



streamsets 实时同步mysql到kudu
streamsets mysql的全量同步采用的读binlog文件实现,所以,源mysql数据库需要开启binlog日志。
废话不多说,直接上例子:

增量同步mysql配置:第一次全量同步,需要从binlog开始的位置开始同步,
也可以从设置的偏移量处开始。
Advanced 配置里面写需要同步的表,database.table 格式。
Jython Evaluator配置:这个组件的作用是将binlog日志解析成需要的map。代码如下:
for record in records:
newRecord = sdcFunctions.createRecord(record.sourceId + ':newRecordId')
try:
if record.value['Type'] == 'DELETE':
newRecord.attributes['sdc.operation.type']='2'
newRecord.attributes['Type']=record.value['Type']
newRecord.attributes['Table']=record.value['Table']
newRecord.value = record.value['OldData']
else:
newRecord.attributes['sdc.operation.type']='4';
newRecord.attributes['Type']=record.value['Type']
newRecord.attributes['Table']=record.value['Table']
newRecord.value = record.value['Data'];
# Write record to processor output
output.write(newRecord)
except Exception as e:
# Send record to error
error.write(newRecord, str(e))Stream Selector 配置:这个组件的作用是分流,这里就是将insert update delete的DML操作分流。

kudu配置:连接分流1的,Default Operation 选择DELETE,连接分流2的选择UPSERT。
![]()
第一个Field Type Converter 配置:这里用这个是把DATE或者TIME格式转化成string类型,把DATETIME转成ZONED_DATETIME格式。这样做原因如下:
1、Mysql binlog方式,mysqlDATETIME格式的数据会自动多8小时,而且还成了12小时制,猜测可能是 默认是UTC格式时间,通过binlog组件取数会自动转成当地时区的DATETIME,所以需要还原成UTC格式。
2、后期用string格式的时间便于处理,兼容性也好,不用担心不同时间格式造成的困扰。
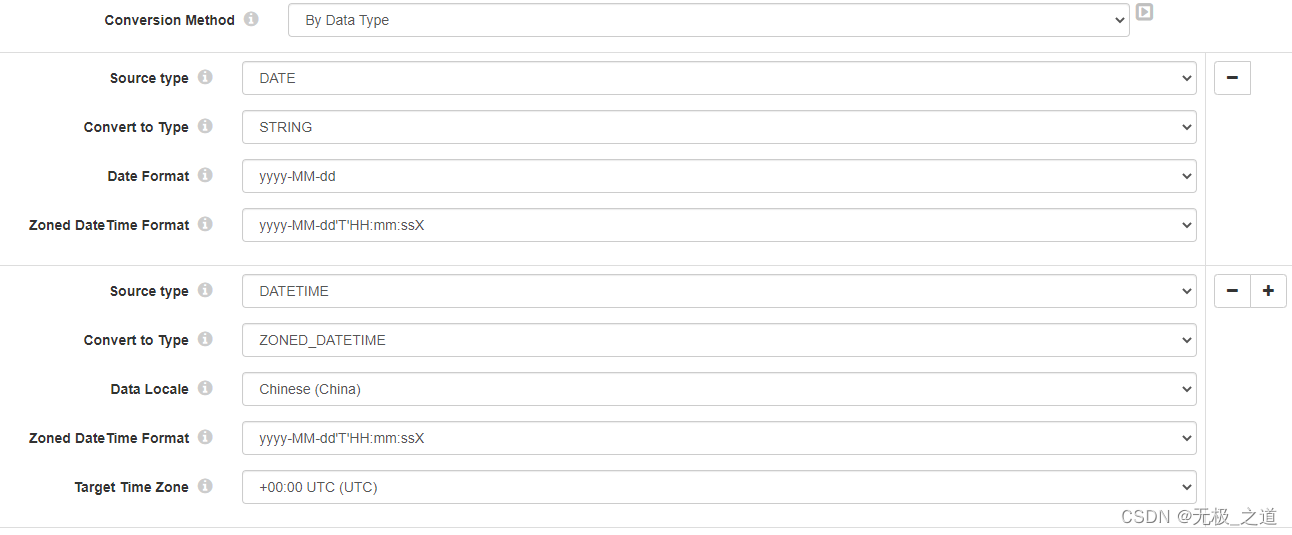
第二个Field Type Converter 配置:这个是为了将带时区的、12小时制的时间转化成string格式。直接如库:

这里要特别注意zoned date的设置,HH是代表24小时制的。
当你把pg数据用CDC方式实时同步的时候,就知道时间转换成string有多香,特别是那些多个带毫秒还不固定长度的字段处理。kudu里面,建表的时候也是需要string的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号