Design a web crawler(like Dropbox, Google, Alibaba)
analysis this problem based on the 4S
Scenario:
Given seeds, crawl the web.
but how many web pages? for how long? and how large?
1.6M web pages per second, average size of per web page: 10KB
Service:
what service do i have to provide?
crawler, task service and storage service
Storage:
use DB to store tasks and use Big table to store web pages
//after we have a solution, then we need to think about the scaling thing
Scale:
主要是处理当数据量非常大 以及其他可能出现的问题
详见博客《The scale step when design web crawler》
Now let’s start from a simple crawler:
in this crawler, we are given the URL of news list page. and
we will send http requests and extract the title of each of them.
what if the input url seeds are thousands of millions? and we can’t just do that one by one, instead, we need to multi-thread
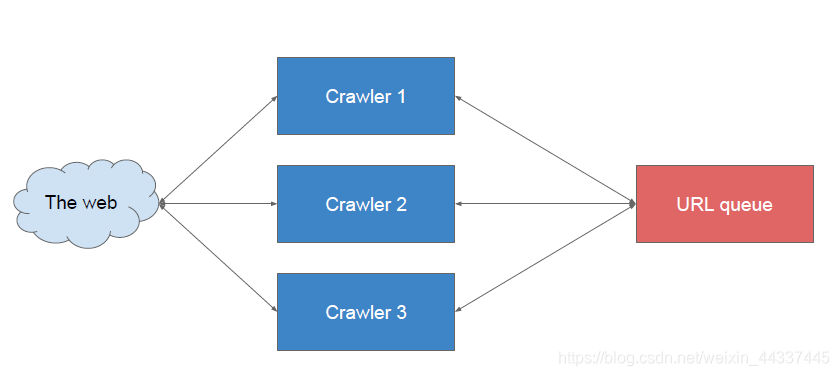
however, more thread doesn’t necessarily mean higher performance
because:
the CPU number limitation
the port number limitation(the port we use is the thread we have)
network bottle for a single machine

 浙公网安备 33010602011771号
浙公网安备 33010602011771号