K8S二次开发02-kubeadm安装k8s集群
K8S二次开发02-kubeadm安装k8s集群39套云原生实战训练营K8s,挑战年薪50万(K8s+Docker+DevOps+Jenkins+CICD+Git+Istio+Service Mesh)视频教程
39套云原生技术包含:云原生实战训练营K8s,挑战年薪50万(K8s+Docker+DevOps+Jenkins+CICD+Git+Istio+Service Mesh)云计算,微服务,容器架构师,全栈架构师,集群实战,部署落地,服务治理,服务网格,原理剖析,实战应用,云原生架构,CKA认证实战班,平台设计与开发等视频教程。

总目录:39套云原生实战训练营K8s,挑战年薪50万(K8s+Docker+DevOps+Jenkins+CICD+Git+Istio+Service Mesh)云计算,微服务,容器架构师,全栈架构师,集群实战,部署落地,服务治理,服务网格,原理剖析,实战应用,云原生架构,CKA认证实战班,平台设计与开发视频教程

第01套:云原生高薪课,挑战年薪50万,从零到一构建开源的企业级PaaS平台视频教程

第02套:拥抱云原生从无到有搭建企业自己的私有云平台实现云上亿级流Kubernetes+DevOps+Jenkins+Istio

第03套:云原生实战Docker+K8s+Kubeshere+DevOps云原生实战架构师必修课

第04套:云原生微服务架构实战精讲,微服务架构的迁移和落地视频教程

第05套:云原生微信小程序开发实战-云开发已经成为小程序开发的标配

第06套:云原生+边缘计算项目实战-KubeEdge打造边缘管理平台,实战云边端一体化设计,迈向高阶人才

第07套:真架构!真正的云原生架构与云IDC实操业务 腾讯架构师工程师TCP认证课程 含DevOps

第08套:Kubernetes全栈架构师:基于世界500强的k8s实战课程

第09套:K8S微服务与容器云架构师(Linux云计算微服务架构师) 讲解实际生产内容知识体系视频课程

第10套:KubernetesK8s CKA认证实战班(完整版)BAT大厂基于K8s构建企业容器云平台

第11套:Kubernetes 原理剖析与实战应用-进阶高级架构师的必须选项视频教程

第12套:K8S集群实战,k8s各种扩展组件的部署和使用,k8s持久化存储,k8s代码自动发布教程

第13套:Docker与Kubernetes最佳实践-架构师必备技能docker入门到专精高阶视频教程

第14套:全面Docker系统性入门+进阶实战(Docker 知识体系及使用指南&最佳实践)

第15套:DevOps实战笔记-DevOps平台设计和开发视频教程

第16套:大厂进阶篇Docker与微服务实战-技术点从入门到高级全面覆盖视频教程

第17套:DevOps落地笔记视频教程-优化研发流程,提高研发效率和产品质量,解决企业实际遇到问题

第18套:微服务Service Mesh实战 Service Mesh实践和落地的学习内容视频教程

第19套:火遍大厂的Service Mesh服务实战课程 从组件到架构全方位解读微服务之Service Mesh

第20套:Istio服务网格服务治理微服务架构与设计全面解析视频教程

第21套:大厂Istio基础与实践 云原生“薪”能力合集,一线大厂实战分享视频教程

第22套:KubernetesK8s CKS 认证实战班-架构+网络+存储+安+监控+日志+QCD视频教程

第23套:Kubernetes网络训练营,为运维和开发打造的进阶体系课Flannel+Calico+Multus+Cilium

第24套:Kubernetes实战与源码剖析体系进阶班MSB,自动化运维管理多个跨机器Docker的集群

第25套:基于阿里云平台,从0构建云原生应用架构设计与开发实战,掌握云原生技术架构开发全流程

第26套:百万云原生架构师4期-掌握云原生架构师的9大顶级架构设计思维模型,架构设计哲学本质

第27套:基于Jenkins的DevOps工程实践 使用Jenkins完成DevOps交付流水线实践落地视频教程

第28套:Jenkins核心功能快速上手Jenkins企业级持续集成持续部署CICD(DI)视频教程

第29套:P7云原生架构师剑指未来,一站式搞定企业级云原生-专业技能+核心原理+方案设计+系统分析

第30套:前端配置化+后端Serverless开发个人博客(全栈+实战)HOOKS+Redux+Webpack+Immer

第31套:玩转Serverless架构 概念篇+开发基础篇+开发进阶篇+场景案例篇视频教程

第32套:Serverless进阶实战课 成为会Serverless懂 Serverless的工程师,云原生技术要红利

第33套:kubernetesk8s各个版本高可用集群灵活安装 掌握k8s日常运维视频教程

第34套:新版K8S+DevOps云原生全栈技术——基于世界500强的高薪实战Kubernetes课

第35套:基于GO语言,K8s+gRPC实战云原生微服务开发与治理实战,完整掌握K8s微服务治理

第36套:新版容器编排k8s最佳实践kubernetes-Rancher2.x–第一季最佳实践

第37套:诸葛老师-电商项目K8S部署与性能优化实战,基于K8S集群电商微服务项目性能优化实战

第38套:Docker入门到进阶教程(Docker从零走向实战),7个深度3个全面 基础篇+提升篇+高级篇

第39套:Golang企业级运维 融合DevOps运维开发实战,高级运维必修视频课程(76课)

组件概览
关于k8s整体架构,可参考:之前文章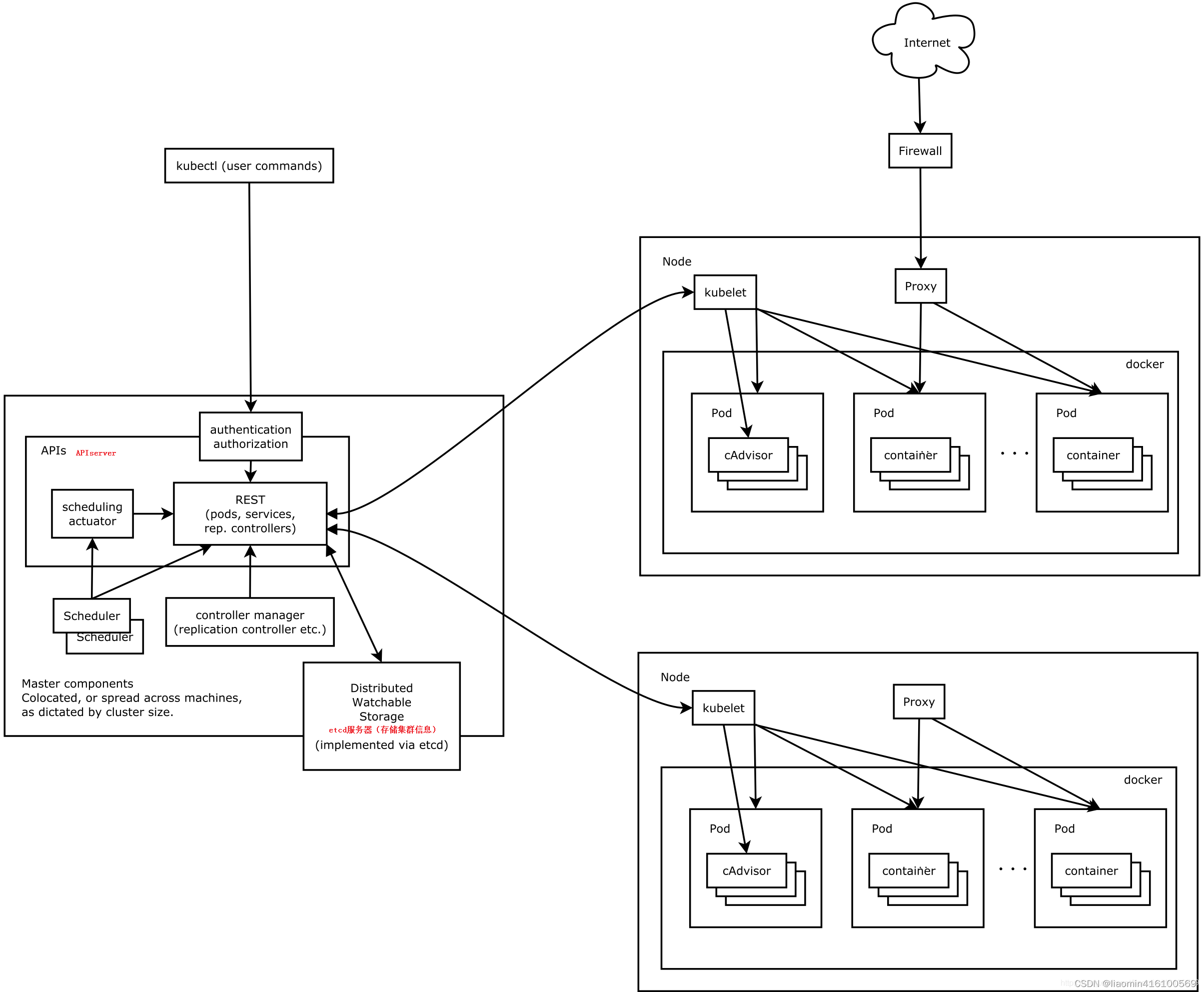
Kubernetes主要由以下几个核心组件组成(必须安装):
- etcd保存了整个集群的状态;
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
- controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理,安装每台工作节点;
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡,安装在每台工作节点;
除了核心组件,还有一些推荐的Add-ons(选装): - kube-dns负责为整个集群提供DNS服务,应该使用kubectl添加一个服务到容器,是一个发布的应用服务于
其中kubelet是二进制安装包,其他组件均为docker镜像,kubeadm负责拉取镜像并初始化环境。
kubectl是客户端管理工具,同样是个二进制。
所以kubelet,kubeadm,kubectl需要通过yum|apt-get安装,其他组件通过kubeadm安装。
安装k8s
最简单,成功率最高的安装方式其实是使用rke安装,这里使用kubeadmin是想知道每个组件的单独原理和作用,具体安装教程参考:https://docs.rancher.cn/docs/rke/installation/_index/。
已经安装如果需要清除,可按照此步骤处理(重置k8s,删除所有运行容易和镜像)
kubeadm reset
docker ps -a | awk '{if(NR>1){print $1;system("docker stop "$1);system("docker rm "$1)}}';
docker images | awk '{system("docker rmi "$3)}'
rm -rf $HOME/.kube
同时清除下面安装网络章节的网络相关文件- 1
- 2
- 3
- 4
- 5
准备机器
这里使用debian环境,主备一主一从两台机器,最好固定ip,ip最好在同一网段
k8s-master 10.10.0.115
k8s-worker 10.10.0.116- 1
- 2
安装kubelet,kubeadm,kubectl,两台机器均相同
确保两台机器提前安装包docker
apt-get install docker-ce- 1
设置阿里云源
sudo vim /etc/apt/sources.list.d/kubernetes.list
# 将下面的阿里源加入文件中
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
# 也可以选择中科大的源
deb http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main- 1
- 2
- 3
- 4
- 5
- 6
- 7
里先运行一下 apt update, 会报错,原因是缺少相应的key,可以通过下面的命令添加(E084DAB9 为上面报错的key后8位)
gpg --keyserver keyserver.ubuntu.com --recv-keys E084DAB9
gpg --export --armor E084DAB9 | sudo apt-key add -- 1
- 2
下载安装
apt-get update && apt-get install -y kubelet kubeadm kubectl- 1
关闭swap
如果不关闭kubernetes运行会出现错误, 即使安装成功了,node重启后也会出现kubernetes server运行错误。
#暂时关闭,
sudo swapoff -a
# 永久关闭
vim /etc/fstab
注释掉swap那一行就行
虚拟机最好把内存分配调整到2G以上,否则关掉swap会导致图形界面难以进入。- 1
- 2
- 3
- 4
- 5
- 6
- 7
我这里是注释最后一行
root@liaok8s:/home/mainte# more /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda1 during installation
UUID=52c86df1-9442-46c0-a29c-b8f7d0a421ab / ext4 errors=remount-ro 0 1
# swap was on /dev/sda5 during installation
#UUID=e4e792e9-d30b-4e4a-ab3c-26bd488adaae none swap sw 0 0
#/dev/sr0 /media/cdrom0 udf,iso9660 user,noauto 0 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
获取镜像
由于官方镜像地址被墙,所以我们需要首先获取所需镜像以及它们的版本。然后从国内阿里的镜像站获取。
kubeadm config images list- 1
获取镜像列表后可以通过下面的脚本从阿里云获取:
for i in `kubeadm config images list`; do
#coredns镜像在gcr.io上是k8s.gcr.io/coredns/coredns:v1.8.6 在阿里云上是 registry.aliyuncs.com/google_containers/coredns:v1.8.6,需要特殊处理
if echo $i | grep coredns/coredns;then
imageName=${i#k8s.gcr.io/coredns/}
docker pull registry.aliyuncs.com/google_containers/$imageName
docker tag registry.aliyuncs.com/google_containers/$imageName k8s.gcr.io/coredns/$imageName
docker rmi registry.aliyuncs.com/google_containers/$imageName
else
imageName=${i#k8s.gcr.io/}
docker pull registry.aliyuncs.com/google_containers/$imageName
docker tag registry.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
docker rmi registry.aliyuncs.com/google_containers/$imageName
fi
done;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
主节点
初始化
kubeadm init --service-cidr=10.96.0.0/12 --image-repository=registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16- 1
初始化可常用的参数:
参数说明
--apiserver-advertise-address=10.10.0.115 这个参数就是master主机的IP地址,例如我的Master主机的IP是:10.10.0.115
--image-repository=registry.aliyuncs.com/google_containers 这个是镜像地址,由于国外地址无法访问,故使用的阿里云仓库地址:registry.aliyuncs.com/google_containers,如果不指定就需要做下面获取镜像章节的动作。
--kubernetes-version=v1.17.4 这个参数是下载的k8s软件版本号
--service-cidr=10.96.0.0/12 这个参数后的IP地址直接就套用10.96.0.0/12 ,以后安装时也套用即可,不要更改
--pod-network-cidr=10.244.0.0/16 k8s内部的pod节点之间网络可以使用的IP段,不能和service-cidr写一样,如果不知道怎么配,就先用这个10.244.0.0/16- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
一般都会报错
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
查看官网介绍为 docker 和 kubelet 服务中的 cgroup 驱动不一致,有两种方法
方式一:驱动向 docker 看齐
方式二:驱动为向 kubelet 看齐
如果docker 不方便重启则统一向 kubelet看齐,并重启对应的服务即可
解决方式
docker 配置文件
这里采取的是方式二,docker 默认驱动为 cgroupfs ,只需要添加
“exec-opts”: [
“native.cgroupdriver=systemd”
],
修改后配置文件
root@controlplane:~# cat /etc/docker/daemon.json
{
"exec-opts": [
"native.cgroupdriver=systemd"
],
"bip":"172.12.0.1/24",
"registry-mirrors": [
"http://docker-registry-mirror.kodekloud.com"
]
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
重启docker
systemctl restart docker- 1
kublete 配置文件
grep 截取一下,可以看得出来kubelet默认 cgoup 驱动为systemd
root@controlplane:~# cat /var/lib/kubelet/config.yaml |grep group
cgroupDriver: systemd- 1
- 2
- 3
修改后重置并重新初始化可正常初始化
kubeadm reset && kubeadm init- 1
成功后提示
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.10.0.115:6443 --token pedwrg.x3ocfkg6ui1t5yht \
--discovery-token-ca-cert-hash sha256:a696588d58710779c758a0cdc4f0da3154af5d62f9b54420b5bb78d63f11e7a2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
注意最后一段的kubeadm join是worker节点加入使用的,注意保存,如果忘记了可通过以下命令打印:
kubeadm token create --print-join-command- 1
普通用户安装需要执行如下脚本:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config- 1
- 2
- 3
root用户直接运行
export KUBECONFIG=/etc/kubernetes/admin.conf- 1
此时查看所有二进制安装的进程
root@liaok8s:/home/mainte# ps -ef | grep kube
root 7691 7622 2 16:30 ? 00:00:03 etcd --advertise-client-urls=https://10.10.0.115:2379 --cert-file=/etc/kubernetes/pki/etcd/server.crt --client-cert-auth=true --data-dir=/var/lib/etcd --initial-advertise-peer-urls=https://10.10.0.115:2380 --initial-cluster=liaok8s=https://10.10.0.115:2380 --key-file=/etc/kubernetes/pki/etcd/server.key --listen-client-urls=https://127.0.0.1:2379,https://10.10.0.115:2379 --listen-metrics-urls=http://127.0.0.1:2381 --listen-peer-urls=https://10.10.0.115:2380 --name=liaok8s --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt --peer-client-cert-auth=true --peer-key-file=/etc/kubernetes/pki/etcd/peer.key --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt --snapshot-count=10000 --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
root 7736 7648 8 16:30 ? 00:00:10 kube-apiserver --advertise-address=10.10.0.115 --allow-privileged=true --authorization-mode=Node,RBAC --client-ca-file=/etc/kubernetes/pki/ca.crt --enable-admission-plugins=NodeRestriction --enable-bootstrap-token-auth=true --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key --etcd-servers=https://127.0.0.1:2379 --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key --requestheader-allowed-names=front-proxy-client --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --secure-port=6443 --service-account-issuer=https://kubernetes.default.svc.cluster.local --service-account-key-file=/etc/kubernetes/pki/sa.pub --service-account-signing-key-file=/etc/kubernetes/pki/sa.key --service-cluster-ip-range=10.96.0.0/12 --tls-cert-file=/etc/kubernetes/pki/apiserver.crt --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
root 7744 7661 2 16:30 ? 00:00:03 kube-controller-manager --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf --bind-address=127.0.0.1 --client-ca-file=/etc/kubernetes/pki/ca.crt --cluster-name=kubernetes --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt --cluster-signing-key-file=/etc/kubernetes/pki/ca.key --controllers=*,bootstrapsigner,tokencleaner --kubeconfig=/etc/kubernetes/controller-manager.conf --leader-elect=true --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --root-ca-file=/etc/kubernetes/pki/ca.crt --service-account-private-key-file=/etc/kubernetes/pki/sa.key --use-service-account-credentials=true
root 7752 7695 1 16:30 ? 00:00:01 kube-scheduler --authentication-kubeconfig=/etc/kubernetes/scheduler.conf --authorization-kubeconfig=/etc/kubernetes/scheduler.conf --bind-address=127.0.0.1 --kubeconfig=/etc/kubernetes/scheduler.conf --leader-elect=true
root 7965 1 2 16:30 ? 00:00:03 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-container-image=k8s.gcr.io/pause:3.6
root 8294 8274 0 16:31 ? 00:00:00 /usr/local/bin/kube-proxy --config=/var/lib/kube-proxy/config.conf --hostname-override=liaok8s
root 9929 1346 0 16:33 pts/0 00:00:00 grep kube- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查看系统pod
root@liaok8s:/home/mainte# kubectl get pods --namespace kube-system
NAME READY STATUS RESTARTS AGE
coredns-64897985d-f9l5d 0/1 ContainerCreating 0 3m18s
coredns-64897985d-gtbp6 0/1 ContainerCreating 0 3m18s
etcd-liaok8s 1/1 Running 2 3m23s
kube-apiserver-liaok8s 1/1 Running 2 3m25s
kube-controller-manager-liaok8s 1/1 Running 2 3m23s
kube-proxy-2phdl 1/1 Running 0 3m18s
kube-scheduler-liaok8s 1/1 Running 4 3m22s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
发现dns关于网络的服务都是0个实例
同时检查node节点(目前就一个master节点,版本1.12.3)
root@liaok8s:/home/mainte# kubectl get node
NAME STATUS ROLES AGE VERSION
liaok8s Ready control-plane,master 4m9s v1.23.3- 1
- 2
- 3
查看版本
root@liaok8s:/home/mainte# kubectl version --short=true
Client Version: v1.23.3
Server Version: v1.23.3- 1
- 2
- 3
上面安装成功后如果通过查询kube-system下Pod的运行情况,会发现和网络相关的Pod都处于Pending的状态,这是因为缺少相关的网络插件。
安装网络
上面安装成功后如果通过查询kube-system下Pod的运行情况,会放下和网络相关的Pod都处于Pending的状态,这是因为缺少相关的网络插件,而网络插件有很多个(以下任选一个),可以选择自己需要的。
比较流行的几个为:
- flannel
- weave
- calico
这里以calico为例
Calico是一个纯三层的协议,为OpenStack虚机和Docker容器提供多主机间通信。Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,
它是一个纯三层的方法,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到剩余数据中心。calico原理参考
不要直接使用下面方式下载安装,因为node间通信,默认会选择第一个物理网卡的ip,会导致选错ip,无法通信
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml- 1
应该首先下载calico.yaml
wget https://docs.projectcalico.org/manifests/calico.yaml
修改yaml文件容器名称为:calico-node,搜索大概这个内容
containers:
- name: calico-node
image: docker.io/calico/node:v3.22.0- 1
- 2
- 3
新增一个变量 env部分
- name: IP_AUTODETECTION_METHOD
value: "interface=ens.*"- 1
- 2
意思是找物理主机的ip是使用ens开头的网卡,具体的本地物理网卡名称可以通过 ip addr查看
kubectl apply -f ./calico.yaml- 1
检测pod是否安装成功
root@liaok8s:/home/mainte# kubectl get pods --namespace kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-566dc76669-dwlrk 1/1 Running 0 4m4s 192.168.134.129 liaok8s <none> <none>
calico-node-gtpcw 1/1 Running 0 4m4s 10.10.0.115 liaok8s <none> <none>
coredns-64897985d-f9l5d 1/1 Running 0 64m 172.16.134.131 liaok8s <none> <none>
coredns-64897985d-gtbp6 1/1 Running 0 64m 172.16.134.129 liaok8s <none> <none>
etcd-liaok8s 1/1 Running 2 64m 10.10.0.115 liaok8s <none> <none>
kube-apiserver-liaok8s 1/1 Running 2 64m 10.10.0.115 liaok8s <none> <none>
kube-controller-manager-liaok8s 1/1 Running 2 64m 10.10.0.115 liaok8s <none> <none>
kube-proxy-2phdl 1/1 Running 0 64m 10.10.0.115 liaok8s <none> <none>
kube-scheduler-liaok8s 1/1 Running 4 64m 10.10.0.115 liaok8s <none> <none>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果安装失败很有可能是之前安装reset过没有清除完,清除后重装
1、删除安装插件
kubectl delete -f ./calico.yaml
2、检查所有节点上的网络,看看是否存在Tunl0
若存在Tunl0,将其删除
modprobe -r ipip
3、移除与Calico网络插件有关的网络配置文件
ls /etc/cni/net.d/
rm -rf calico相关文件
rm -rf /etc/cni/net.d/*calico*
删除所有calico的pod
for i in `kubectl get pods --namespace kube-system`; do
if echo $i | grep calico;then
echo $i | awk 'system("kubectl delete --force pod "$1" --namespace kube-system")'
fi
done;
4、重新安装
kubectl apply -f ./calico.yaml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
worker节点
同主节点kubelet和docker的驱动类型必须一致
修改/etc/docker/daemon.json 重启docker
"exec-opts": [
"native.cgroupdriver=systemd"
],- 1
- 2
- 3
注意worker节点也要获取这些镜像,虽然只有部分使用,比如pause,否则kubelet会出现拉取错误
之前是没有在worker节点拉取镜像,在主节点查看calico网络的event日志
kubectl describe pods calico-node-ncwdc -n kube-system
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 15m default-scheduler Successfully assigned kube-system/calico-node-ncwdc to pve-tmpl
Warning FailedCreatePodContainer 15m kubelet unable to ensure pod container exists: failed to create container for [kubepods burstable podb1e24b58-fe92-42d6-8857-61d4d36638a2] : mkdir /sys/fs/cgroup/devices/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podb1e24b58_fe92_42d6_8857_61d4d36638a2.slice: no such file or directory
Warning FailedCreatePodSandBox 15m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.6": Error response from daemon: Get "https://k8s.gcr.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning FailedCreatePodSandBox 14m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.6": Error response from daemon: Get "https://k8s.gcr.io/v2/": dial tcp 74.125.204.82:443: i/o timeout
Warning FailedCreatePodSandBox 10m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.6": Error response from daemon: Get "https://k8s.gcr.io/v2/": dial tcp 142.251.8.82:443: i/o timeout
Warning FailedCreatePodSandBox 8m35s (x13 over 15m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.6": Error response from daemon: Get "https://k8s.gcr.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning FailedCreatePodSandBox 8m6s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.6": Error response from daemon: Get "https://k8s.gcr.io/v2/": dial tcp 108.177.125.82:443: i/o timeout- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用之前的kubeadm join命令加入,如果忘记了可以在主节点获取
kubeadm token create --print-join-command- 1
kubeadm join 10.10.0.115:6443 --token dprbpd.gdjxay6moqf10d05 --discovery-token-ca-cert-hash sha256:a696588d58710779c758a0cdc4f0da3154af5d62f9b54420b5bb78d63f11e7a2- 1
加入成功后,可通过docker ps 查看
root@pve-tmpl:/home/mainte# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
96170aa46f83 k8s.gcr.io/pause:3.6 "/pause" 13 hours ago Up 13 hours k8s_POD_nginx_default_7c3d47ef-f478-40b4-b154-e9334cff14e3_1
6c627df7a7ca f109b1742d34 "start_runit" 13 hours ago Up 13 hours k8s_calico-node_calico-node-j8x2d_kube-system_3875d252-86cf-47e4-8c86-e74f32356d51_1
c30f1e963eae k8s.gcr.io/pause:3.6 "/pause" 13 hours ago Up 13 hours k8s_POD_calico-node-j8x2d_kube-system_3875d252-86cf-47e4-8c86-e74f32356d51_1
0426d0f18715 9b7cc9982109 "/usr/local/bin/kube…" 13 hours ago Up 13 hours k8s_kube-proxy_kube-proxy-kql69_kube-system_838b79c1-14c1-46e1-a806-868ca3fa87d3_2
773974f94bba k8s.gcr.io/pause:3.6 "/pause" 13 hours ago Up 13 hours k8s_POD_kube-proxy-kql69_kube-system_838b79c1-14c1-46e1-a806-868ca3fa87d3_1- 1
- 2
- 3
- 4
- 5
- 6
- 7
从节点回安装pause,calico,kubeproxy等组件,二进制组件
root@pve-tmpl:/home/mainte# ps -ef | grep kube
root 392 1 1 Feb10 ? 00:13:19 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-container-image=k8s.gcr.io/pause:3.6
root 967 947 0 Feb10 ? 00:00:08 /usr/local/bin/kube-proxy --config=/var/lib/kube-proxy/config.conf --hostname-override=pve-tmpl- 1
- 2
- 3
异常问题
calico容器异常
如果calico安装出现问题,一般都会导致kube-system下的calico相关的容器无法正常运行
root@liaok8s:/usr/local/bin# kubectl get pods --namespace kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-566dc76669-dllq7 1/1 Running 0 13h
calico-node-j2ffk 1/1 Running 0 13h
calico-node-j8x2d 1/1 Running 1 (13h ago) 13h
coredns-64897985d-f9l5d 1/1 Running 1 (13h ago) 17h
coredns-64897985d-gtbp6 1/1 Running 1 (13h ago) 17h
etcd-liaok8s 1/1 Running 3 (13h ago) 17h
kube-apiserver-liaok8s 1/1 Running 4 (13h ago) 17h
kube-controller-manager-liaok8s 1/1 Running 3 (13h ago) 17h
kube-proxy-2phdl 1/1 Running 1 (13h ago) 17h
kube-proxy-kql69 1/1 Running 2 (13h ago) 15h
kube-scheduler-liaok8s 1/1 Running 5 (13h ago) 17h- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
如果任意一个容器出现异常可以通过查看event发现问题
kubectl describe pod calico-node-j2ffk -n kube-system- 1
我这里之前没有修改calico.yaml直接apply导致出现了一个问题
Warning Unhealthy 23s (x3 over 25s) kubelet Readiness probe failed: calico/node is not ready: BIRD is not ready: Error querying BIRD: unable to connect to BIRDv4 socket: dial unix /var/run/calico/bird.ctl: connect: connection refused
Warning Unhealthy 20s kubelet Readiness probe failed: 2022-02-10 10:15:15.807 [INFO][250] confd/health.go 180: Number of node(s) with BGP peering established = 0- 1
- 2
这个问题就是calico通信无法识别主机间真实的物理ip引起的,可通过安装calicoctl诊断
安装请参考官网:https://projectcalico.docs.tigera.io/maintenance/clis/calicoctl/install
正确的结果为
在master节点,peer_address为多个从节点的ip,一个从节点一个,INFO为Established
root@liaok8s:/usr/local/bin# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+-------------------+-------+----------+-------------+
| 10.10.0.116 | node-to-node mesh | up | 12:29:59 | Established |
+--------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在worker节点,peer_address为多个从节点的ip和主节点的ip,一个从节点一个,INFO为Established
root@pve-tmpl:/home/mainte# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+-------------------+-------+----------+-------------+
| 10.10.0.115 | node-to-node mesh | up | 12:29:59 | Established |
+--------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意这些ip如果不是物理主机的ip, 变成了某个网卡的内部地址就会出现通信问题。
在主和工作节点上都会有个tunl0的网卡,工作节点的tunl0的ip地址就是pod的节点ip段
无法ping通clusterip和服务名
因为我之前重置过多次集群,没有指定固定的pod ip段,导致master和worker节点tunl0的ip不在同一个网段,导致无法正常通讯。
此时我们可以创建一个dnsutils镜像在kube-system下用来诊断网络
apiVersion: v1
kind: Pod
metadata:
name: dnsutils
spec:
containers:
- name: dnsutils
image: mydlqclub/dnsutils:1.3
imagePullPolicy: IfNotPresent
command: ["sleep","3600"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
通过 Kubectl 工具部署 NDS 工具镜像
通过 Kubectl 工具,将对上面 DNS 工具镜像部署到 Kubernetes 中:
-n:指定应用部署的 Namespace 空间。
$ kubectl create -f ndsutils.yaml -n kube-system- 1
进入 DNS 工具 Pod 的命令行
上面 DNS 工具已经部署完成,我们可也通过 Kubectl 工具进入 Pod 命令行,然后,使用里面的一些工具进行问题分析,命令如下:
exec:让指定 Pod 容器执行某些命令。
-i:将控制台内容传入到容器。
-t:进入容器的 tty 使用 bash 命令行。
-n:指定上面部署 DNS Pod 所在的 Namespace。
$ kubectl exec -it dnsutils /bin/sh -n kube-system- 1
通过 Ping 和 Nsloopup 命令测试
进入容器 sh 命令行界面后,先使用 ping 命令来分别探测观察是否能够 ping 通集群内部和集群外部的地址
首先确认下ndsutils的ip地址:192.168.57.136和第一个coredns相同。
进入容器后 :
/ # ping 192.168.57.136 coredns1能ping通,在同一个worker节点
PING 192.168.57.136 (192.168.57.136): 56 data bytes
64 bytes from 192.168.57.136: seq=0 ttl=64 time=0.058 ms
64 bytes from 192.168.57.136: seq=1 ttl=64 time=0.045 ms
^C
--- 192.168.57.136 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.045/0.051/0.058 ms
/ # ping 192.168.134.132 master对应的coredns无法ping通
PING 192.168.134.132 (192.168.134.132): 56 data bytes
^C
--- 192.168.134.132 ping statistics ---
11 packets transmitted, 0 packets received, 100% packet loss- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
查看容器的/etc/resolv.conf文件
/ # more /etc/resolv.conf
nameserver 10.96.0.10
search kube-system.svc.cluster.local svc.cluster.local cluster.local
options ndots:5- 1
- 2
- 3
- 4
发现nameserver指向的是service=kube-dns的集群ip
注意clusterip是不能ping的 可以通过ip:端口组合来访问。
此时ping下外网,不通的
/ # ping www.baidu.com
^C- 1
- 2
kube-dns的service实际是负载均衡到两个coredns上,其中一个是通的我们设置dns服务是这个通的试试
#nameserver 10.96.0.10
nameserver 192.168.57.138
search kube-system.svc.cluster.local svc.cluster.local cluster.local
options ndots:5- 1
- 2
- 3
- 4
再次测试发现正常
/ # ping www.baidu.com
PING www.baidu.com (110.242.68.4): 56 data bytes
64 bytes from 110.242.68.4: seq=0 ttl=52 time=44.204 ms
64 bytes from 110.242.68.4: seq=1 ttl=52 time=44.330 ms
64 bytes from 110.242.68.4: seq=2 ttl=52 time=43.863 ms
64 bytes from 110.242.68.4: seq=3 ttl=52 time=44.107 ms
64 bytes from 110.242.68.4: seq=4 ttl=52 time=44.148 ms
64 bytes from 110.242.68.4: seq=5 ttl=52 time=44.329 ms
64 bytes from 110.242.68.4: seq=6 ttl=52 time=44.210 ms
64 bytes from 110.242.68.4: seq=7 ttl=52 time=44.204 ms
64 bytes from 110.242.68.4: seq=8 ttl=52 time=44.113 ms
64 bytes from 110.242.68.4: seq=9 ttl=52 time=44.161 ms
^C
--- www.baidu.com ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 43.863/44.166/44.330 ms
/ # ping nginx.default
PING nginx.default (10.99.35.228): 56 data bytes
^C
--- nginx.default ping statistics ---
2 packets transmitted, 0 packets received, 100% packet loss
/ # ping httpd.default
PING httpd.default (10.98.37.38): 56 data bytes
^C
/ # wget nginx.default 注意属于两个不同的namespace所以需要在服务名称后加上.namesapce:端口访问,ip是不能直接ping通的 但是可以获取到dns的地址
Connecting to nginx.default (10.99.35.228:80)
index.html 100% |**********************************************************************************************************************************************************************************************| 615 0:00:00 ETA
/ # more index.html
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
/ #- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
这里可以想到 ,想着是否我们需要将pod的ip全部都设置为相同的段能访问是否就可行了,重置k8s,init
带上–pod-network-cidr=10.244.0.0/16 发现依然不行,会不是是coredns不应该在master节点上有个pod的了。
重新按照coredns,参考: https://github.com/coredns/deployment/tree/master/kubernetes
下载这两个文件
wget https://raw.githubusercontent.com/coredns/deployment/master/kubernetes/coredns.yaml.sed
wget https://raw.githubusercontent.com/coredns/deployment/master/kubernetes/deploy.sh- 1
- 2
执行命令(-i指定的参数是kube-dns clusterid的地址,默认是10.96.0.10),
注意先提前删除kube-system下的deploy=coredns,service=kube-dns
kubectl delete deploy coredns && kubectl delete svc kube-dns
chmod +x ./deploy.sh && ./deploy.sh -i 10.96.0.10 | kubectl apply -f -- 1
- 2
如果命令执行缺少jq,提前用yum或者apt-get或者apk安装,重新安装完成,在测试一切正常了,但是这个命令安装只是产生了一个coredns的pod,依然有点不知所以然虽然正常运行,后续在新增一个worker节点在测试下他的service分发的逻辑。
发布测试
主节点运行
kubectl run nginx --image=nginx- 1
- 2
查看nginx状态
root@liaok8s:/usr/local/bin# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 1 (13h ago) 14h 192.168.57.130 pve-tmpl <none> <none>- 1
- 2
- 3
查看执行过程(如果ready状态一直是0)
kubectl describe pod nginx- 1
通过pod ip访问http地址
root@liaok8s:/usr/local/bin# curl 192.168.57.130
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
创建service
root@liaok8s:/usr/local/bin# kubectl expose pod nginx --port=80
service/nginx exposed- 1
- 2
查看service
root@liaok8s:/usr/local/bin# kubectl get service nginx -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx ClusterIP 10.99.35.228 <none> 80/TCP 46s run=nginx- 1
- 2
- 3
通过集群ip负载访问容器
root@liaok8s:/usr/local/bin# curl 10.99.35.228
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
验证dns正确性
安装一个apahce httpd服务
kubectl run httpd --image httpd- 1
安装成功后进入worker节点宿主机,进入nginx容器
重新启动
如果因为异常断电,导致k8s停止,可设置集群自动启动
配置环境变量
#centos下
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile && source ~/.bash_profile
#debian下
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bashrc && source ~/.bashrc- 1
- 2
- 3
- 4
在主工作节点设置服务自启
systemctl enable kubelet && systemctl restart kubelet- 1
如果kubelet无法启动,很大可能是swap未正常关闭 ,sudo swapoff -a 再试试
图形管理工具
Kubernetes 容器编排已越来越被大家关注,然而使用 Kubernetes 的门槛却依然很高,主要体现在这几个方面:
- 集群的安装复杂,出错概率大
- Kubernetes相较于容器化,引入了许多新的概念,学习难度高
- 需要手工编写 YAML 文件,难以在多环境下管理
- 缺少好的实战案例可以参考
Kuboard,是一款免费的 Kubernetes 图形化管理工具,Kuboard 力图帮助用户快速在 Kubernetes 上落地微服务。
安装
如果您参考 https://kuboard.cn 网站上提供的 Kubernetes 安装文档,可在 master 节点上执行以下命令。
kubectl apply -f https://kuboard.cn/install-script/kuboard.yaml- 1
- 2
查看 Kuboard 运行状态:
# kubectl get pods -l k8s.eip.work/name=kuboard -n kube-system
NAME READY STATUS RESTARTS AGE
kuboard-756d46c4d4-qh6cm 1/1 Running 0 101m- 1
- 2
- 3
确保kuboard 处于 Running 状态
获取Token
您可以获得管理员用户、只读用户的Token。
Kuboard 有计划开发权限设置的功能,在这之前,如果您需要更细粒度的权限控制,请参考 RBAC Example
此Token拥有 ClusterAdmin 的权限,可以执行所有操作
# kubectl -n kube-system get secret $(kubectl -n kube-system get secret | grep kuboard-user | awk '{print $1}') -o go-template='{{.data.token}}' | base64 -d- 1
Kuboard Service 使用了 NodePort 的方式暴露服务,NodePort 为 32567;您可以按如下方式访问 Kuboard。
http://任意一个Worker节点的IP地址:32567/- 1
输入前一步骤中获得的 token,可进入 Kuboard 集群概览页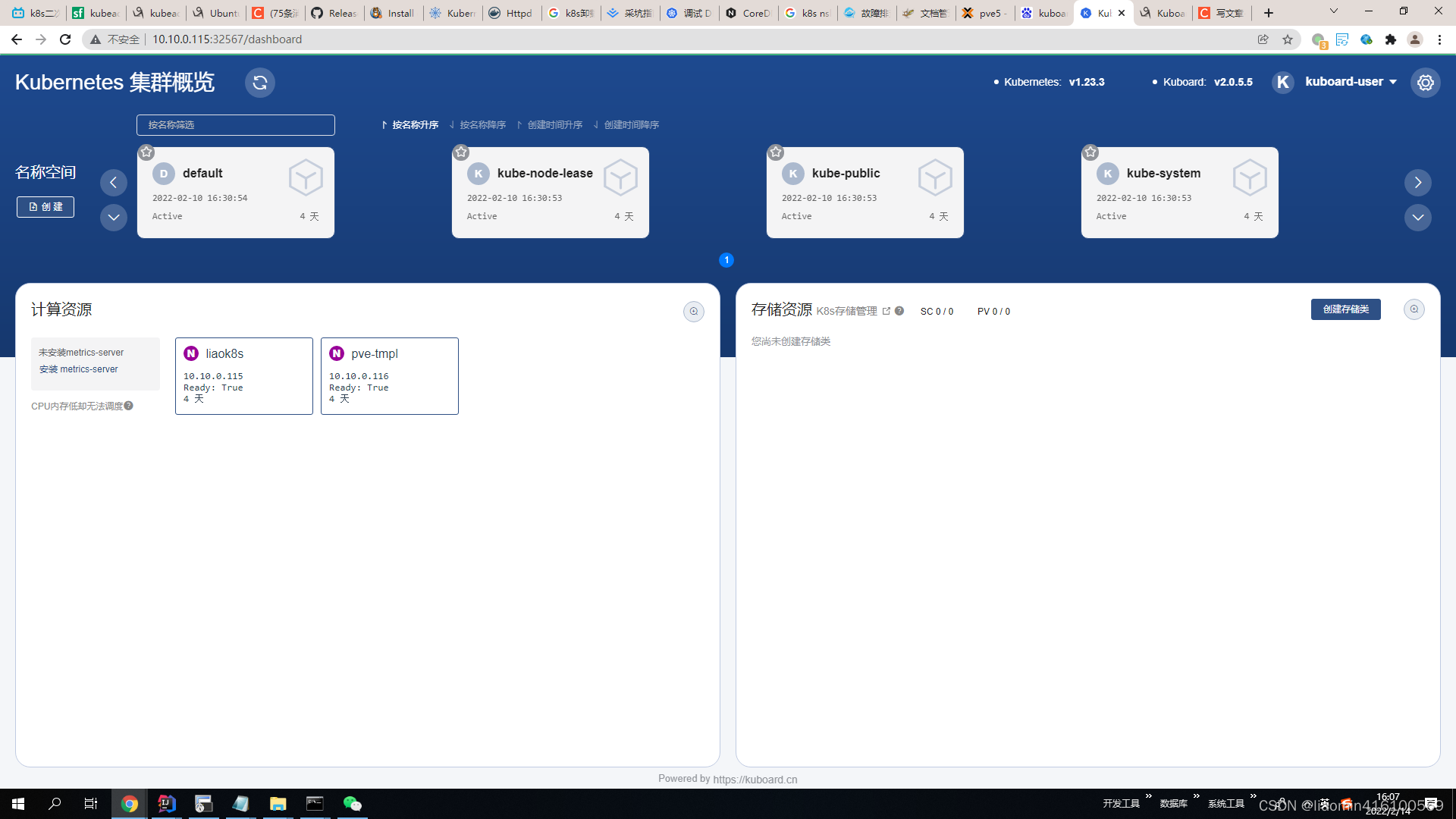
Kuboard v3.x
Kuboard v3.x 支持 Kubernetes 多集群管理。如果您从 Kuboard v1.0.x 或者 Kuboard v2.0.x 升级到 Kuboard,请注意:
- 您可以同时使用 Kuboard v3.x 和 Kuboard v2.0.x;
- Kuboard v3.x 支持 amd64 (x86) 架构和 arm68 (armv8) 架构的 CPU;
可参考kuboard官网:https://kuboard.cn/install/v3/install-in-k8s.html
在线安装:
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yamlK8S二次开发02-kubeadm安装k8s集群K8S二次开发02-kubeadm安装k8s集群K8S二次开发02-kubeadm安装k8s集群K8S二次开发02-kubeadm安装k8s集群K8S二次开发02-kubeadm安装k8s集群K8S二次开发02-kubeadm安装k8s集群

 浙公网安备 33010602011771号
浙公网安备 33010602011771号