kafka-go源码简单笔记
1.问题
最近在项目中用到了kafka,客户端使用的是开源的kafka-go,版本v0.4.8。前段时间kafka缩容之后,发现客户端写数据总是返回连接超时错误。一般而言,客户端都是会动态更新元数据的,但是为什么总是失败呢?只好把源代码梳理了下。
2.调用过程
中间调用过程还是有点复杂的,估计我也讲不清楚就不尝试了。感兴趣的朋友可以结合源码和下面的导图自己看下。
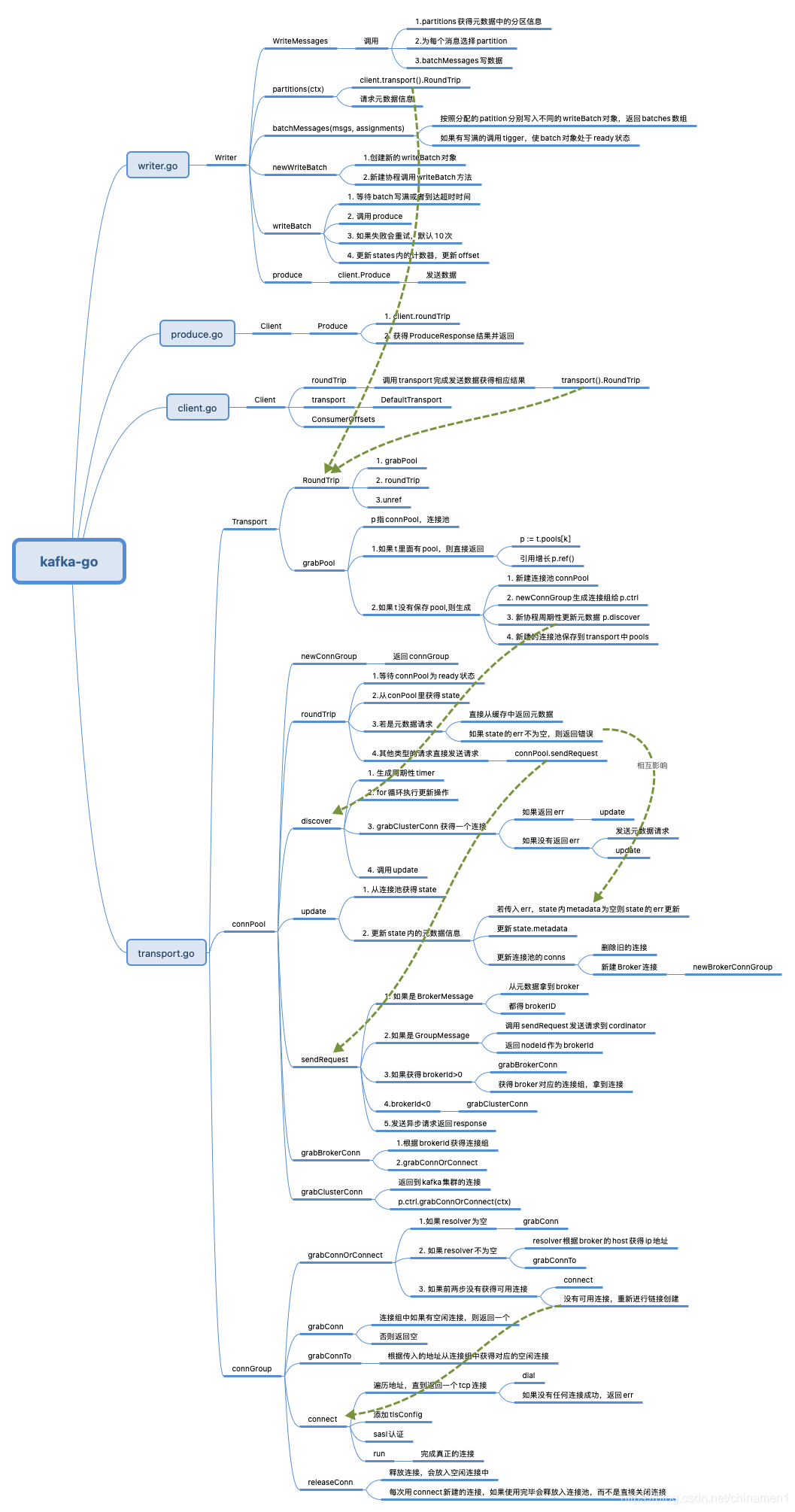
3.问题分析
3.1为什么写数据总是返回错误
对于我遇到的问题,主要关注两个地方。一个是发送数据时的Writer.WriteMessages方法,会调用partitions方法查询一次元数据中的分片信息。在这个版本中元数据请求会从缓存中返回从而减少真正发送请求的次数,最后会到下面的方法中。
func (p *connPool) roundTrip(ctx context.Context, req Request) (Response, error) {
// This first select should never block after the first metadata response
// that would mark the pool as `ready`.
select {
case <-p.ready:
case <-ctx.Done():
return nil, ctx.Err()
}
var expectTopics []string
defer func() {
if len(expectTopics) != 0 {
p.refreshMetadata(ctx, expectTopics)
}
}()
state := p.grabState()
var response promise
switch m := req.(type) {
case *meta.Request:
// We serve metadata requests directly from the transport cache.
//
// This reduces the number of round trips to kafka brokers while keeping
// the logic simple when applying partitioning strategies.
//这里会判断缓存的状态里err,如果非nil,会返回错误
if state.err != nil {
return nil, state.err
}
return filterMetadataResponse(m, state.metadata), nil
case *createtopics.Request:
// Force an update of the metadata when adding topics,
// otherwise the cached state would get out of sync.
expectTopics = make([]string, len(m.Topics))
for i := range m.Topics {
expectTopics[i] = m.Topics[i].Name
}
case protocol.Splitter:
// Messages that implement the Splitter interface trigger the creation of
// multiple requests that are all merged back into a single results by
// a merger.
messages, merger, err := m.Split(state.layout)
if err != nil {
return nil, err
}
promises := make([]promise, len(messages))
for i, m := range messages {
promises[i] = p.sendRequest(ctx, m, state)
}
response = join(promises, messages, merger)
}
if response == nil {
response = p.sendRequest(ctx, req, state)
}
return response.await(ctx)
}
另一个是自动进行元数据更新时存在的bug。从下面的代码能看到,如果请求元数据成功了会对缓存信息进行更新的。但是由于没有及时清空错误信息,导致如果之前出现过错误之后也不会被更新。从而在调用上面的roundTrip方法时总是返回错误,导致发送数据失败。
func (p *connPool) update(ctx context.Context, metadata *meta.Response, err error) {
var layout protocol.Cluster
if metadata != nil {
metadata.ThrottleTimeMs = 0
// Normalize the lists so we can apply binary search on them.
sortMetadataBrokers(metadata.Brokers)
sortMetadataTopics(metadata.Topics)
for i := range metadata.Topics {
t := &metadata.Topics[i]
sortMetadataPartitions(t.Partitions)
}
layout = makeLayout(metadata)
}
state := p.grabState()
addBrokers := make(map[int32]struct{})
delBrokers := make(map[int32]struct{})
if err != nil {
// Only update the error on the transport if the cluster layout was
// unknown. This ensures that we prioritize a previously known state
// of the cluster to reduce the impact of transient failures.
if state.metadata != nil {
return
}
//如果请求元数据出错,则缓存里的状态记录下这个err
state.err = err
} else {
for id, b2 := range layout.Brokers {
if b1, ok := state.layout.Brokers[id]; !ok {
addBrokers[id] = struct{}{}
} else if b1 != b2 {
addBrokers[id] = struct{}{}
delBrokers[id] = struct{}{}
}
}
for id := range state.layout.Brokers {
if _, ok := layout.Brokers[id]; !ok {
delBrokers[id] = struct{}{}
}
}
state.metadata, state.layout = metadata, layout
//如果在更新时没有错误,并没有把state.err清空
//在0.4.9之后的代码里修复了这个问题
}
defer p.setReady()
defer p.setState(state)
if len(addBrokers) != 0 || len(delBrokers) != 0 {
// Only acquire the lock when there is a change of layout. This is an
// infrequent event so we don't risk introducing regular contention on
// the mutex if we were to lock it on every update.
p.mutex.Lock()
defer p.mutex.Unlock()
if ctx.Err() != nil {
return // the pool has been closed, no need to update
}
for id := range delBrokers {
if broker := p.conns[id]; broker != nil {
broker.closeIdleConns()
delete(p.conns, id)
}
}
for id := range addBrokers {
broker := layout.Brokers[id]
p.conns[id] = p.newBrokerConnGroup(Broker{
Rack: broker.Rack,
Host: broker.Host,
Port: int(broker.Port),
ID: int(broker.ID),
})
}
}
}
3.2 为什么缩容会导致请求超时?
注意到上面图里在没有可用连接时会最终到下面的方法来获取连接。其实就是根据初始配置的broker的地址打散之后遍历尝试建立连接,只要有一个成功就直接返回。
在缩容之后,原来配置的broker列表里大部分都连接不上了,所以会重新回到这里进行建连。但是由于是遍历尝试建连的,而尝试的总次数受到超时时间限制,也就是deadline。
默认配置是5秒,而建连一次超时是3s,导致实际上无法遍历所有列表,尝试了前面两个如果失败了整个就超时了。导致新的连接迟迟无法建立。
不过由于是每次打散的,理论上尝试一些次数之后是可能恢复建连从而拉取到最新的元数据的。而由于上面提到的bug导致元数据无法更新。
func (g *connGroup) connect(ctx context.Context, addr net.Addr) (*conn, error) {
//注意这里是有个超时时间的
deadline := time.Now().Add(g.pool.dialTimeout)
ctx, cancel := context.WithDeadline(ctx, deadline)
defer cancel()
var network = strings.Split(addr.Network(), ",")
var address = strings.Split(addr.String(), ",")
var netConn net.Conn
var netAddr net.Addr
var err error
if len(address) > 1 {
// Shuffle the list of addresses to randomize the order in which
// connections are attempted. This prevents routing all connections
// to the first broker (which will usually succeed).
rand.Shuffle(len(address), func(i, j int) {
network[i], network[j] = network[j], network[i]
address[i], address[j] = address[j], address[i]
})
}
//遍历,有一个成功就返回
for i := range address {
netConn, err = g.pool.dial(ctx, network[i], address[i])
if err == nil {
netAddr = &networkAddress{
network: network[i],
address: address[i],
}
break
}
}
if err != nil {
return nil, err
}
defer func() {
if netConn != nil {
netConn.Close()
}
}()
if tlsConfig := g.pool.tls; tlsConfig != nil {
if tlsConfig.ServerName == "" && !tlsConfig.InsecureSkipVerify {
host, _, _ := net.SplitHostPort(netAddr.String())
tlsConfig = tlsConfig.Clone()
tlsConfig.ServerName = host
}
netConn = tls.Client(netConn, tlsConfig)
}
pc := protocol.NewConn(netConn, g.pool.clientID)
pc.SetDeadline(deadline)
r, err := pc.RoundTrip(new(apiversions.Request))
if err != nil {
return nil, err
}
res := r.(*apiversions.Response)
ver := make(map[protocol.ApiKey]int16, len(res.ApiKeys))
if res.ErrorCode != 0 {
return nil, fmt.Errorf("negotating API versions with kafka broker at %s: %w", g.addr, Error(res.ErrorCode))
}
for _, r := range res.ApiKeys {
apiKey := protocol.ApiKey(r.ApiKey)
ver[apiKey] = apiKey.SelectVersion(r.MinVersion, r.MaxVersion)
}
pc.SetVersions(ver)
pc.SetDeadline(time.Time{})
if g.pool.sasl != nil {
if err := authenticateSASL(ctx, pc, g.pool.sasl); err != nil {
return nil, err
}
}
reqs := make(chan connRequest)
c := &conn{
network: netAddr.Network(),
address: netAddr.String(),
reqs: reqs,
group: g,
}
go c.run(pc, reqs)
netConn = nil
return c, nil
}
后记
- 花了一些时间看源码实现,虽然不是很细节地看,不过能了解到整体实现还是很有成就感。主要是解决了自己遇到的问题。
- 本来以为发现了一个项目
bug,准备去提一下,发现新版本的已经修复了。 - 生产中使用开源项目也是有风险的。要使用还是要熟悉,否则出问题了都不知道怎么回事。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号