
【机器学习算法应用和学习_3_代码API篇】3.1 决策树
一、V1.0(sklearn版)
1.1简易API
注意,
1)基于树的算法只是计算划分前后混乱度(对每个分类样本数的某种加和)变化,并不对特征进行计算。所以不需要进行标准化、独热编码等。
2)输入的特征不能是字符串型。
import pandas as pd import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier,plot_tree from sklearn.model_selection import train_test_split #------1.预处理-------------------------- #导入数据 Xy=pd.read_csv("E://data/20190809_sklearn_DT.csv",skiprows=1,names=["fc","level","etimes","escore","sds","pds","sp","pp","target"]) X=Xy.iloc[:, :-1] y=Xy.iloc[:,-1:] #划分训练集测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) #------2.训练模型------------------------- #------训练模型 clf = DecisionTreeClassifier(criterion='entropy',max_depth=5).fit(X_train, y_train) #------绘制决策树 #绘制决策树 plt.figure(figsize=(10,10),dpi=1000) plot_tree(clf, filled=True) #决策树太大保存图片便于放大查看 plt.savefig("E://sklearn_DT_entropy.png") plt.show() #-----3.模型效果测试------------------------- #对测试集进行预测 y_predict = clf.predict(X_test) #y_test是dataframe的一列,y_predict是一维数组,所以需要将y_test转为一维数组 y_test_=y_test.values.T[0] #----输出分类错误数和准确度 print('错误分类的样本数: %d' % ( y_test_!= y_predict).sum() + '个') from sklearn.metrics import accuracy_score print('准确度: %.2f' % accuracy_score(y_test_, y_predict)) print() #----输出分类结果混淆矩阵 def my_confusion_matrix(y_true, y_pred): from sklearn.metrics import confusion_matrix labels = list(set(y_true)) conf_mat = confusion_matrix(y_true, y_pred, labels = labels) print("confusion_matrix(left labels: y_true, up labels: y_pred)") print("labels",'\t',end='') for i in range(len(labels)): print(labels[i],'\t',end='') print() for i in range(len(conf_mat)): print(i,'\t',end='') for j in range(len(conf_mat[i])): print(conf_mat[i][j],'\t',end='') print() my_confusion_matrix(y_test_,y_predict) print() #----输出分类报告 from sklearn.metrics import classification_report print("classification_report(left: labels):") print(classification_report(y_test_, y_predict)) #----输出特征权重 a=X.columns.values.tolist() b=clf.feature_importances_ for i in range(len(a)): print(a[i],',',b[i])
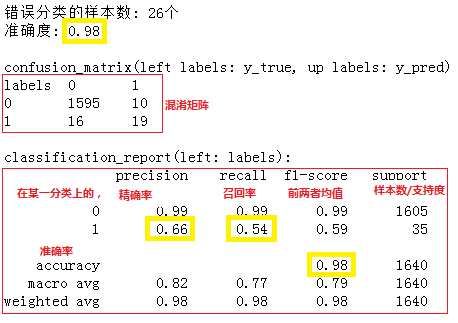
这个例子是一个分类不均衡问题,用决策树计算出来准确率是0.98,看起来非常高,但并没有什么用。精确率是0.66,也就是说“在所有被分类为正例的样本中,真正是正例的比例只有66%”;召回率0.54,即“所有实际为正例的样本中,被预测为正例的样本比例只有54%”。预测效果很差。
1.2复杂API
目的是尽量全。
1.3API资料
目的是前面不满足使用或不太理解可以从这里获得灵感。
在sklearn库里,决策树在tree模块,主要使用的是tree.DecisionTreeClassifier这个类。
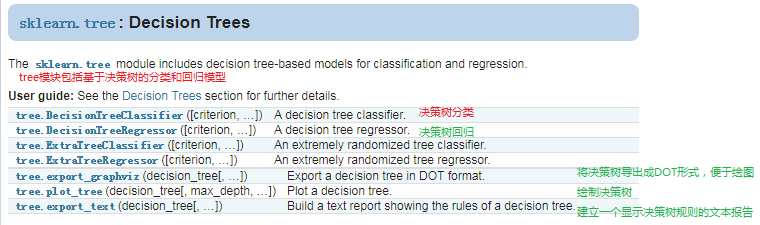
类tree.DecisionTreeClassifier:


from sklearn import tree model = tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)[source]
'''注意
参数值控制着树的大小,DecisionTreeClassifier的所有参数都可以省略。但在一些数据集上,默认参数值使得树完全生长且没有被剪枝会导致树非常大。为了减少内存消耗,应该通过设置参数控制树的生长;
在每次划分时,特征总是会被随机排列。所以,即使在同一个数据集上,最终结果可能也会差异很大。为了获得一个确定性的答案,应该设置一下random_state参数。
'''
'''参数说明
criterion:(必用,字符串,可选,默认gini)度量划分质量的标准,支持gini/entropy两个值。gini是基尼不纯度,entropy是信息增益
splitter:(未知含义,字符串,可选,默认best)在每个节点选择划分的策略,有best/random两个值。
max_depth:(可能需要,整型/None,可选,默认None)设定树的最大深度。如果是None,则尽量下分(节点一直展开知道所有的叶子精纯了或所有叶子只包含小于最小样本划分的样本)。
min_samples_split:(可能需要,整型/浮点型,可选,默认2)分裂内部节点所需要的最小样本树。如果是整数,则整数就是最小样本数,如果是浮点数,则浮点数是最小样本比例。
min_samples_leaf:(可能需要,整型/浮点型,可选,默认1)叶子节点所需要的最小样本数。值含义同上。
min_weight_fraction_leaf:(未知含义,浮点型,可选,默认0)叶节点(所有输入样本)所需权值之和的最小加权分数。当不提供sample_weight时,样本具有相同的权重。
max_features:(可能需要,整型/浮点型/字符串/None,可选,默认None)寻找最优分割点时的最大特征数。值含义同上,字符串则是auto/sqrt/log2一些对总特征数计算取值。
random_state:(未知含义,整型/RandomState instance/None,可选,默认None)随机状态。如果是整型,则是随机seed,如果是None则随机生成。
max_leaf_nodes:{可能需要,整型/None,可选,默认None)优先增长到最大叶子节点数。如果是None则不限制叶子数。
min_impurity_decrease:(可能需要,浮点型,可选,默认0)如果这种分离导致杂质的减少大于或等于这个值,则节点将被拆分。
min_impurity_split:(新版本已弃用使用min_impurity_decrease即可,浮点型,默认1e-7)提前停止叶子下分的门槛。如果叶子的不纯度大于这个门槛,则继续下分,否则不再下分。
class_weight:{未知含义,字典/列表/字典列表/balanced/None,默认None)
presort:(未知含义,布尔型,可选,默认False)在训练找到最好划分的模型中是否预分类以提高训练速度。在一个大数据集中,设置True可能会降低训练速度;在小数据集或有限深度数据集中,设置Treu可能会提高训练速度。
'''
'''类属性说明
classes_:(未知含义,数组)返回类标签列表
feature_importances_:(未知含义,数组)返回特征权重
max_features_:(未知含义,整型)最大特征数的推断值
n_classes_ :{未知含义,整型/列表)类数目
n_features_:(未知含义,整型)执行匹配时的特征数
n_outputs_:(未知含义,整型)执行匹配时的输出数
tree_:(未知含义,树对象)
'''
'''类方法说明(fit/predict/score很多算法是一样的)
apply(self, X[, check_input]):返回给定某个样本预测的叶子索引
decision_path(self, X[, check_input]):返回给定某个样本在决策树上的路径
fit(self, X, y[, sample_weight, …]):从训练集(X,y)建立决策树分类器
get_depth(self):返回决策树的深度
get_n_leaves(self):返回决策树叶子的个数
get_params(self[, deep]):获取这个估计量的参数
predict(self, X[, check_input]):为给定的X预测类别或回归值
predict_log_proba(self, X):为给定的X预测类的可能性log值
predict_proba(self, X[, check_input]):为给定的X预测类的可能性
score(self, X, y[, sample_weight]):返回给定测试集的平均精确度
set_params(self, \*\*params):设置这个估计量的参数
'''
相关例子:
tree.DecisionTreeClassifier底部关联了几个例子,初学者推荐阅读这三个:
Plot the decision surface of a decision tree on the iris dataset
Understanding the decision tree structure
第一个是利用iris数据集多个特征进行决策树训练并绘制出决策树结构,这是决策树应用的常规流程;
第二个是比较几个分类算法对三个自定义数据集进行训练的精确度大小,可以看到不同算法调用其实非常相似;
第三个是决策树一些方法的作用,比如给定一个样本怎样显示他的预测分类等等,可以基于这篇文章更好地理解上面类的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号