申明 :文本的观点都是基于生活经验参考别人的书和资料整理思考而得。难免有差错,请明白人指正,不甚感激。
1一件习以为常的事:
1+1=?
当你使用做一道题1+1的时候,你先从记忆力提取出 数字1和+的含义,再通过提取并调用加法的知识, 返回结果。
什么是记忆?如何记忆?如何提取记忆。
记忆就是人把自己看到听到感觉等等编码进大脑的神经网络的东西。提取记忆也是人像大脑的神经网络发出请求获取数据。
我把记忆想像成一个复杂的网络上的点。通过与知识和其他数据的线索链接。
那么知识呢?
假设说记忆是数据,存在大脑神经网络的1/0数据。那么知识就是一堆操作数据的指令。
2那么大脑是如何查找记忆的呢?
如果我是上帝也许我会考虑debug一个人的计算1+1,但显然不可能,对于这种黑箱操作。
我只能往大脑里输入大量数据查看输出结果。和“经验”则是最好的输出结果的统计。
从经验和别人的文章中获取启发:
答案:自然是依靠编码进记忆的的线索去回忆
(设想)一个记忆节点是一个拥有多个双向链接节点的一个记忆节点。(假设)我们可以从一个记忆节点出发找到当时所有的信息,看到1时的指向心情的节点的值,指向气味节点的值等等。。
PS:我无法想象当我回忆1时给我的气味, 因为每次当我每次使用了1的时候气味被"冲淡"了.由稀疏矩阵模型解释。
3记忆是一个稀疏矩阵!
#1我们可以基于我们的常识记忆建立模型。 假定以下常识为正确。
- 记忆的是一个节点。
- 回忆是一次对记忆的update。
- 节点之间用线索链接,也是大脑寻找记忆的唯一途径。 (2.1.3)
- 回忆在节点间奔走会自我减弱。当一定程度上匹配时会回忆成功。
- 回忆会让两个节点的距离变近。(更容易被记起——记得牢)
- 存取,搜索的过程有一个重要的因素是神经的兴奋程度。
#2提出概念:
- 属性: 属性可以作为节点的值,同时也是一个节点。比如气味(一个父节点):香(一个分支)/臭:(幽香/浓香)。
- 节点: 一个节点可以包含任意个节点,//一个节点 @1属性(节点) @2值(节点的一个分支)。
- 值:对属性的一个具体的描述。
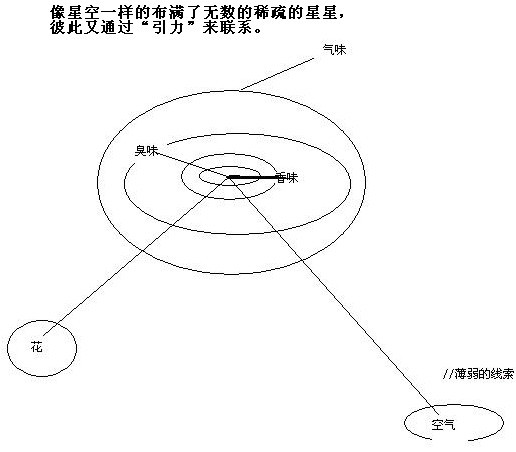
#3 指导思想:更多的线索!更好的线索!更近的距离!兴奋!
如何更好的记住想记住的东西,比如你女朋友的生日,你的银行的密码或者某个难看又长的单词。我们的前辈想了无数的花招,包括理解记忆法,联想记忆法,多通道记忆法,自我欺骗法等等,
究其本质便有 :
- 1为记忆的节点牵扯更多更好的线索。(比如把你女朋友的生日作为银行密码和电脑开机密码)
- 2拉近(某个中文解释)与最终要触发的条件(某个单词)的距离。
#4 据此模型提出的记忆优化
4.1打造记忆的哈夫曼树。
我们知道稀疏矩阵是一个非常好的储存离散数据的数据结构。在人类早期的环境中,这是一个非常好的存储模式,但是他并不太适应现代某些情形。我们最需要记住的知识往往是分门别类的各种领域知识(按照规范码代码,按照规范加工产品),这时候我们多么 希望在巨大的神经网络的稀疏矩阵中有一块是高效的哈弗曼树结构!
按记忆的触发条件分门别类的记录
强化了他们之间的(基于稀疏矩阵的)哈夫曼树的性质的联系。
4.2抽象与推广
这不仅是记忆的好方法也是学习的好方法。
4.3让你的神经兴奋起来
这个例子很好举,也很容易让大家接受。(是我本来想收尾的时候突然想想我的模型无法解释的一些问题而想到的)而刘未鹏大哥的《如何有效地记忆与学习》却没有提及,但是却真的很重要。试想要是每个英文单词都想初恋一样让人无法忘记那是多么的无敌啊!套用一句很欠揍的话,我让你考四级,让你考四级。
4.4设身处地地“虚拟经历”别人经历过的事情
4.5联系/比较自身的经历
本文参考和copy了刘未鹏大哥的很多文字(他自己也援引了一些别人的文字),但却有我自己的思考,我还把我是如何想如何推理的整个过程写了出来。copy是为了减少重复的劳动和写一些很次的东西,希望大家少拍砖,如果有版权问题,我也可以撤掉,但我想刘未鹏大哥应该没空来我这偏辟的地方,如果别人想这样copy我的,然后扩展自己的。我也会很高兴。
欢迎大家一起来思考。
相关资料<追寻逝去的记忆>以及上文提到的其他


