
MongoDB 的主键 _id 为什么不是自增数字
MongoDB 从一开始就是设计作为分布式数据库的,为了方便不同的机器都能全局唯一的生成 _id,而自增 id 需要在多个服务器上同步其值,费时费力,所以自然得设计成长字符串。
ObjectId 是"_id" 的默认类型,举个官网的例子
db.products.insert(
[
{ _id: 11, item: "pencil", qty: 50, type: "no.2" },
{ item: "pen", qty: 20 },
{ item: "eraser", qty: 25 }
]
)
{ "_id" : 11, "item" : "pencil", "qty" : 50, "type" : "no.2" }
{ "_id" : ObjectId("51e0373c6f35bd826f47e9a0"), "item" : "pen", "qty" : 20 }
{ "_id" : ObjectId("51e0373c6f35bd826f47e9a1"), "item" : "eraser", "qty" : 25 }
ObjectId 是一个字符串,有 24 个字符,使用 12 字节的存储空间,每个字节两位十六进制数字。
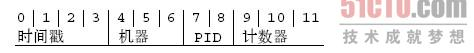
上文官网那个例子,ObjectId 的前 8 个字符可以被当做时间来计算,以秒做单位的。
new Date(parseInt('51e0373c', 16) * 1000).toJSON()
"2013-07-12T17:05:00.000Z"
接下来的 3 字节是所在主机的唯一标识符。通常是机器主机名的 MD5 散列值。这样就可以确保不同主机生成不同的 ObjectId,不产生冲突
parseInt('6f35bd', 16)
7288253
还为了确保同一台机器上并发多个进程的 ObjectId 是唯一的,那么还需要加入进程的 PID
// PID 是 33391
parseInt('826f', 16)
33391
最后来一个自动增加的计数器,来确保相同进程同一秒产生的 ObjectId 也是不一样的。
parseInt('47e9a0', 16)
4712864
MySQL 为什么需要使用自增数字做主键
参照 Mysql 索引使用以及优化策略 的 “为什么说主键最好使用与业务无关的自增字段”,
Innodb 使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
MongoDB 可没有聚族索引,没有那样的顾虑。
参考
Mysql 索引使用以及优化策略 的 “为什么说主键最好使用与业务无关的自增字段”,
MongoDB学习笔记-ObjectId主键的设计,本篇分析了 MongoDB 主键设计的部分源码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号