bar" } |
false |
false |
false |
new String("foo") |
new String("foo") |
false |
false |
false |
0 |
null |
false |
false |
false |
0 |
NaN |
false |
false |
false |
"foo" |
NaN |
false |
false |
false |
NaN |
NaN |
false |
false |
true |
16.6 什么时候使用 Object.is() 或是 ===
总的来说,除了对待NaN的方式,Object.is唯一让人感兴趣的,是当你需要一些元编程方案时,它对待0的特殊方式,特别是关于属性描述器,即你的工作需要去镜像Object.defineProperty的一些特性时。如果你的工作不需要这些,那你应该避免使用Object.is,使用===来代替。即使你需要比较两个NaN使其结果为true,总的来说编写使用NaN 检查的特例函数(用旧版本ECMAScript的isNaN方法)也会比想出一些计算方法让Object.is不影响不同符号的0的比较更容易些。
17. JavaScript 中的内存管理
像C语言这样的底层语言一般都有底层的内存管理接口,比如 malloc()和free()。相反,JavaScript是在创建变量(对象,字符串等)时自动进行了分配内存,并且在不使用它们时“自动”释放。 释放的过程称为垃圾回收。这个“自动”是混乱的根源,并让JavaScript(和其他高级语言)开发者错误的感觉他们可以不关心内存管理。
内存生命周期
- 分配所需要的内存
- 使用分配到的内存(读、写)
- 不需要时将其释放/归还
所有语言第二部分都是明确的。第一和第三部分在底层语言中是明确的,但在像 JavaScript 这些高级语言中,大部分都是隐含的。
JavaScript 的内存分配
值的初始化
为了不让程序员费心分配内存,JavaScript 在定义变量时就完成了内存分配。
使用值的过程实际上是对分配内存进行读取与写入的操作。读取与写入可能是写入一个变量或者一个对象的属性值,甚至传递函数的参数。
当内存不再需要使用时释放
大多数内存管理的问题都在这个阶段。在这里最艰难的任务是找到“哪些被分配的内存确实已经不再需要了”。它往往要求开发人员来确定在程序中哪一块内存不再需要并且释放它。
高级语言解释器嵌入了“垃圾回收器”,它的主要工作是跟踪内存的分配和使用,以便当分配的内存不再使用时,自动释放它。这只能是一个近似的过程,因为要知道是否仍然需要某块内存是无法判定的(无法通过某种算法解决)。
17.1 引用技术
垃圾回收算法主要依赖于引用的概念。在内存管理的环境中,一个对象如果有访问另一个对象的权限(隐式或者显式),叫做一个对象引用另一个对象。例如,一个Javascript对象具有对它原型的引用(隐式引用)和对它属性的引用(显式引用)。
在这里,“对象”的概念不仅特指 JavaScript 对象,还包括函数作用域(或者全局词法作用域)。
这是最初级的垃圾收集算法。此算法把“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”。如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。
限制:循环引用
该算法有个限制:无法处理循环引用的事例。在下面的例子中,两个对象被创建,并互相引用,形成了一个循环。它们被调用之后会离开函数作用域,所以它们已经没有用了,可以被回收了。然而,引用计数算法考虑到它们互相都有至少一次引用,所以它们不会被回收。
function f(){
var o = {};
var o2 = {};
o.a = o2; // o 引用 o2
o2.a = o; // o2 引用 o
return "azerty";
}
f();
17.2 标记-清除算法 Mark-Sweep
这个算法把“对象是否不再需要”简化定义为“对象是否可以获得”。
这个算法假定设置一个叫做根(root)的对象(在Javascript里,根是全局对象)。垃圾回收器将定期从根开始,找所有从根开始引用的对象,然后找这些对象引用的对象……从根开始,垃圾回收器将找到所有可以获得的对象和收集所有不能获得的对象。
这个算法比前一个要好,因为“有零引用的对象”总是不可获得的,但是相反却不一定,参考“循环引用”。
从2012年起,所有现代浏览器都使用了标记-清除垃圾回收算法。所有对JavaScript垃圾回收算法的改进都是基于标记-清除算法的改进,并没有改进标记-清除算法本身和它对“对象是否不再需要”的简化定义。
这样循环引用不再是问题了
在上面的示例中,函数调用返回之后,两个对象从全局对象出发无法获取。因此,他们将会被垃圾回收器回收。第二个示例同样,一旦 div 和其事件处理无法从根获取到,他们将会被垃圾回收器回收。
限制: 那些无法从根对象查询到的对象都将被清除
尽管这是一个限制,但实践中我们很少会碰到类似的情况,所以开发者不太会去关心垃圾回收机制。
17.3 V8 的垃圾回收
V8 实现了准确式 GC,GC 算法采用了 分代式垃圾回收机制。因此,V8 将内存(堆)分为新生代和老生代两部分。
17.3.1 V8 的内存限制
Node不同于其他后端语言,Node在对系统的内存使用中,只能使用到系统的部分内存,比如64位系统只能使用1.4GB,32位系统只能使用0.7GB。随之到来的问题是Node采用单线程,就导致每个线程无法对大的内存对象进行处理,比如将一个2GB的文件读入内存进行字符串分析处理,即使你有16G的物理内存。
17.3.2 V8 的对象分配
在javascript中我们的基本类型存储在栈中,所有对象都分配给了堆处理。 我们每赋值一个对象,该对象的内存就会分配在堆中。如果已申请堆所剩内存不足以分配新的对象,将会继续申请新内存,直到堆的大小超过V8的内存大小限制为止。

至于V8的内存限制,起源于V8本身是chrome为浏览器设计而生,而浏览器中对于网页来说,V8控制的内存绰绰有余。还源于V8设计者对于V8的垃圾回收机制的限制,官方以1.5GB的垃圾回收堆内存为例,V8执行一个小的垃圾回收要使用50毫秒以上,做一次常规非增量式垃圾回收要在1秒以上。
最关键的,javascript的垃圾回收会对javascript执行线程形成阻塞,作为一个开发人员你应该能够清楚时长1秒的进程阻塞,对你的项目性能的影响,故此V8的设计者采用了对堆内存进行限制的策略。
17.3.3 V8 的内存分代
V8的垃圾回收策略主要基于分代,那么怎么分代呢?
在V8中,主要将内存分为 新生代 和 老生代 两类。
新生代指的是那些 存活时间较短 的对象,
老生代指的是 存活时间较长的或者常驻内存 的对象。
而新生代加老生代的对象所占空间大小就是V8的堆的整体大小。

V8 提供了设置新生代和老生代最大内存值的方式,从而可以调整V8的整体内存限制,使用更多的内存空间。
使用
--max-old-space-size来调整老生代最大空间
--max-new-space-size来调整新生代最大空间,但是该操作需要在 Node 进程启动时就设置才有效。
17.3.4 V8 的主要垃圾回收算法
-
Scanvenge 算法
Scanvenge是一种复制形式的垃圾回收算法,是应用于新生代对象中的一种垃圾回收算法,算法首先将堆内存一分为二,两部分空间一半用来分配赋值的对象,叫做 From 空间,另一半处于空闲的叫做 To 空间。
为什么要有一半空间用来闲置呢?这不是让我们的可用内存更小了吗?
当我们为堆分配对象时,会将分配对象放到From空间中存储,
在V8的垃圾和回收过程中,
- 会首先检查From中存活的对象(什么是存活的对象,就是指那些 还被继续引用没有完全释放的对象),
- V8会将From中存活的对象复制到To空间中,同时清理掉已经被释放的对象空间。
- 完成该过程From空间和To空间即完成了角色对换,也就是在下一次回收中,之前的From空间变成了To空间,之前的To空间变成了From空间。
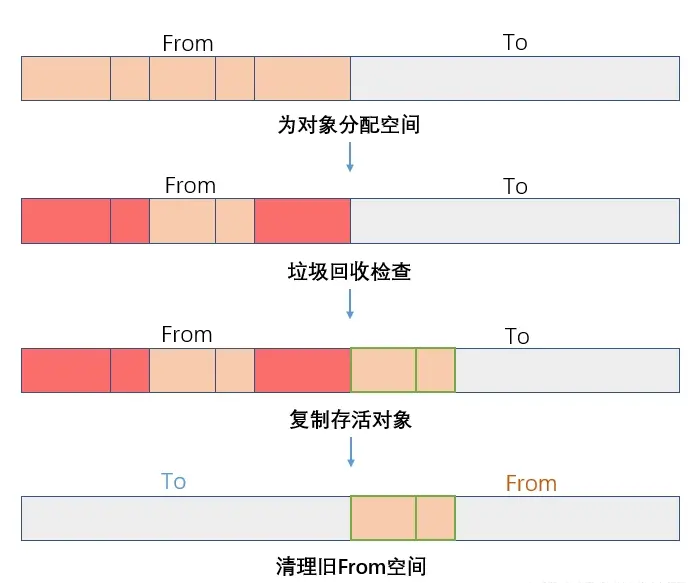
缺点: 明显的缺点就是只能使用堆内存的一半
**优点: ** 但是随之带来的好处就是它在 **时间效率 **上的优异的表现,属于典型的牺牲空间换取时间的算法。
需要强调的是,开头提到的 Scanvenge算法是应用于新生代对象中的一种垃圾回收算法,因为新生代对象中的生命周期较短的特性,也契合于该算法优先时间考虑的特性。
怎样算生命周期较长的对象?
当一个对象经过多次复制依然存活时,它将会被认为是生命周期较长的对象。这种生命周期较长的对象随后会被移动到老生代对象中,采用新的算法(Mark-Sweep&Mark-Compact)进行管理,这个过程称为晋升。
通过上图可以了解到,对象进行垃圾回收是怎样从From到To之间转换的,那么这个晋升的过程在哪儿体现呢?
在默认情况下,V8对新生代对象进行从From到To空间进行复制时,会先检查它的内存地址来判断这个对象是否已经经历过一次Scanvenge回收。如果已经经历过,那么会将该对象从From空间直接复制到老生代空间,如果没有,才会将其复制到To空间。
对象晋升的条件主要有两个:
- 一个是对象是否经历过Scanvenge回收
- 一个是To空间的内存占用超过限制。
假设一个对象像刚才说的没有经历过Scanvenge回收,要将它复制到To空间之前,还要再进行一次检查。检查To空间是否已经使用了超过25%,如果To空间超过25%,该对象将直接被晋升到老生代空间进行管理。
完整看一下这个流程:
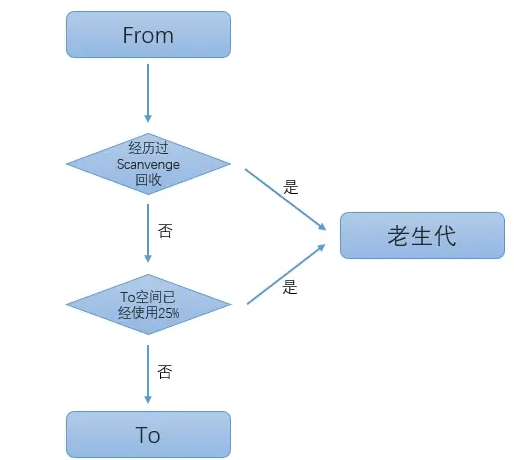
对象晋升后,该对象即成为老生代中的存活周期较长的对象,所以我们可以重新对老生代进行定义:老生代对象为存活周期较长或常驻内存的对象,或为新生代对象回收中溢出的对象。
至于为什么设置25%的原因是,当一次Scanvenge回收完成时,To空间变为From空间,如果新的From空间使用占比过高,将对接下来的内存分配到这个新的From空间过程存在很大的影响。
-
Mark-Sweep & Mark-Compact 算法
老生代中的对象使用的回收算法,这种算法(Mark-Sweep)也是我们常说的垃圾回收中的 标记清除 算法。
首先,老生代空间不会一分为二,老生代空间进行垃圾回收时,首先是标记阶段。V8会在标记阶段遍历老生代空间中的所有对象,并标记存活的对象(即还没有被完全释放的对象),在随后的清除阶段,会将所有未标记的老生代对象全部回收。
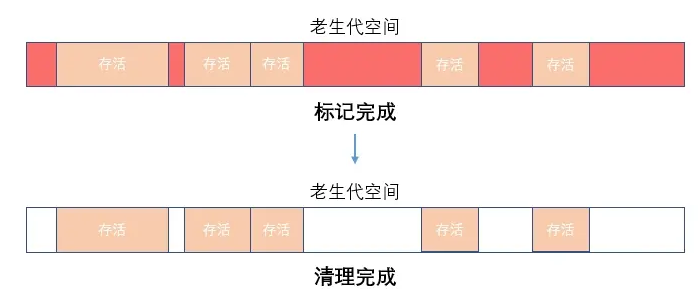
Mark-Sweep在执行完清除之后,导致内存空间出现不连续的情况,就像你的磁盘分析图一样。
这样会带来的一个问题就是,当你需要分配一个较大的对象时,剩余的内存因为碎片化的原因,没有任何一个内存碎片足以分配给这个大的对象内存空间,就会导致提前触发垃圾回收,而这次回收是不必要的。
所以Mark-Compact算法随之而生,Mark-Compact比Mark-Sweep增加了一个 整理 的概念,它的回收执行顺序是 **标记—整理—清除 **。 Mark-Compact所谓的整理概念是指在对象同样被标记为存活后,会将活着的对象往一端移动,移动完成后在直接清理掉死亡的对象内存。

两种差别显而易见,Mark-Compact 算法执行后的内存空间更合理。但是因为 Mark-Compact 算法需要移动对象,随之导致的就是它的执行速度没有 Mark-Sweep快。
所以在V8中主要使用Mark-Sweep算法,只有在空间不足以对新生代中晋升过来的对象进行分配时,才会使用Mark-Compact算法进行回收。
回收算法 Scanvenge Mark-Sweep Mark-Compact 速度 最快 中等 最慢 空间开销 双倍空间(无碎片) 少(有碎片) 少(无碎片) 是否移动对象 是 否 是 -
Incrental Marking 算法
因为垃圾回收会阻塞javascript的运行,故此老生代对象又因为其占用空间大,存活对象多的特点,对其进行标记,整理,回收的过程引起的阻塞要远远比新生代对象回收过程一起的阻塞要严重的多,Incremental Marking算法成为了优化老生代对象耗时的算法选择。
为了降低老生代空间垃圾回收带来的停顿影响,V8 采用了增量标记(incremental marking)的算法。将原本一口气停顿完成的来及回收过程拆分为许多小“步进”,每做完一“步进”就让JavaScript应用逻辑继续执行一小会儿,垃圾回收与应用逻辑交替执行直到标记阶段完成。取得的效果就是,将老生代空间垃圾回收的最大停顿时间可以减少到原本的1/6左右。
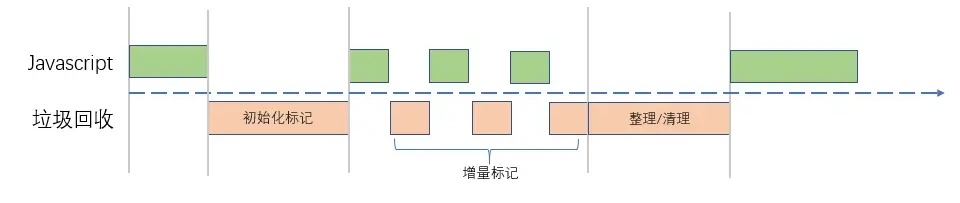
V8 后续还引入了延迟清理(lazy sweeping)、增量式整理(incremental compaction)、并发标记 等技术。
18. 手写发布订阅模式 EventEmitter
class EventEmitter {
constructor() {
// 单例模式
if (!EventEmitter.instance) {
EventEmitter.instance = this;
this.handleMap = {};
}
//map结构,用于储存事件与其对应的回调
return EventEmitter.instance;
}
//事件订阅,需要接收订阅事件名和对应的回调函数
on(eventName, callback) {
this.handleMap[eventName] = this.handleMap[eventName] ?? [];
this.handleMap[eventName].push(callback);
}
//事件发布,需要接收发布事件名和对应的参数
emit(eventName, ...args) {
if (this.handleMap[eventName]) {
//这里需要浅拷贝一下handleMap[eventName],因为在 once 添加订阅时会修改this.handleMap,若once绑定在前就会导致后一个监听被移除
const handlers = [...this.handleMap[eventName]];
handlers.forEach((callback) => callback(...args));
}
}
//移除订阅,需要移除的订阅事件名及指定的回调函数
remove(eventName, callback) {
const callBacks = this.handleMap[eventName];
const index = callBacks.indexOf(callback);
if (index !== -1) {
callBacks.splice(index, 1);
}
}
//添加单次订阅,触发一次订阅事件后取消订阅,需要添加的订阅事件名及指定的回调函数
once(eventName, callback) {
const wrapper = (...args) => {
callback(...args);
this.remove(eventName, warpper);
};
this.on(eventName, wrapper);
}
}
测试:
//基础测试
const eventBus = new EventEmitter();
eventBus.once("demo", (params) => {
console.log(1, params);
});
eventBus.on("demo", (params) => {
console.log(2, params);
});
eventBus.on("demo", (params) => {
console.log(3, params);
});
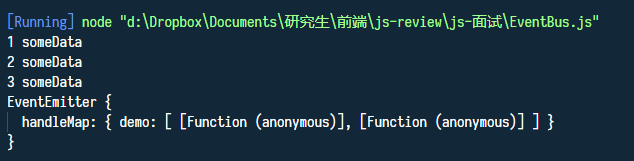
eventBus.emit("demo", "someData");
console.log(eventBus);
19. 获取 url 参数
-
直接使用
URLSearchParams方法// 创建一个URLSearchParams实例 const urlSearchParams = new URLSearchParams(window.location.search); // 把键值对列表转换为一个对象 const params = Object.fromEntries(urlSearchParams.entries()); -
使用
split方法function getParams(url) { const res = {} if (url.includes('?')) { const str = url.split('?')[1] const arr = str.split('&') arr.forEach(item => { const key = item.split('=')[0] const val = item.split('=')[1] res[key] = decodeURIComponent(val) // 解码 }) } return res } // 测试 const user = getParams('http://www.baidu.com?user=%E9%98%BF%E9%A3%9E&age=16') console.log(user) // { user: '阿飞', age: '16' }
20. 手写 Promise
// Promise 实现
const PENDING = "pending";
const FULFILLED = "fulfilled";
const REJECTED = "rejected";
function Promise(executor) {
// 默认属性
this.PromiseState = PENDING;
this.PromiseResult = null;
// 保存回调
this.callbacks = [];
// 保存示例的 this
const self = this;
// resolve 函数
function resolve(data) {
if (self.PromiseState !== PENDING) {
return;
}
// 1. 设置对象状态为 fulfilled
self.PromiseState = FULFILLED;
// 2. 设置对象结果值
self.PromiseResult = data;
// 调用成功的回调
self.callbacks.forEach((callback) => {
setTimeout(() => {
callback.onResolved(data);
});
});
}
function reject(data) {
if (self.PromiseState !== PENDING) {
return;
}
// 1. 设置对象状态为 rejected
self.PromiseState = REJECTED;
// 2. 设置对象结果值
self.PromiseResult = data;
// 调用失败的回调
self.callbacks.forEach((callback) => {
setTimeout(() => {
callback.onRejected(data);
});
});
}
try {
// 同步调用 执行器函数
executor(resolve, reject);
} catch (e) {
// 修改 promise 状态为 rejected
reject(e);
}
}
// 添加 then 方法
Promise.prototype.then = function (onResolved, onRejected) {
if (typeof onResolved !== "function") {
onResolved = (value) => value;
}
if (typeof onRejected !== "function") {
onRejected = (reason) => {
throw reason;
};
}
let self = this;
return new Promise((resolve, reject) => {
function callback(type) {
try {
let result = type(self.PromiseResult);
if (result instanceof Promise) {
result.then(
(v) => {
resolve(v);
},
(r) => {
reject(r);
}
);
} else {
resolve(result);
}
} catch (e) {
reject(e);
}
}
// 调用回调函数
if (this.PromiseState === FULFILLED) {
setTimeout(() => {
callback(onResolved);
});
}
if (this.PromiseState === REJECTED) {
setTimeout(() => {
callback(onRejected);
});
}
// 如果当前为 PENGDING 状态
if (this.PromiseState === PENDING) {
// 保存回调函数
this.callbacks.push({
onResolved: function () {
callback(onResolved);
},
onRejected: function () {
callback(onRejected);
},
});
}
});
};
// 添加 catch 方法
Promise.prototype.catch = function (onRejected) {
return this.then(undefined, onRejected);
};
// finally
Promise.prototype.finally = function (fn) {
return this.then(
function (value) {
return Promise.resolve(fn()).then(function () {
return value;
});
},
function (error) {
return Promise.resolve(fn()).then(function () {
throw error;
});
}
);
};
Promise.resolve = function (value) {
return new Promise((resolve, reject) => {
if (value instanceof Promise) {
value.then(
(v) => {
resolve(v);
},
(r) => {
reject(r);
}
);
} else {
resolve(value);
}
});
};
Promise.reject = function (reason) {
return new Promise((resolve, reject) => {
reject(reason);
});
};
Promise.all = function (promises) {
return new Promise((resolve, reject) => {
let count = 0,
arr = [];
for (let i = 0; i < promises.length; i++) {
promises[i].then(
(v) => {
count++;
arr[i] = v;
if (count === promises.length) {
resolve(arr);
}
},
(r) => {
reject(r);
}
);
}
});
};
Promise.race = function (promises = []) {
return new Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(
(v) => {
resolve(v);
},
(r) => {
reject(r);
}
);
}
});
};
Promise.any = function (promises = []) {
return new Promise((resolve, reject) => {
let count = 0;
for (let i = 0; i < promises.length; i++) {
promises[i].then(
(v) => {
resolve(v);
},
(r) => {
count++;
if (count === promises.length) {
console.log("promise any:", r);
// reject(r);
reject(
new AggregateError("No promise in Promise.any was resolved")
);
}
}
);
}
});
};
21. JS 事件循环
众所周知 JS 是门非阻塞单线程语言,因为在最初 JS 就是为了和浏览器交互而诞生的。如果 JS 是门多线程的语言话,我们在多个线程中处理 DOM 就可能会发生问题(一个线程中新加节点,另一个线程中删除节点),当然可以引入读写锁解决这个问题。
JS 在执行的过程中会产生执行环境,这些执行环境会被顺序的加入到执行栈中。如果遇到异步的代码,会被挂起并加入到 Task(有多种 task) 队列中。一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说 JS 中的异步还是同步行为。
console.log('script start')
setTimeout(function() {
console.log('setTimeout')
}, 0)
console.log('script end')
以上代码虽然 setTimeout 延时为 0,其实还是异步。这是因为 HTML5 标准规定这个函数第二个参数不得小于 4 毫秒,不足会自动增加。所以 setTimeout 还是会在 script end 之后打印。
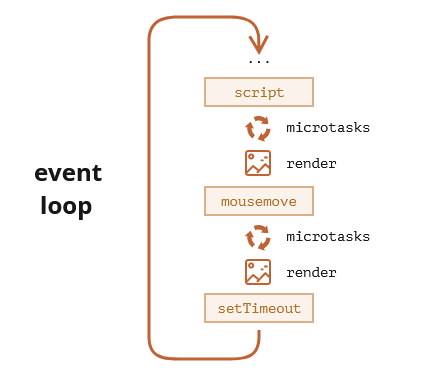
不同的任务源会被分配到不同的 Task 队列中,任务源可以分为 微任务(microtask) 和 宏任务(macrotask)。在 ES6 规范中,microtask 称为 jobs,macrotask 称为 task。
所以正确的一次 Event loop 顺序是这样的
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染 UI
- 然后开始下一轮 Event loop,执行宏任务中的异步代码
通过上述的 Event loop 顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作 DOM 的话,为了更快的 界面响应,我们可以把操作 DOM 放入微任务中。
事件循环由三部分组成
-
调用栈 call stack
function foo1(){ console.log("22") } function foo() { console.log("11"); foo1() console.log("33") } foo() // 打印顺序是:11 22 33 -
消息队列 message queue
console.log("00"); function foo() { console.log("11"); setTimeout(() => { console.log("22") }, 0); console.log("33") } foo(); console.log("44") // 打印顺序是:00 11 33 44 22 -
微任务队列 microtask queue
- 普通函数执行时先放入 调用栈 中 按 顺序 执行并立即释放
- 异步函数 setTimeout, setInterval, xhr... 执行时放入 消息队列中,执行完调用栈中的任务后执行
- promise, async, await 创建的函数先放入 微任务队列 中,调用栈清空后 立即被执行
-
主线程
所有的同步任务都是在主线程里执行的,异步任务可能会在
macrotask或者microtask里面- 同步任务 指的是在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务
- 异步任务 指的是不进入主线程,某个异步任务可以执行了,该任务才会进入主线程执行
-
微任务 micro task
- promise
- async
- await
- process.nextTick(node)
- mutationObserver
-
宏任务 marco task
- script 整体代码
- setTimeout
- setInterval
- setImmediate
- I/O
- UI render
-
大致流程
简单的说,事件循环(
eventLoop)是单线程的JavaScript在处理异步事件时进行的一种循环过程,具体来讲,对于异步事件它会先加入到事件队列中挂起,等主线程空闲时会去执行事件队列中的事件。- 主线程任务——>微任务——>宏任务 如果宏任务里还有微任务就继续执行宏任务里的微任务,如果宏任务中的微任务中还有宏任务就在依次进行
- 主线程任务——>微任务——>宏任务——>宏任务里的微任务——>宏任务里的微任务中的宏任务——>直到任务全部完成 我的理解是在同级下,微任务要优先于宏任务执行
-
在同一轮任务队列中,同一个微任务产生的微任务会放在这一轮微任务的后面,产生的宏任务会放在这一轮的宏任务后面
-
在同一轮任务队列中,同一个宏任务产生的微任务会马上执行,产生的宏任务会放在这一轮的宏任务后面
总结:
-
微任务队列优先于宏任务队列执行;
-
微任务队列上创建的宏任务会被后添加到当前宏任务队列的尾端;
-
微任务队列中创建的微任务会 被添加到微任务队列的尾端;
-
只要微任务队列中还有任务,宏任务队列就只会等待微任务队列执行完毕后再执行;
-
只有运行完
await语句,才把await语句后面的全部代码加入到微任务行列; -
在遇到
await promise时,必须等await promise函数执行完毕才能对await语句后面的全部代码加入到微任务中;-
在等待
await Promise.then微任务时:-
运行其他同步代码;
-
等到同步代码运行完,开始运行
await promise.then微任务; -
await promise.then微任务完成后,把await语句后面的全部代码加入到微任务行列;
-
-
Node 中的 Event Loop
Node 中的 Event loop 和浏览器中的不相同。
Node 的 Event loop 分为 6 个阶段,它们会按照顺序反复运行
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──connections─── │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
-
timer
timers 阶段会执行
setTimeout和setInterval一个
timer指定的时间并不是准确时间,而是在达到这个时间后尽快执行回调,可能会因为系统正在执行别的事务而延迟。下限的时间有一个范围:
[1, 2147483647],如果设定的时间不在这个范围,将被设置为 1 -
I/O I/O 阶段会执行除了 close 事件,定时器和
setImmediate的回调 -
idel, prepare 阶段内部实现
-
poll
poll 阶段很重要,这一阶段中,系统会做两件事情
- 执行到点的定时器
- 执行 poll 队列中的事件
并且当 poll 中没有定时器的情况下,会发现以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者系统限制
- 如果 poll 队列为空,会有两件事发生
- 如果有
setImmediate需要执行,poll 阶段会停止并且进入到 check 阶段执行setImmediate - 如果没有
setImmediate需要执行,会等待回调被加入到队列中并立即执行回调
- 如果有
如果有别的定时器需要被执行,会回到 timer 阶段执行回调
-
check 阶段执行
setImmediate -
close callbacks 阶段执行 close 事件
并且在 Node 中,有些情况下的定时器执行顺序是随机的
setTimeout(() => { console.log('setTimeout') }, 0) setImmediate(() => { console.log('setImmediate') }) // 这里可能会输出 setTimeout,setImmediate // 可能也会相反的输出,这取决于性能 // 因为可能进入 event loop 用了不到 1 毫秒,这时候会执行 setImmediate // 否则会执行 setTimeout当然在这种情况下,执行顺序是相同的
var fs = require('fs') fs.readFile(__filename, () => { setTimeout(() => { console.log('timeout') }, 0) setImmediate(() => { console.log('immediate') }) }) // 因为 readFile 的回调在 poll 中执行 // 发现有 setImmediate ,所以会立即跳到 check 阶段执行回调 // 再去 timer 阶段执行 setTimeout // 所以以上输出一定是 setImmediate,setTimeout上面介绍的都是 macrotask 的执行情况,microtask 会在以上每个阶段完成后立即执行。
setTimeout(() => { console.log('timer1') Promise.resolve().then(function() { console.log('promise1') }) }, 0) setTimeout(() => { console.log('timer2') Promise.resolve().then(function() { console.log('promise2') }) }, 0) // 以上代码在浏览器和 node 中打印情况是不同的 // 浏览器中一定打印 timer1, promise1, timer2, promise2 // node 中可能打印 timer1, timer2, promise1, promise2 // 也可能打印 timer1, promise1, timer2, promise2Node 中的
process.nextTick会先于其他 microtask 执行。setTimeout(() => { console.log('timer1') Promise.resolve().then(function() { console.log('promise1') }) }, 0) process.nextTick(() => { console.log('nextTick') }) // nextTick, timer1, promise1
22. 对于函数式编程的理解
函数式编程有两个核心概念。
- 数据不可变(无副作用): 它要求你所有的数据都是不可变的,这意味着如果你想修改一个对象,那你应该创建一个新的对象用来修改,而不是修改已有的对象。
- 无状态: 主要是强调对于一个函数,不管你何时运行,它都应该像第一次运行一样,给定相同的输入,给出相同的输出,完全不依赖外部状态的变化。
函数式编程提出函数应该具备的特性:没有副作用和纯函数。
-
没有副作用
副作用的含义是:在完成函数主要功能之外完成的其他副要功能。在我们函数中最主要的功能当然是根据输入返回结果,而在函数中我们最常见的副作用就是随意操纵外部变量。由于 JS 中对象传递的是引用地址,哪怕我们用
const关键词声明对象,它依旧是可以变的。而正是这个“漏洞”让我们有机会随意修改对象。保证函数没有副作用,一来能保证数据的不可变性,二来能避免很多因为共享状态带来的问题。当你一个人维护代码时候可能还不明显,但随着项目的迭代,项目参与人数增加,大家对同一变量的依赖和引用越来越多,这种问题会越来越严重。最终可能连维护者自己都不清楚变量到底是在哪里被改变而产生 Bug。
-
纯函数
- 不依赖外部状态(无状态): 函数的的运行结果不依赖全局变量,this 指针,IO 操作等。
- 没有副作用(数据不变): 不修改全局变量,不修改入参。
- 所以纯函数才是真正意义上的 “函数”, 它意味着 相同的输入,永远会得到相同的输出。
纯函数带来的意义。
- 便于测试和优化:这个意义在实际项目开发中意义非常大,由于纯函数对于相同的输入永远会返回相同的结果,因此我们可以轻松断言函数的执行结果,同时也可以保证函数的优化不会影响其他代码的执行。
- 可缓存性:因为相同的输入总是可以返回相同的输出,因此,我们可以提前缓存函数的执行结果。
- 更少的 Bug:使用纯函数意味着你的函数中不存在指向不明的 this,不存在对全局变量的引用,不存在对参数的修改,这些共享状态往往是绝大多数 bug 的源头。
函数式编程流水线的构建。如果说函数式编程中有两种操作是必不可少的那无疑就是柯里化(Currying)*和*函数组合(Compose),柯里化其实就是流水线上的加工站,函数组合就是我们的流水线,它由多个加工站组成。
-
柯里化 柯里化的意思是将一个多元函数,转换成一个依次调用的单元函数。
f(a,b,c) → f(a)(b)(c)例如 curry 版的 add 函数:
const add = function (x) { return function (y) { x + y; }; }; const increment = add(1); increment(10);柯里化强调的是生成单元函数,部分函数应用的强调的固定任意元参数,而我们平时生活中常用的其实是部分函数应用,这样的好处是可以固定参数,降低函数通用性,提高函数的适合用性。
部分函数应用强调的是固定一定的参数,返回一个更小元的函数。通过以下表达式展示出来就明显了:
// 柯里化 f(a,b,c) → f(a)(b)(c) // 部分函数调用 f(a,b,c) → f(a)(b,c) / f(a,b)(c)// 假设一个通用的请求 API const request = (type, url, options) => ... // GET 请求 request('GET', 'http://....') // POST 请求 request('POST', 'http://....') // 但是通过部分调用后,我们可以抽出特定 type 的 request const get = request('GET'); get('http://', {..})可以用高级柯里化去实现部分函数应用,但是柯里化不等于部分函数应用
-
函数组合 函数组合的目的是将多个函数组合成一个函数
const compose = (f, g) => x => f(g(x)) const f = x => x + 1; const g = x => x * 2; const fg = compose(f, g); fg(1) //3更高级的:
const compose = (...fns) => (...args) => fns.reduceRight((val, fn) => fn.apply(null, [].concat(val)), args); const f = x => x + 1; const g = x => x * 2; const t = (x, y) => x + y; let fgt = compose(f, g, t); fgt(1, 2); // 3 -> 6 -> 7函数组合的好处:函数组合的好处显而易见,它让代码变得简单而富有可读性,同时通过不同的组合方式,我们可以轻易组合出其他常用函数,让我们的代码更具表现力
23. 性能优化
- 代码层面
- 防抖和节流(resize,scroll,input)。
- 减少回流(重排)和重绘。
- 事件委托。
- css 放 ,js 脚本放 最底部。
- 减少 DOM 操作。
- 按需加载,比如 React 中使用
React.lazy和React.Suspense,通常需要与 webpack 中的splitChunks配合。
- 构建方面
- 压缩代码文件,在 webpack 中使用
terser-webpack-plugin压缩 Javascript 代码;使用css-minimizer-webpack-plugin压缩 CSS 代码;使用html-webpack-plugin压缩 html 代码。 - 开启 gzip 压缩,webpack 中使用
compression-webpack-plugin,node 作为服务器也要开启,使用compression。 - 常用的第三方库使用 CDN 服务,在 webpack 中我们要配置 externals,将比如 React, Vue 这种包不打倒最终生成的文件中。而是采用 CDN 服务。
- 压缩代码文件,在 webpack 中使用
- 其他方面
- 使用 http2。因为解析速度快,头部压缩,多路复用,服务器推送静态资源。
- 使用服务端渲染。
- 图片压缩。
- 使用 http 缓存,比如服务端的响应中添加
Cache-Control / Expires。
24. 词法作用域和动态作用域
-
作用域
作用域是指程序源代码中定义变量的区域。
作用域规定了如何查找变量,也就是确定当前执行代码对变量的访问权限。
JavaScript 采用词法作用域(lexical scoping),也就是静态作用域
-
静态作用域和动态作用域
因为 JavaScript 采用的是词法作用域,函数的作用域在函数定义的时候就决定了。
而与词法作用域相对的是动态作用域,函数的作用域是在函数调用的时候才决定的。
让我们认真看个例子就能明白之间的区别:
var value = 1; function foo() { console.log(value); } function bar() { var value = 2; foo(); } bar(); // 结果是 1假设JavaScript采用静态作用域,让我们分析下执行过程:
执行 foo 函数,先从 foo 函数内部查找是否有局部变量 value,如果没有,就根据书写的位置,查找上面一层的代码,也就是 value 等于 1,所以结果会打印 1。
假设JavaScript采用动态作用域,让我们分析下执行过程:
执行 foo 函数,依然是从 foo 函数内部查找是否有局部变量 value。如果没有,就从调用函数的作用域,也就是 bar 函数内部查找 value 变量,所以结果会打印 2。
前面我们已经说了,JavaScript采用的是静态作用域,所以这个例子的结果是 1。
-
动态作用域
bash 就是动态作用域,不信的话,把下面的脚本存成例如 scope.bash,然后进入相应的目录,用命令行执行
bash ./scope.bash,看看打印的值是多少。value=1 function foo () { echo $value; } function bar () { local value=2; foo; } bar -
思考
最后,让我们看一个《JavaScript权威指南》中的例子:
var scope = "global scope"; function checkscope(){ var scope = "local scope"; function f(){ return scope; } return f(); } checkscope();var scope = "global scope"; function checkscope(){ var scope = "local scope"; function f(){ return scope; } return f; } checkscope()();两段代码都会打印:
local scope。原因也很简单,因为JavaScript采用的是词法作用域,函数的作用域基于函数创建的位置。
而引用《JavaScript权威指南》的回答就是:
JavaScript 函数的执行用到了作用域链,这个作用域链是在函数定义的时候创建的。嵌套的函数 f() 定义在这个作用域链里,其中的变量 scope 一定是局部变量,不管何时何地执行函数 f(),这种绑定在执行 f() 时依然有效。
25. 浮点数精度
0.1 + 0.2 是否等于 0.3 作为一道经典的面试题,已经广外熟知,说起原因,大家能回答出这是浮点数精度问题导致,也能辩证的看待这并非是 ECMAScript 这门语言的问题,今天就是具体看一下背后的原因。
ECMAScript 中的 Number 类型使用 IEEE754 标准来表示整数和浮点数值。所谓 IEEE754 标准,全称 IEEE 二进制浮点数算术标准,这个标准定义了表示浮点数的格式等内容。
在 IEEE754 中,规定了四种表示浮点数值的方式:
- 单精确度(32位)
- 双精确度(64位)
- 延伸单精确度
- 延伸双精确度。
像 ECMAScript 采用的就是双精确度,也就是说,会用 64 位来储存一个浮点数。
浮点数转二进制
-
例如 1020 用十进制表示为:
\[1020 = 1\times10^3 + 0\times10^2 + 2\times10^1 + 0\times10^0 \]二进制表示为:
\[1020 = 1111111100=1\times2^9 + 1\times2^8 +1\times2^7+1\times2^6 + 1\times2^5 + \\ 1\times2^4 + 1\times2^3 + 1\times2^2 + 0\times2^1 + 0\times2^0 \]而 0.75 的二进制为:
\[0.75 = a\times2^{-1} + b\times2^{-2} + c\times2^{-3} + d\times2^{-4} + \dots \]可以通过将等式两边不断乘以 2 计算出来
a, b, c,d ...\[1+0.5=a + b\times2^{-1} + c\times2^{-2} + d\times2^{-3} + \dots \rightarrow a=1 \]\[1 = b + c\times2^{-1} + d\times2^{-2} + \dots \rightarrow b = 1, c=d=0 \]所以 0.75 转换为二进制就为 0.11
但是 0.1 转换成一个二进制就是一个无限循环的数 0.00011001100110011……
浮点数的储存
IEE754 规定一个浮点数 Value可以这样表示(即科学计数法):
而当只做二进制科学计数法的表示时,这个 Value 的表示可以再具体一点变成:
-
\((-1)^S\) 表示符号位,当 S = 0,V 为正数;当 S = 1,V 为负数
-
\(1+fraction\) 所有的浮点数都可以表示为 1.xxxx * 2^xxx 的形式,前面的一定是 1.xxx,那干脆我们就不存储这个 1 了,直接存后面的 xxxxx 好了,这也就是 Fraction 的部分。
-
\(2^E\)
如果是 1020.75,对应二进制数就是 1111111100.11,对应二进制科学计数法就是 1 * 1.11111110011 * 2^9,E 的值就是 9,而如果是 0.1 ,对应二进制是 1 * 1.1001100110011…… * 2^-4, E 的值就是 -4,也就是说,E 既可能是负数,又可能是正数,那问题就来了,那我们该怎么储存这个 E 呢?
我们这样解决,假如我们用 8 位来存储 E 这个数,如果只有正数的话,储存的值的范围是 0 ~ 254,而如果要储存正负数的话,值的范围就是 -127~127,我们在存储的时候,把要存储的数字加上 127,这样当我们存 -127 的时候,我们存 0,当存 127 的时候,存 254,这样就解决了存负数的问题。对应的,当取值的时候,我们再减去 127。
所以呢,真到实际存储的时候,我们并不会直接存储 E,而是会存储 E + bias,当用 8 位的时候,这个 bias 就是 127。
所以,如果要存储一个浮点数,我们存 S 和 Fraction 和 E + bias 这三个值就好了,那具体要分配多少个位来存储这些数呢?IEEE754 给出了标准:
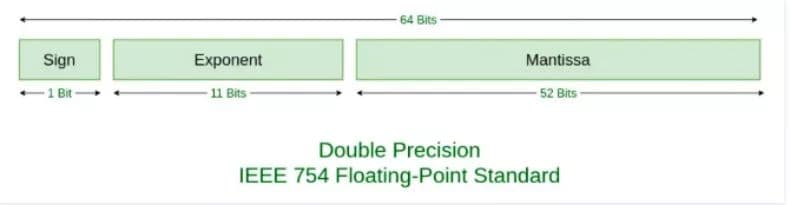
在这个标准下:
我们会用 1 位存储 S,0 表示正数,1 表示负数。
用 11 位存储 E + bias,对于 11 位来说,bias 的值是 2^(11-1) - 1,也就是 1023。
用 52 位存储 Fraction。
浮点数运算
关于浮点数的运算,一般由以下五个步骤完成:对阶、尾数运算、规格化、舍入处理、溢出判断。我们来简单看一下 0.1 和 0.2 的计算。
首先是对阶,所谓对阶,就是把阶码调整为相同,比如 0.1 是 1.1001100110011…… * 2^-4,阶码是 -4,而 0.2 就是 1.10011001100110...* 2^-3,阶码是 -3,两个阶码不同,所以先调整为相同的阶码再进行计算,调整原则是小阶对大阶,也就是 0.1 的 -4 调整为 -3,对应变成 0.11001100110011…… * 2^-3
接下来是尾数计算:
0.1100110011001100110011001100110011001100110011001101
+ 1.1001100110011001100110011001100110011001100110011010
————————————————————————————————————————————————————————
10.0110011001100110011001100110011001100110011001100111
我们得到结果为 \(10.0110011001100110011001100110011001100110011001100111 \times 2^{-3}\)
将这个结果处理一下,即结果规格化,变成 \(1.0011001100110011001100110011001100110011001100110011(1) \times 2^{-2}\)
括号里的 1 意思是说计算后这个 1 超出了范围,所以要被舍弃了。
再然后是舍入,四舍五入对应到二进制中,就是 0 舍 1 入,因为我们要把括号里的 1 丢了,所以这里会进一,结果变成
1.0011001100110011001100110011001100110011001100110100 * 2^-2
所以最终的结果存成 64 位就是
0 01111111101 0011001100110011001100110011001100110011001100110100
将它转换为10进制数就得到 0.30000000000000004440892098500626
因为两次存储时的精度丢失加上一次运算时的精度丢失,最终导致了 0.1 + 0.2 !== 0.3
JS 中的转换
-
十进制转二进制
// 十进制转二进制 parseFloat(0.1).toString(2); => "0.0001100110011001100110011001100110011001100110011001101" -
二进制转十进制
// 二进制转十进制 parseInt(1100100,2) => 100 -
以指定的进度返回该数值对象的字符串表示
// 以指定的精度返回该数值对象的字符串表示 (0.1 + 0.2).toPrecision(21) => "0.300000000000000044409" (0.3).toPrecision(21) => "0.299999999999999988898"
26. Virtual DOM 的优势在哪里
「Virtual Dom 的优势」其实这道题目面试官更想听到的答案不是上来就说「直接操作/频繁操作 DOM 的性能差」,如果 DOM 操作的性能如此不堪,那么 jQuery 也不至于活到今天。所以面试官更想听到 VDOM 想解决的问题以及为什么频繁的 DOM 操作会性能差。
首先我们需要知道:
DOM 引擎、JS 引擎 相互独立,但又工作在同一线程(主线程)
JS 代码调用 DOM API 必须 挂起 JS 引擎、转换传入参数数据、激活 DOM 引擎,DOM 重绘后再转换可能有的返回值,最后激活 JS 引擎并继续执行若有频繁的 DOM API 调用,且浏览器厂商不做“批量处理”优化, 引擎间切换的单位代价将迅速积累若其中有强制重绘的 DOM API 调用,重新计算布局、重新绘制图像会引起更大的性能消耗。
其次是 VDOM 和真实 DOM 的区别和优化:
- 虚拟 DOM 不会立马进行排版与重绘操作
- 虚拟 DOM 进行频繁修改,然后一次性比较并修改真实 DOM 中需要改的部分,最后在真实 DOM 中进行排版与重绘,减少过多DOM节点排版与重绘损耗
- 虚拟 DOM 有效降低大面积真实 DOM 的重绘与排版,因为最终与真实 DOM 比较差异,可以只渲染局部
27 类型转换
将值从一种类型转换为另一种类型通常称为类型转换。
ES6 前,JavaScript 共有六种数据类型:Undefined、Null、Boolean、Number、String、Object。
27.1 基本类型之间的转换
27.1.1 原始值转布尔值
我们使用 Boolean 函数将类型转换成布尔类型,在 JavaScript 中,只有 6 种值 undefined, null, +0, -0, NaN, "" 可以被转换成 false,其他都会被转换成 true。
console.log(Boolean()) // false
console.log(Boolean(false)) // false
console.log(Boolean(undefined)) // false
console.log(Boolean(null)) // false
console.log(Boolean(+0)) // false
console.log(Boolean(-0)) // false
console.log(Boolean(NaN)) // false
console.log(Boolean("")) // false
注意,当 Boolean 函数不传任何参数时,会返回 false。
27.1.2 原始值转数字
我们可以使用 Number 函数将类型转换成数字类型,如果参数无法被转换为数字,则返回 NaN。

根据规范,如果 Number 函数不传参数,返回 +0,如果有参数,调用 ToNumber(value)。
注意这个 ToNumber 表示的是一个底层规范实现上的方法,并没有直接暴露出来。
而 ToNumber 则直接给了一个对应的结果表。表如下:
| 参数类型 | 结果 |
|---|---|
| Undefined | NaN |
| Null | +0 |
| Boolean | 如果参数是 true,返回 1。参数为 false,返回 +0 |
| Number | 返回与之相等的值 |
| String | 这段比较复杂,看例子 |
console.log(Number()) // +0
console.log(Number(undefined)) // NaN
console.log(Number(null)) // +0
console.log(Number(false)) // +0
console.log(Number(true)) // 1
console.log(Number("123")) // 123
console.log(Number("-123")) // -123
console.log(Number("1.2")) // 1.2
console.log(Number("000123")) // 123
console.log(Number("-000123")) // -123
console.log(Number("0x11")) // 17
console.log(Number("")) // 0
console.log(Number(" ")) // 0
console.log(Number("123 123")) // NaN
console.log(Number("foo")) // NaN
console.log(Number("100a")) // NaN
如果通过 Number 转换函数传入一个字符串,它会试图将其转换成一个整数或浮点数,而且会忽略所有前导的 0,如果有一个字符不是数字,结果都会返回 NaN,鉴于这种严格的判断,我们一般还会使用更加灵活的 parseInt 和 parseFloat 进行转换。
parseInt 只解析整数,parseFloat 则可以解析整数和浮点数,如果字符串前缀是 "0x" 或者"0X",parseInt 将其解释为十六进制数,parseInt 和 parseFloat 都会跳过任意数量的前导空格,尽可能解析更多数值字符,并忽略后面的内容。如果第一个非空格字符是非法的数字直接量,将最终返回 NaN:
console.log(parseInt("3 abc")) // 3
console.log(parseFloat("3.14 abc")) // 3.14
console.log(parseInt("-12.34")) // -12
console.log(parseInt("0xFF")) // 255
console.log(parseFloat(".1")) // 0.1
console.log(parseInt("0.1")) // 0
27.1.3 原始值转字符
我们使用 String 函数将类型转换成字符串类型,依然先看 规范15.5.1.1中有关 String 函数的介绍:
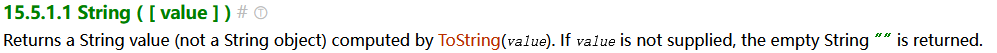
如果 String 函数不传参数,返回空字符串,如果有参数,调用 ToString(value),而 ToString 也给了一个对应的结果表。表如下:
| 参数类型 | 结果 |
|---|---|
| Undefined | "undefined" |
| Null | "null" |
| Boolean | 如果参数是 true,返回 "true"。参数为 false,返回 "false" |
| Number | 又是比较复杂,可以看例子 |
| String | 返回与之相等的值 |
console.log(String()) // 空字符串
console.log(String(undefined)) // undefined
console.log(String(null)) // null
console.log(String(false)) // false
console.log(String(true)) // true
console.log(String(0)) // 0
console.log(String(-0)) // 0
console.log(String(NaN)) // NaN
console.log(String(Infinity)) // Infinity
console.log(String(-Infinity)) // -Infinity
console.log(String(1)) // 1
注意这里的 ToString 和上一节的 ToNumber 都是底层规范实现的方法,并没有直接暴露出来。
27.1.4 原始值转对象
原始值到对象的转换非常简单,原始值通过调用 String()、Number() 或者 Boolean() 构造函数,转换为它们各自的包装对象。
null 和 undefined 属于例外,当将它们用在期望是一个对象的地方都会造成一个类型错误 (TypeError) 异常,而不会执行正常的转换。
var a = 1;
console.log(typeof a); // number
var b = new Number(a);
console.log(typeof b); // object
27.1.5 对象转布尔值
对象到布尔值的转换非常简单:所有对象(包括数组和函数)都转换为 true。对于包装对象也是这样,举个例子:
console.log(Boolean(new Boolean(false))) // true
27.1.6 对象转字符串和数字
对象到字符串和对象到数字的转换都是通过调用待转换对象的一个方法来完成的。而 JavaScript 对象有两个不同的方法来执行转换,一个是 toString,一个是 valueOf。注意这个跟上面所说的 ToString 和 ToNumber 是不同的,这两个方法是真实暴露出来的方法。
所有的对象除了 null 和 undefined 之外的任何值都具有 toString 方法,通常情况下,它和使用 String 方法返回的结果一致。toString 方法的作用在于返回一个反映这个对象的字符串,然而这才是情况复杂的开始。
Object.prototype.toString 方法会根据这个对象的[[class]]内部属性,返回由 "[object " 和 class 和 "]" 三个部分组成的字符串。举个例子:
Object.prototype.toString.call({a: 1}) // "[object Object]"
({a: 1}).toString() // "[object Object]"
({a: 1}).toString === Object.prototype.toString // true
我们可以看出当调用对象的 toString 方法时,其实调用的是 Object.prototype 上的 toString 方法。
然而 JavaScript 下的很多类根据各自的特点,定义了更多版本的 toString 方法。例如:
- 数组的 toString 方法将每个数组元素转换成一个字符串,并在元素之间添加逗号后合并成结果字符串。
- 函数的 toString 方法返回源代码字符串。
- 日期的 toString 方法返回一个可读的日期和时间字符串。
- RegExp 的 toString 方法返回一个表示正则表达式直接量的字符串。
console.log(({}).toString()) // [object Object]
console.log([].toString()) // ""
console.log([0].toString()) // 0
console.log([1, 2, 3].toString()) // 1,2,3
console.log((function(){var a = 1;}).toString()) // function (){var a = 1;}
console.log((/\d+/g).toString()) // /\d+/g
console.log((new Date(2010, 0, 1)).toString()) // Fri Jan 01 2010 00:00:00 GMT+0800 (CST)
而另一个转换对象的函数是 valueOf,表示对象的原始值。默认的 valueOf 方法返回这个对象本身,数组、函数、正则简单的继承了这个默认方法,也会 返回对象本身。日期是一个例外,它会返回它的一个内容表示: 1970 年 1 月 1 日以来的毫秒数。
console.log([1, 2, 3].valueOf()); // [1, 2, 3]
console.log((()=>{}).valueOf()); // ()=>{}
console.log((/\d+/g).valueOf()); // /\d+/g
var date = new Date(2017, 4, 21);
console.log(date.valueOf()) // 1495296000000
了解了 toString 方法和 valueOf 方法,我们分析下从对象到字符串是如何转换的。看规范 ES5 9.8,其实就是 ToString 方法的对应表,只是这次我们加上 Object 的转换规则:
| 参数类型 | 结果 |
|---|---|
| Object | 1. primValue = ToPrimitive(input, String) 2. 返回ToString(primValue). |
所谓的 ToPrimitive 方法,其实就是输入一个值,然后返回一个一定是基本类型的值。
我们总结一下,当我们用 String 方法转化一个值的时候,如果是基本类型,就参照 “原始值转字符” 这一节的对应表,如果不是基本类型,我们会将调用一个 ToPrimitive 方法,将其转为基本类型,然后再参照“原始值转字符” 这一节的对应表进行转换。
对象到数字的转换也是一样:
| 参数类型 | 结果 |
|---|---|
| Object | 1. primValue = ToPrimitive(input, Number) 2. 返回ToNumber(primValue)。 |
虽然转换成基本值都会使用 ToPrimitive 方法,但传参有不同,最后的处理也有不同,转字符串调用的是 ToString,转数字调用 ToNumber。
-
ToPrimitive
那接下来就要看看 ToPrimitive 了,在了解了 toString 和 valueOf 方法后,这个也很简单。
让我们看规范 9.1,函数语法表示如下:
ToPrimitive(input[, PreferredType])第一个参数是 input,表示要处理的输入值。
第二个参数是 PreferredType,非必填,表示希望转换成的类型,有两个值可以选,Number 或者 String。
当不传入 PreferredType 时,如果 input 是日期类型,相当于传入 String,否则,都相当于传入 Number。
如果传入的 input 是 Undefined、Null、Boolean、Number、String 类型,直接返回该值。
-
如果是 ToPrimitive(obj, Number),处理步骤如下:
- 如果 obj 为 基本类型,直接返回
- 否则,调用 valueOf 方法,如果返回一个原始值,则 JavaScript 将其返回。
- 否则,调用 toString 方法,如果返回一个原始值,则 JavaScript 将其返回。
- 否则,JavaScript 抛出一个类型错误异常。
-
如果是 ToPrimitive(obj, String),处理步骤如下:
- 如果 obj为 基本类型,直接返回
- 否则,调用 toString 方法,如果返回一个原始值,则 JavaScript 将其返回。
- 否则,调用 valueOf 方法,如果返回一个原始值,则 JavaScript 将其返回。
- 否则,JavaScript 抛出一个类型错误异常。
-
对象转字符串
所以总结下,对象转字符串(就是 Number() 函数)可以概括为:
- 如果对象具有 toString 方法,则调用这个方法。如果他返回一个原始值,JavaScript 将这个值转换为字符串,并返回这个字符串结果。
- 如果对象没有 toString 方法,或者这个方法并不返回一个原始值,那么 JavaScript 会调用 valueOf 方法。如果存在这个方法,则 JavaScript 调用它。如果返回值是原始值,JavaScript 将这个值转换为字符串,并返回这个字符串的结果。
- 否则,JavaScript 无法从 toString 或者 valueOf 获得一个原始值,这时它将抛出一个类型错误异常。
对象转数字
对象转数字的过程中,JavaScript 做了同样的事情,只是它会首先尝试 valueOf 方法
- 如果对象具有 valueOf 方法,且返回一个原始值,则 JavaScript 将这个原始值转换为数字并返回这个数字
- 否则,如果对象具有 toString 方法,且返回一个原始值,则 JavaScript 将其转换并返回。
- 否则,JavaScript 抛出一个类型错误异常。
console.log(Number({})) // NaN
console.log(Number({a : 1})) // NaN
console.log(Number([])) // 0
console.log(Number([0])) // 0
console.log(Number([1, 2, 3])) // NaN
console.log(Number(function(){var a = 1;})) // NaN
console.log(Number(/\d+/g)) // NaN
console.log(Number(new Date(2010, 0, 1))) // 1262275200000
console.log(Number(new Error('a'))) // NaN
注意,在这个例子中,[] 和 [0] 都返回了 0,而 [1, 2, 3] 却返回了一个 NaN。我们分析一下原因:
当我们 Number([]) 的时候,先调用 [] 的 valueOf 方法,此时返回 [],因为返回了一个对象而不是原始值,所以又调用了 toString 方法,此时返回一个空字符串,接下来调用 ToNumber 这个规范上的方法,参照对应表,转换为 0, 所以最后的结果为 0。
而当我们 Number([1, 2, 3]) 的时候,先调用 [1, 2, 3] 的 valueOf 方法,此时返回 [1, 2, 3],再调用 toString 方法,此时返回 1,2,3,接下来调用 ToNumber,参照对应表,因为无法转换为数字,所以最后的结果为 NaN。
27.1.7 JSON.stringify
值得一提的是:JSON.stringify() 方法可以将一个 JavaScript 值转换为一个 JSON 字符串,实现上也是调用了 toString 方法,也算是一种类型转换的方法。下面讲一讲JSON.stringify 的注意要点:
-
处理基本类型时,与使用toString基本相同,结果都是字符串,除了
undefinedconsole.log(JSON.stringify(null)) // null console.log(JSON.stringify(undefined)) // undefined,注意这个undefined不是字符串的undefined console.log(JSON.stringify(true)) // true console.log(JSON.stringify(42)) // 42 console.log(JSON.stringify("42")) // "42" -
布尔值、数字、字符串的包装对象在序列化过程中会自动转换成对应的原始值。
JSON.stringify([new Number(1), new String("false"), new Boolean(false)]); // "[1,"false",false]" -
undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成 null(出现在数组中时)。
JSON.stringify({x: undefined, y: Object, z: Symbol("")}); // "{}" JSON.stringify([undefined, Object, Symbol("")]); // "[null,null,null]" -
JSON.stringify 有第二个参数 replacer,它可以是数组或者函数,用来指定对象序列化过程中哪些属性应该被处理,哪些应该被排除。
function replacer(key, value) { if (typeof value === "string") { return undefined; } return value; } var foo = {foundation: "Mozilla", model: "box", week: 45, transport: "car", month: 7}; var jsonString = JSON.stringify(foo, replacer); console.log(jsonString) // {"week":45,"month":7}var foo = {foundation: "Mozilla", model: "box", week: 45, transport: "car", month: 7}; console.log(JSON.stringify(foo, ['week', 'month'])); // {"week":45,"month":7} -
如果一个被序列化的对象拥有 toJSON 方法,那么该 toJSON 方法就会覆盖该对象默认的序列化行为:不是那个对象被序列化,而是调用 toJSON 方法后的返回值会被序列化,例如:
var obj = { foo: 'foo', toJSON: function () { return 'bar'; } }; JSON.stringify(obj); // '"bar"' JSON.stringify({x: obj}); // '{"x":"bar"}'
27.2 一元操作符 +
console.log(+'1');
当 + 运算符作为一元操作符的时候,查看 ES5规范1.4.6,会调用 ToNumber 处理该值,相当于 Number('1'),最终结果返回数字 1。
那么下面的这些结果呢?
console.log(+[]);
console.log(+['1']);
console.log(+['1', '2', '3']);
console.log(+{});
当输入的值是对象的时候,先调用 ToPrimitive(input, Number) 方法,执行的步骤是:
- 如果
obj为基本类型,直接返回 - 否则,调用
valueOf方法,如果返回一个原始值,则JavaScript将其返回。 - 否则,调用
toString方法,如果返回一个原始值,则JavaScript将其返回。 - 否则,
JavaScript抛出一个类型错误异常。
以 +[] 为例,[] 调用 valueOf 方法,返回一个空数组,因为不是原始值,调用 toString 方法,返回 ""。
得到返回值后,然后再调用 ToNumber 方法,"" 对应的返回值是 0,所以最终返回 0。
剩下的例子以此类推。结果是:
console.log(+['1']); // 1
console.log(+['1', '2', '3']); // NaN
console.log(+{}); // NaN
27.3 二元操作符 +
现在 + 运算符又变成了二元操作符,毕竟它也是加减乘除中的加号
1 + '1' 我们知道答案是 '11',那 null + 1、[] + []、[] + {}、{} + {} 呢?
当计算 value1 + value2时:
- lprim = ToPrimitive(value1)
- rprim = ToPrimitive(value2)
- 如果 lprim 是字符串或者 rprim 是字符串,那么返回 ToString(lprim) 和 ToString(rprim)的拼接结果
- 返回 ToNumber(lprim) 和 ToNumber(rprim)的运算结果
-
Null 与数字
console.log(null + 1);按照规范的步骤进行分析:
- lprim = ToPrimitive(null) 因为null是基本类型,直接返回,所以 lprim = null
- rprim = ToPrimitive(1) 因为 1 是基本类型,直接返回,所以 rprim = null
- lprim 和 rprim 都不是字符串
- 返回 ToNumber(null) 和 ToNumber(1) 的运算结果
接下来:
ToNumber(null)的结果为0,(回想上篇 Number(null)),ToNumber(1)的结果为 1所以,
null + 1相当于0 + 1,最终的结果为数字1。 -
数组与数组
console.log([] + []);依然按照规范:
- lprim = ToPrimitive([]),[]是数组,相当于ToPrimitive([], Number),先调用valueOf方法,返回对象本身,因为不是原始值,调用toString方法,返回空字符串""
- rprim类似。
- lprim和rprim都是字符串,执行拼接操作
所以,
[] + []相当于"" + "",最终的结果是空字符串""。 -
数组与对象
// 两者结果一致 console.log([] + {}); console.log({} + []);按照规范:
- lprim = ToPrimitive([]),lprim = ""
- rprim = ToPrimitive({}),相当于调用 ToPrimitive({}, Number),先调用 valueOf 方法,返回对象本身,因为不是原始值,调用 toString 方法,返回 "[object Object]"
- lprim 和 rprim 都是字符串,执行拼接操作
所以,
[] + {}相当于"" + "[object Object]",最终的结果是 "[object Object]"。下面的例子,可以按照示例类推出结果:
console.log(1 + true); console.log({} + {}); console.log(new Date(2017, 04, 21) + 1) // 这个知道是数字还是字符串类型就行结果是:
console.log(1 + true); // 2 console.log({} + {}); // "[object Object][object Object]" console.log(new Date(2017, 04, 21) + 1) // "Sun May 21 2017 00:00:00 GMT+0800 (CST)1"
28. 比较箭头函数与普通函数
箭头函数
箭头函数表达式的语法比函数表达式更短,并且不绑定自己的this,arguments,super或 new.target。这些函数表达式最适合用于非方法函数(non-method functions),并且它们不能用作构造函数。
28.1 没有 this
箭头函数没有 this,所以需要通过查找作用域链来确定 this 的值。
这就意味着如果箭头函数被非箭头函数包含,this 绑定的就是最近一层非箭头函数的 this。
因为箭头函数没有 this,所以也不能用 call()、apply()、bind() 这些方法改变 this 的指向:
var value = 1;
var result = (() => this.value).bind({value: 2})();
console.log(result); // 1
28.2 没有 arguments
箭头函数没有自己的 arguments 对象,这不一定是件坏事,因为箭头函数可以访问外围函数的 arguments 对象:
function constant() {
return () => arguments[0]
}
var result = constant(1);
console.log(result()); // 1
那如果我们就是要访问箭头函数的参数呢?
你可以通过命名参数或者 rest 参数的形式访问参数:
let nums = (...nums) => nums;
28.3 不能通过 new 关键字调用
JavaScript 函数有两个内部方法:[[Call]] 和 [[Construct]]。
当通过 new 调用函数时,执行 [[Construct]] 方法,创建一个实例对象,然后再执行函数体,将 this 绑定到实例上。
当直接调用的时候,执行 [[Call]] 方法,直接执行函数体。
箭头函数并没有 [[Construct]] 方法,不能被用作构造函数,如果通过 new 的方式调用,会报错。
var Foo = () => {};
var foo = new Foo(); // TypeError: Foo is not a constructor

28.4 没有 new.target
因为不能使用 new 调用,所以也没有 new.target 值。
28.5 没有原型
由于不能使用 new 调用箭头函数,所以也没有构建原型的需求,于是箭头函数也不存在 prototype 这个属性。
var Foo = () => {};
console.log(Foo.prototype); // undefined
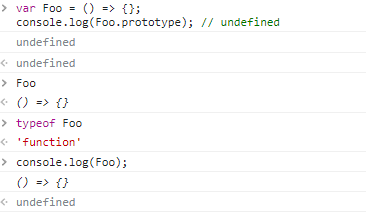
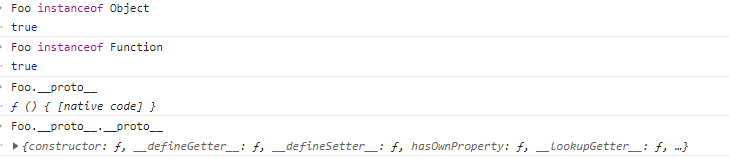
28.6 没有 super
连原型都没有,自然也不能通过 super 来访问原型的属性,所以箭头函数也是没有 super 的,不过跟 this、arguments、new.target 一样,这些值由外围最近一层非箭头函数决定。
29. 模块加载方案
29.1 require.js
在了解 AMD 规范之前,我们先来看看 require.js 的使用方式。
项目目录为:
* project/
* index.html
* vender/
* main.js
* require.js
* add.js
* square.js
* multiply.js
index.html 的内容如下:
<!DOCTYPE html>
<html>
<head>
<title>require.js</title>
</head>
<body>
<h1>Content</h1>
<script data-main="vender/main" src="vender/require.js"></script>
</body>
</html>
data-main="vender/main" 表示主模块是 vender 下的 main.js。
main.js 的配置如下:
// main.js
require(['./add', './square'], function(addModule, squareModule) {
console.log(addModule.add(1, 1))
console.log(squareModule.square(3))
});
require 的第一个参数表示依赖的模块的路径,第二个参数表示此模块的内容。
由此可以看出,主模块依赖 add 模块和 square 模块。
我们看下 add 模块即 add.js 的内容:
// add.js
define(function() {
console.log('加载了 add 模块');
var add = function(x, y) {
return x + y;
};
return {
add: add
};
});
requirejs 为全局添加了 define 函数,你只要按照这种约定的方式书写这个模块即可。
那如果依赖的模块又依赖了其他模块呢?
我们来看看主模块依赖的 square 模块, square 模块的作用是求出一个数字的平方,比如输入 3 就返回 9,该模块依赖一个乘法模块,该乘法模块即 multiply.js 的代码如下:
// multiply.js
define(function() {
console.log('加载了 multiply 模块')
var multiply = function(x, y) {
return x * y;
};
return {
multiply: multiply
};
});
而 square 模块就要用到 multiply 模块,其实写法跟 main.js 添加依赖模块一样:
// square.js
define(['./multiply'], function(multiplyModule) {
console.log('加载了 square 模块')
return {
square: function(num) {
return multiplyModule.multiply(num, num)
}
};
});
require.js 会自动分析依赖关系,将需要加载的模块正确加载。
而如果我们在浏览器中打开 index.html,打印的顺序为:
加载了 add 模块
加载了 multiply 模块
加载了 square 模块
2
9
29.2 AMD
requirejs为全局添加了define函数,你只要按照这种约定的方式书写这个模块即可。
那这个约定的书写方式是指什么呢?
指的便是 The Asynchronous Module Definition (AMD) 规范。
所以其实 AMD 是 RequireJS 在推广过程中对模块定义的规范化产出。
你去看 AMD 规范 的内容,其主要内容就是定义了 define 函数该如何书写,只要你按照这个规范书写模块和依赖,require.js 就能正确的进行解析。
AMD规范采用异步方式加载模块,模块的加载不影响它后面语句的运行。
所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
这里介绍用require.js实现AMD规范的模块化:用require.config()指定引用路径等,用define()定义模块,用require()加载模块。
29.3 sea.js
在国内,经常与 AMD 被一起提起的还有 CMD,CMD 又是什么呢?我们从 sea.js 的使用开始说起。
文件目录与 requirejs 项目目录相同:
* project/
* index.html
* vender/
* main.js
* require.js
* add.js
* square.js
* multiply.js
index.html 的内容如下:
<!DOCTYPE html>
<html>
<head>
<title>sea.js</title>
</head>
<body>
<h1>Content</h1>
<script src="vender/sea.js"></script>
<script>
// 在页面中加载主模块
seajs.use("./vender/main");
</script>
</body>
</html>
main.js 的内容如下:
// main.js
define(function(require, exports, module) {
var addModule = require('./add');
console.log(addModule.add(1, 1))
var squareModule = require('./square');
console.log(squareModule.square(3))
});
add.js 的内容如下:
// add.js
define(function(require, exports, module) {
console.log('加载了 add 模块')
var add = function(x, y) {
return x + y;
};
module.exports = {
add: add
};
});
square.js 的内容如下:
define(function(require, exports, module) {
console.log('加载了 square 模块')
var multiplyModule = require('./multiply');
module.exports = {
square: function(num) {
return multiplyModule.multiply(num, num)
}
};
});
multiply.js 的内容如下:
define(function(require, exports, module) {
console.log('加载了 multiply 模块')
var multiply = function(x, y) {
return x * y;
};
module.exports = {
multiply: multiply
};
});
跟第一个例子是同样的依赖结构,即 main 依赖 add 和 square,square 又依赖 multiply。
而如果我们在浏览器中打开 index.html,打印的顺序为:
加载了 add 模块
2
加载了 square 模块
加载了 multiply 模块
9
29.4 CMD
与 AMD 一样,CMD 其实就是 SeaJS 在推广过程中对模块定义的规范化产出。
你去看 CMD 规范的内容,主要内容就是描述该如何定义模块,如何引入模块,如何导出模块,只要你按照这个规范书写代码,sea.js 就能正确的进行解析。
AMD 与 CMD 的区别
从 sea.js 和 require.js 的例子可以看出:
-
CMD 推崇 依赖就近,AMD 推崇 依赖前置。看两个项目中的 main.js:
// require.js 例子中的 main.js // 依赖必须一开始就写好 require(['./add', './square'], function(addModule, squareModule) { console.log(addModule.add(1, 1)) console.log(squareModule.square(3)) });// sea.js 例子中的 main.js define(function(require, exports, module) { var addModule = require('./add'); console.log(addModule.add(1, 1)) // 依赖可以就近书写 var squareModule = require('./square'); console.log(squareModule.square(3)) }); -
对于依赖的模块,AMD 是 提前执行,CMD 是 延迟执行。看两个项目中的打印顺序:
// require.js 加载了 add 模块 加载了 multiply 模块 加载了 square 模块 2 9// sea.js 加载了 add 模块 2 加载了 square 模块 加载了 multiply 模块 9
AMD 是将需要使用的模块先加载完再执行代码,而 CMD 是在 require 的时候才去加载模块文件,加载完再接着执行。
29.5 CommonJS
AMD 和 CMD 都是用于浏览器端的模块规范,而在服务器端比如 node,采用的则是 CommonJS 规范。
Node.js是commonJS规范的主要实践者,它有四个重要的环境变量为模块化的实现提供支持:module、exports、require、global。实际使用时,用module.exports 定义当前模块对外输出的接口(不推荐直接用exports),用require加载模块。
CommonJS用同步的方式加载模块。
在服务端,模块文件都存在本地磁盘,读取非常快,所以这样做不会有问题。
但是在浏览器端,限于网络原因,更合理的方案是使用异步加载。
导出模块的方式:
var add = function(x, y) {
return x + y;
};
module.exports.add = add;
引入模块的方式:
var add = require('./add.js');
console.log(add.add(1, 1));
我们将之前的例子改成 CommonJS 规范:
// main.js
var add = require('./add.js');
console.log(add.add(1, 1))
var square = require('./square.js');
console.log(square.square(3));
// add.js
console.log('加载了 add 模块')
var add = function(x, y) {
return x + y;
};
module.exports.add = add;
// multiply.js
console.log('加载了 multiply 模块')
var multiply = function(x, y) {
return x * y;
};
module.exports.multiply = multiply;
// square.js
console.log('加载了 square 模块')
var multiply = require('./multiply.js');
var square = function(num) {
return multiply.multiply(num, num);
};
module.exports.square = square;
如果我们执行 node main.js,打印的顺序为:
加载了 add 模块
2
加载了 square 模块
加载了 multiply 模块
9
跟 sea.js 的执行结果一致,也是在 require 的时候才去加载模块文件,加载完再接着执行。
CommonJS 与 AMD
引用阮一峰老师的《JavaScript 标准参考教程(alpha)》:
CommonJS 规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。
AMD规范则是非同步加载模块,允许指定回调函数。
由于 Node.js 主要用于服务器编程,模块文件一般都已经存在于本地硬盘,所以加载起来比较快,不用考虑非同步加载的方式,所以 CommonJS 规范比较适用。
但是,如果是浏览器环境,要从服务器端加载模块,这时就必须采用非同步模式,因此浏览器端一般采用 AMD 规范。
29.6 ES6
ECMAScript2015 规定了新的模块加载方案。
导出模块的方式:
var firstName = 'Michael';
var lastName = 'Jackson';
var year = 1958;
export {firstName, lastName, year};
引入模块的方式:
import {firstName, lastName, year} from './profile';
我们再将上面的例子改成 ES6 规范:
目录结构与 requirejs 和 seajs 目录结构一致。
<!DOCTYPE html>
<html>
<head>
<title>ES6</title>
</head>
<body>
<h1>Content</h1>
<script src="vender/main.js" type="module"></script>
</body>
</html>
注意!浏览器加载 ES6 模块,也使用 <script> 标签,但是要加入 type="module" 属性。
// main.js
import {add} from './add.js';
console.log(add(1, 1))
import {square} from './square.js';
console.log(square(3));
// add.js
console.log('加载了 add 模块')
var add = function(x, y) {
return x + y;
};
export {add}
// multiply.js
console.log('加载了 multiply 模块')
var multiply = function(x, y) {
return x * y;
};
export {multiply}
// square.js
console.log('加载了 square 模块')
import {multiply} from './multiply.js';
var square = function(num) {
return multiply(num, num);
};
export {square}
打印的顺序为:
加载了 add 模块
加载了 multiply 模块
加载了 square 模块
2
9
跟 require.js 的执行结果是一致的,也就是将需要使用的模块先加载完再执行代码。
ES6 与 CommonJS
引用阮一峰老师的 《ECMAScript 6 入门》:
它们有两个重大差异。
CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令
import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。换句话说,ES6 的import有点像 Unix 系统的“符号连接”,原始值变了,import加载的值也会跟着变。因此,ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
运行时加载: CommonJS 模块就是对象;即在输入时是先加载整个模块,生成一个对象,然后再从这个对象上面读取方法,这种加载称为“运行时加载”。
编译时加载: ES6 模块不是对象,而是通过
export命令显式指定输出的代码,import时采用静态命令的形式。即在import时可以指定加载某个输出值,而不是加载整个模块,这种加载称为“编译时加载”。
第二个差异可以从两个项目的打印结果看出,导致这种差别的原因是:
因为 CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
重点解释第一个差异。
CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
举个例子:
// 输出模块 counter.js
var counter = 3;
function incCounter() {
counter++;
}
module.exports = {
counter: counter,
incCounter: incCounter,
};
// 引入模块 main.js
var mod = require('./counter');
console.log(mod.counter); // 3
mod.incCounter();
console.log(mod.counter); // 3
counter.js 模块加载以后,它的内部变化就影响不到输出的 mod.counter 了。这是因为 mod.counter 是一个原始类型的值,会被缓存。
但是如果修改 counter 为一个引用类型的话:
// 输出模块 counter.js
var counter = {
value: 3
};
function incCounter() {
counter.value++;
}
module.exports = {
counter: counter,
incCounter: incCounter,
};
// 引入模块 main.js
var mod = require('./counter.js');
console.log(mod.counter.value); // 3
mod.incCounter();
console.log(mod.counter.value); // 4
而如果我们将这个例子改成 ES6:
// counter.js
export let counter = 3;
export function incCounter() {
counter++;
}
// main.js
import { counter, incCounter } from './counter';
console.log(counter); // 3
incCounter();
console.log(counter); // 4
这是因为
ES6 模块的运行机制与 CommonJS 不一样。JS 引擎对脚本静态分析的时候,遇到模块加载命令 import,就会生成一个只读引用。等到脚本真正执行时,再根据这个只读引用,到被加载的那个模块里面去取值。换句话说,ES6 的 import 有点像 Unix 系统的“符号连接”,原始值变了,import 加载的值也会跟着变。因此,ES6 模块是动态引用,并且不会缓存值,模块里面的变量绑定其所在的模块。
30. “use strict” 严格模式
**严格模式 ** 是采用具有限制性JavaScript变体的一种方式,从而使代码隐式地脱离“马虎模式/稀松模式/懒散模式“(sloppy)模式。
严格模式不仅仅是一个子集:它的产生是为了形成与正常代码不同的语义。
不支持严格模式与支持严格模式的浏览器在执行严格模式代码时会采用不同行为。
所以在没有对运行环境展开特性测试来验证对于严格模式相关方面支持的情况下,就算采用了严格模式也不一定会取得预期效果。严格模式代码和非严格模式代码可以共存,因此项目脚本可以渐进式地采用严格模式。
严格模式对正常的 JavaScript语义做了一些更改。
- 严格模式通过 抛出错误 来消除了一些原有 静默错误。
- 严格模式修复了一些导致 JavaScript引擎难以执行优化的缺陷:有时候,相同的代码,严格模式可以比非严格模式下 运行得更快。
- 严格模式 禁用了 在ECMAScript的未来版本中可能会定义的一些语法。
31. WeakMap & WeakSet
WeakMap对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。WeakSet对象允许你将 弱保持对象 存储在一个集合中。
31.1 WeakMap 与 Map 的区别
已经有了 Map,为什么还会有 WeakMap,它们之间有什么区别呢?
Map 和 WeakMap 之间的主要区别:
- Map 对象的键可以是任何类型,但 WeakMap 对象中的键只能是对象引用, 只能是对象,不能为原始值;
- WeakMap 不能包含无引用的对象,否则会被自动清除出集合(垃圾回收机制);
- WeakMap 对象是不可枚举的,无法获取集合的大小,没有
entries(), keys(), values()方法,没有遍历操作,没有size属性,也不支持clear方法,只用 4 个方法可用set(), get(), has(), delete()。
WeakSet 的表现类似:
- 与
Set类似,但是我们只能向WeakSet添加对象(而不能是原始值)。 - 对象只有在其它某个(些)地方能被访问的时候,才能留在 set 中。
- 跟
Set一样,WeakSet支持add,has和delete方法,但不支持size和keys(),并且不可迭代。
总结
-
WeakMap是类似于Map的集合,它仅允许对象作为键,并且一旦通过其他方式无法访问它们,便会将它们与其关联值一同删除。 -
WeakSet是类似于Set的集合,它仅存储对象,并且一旦通过其他方式无法访问它们,便会将其删除。
它们的 主要优点是它们对对象是弱引用,所以被它们引用的对象很容易地被垃圾收集器移除。
这是以不支持 clear、size、keys、values 等作为代价换来的……
WeakMap 和 WeakSet 被用作“主要”对象存储之外的“辅助”数据结构。一旦将对象从主存储器中删除,如果该对象仅被用作 WeakMap 或 WeakSet 的键,那么它将被自动清除。
31.2 应用场景
31.2.1 在 DOM 对象上保存相关数据
传统使用 jQuery 的时候,我们会通过 $.data() 方法在 DOM 对象上储存相关信息(就比如在删除按钮元素上储存帖子的 ID 信息),jQuery 内部会使用一个对象管理 DOM 和对应的数据,当你将 DOM 元素删除,DOM 对象置为空的时候,相关联的数据并不会被删除,你必须手动执行 $.removeData() 方法才能删除掉相关联的数据,WeakMap 就可以简化这一操作:
let wm = new WeakMap(), element = document.querySelector(".element");
wm.set(element, "data");
let value = wm.get(element);
console.log(value); // data
element.parentNode.removeChild(element);
element = null;
31.2.2 数据缓存
我们需要关联对象和数据,比如在不修改原有对象的情况下储存某些属性或者根据对象储存一些计算的值等,而又不想管理这些数据的死活时非常适合考虑使用 WeakMap。数据缓存就是一个非常好的例子:
const cache = new WeakMap();
function countOwnKeys(obj) {
if (cache.has(obj)) {
console.log("Cached");
return cache.get(obj);
} else {
console.log("Computed");
const count = Object.keys(obj).length;
cache.set(obj, count);
return count;
}
}
31.2.3 私有属性
WeakMap 也可以被用于实现私有变量,不过在 ES6 中实现私有变量的方式有很多种,这只是其中一种:
(function () {
const privateData = new WeakMap();
class Person {
constructor(name, age) {
privateData.set(this, { name, age });
}
getName() {
return privateData.get(this).name;
}
getAge() {
return privateData.get(this).age;
}
}
})();
32. JS V8 引擎下的数组底层实现
前言
JavaScript 中的数组中可以存放不同类型的元素,并且数组的长度是可变的。
但是在数据结构中定义的数组是定长的,并且数据类型必须一致
33. for in 与 for of 的区别
-
for...in语句以任意顺序迭代对象的可枚举属性。以任意顺序迭代一个对象的除Symbol以外的可枚举属性,包括继承的可枚举属性。for ... in是为遍历对象属性而构建的,不建议与数组一起使用,数组可以用Array.prototype.forEach()和for ... of,那么for ... in的到底有什么用呢?它最常用的地方应该是用于调试,可以更方便的去检查对象属性(通过输出到控制台或其他方式)。尽管对于处理存储数据,数组更实用些,但是你在处理有
key-value数据(比如属性用作“键”),需要检查其中的任何键是否为某值的情况时,还是推荐用for ... in。for...in不应该用于迭代一个关注索引顺序的Array。 -
for...of语句遍历可迭代对象定义要迭代的数据。 包括Array,Map,Set,String,TypedArray,arguments 对象等等)上创建一个迭代循环,调用自定义迭代钩子,并为每个不同属性的值执行语句
Object.prototype.objCustom = function() {};
Array.prototype.arrCustom = function() {};
let iterable = [3, 5, 7];
iterable.foo = 'hello';
for (let i in iterable) {
console.log(i); // logs 0, 1, 2, "foo", "arrCustom", "objCustom"
}
for (let i in iterable) {
if (iterable.hasOwnProperty(i)) {
console.log(i); // logs 0, 1, 2, "foo"
}
}
for (let i of iterable) {
console.log(i); // logs 3, 5, 7
}
34. React 中为什么不建议采用数组遍历的 index 作为 key
由于在进行 diff 算法的过程中,会进行新旧 VDOm 比较,如果是删除了一个节点,那么数组中元素减少,对应所有之后的 key 值就会发生和之前组件不匹配的情况,导致组件的重新渲染,而不是直接复用之前的状态
import React, { useState } from "react";
function UseIndexAsKeyDemo() {
const [list, setList] = useState(["a", "b", "c", "d", "e"]);
const deleteItem = (index) => {
list.splice(index, 1);
setList([...list]);
};
return (
<ul>
{list.map((item, index) => (
<li key={index} onClick={(index) => deleteItem(index)}>
{item}
</li>
))}
</ul>
);
}
export default UseIndexAsKeyDemo;

35. javascript:void(0) 的含义
javascript:void(0) 中最关键的是 void 关键字, void 是 JavaScript 中非常重要的关键字,该操作符指定要计算一个表达式但是不返回值。
语法格式如下:
void func()
javascript:void func()
或者:
void(func())
javascript:void(func())
应用
// 阻止链接跳转,URL不会有任何变化
<a href="javascript:void(0)" rel="nofollow ugc">点击此处</a>
// 虽然阻止了链接跳转,但URL尾部会多个#,改变了当前URL。(# 主要用于配合 location.hash)
<a href="#" rel="nofollow ugc">点击此处</a>
// 同理,# 可以的话,? 也能达到阻止页面跳转的效果,但也相同的改变了URL。(? 主要用于配合 location.search)
<a href="?" rel="nofollow ugc">点击此处</a>
// Chrome 中即使 javascript:0; 也没变化,firefox中会变成一个字符串0
<a href="javascript:0" rel="nofollow ugc">点击此处</a>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号