



Hadoop-3.3.3分布式集群的文件配置,配置启动hadoop历史服务和启动日志聚集
一、分布式集群的文件配置
涉及$HADOOP_HOME/etc/hadoop路径下的5个文件
workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
个人的配置
hadoop100 hadoop102 hadoop103

首先修改workers
进入$HADOOP_HOME/etc/hadoop
vim workers
编辑自己的主机节点。注意!每行一个,默认为把本机节点同时作为数据节点(dn)和名称节点(nn),如果只想做名称节点(nn)就不要添加那台主机名

之后修改core-site.xml
<configuration>
<!-- The address of Namenode -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<!-- The address of saving data -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.3/data</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<!-- nn web access address -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<!--n 2nn web access address -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<!-- Specifies MR to run on yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- Historical server server-side address -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
</property>
<!-- The web address of the historical server -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.3</value>
</property>
</configuration>
修改yarn代码
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Specify the address of resourcemanager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- The way to Specify MR is shffule -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Enable the log aggregation ferture -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- Set the address of the log aggregation server -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop100:19888/jobhistory/logs</value>
</property>
<!-- Set the log retrntion period to 7 days -->
<property>
<name>yarn.log-aggregation,retain-seconds</name>
<value>604800</value>
</property>
</configuration>
然后将配置分发到其他机器中
cd /opt/module/hadoop-3.3.3/etc xsync hadoop/
分发脚本在这里hadoop 将nn节点的环境配置同步到dn节点 - Evelynlb - 博客园 (cnblogs.com)
然后初始化hdfs
cd /opt/module/hadoop-3.3.3/sbin
hdfs namenode -format
遇到问题

权限不足,就执行以下命令
sudo chmod 777 /opt/module/hadoop-3.3.3/
问题解决,重新初始化
hdfs namenode -format
不报错就是成功了,出错可能是在编辑上述5个文件时出错了
进入data路径
cd /opt/module/hadoop-3.3.3/data
然后像图里一样进入路径查看namenode的version
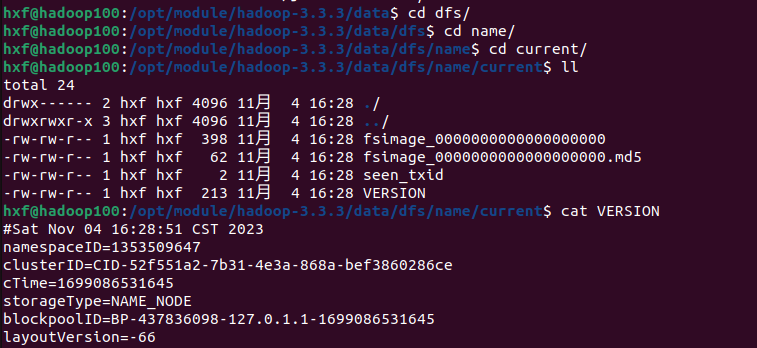
每次初始化的namenode的version都是不同的,namenode和datanode的通信需要一致的version,如果后面错误初始化了datanode会无法通信就是因为version不同
然后进入
cd /opt/module/hadoop-3.3.3/sbin
输入
start-dfs.sh
出现问题
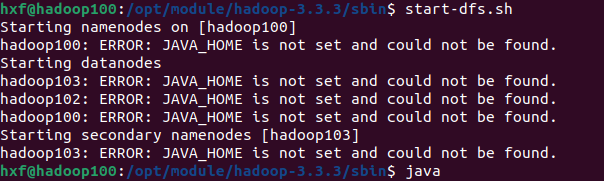
但JAVA_HOME是配置过的了,百度一下,发现是hadoop的环境除了问题
编辑hadoop-env.sh 文件
sudo vim /opt/module/hadoop-3.3.3/etc/hadoop/hadoop-env.sh
在里面添加
export JAVA_HOME=/opt/module/jdk1.8.0_391
保存,重新启动hdfs
start-dfs.sh
成功启动
然后在配置又Resourcemanager的机器上启动yarn
start-yarn.sh
使用jps查看进程,和自己的预先配置无误就可以。
在hadoop100上输入以下命令,检查hdfs的情况
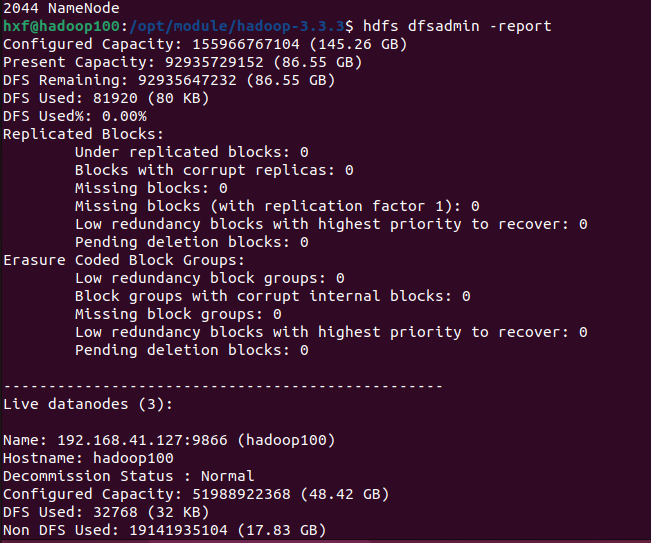
hdfs dfsadmin -report
发现只返回了hadoop100的dn信息,102,103均未返回。
于是在102,103中也输入同样命令,直接报错report: Call From hadoop102/127.0.1.1 to hadoop100:8020 failed on connection exception: java.net.ConnectException: Connection refused;
显示拒绝。同时只能在100中进入hadoop管理界面(hadoop100:9870),102中进入yarn的管理界面(hadoop102:8088)
在hadoop管理界面中也只能看到一个dn,(虽然3台机器使用jps都能看到dn的信息)
1:认为是网络问题,3台机器互ping,但网络畅通,不是这个原因
2:认为防火墙问题,开启防火墙,开放9870,8088等端口后,在关闭防火墙。但没有作用。不是防火墙的原因
3:ConnectionRefused - HADOOP2 - Apache Software Foundation,去官网查询,发现可能是主机名称映射的问题,查看主机名称映射
sudo vim /etc/hosts
发现有多余的映射字段
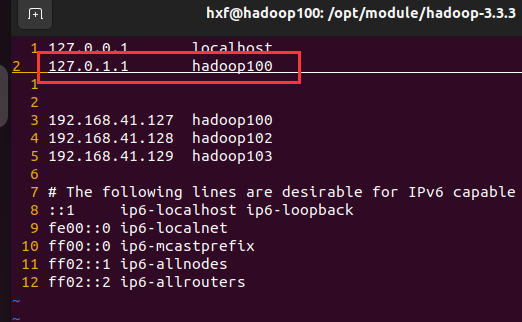
在100,102,103中均删除,并重启
再次
hdfs dfsadmin -report
显示有3个dn,然后尝试用100登录hadoop管理界面和yarn管理界面,都能登录,用102也能登录,问题解除。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号