

【网摘】ETL (Extract-Transform-Load) for Data Warehousing
Resource:
Data Modeling Resource Center: http://infogoal.com/dmc/dmcdmd.htm
Data Warehousing Tutorial: http://www.infogoal.com/datawarehousing/
ETL (Extract-Transform-Load) for Data Warehousing
from http://www.infogoal.com/datawarehousing/etl.htm
Stocking the data warehouse with data is often the most time consuming task needed to make data warehousing and business intelligence a success. In the overall scheme of things Extract-Transform-Load (ETL) often requires about 70 percent of the total effort.
Extracting data for the data warehouse includes:
- Making ETL Architecture Choices
- Data Mapping
- Extracting data to staging area
- Applying data cleansing transformations
- Applying data consistency transformations
- Loading data
Before starting the ETL step for the data warehousing and business intelligence project it is important to determine the business requirements. See the article Requirements for Data Warehousing and Business Intelligence for more information.
Also, the data sources and targets must be defined. See articles Data Sources for Data Warehousing and Business Intelligence and Data Models for Data Warehousing and Business Intelligence to understand this.
Making ETL Architecture Choices for the Data Warehouse
ETL has a prominent place in data warehousing and business intelligence architecture.
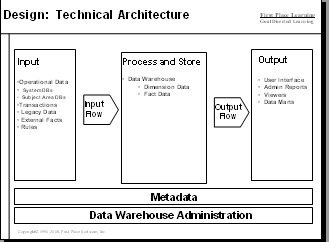
The extract, transformation and loading process includes a number of steps:
Create your own diagrams that show the planned ETL architecture and the flow of data from source to target.
Selecting the right ETL Tools is critical to the success the data warehousing and business intelligence project. Should your company acquire a top of the line specialized ETL tool suite, use lower cost Open Source ETL, or use "Tools at Hand"? The article ETL Tool Selection for the Data Warehouse describes these options along with their pros and cons.
Consider these performance improvement methods:
- Turn off database logging to avoid the overhead of log insertions
- Load using a bulk load utility which does not log
- Primary keys should be single integers
- Drop relational integrity (RI) / foreign keys - restore after load is complete
- Drop indexes and re-build after load
- Partition data leaving data loaded earlier unchanged
- Load changed data only - use "delta" processing
- Avoid SQL Update with logging overhead - possibly drop rows and reload using bulk loader
- Do a small number of updates with SQL Update, then use bulk load for inserts
- Use Cyclic Redundancy Checksum (CRC) to detect changes in data rather than brute force method of comparing each column
- Divide SQL Updates into groups to avoid a big rollback log being create.
- Use an ETL tool that supports parallelism
- Use an ETL tool that supports caching
- Use RAID technologies
- Use fast disk and controllers - 15,000 RPM
- Dedicate servers and disk to business intelligence - do not share with other applications
- Use multiple servers to support BI such as: a database server, an analysis server and a reporting server
- Use a server with large main memory (16 GB +) - this increases data caching and reduces physical data access
- Use a server with multiple processors / cores to enable greater parallelism
Data Mapping for Data Warehousing and Business Intelligence
A Data Map is specification that identifies data sources and targets as well as the mapping between them. The Data Map specification is created and reviewed with input by business Subject Material Experts (SMEs) who understand the data.
There are two levels of mapping, entity level and attribute level. Each target entity (table) will have a high level mapping description and will be supported by a detailed attribute level mapping specification.
| Target Table Name | dw_customer |
| Target Table Description | High level information about a customer such as name, customer type and customer status. |
| Source Table Names | dwprod1.dwstage.crm_cust dwprod1.dwstage.ord_cust |
| Join Rules | crm_cust.custid = ord_cust.cust.cust_nbr |
| Filter Criteria | crm_cust.cust_type not = 7 |
| Additional Logic | N/A |
Then for each attribute the attribute level data map specifies:
- Source: table name, column name, datatype
- Target: table name, column name, datatype
- Transformation Rule
- Notes

Transformations may include:
- Aggregate
- Substring
- Concatenate
- Breakout Array Values / Buckets
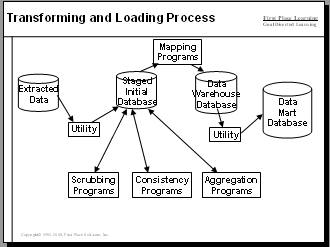
Extracting Data to Staging Area
Data is first extracted from the source system and placed in a staging area. This staging area is typically formatted like the source system. Keeping data in the same format as the source makes the first extract simple and avoids bogging the source system down.
You most likely will want to process only changed data, to avoid the overhead of reprocessing the entire set of data. This could be done by extracting data based on date/time information on the source system, mining change logs or by examining the data to determine what changed.
- Tip 1: Make sure the source system date/time information is consistently available. Use data profiling to validate.
- Tip 2: Store a copy of the prior version of data in the staging area so that it can be compared to the current version to determine what changed.
- Tip 3: Calculate check sums for both current and prior versions, then compare check sums rather than multiple columns. This speeds up processing.
- Tip 4: Add a source system prefix to table names in the staging area. This helps to keep data logically segregated.
Applying Data Transformations
Data is now ready for transformation which includes cleansing, rationalization and enrichment. The cleansing process, sometimes called "scrubbing" removes errors while rationalization removes duplicates and standardizes data. The enrichment process adds data.
Before starting data transformation efforts it is important to diagnose and understand problems. See the Data Profiling topic in the articleData Sources for Data Warehousing and Business Intelligence for guidance. This article assumes that data errors that could be cleaned and / or prevented at the source have already been cleaned or corrected.
These processes may take place in tables dedicated to transformation or may take place "on the fly" as data is moved from staging to data warehouse or from data warehouse to data mart.
Tools have been developed to scrub and standardize party information like SSN, names, addresses, telephone numbers and email addresses. This software can also remove or merge duplicate information ("de-duping").
Techniques available include:
- Audit
- Correct At Source
- Specialized Software (Address Correction Software)
- Substituting Codes and Values
Missing, Incomplete and Wrongly Formatted Data
Common problems that may require correction are missing data, incomplete data and wrongly formatted data. In the case of missing data, a complete column such as zip code or first name is empty. A tool could correct the zip code based on look up of address lines, city and state. Incomplete data is partially missing such as the case where an address constains the name of a street without the building number. Tools are available that can correct some of these problems. Finally, data may be in the wrong format. We may want telephone numbers to contain hyphens. A tool could consistently format telephone numbers.
Applying Data Consistency Transformations
Consistent data is important for "apples to apples" comparisons. For example, all weight measures could be converted to grams or all currency values to dollars. Transformation could be used to make code values consistent such as:
- Gender ("M", "F") or ("y", "n")
- Boolean ("Y", "N") or (1, 0)
More Data Cleansing Issues
| Correcting Duplicate Data |
Same Party with Different Names (T. Jones, Tom Jones, Thomas Jones) |
| Dummy Data |
Dummy data like '111111111' for SSN |
| Mismatched Data |
Postal Code does not Match City / State |
| Inaccurate Data | Incorrect inventory balances |
| Overloaded Attributes |
Attributes mean different things in different contexts. |
| Meaning Embedded in Identifiers and Descriptions | Such as including price in SKU. |
Loading the Data Warehouse
The data warehouse is a mix of atomic and dimensional data. The atomic portion is stored in a normalized, relational format. Data stored in this format can be repackaged in a number of ways for ease of access when moved to the data mart.
Positioned for Direct Load to Data Warehouse by Utility
- Benefits:
- Very Flexible
- Reduces Contention and Load Time for Data Warehouse
Loading the Data Mart
Loading the data mart through efficient and effective methods is the subject of this article. When loading the data mart, dimensions are loaded first and facts are loaded second. Dimensions are loaded first so that the primary keys of the dimensions are known and can be added to the facts.
Make sure that the following prerequisites are in place:
- Data is stored in the data warehouse and ready to load in the data mart
- Data maps have been created for movement from data warehouse to data mart
- Grain is determined for each dimension and fact
Loading Data Mart Dimensions
There are specific prerequisites that must be in place for dimensions:
- Dimensions have surrogate primary keys
- Dimensions have natural keys
- Dimensions have needed descriptive, non-key attributes
- Maintenance strategy is determined for each dimension:
-
- Slowly Changing Dimension (SCD) Type 1: Overwrite
- SCD Type 2: Insert new row - partitions history
- SCD Type 3: Columns in changed dimension contain prior data
Some dimensions are loaded one time at the beginning of the data mart project such as:
- Calendar Date
- Calendar Month
- US State
- US Zip Code
| Dimension Name | Date_Dim |
| Description | Dates of the year |
| Grain | A single day |
| Primary Key | Date_Key (generated integer) |
| Natural Key | YYYY_MM_DD_Date |
| Descriptive Attributes |
Multiple date formats are stored, plus week, month, quarter, year and holidays. Both numeric dates and spelled out dates are included. |
| Maintenance Strategy |
The date dimension is loaded once, at the beginning of the dart mart project. It may require updates to correct problems to change attributes such as: company_holding_ind. |
Loading Data Mart Facts
Data mart facts consist of 3 types of columns:
- Primary key
- Dimensional keys
- Measurements
In the data warehouse, there will be natural keys that can be joined with dimensions to obtain dimensional keys. For example:
| Description | Data Warehouse | Data Mart |
| Primary key | purchase_order_nbr line_item_nbr effective_date |
purchase_order_fact_id |
| Alternate identifiers | Effective_date product_code facility_number |
effective_date_id product_id facility_id |
| measurements | order_qty received_qty unit_price_amt |
order_qty |
===================================================================================
--------------------------------------
Regards,
FangwenYu


 浙公网安备 33010602011771号
浙公网安备 33010602011771号