互联网那些事 | MQ数据丢失
本系列故事的所有案例和解决方案只是笔者以前在互联网工作期间的一些事例,仅供大家参考,实际操作应该根据业务和项目情况设计,欢迎大家留言提出宝贵的意见
背景
小王和小明分别维护分布式系统中A、b两个服务,有一个场景是 A服务会向B服务通过MQ发送事件并且推送用户信息,然后B服务保存用户信息。
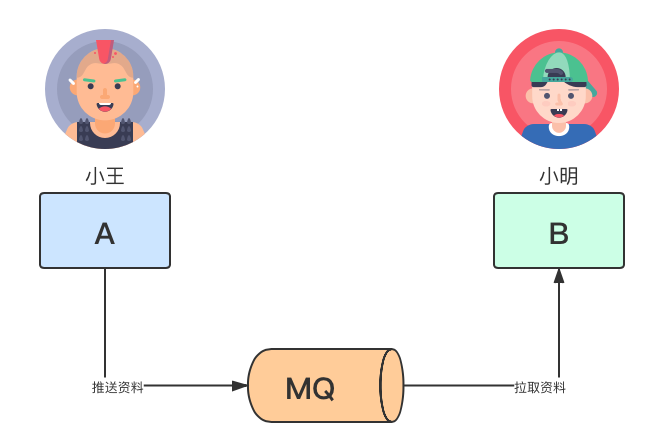
有一天,小王和小明因为一件事讨论得热火朝天、互不相让,事情由来如下:
- 风控部的童鞋找小明说在B服务的数据库找不到一些用户资料
- 小明经过排查,B服务表里确实没有这批用户的数据,在日志里偶尔看到了一些Redis连接超时异常,小明想小王手动帮忙重推试试
- 小王经过排查,确保自己已经成功推送了那几个用户的数据,并且推送的时候A服务并没有发现MQ异常,觉得自己没有义务去帮忙重推,应该小明自己解决
这时候,在一旁扫地的清洁工老梁过来调解,并帮忙排查分析,导致这个问题的主要原因如下:
- B服务在接受MQ的处理类捕获了异常,因为异常并没有抛出,所以框架默认自动回复了ACK,MQ认为已经消费者处理成功,就不再重复投放到队列,但此时方法体内因为工具包出现Redis连接超时,抛出异常,导致消息并没有被正常处理
伪代码如下:
@RabbitHandler
public void handle(byte[] message) {
try {
t = parseBody(messageStr);
} catch (Exception e) {
log.error("消费消息失败", e.getCause());
}
}
private void handleMessage(T t) throws MQHandleException {
//唯一标识
String key = t.getLockedId();
//获取锁
DistributedLock lock = DistributedLockFactory.getLock(key);
try {
// 解决分布式服务提交相同资料并发问题
lock.lock(CacheConstants.LOCK_WAIT_TIME, CacheConstants.LOCK_LEASE_TIME, CacheConstants.DEFAULT_CACHE_UNIT);
// 处理业务逻辑
handleBusinessLogic(t);
} catch (LockException e) {
throw new MQHandleException(e);
} finally {
// 释放锁
lock.unLock();
}
}
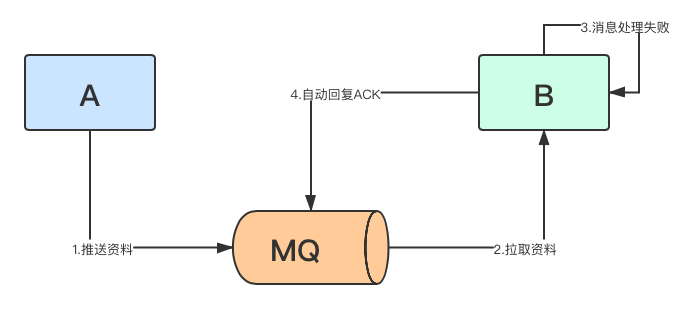
-
频繁Redis超时是因为A、B服务共用一个Redis,A服务Key太多把Redis内存资源占满了(也可能连接占满),导致了B服务经常出现连接超时(该故障不是本章主要关注目标)
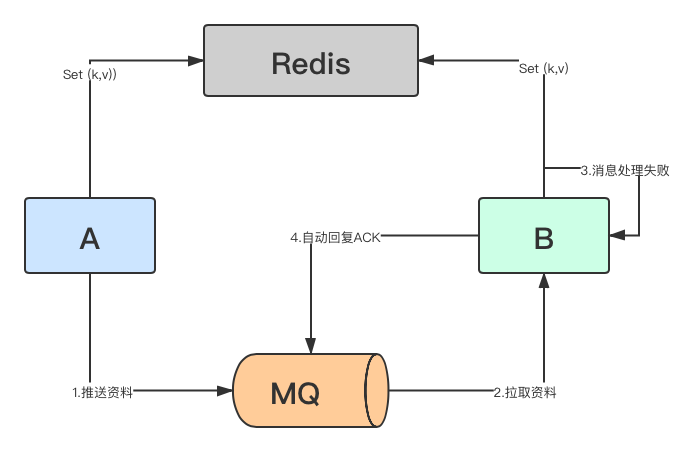
-
B服务在已经成功接受到消息后,没有把消息先保存起来,所以也导致了自身并没有能力重跑
清洁工老梁跟小王和小明进行一番详谈后,了解到他们主要需求有两个:
- B服务尽可能自己重新消费信息,而不是一昧依赖A服务手动重推
- B服务对已接收到的消息,能自己重新消费,当然,这里指的是有意义的消息,如果一些本身A服务推送过来的消息就是有问题的,例如格式错误之类的,这些B服务可以要求A重推
解决思路
经过上面的分析,老梁的解题思路主要分为两个方向:
- B服务建立自己的本地异常消息事件表。
- B服务做异常分类,只对可以重跑的消息事件进行重跑
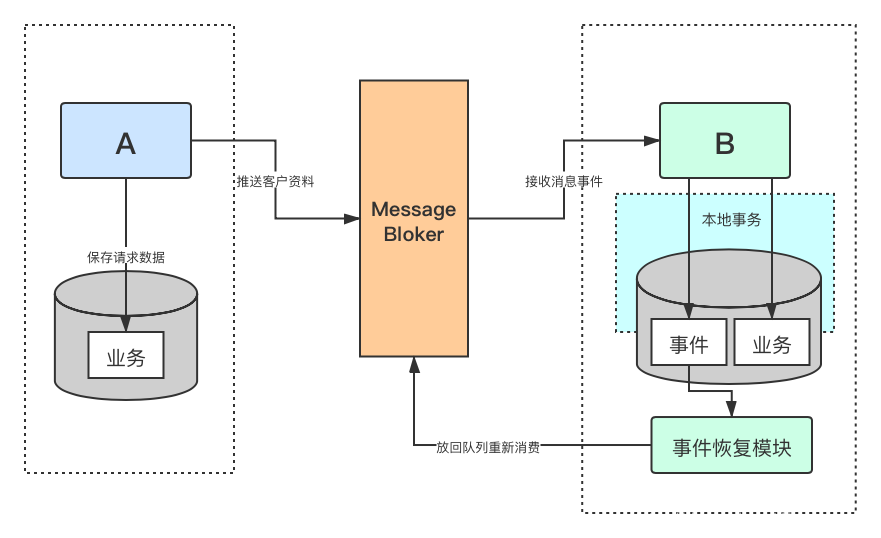
本地异常消息事件表
一般来说,常见的微服务架构实现最终一致性有三种模式:可靠事件模式、业务补偿模式、TCC模式。这里AB服务是通过业务补偿模式实现最终一致性,但这里又跟我们一般的分布式架构的事务问题不同,这里我们只需要保证B服务能最终把正常消息事件消费成功即可。
实现思路:
- 建立一张本地异常消息事件表,为了避免太多数据库IO操作,这里只会记录异常事件
- 提取一个通用消息处理层,统一保存异常消息事件,并进行状态更新
- 提取一个事件恢复模块,统一对失败事件进行追踪
- 对于重跑仍失败消息事件,设置一个重跑次数上限,进行自动重跑,可以通过调度任务去做(事件恢复模块),当重跑多次仍然失败(像网络异常和数据库异常之类,短时间不会被修复),则后期进行人工重跑
表设计

针对于B服务,对于收到的MQ信息没有进行有效的记录,而且MQ信息处理之后,存在修改错误,没法进行对应信息补充修复的功能,增加通用消息处理层,进行消息体的记录和回溯。 在获取消息之后进行一次记录,进行幂等操作和对应的状态更新, 消息状态在业务相关操作完成后,标记为处理完成,认为对应消息状态结束。
这里hash_value是对请求体进行hash计算得出来的一个值,例如:MD5、SHA-2,保证每个不同请求的hash码不一样,相同的请求hash码相同,可以用于幂等控制。
表大致操作流程:
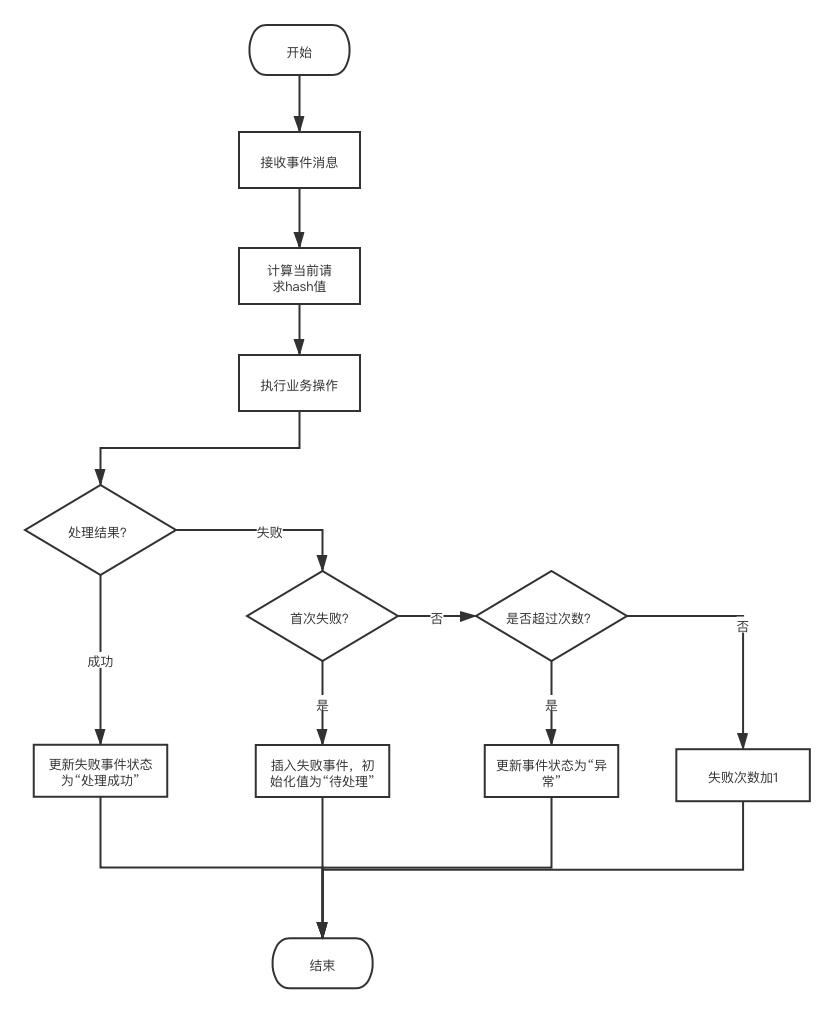
异常消息状态设计
异常消息有4个状态
- 待处理 当系统消费失败时,会对特定的异常插入异常事件表,初始状态为
待处理 - 处理中 当失败恢复模块开始执行任务时会把当前异常事件状态设置为
处理中 - 处理完成 当失败事件重跑成功后,会把当前异常事件状态设置为
处理完成 - 异常 当失败事件重跑超过上限次数后,会把当前异常事件状态设置为
异常,等待后期人工重跑
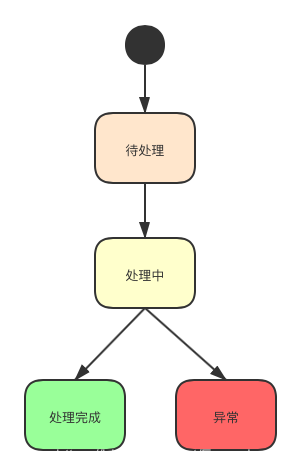
事件恢复模块
失败事件队列在这里是采用数据库表代替
异常分类
因为并非所有的异常都能重跑就能解决问题,我们只能针对可以修复的异常进行重试,这里把异常分为两大类:
- 可修复异常:可修复异常指的是可以通过重跑解决的异常,如:数据库超时、数据库缺少字段、Redis获取锁失败、处理逻辑有问题导致信息缺失、系统升级导致消费失败、网络问题、服务器不稳定等引起。
- 可立即修复异常:指一些可以通过立即重试就能恢复的异常。例如短暂的网络中断引起的异常,一般可以在功能代码级进行立即重试,可以使用spring-retry等组件
- 延迟修复异常:指一些短时间内不能立即恢复的异常,需要延迟执行,等待故障修复。例如依赖的下游系统正在升级,导致一段时间服务接口中断不可以用,需要等待服务启动才能使用,一般通过定时任务设定一定时间间隔或者重跑次数去解决
- 人工修复异常:指系统没办法直接修复,出现了一些未知异常或者短时间内不可解决的异常,例如Redis宕掉无法预知修复时间、上线时脚本遗漏导致表里缺少字段等,需要人工干预进行重跑,一般通过后台管理页面操作
- 不可修复异常:不可修复异常指不能通过重跑就能解决的异常。如:上游系统传输格式有问题、消息事件内容本身有误等引起的异常,这些即使重跑也解决不了问题,应该要从上游系统或者根源去解决。
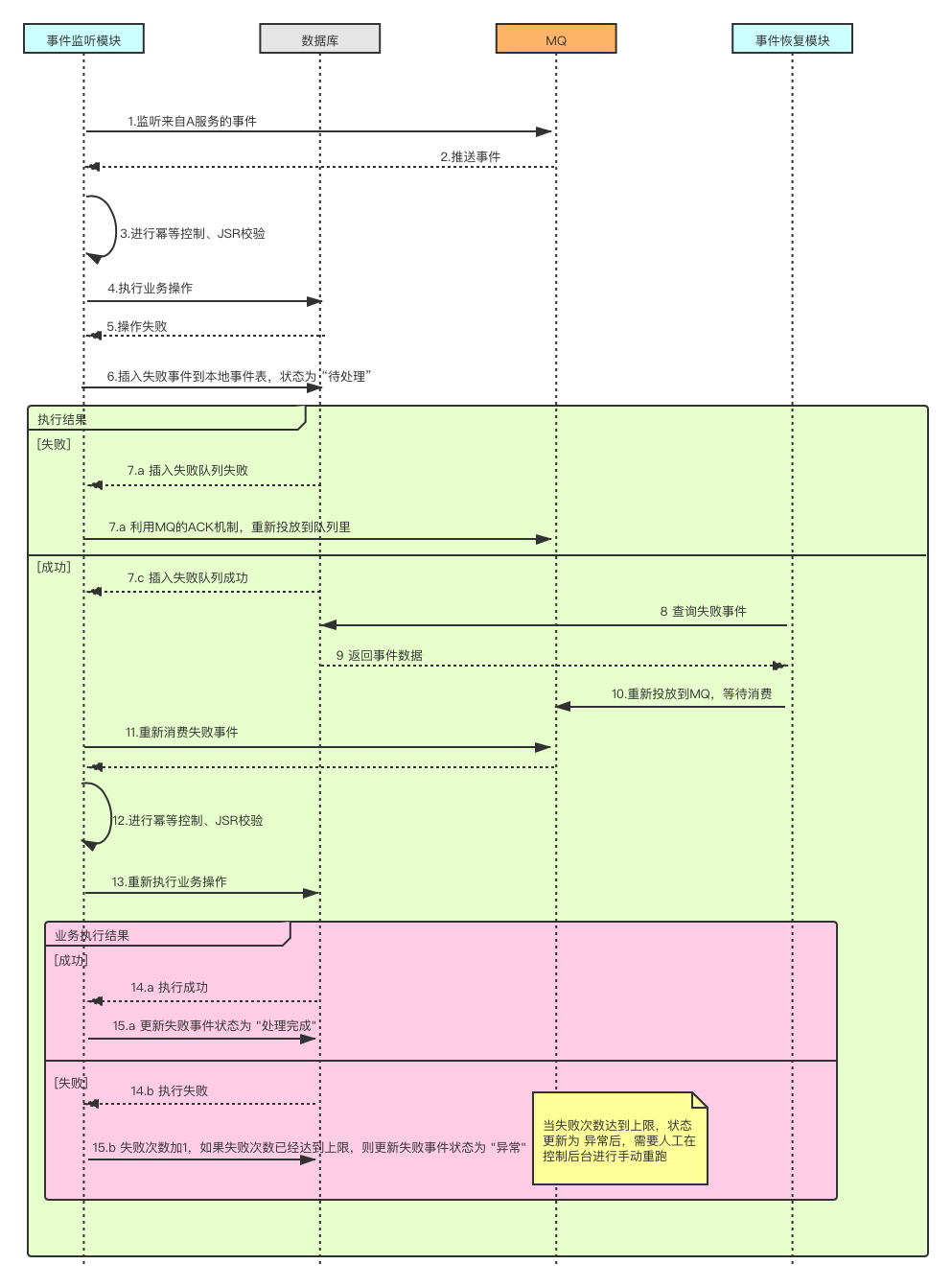
B服务异常处理流程
最后小明负责的B服务按照老梁的思路,重新调整了代码,异常处理流程如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号