《构建之法》第四次作业之结对编程
| 作业要求地址 | 点一下 |
|---|---|
| GitHub项目地址 | 点一下 |
| 结对伙伴博客 | 点一下 |
同样,和上次的程序一样,我们在老师的同意下,采用java+IDEA完成本次作业
零、项目需求
输入文件名以命令行参数传入。例如我们在命令行窗口(cmd)中输入:
wordCount.exe input.txt则会统计input.txt中的以下几个指标
统计文件的字符数:
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
输出的单词统一为小写格式
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的格式为
· characters: number · words: number · lines: number · <word1>: number · <word2>: number · ...
一、PSP表格
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
一个功能完备的程序不是一蹴而就的。通过将词频统计的需求划分为4个部分,可将一个大任务划分为可操作的小任务,同时最好按照任务难度或紧急程度指定各个任务的完成次序。因此,在动手开发之前,要先估计将在程序各模块开发所需耗费的时间,以及完成整个项目所需的时间,将这个[估计值]记录下来,写成PSP 的形式。
PSP的目的是:记录工程师如何实现需求的效率,和我们使用项目管理工具(例如微软的Project Professional,或者禅道等)进行项目进度规划类似。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 300 | 430 |
| Development | 开发 | 90 | 110 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 100 | 120 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | 30 | 20 |
| · Test Report | · 测试报告 | 10 | 15 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 395 | 430 |
二、结对过程
了解完题目后,简单讨论了项目需求以及项目规范,在明确了需求后,开始使用阿里巴巴开发规范进行开发。程序主要分为统计行数,字母数,单词数,分为三个功能。分配任务后,写出了初代版本,然后调试,修改,进行单元测试。最终形成最终版本。
同时我们命名变量统一使用驼峰命名法。

三、解题思路
看完了整个题目,设计了五个类(不包含内部类)来实现此次需求。
基本的流程便是:访问Main主类通过IO输入流传入文件,首先利用String,StringBuffer类经过简单的处理后,调用我们写好的类利用正则表达式进行统计各种数据,返回即可。详细过程见源代码及其注释:
流程如图:
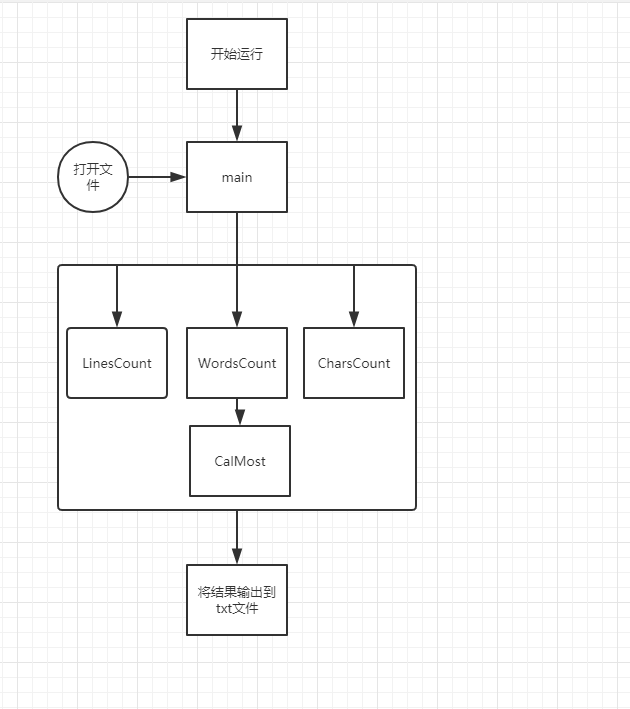
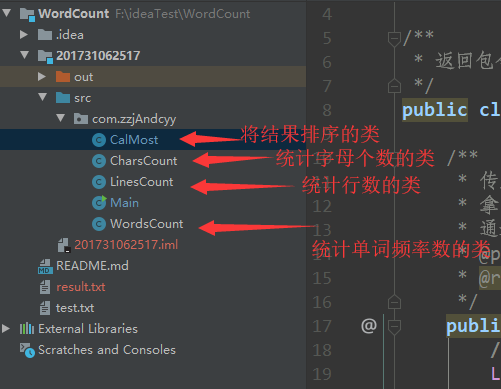
- Main类:程序入口主类,输入需要分析的文件路径,调用其他类的方法,最后在程序中生成result.txt文件
package com.zzjAndcyy;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintStream;
import java.util.List;
import java.util.Map;
import java.util.Scanner;
/**
* 运行主类
*/
public class Main {
/**
* 主要的运行方法,运行该方法,输入文件路径 如F:\test.txt
* 将会自动生成result.txt结果文件
* @param args
*/
public static void main(String[] args) {
System.out.println("请输入想要统计的文件绝对地址(如:F:\\test.txt):");
Scanner sc = new Scanner(System.in);
// 想要读取的文件地址
String url = sc.nextLine();
try {
BufferedReader bufferedReader = new BufferedReader(new FileReader(url));
StringBuilder stringBuilder = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
// 进行必要的文本处理操作,比如换行符的处理
stringBuilder.append(line).append("\n");
}
// 将文本中的标点符号进行处理
String content = stringBuilder.toString()
.replace(".", " ")
.replace(",", " ")
.replace("!", " ")
.replace("?", " ");
// 分别创建字母,单词,行数统计工具类,去完成统计
CharsCount charsCount = new CharsCount();
WordsCount wordsCount = new WordsCount(content);
LinesCount linesCount = new LinesCount();
// 调用相应的方法去得到结果
// 行数
int lines = linesCount.linesNumber(url);
// 字母数
int characters = charsCount.charsNumber(content);
// 单词数
int words = wordsCount.getSum();
// 前十高频词
List<Map.Entry<String, Integer>> mostList = new CalMost().mostWords(wordsCount.getMap());
// 创建输出的结果result.txt文件
PrintStream printStream = new PrintStream("result.txt");
System.setOut(printStream);
System.out.println("characters: " + characters);
System.out.println("words: " + words);
System.out.println("lines: " + lines);
System.out.println("文章中出现的高频词如下:");
for (Map.Entry<String, Integer> i : mostList) {
System.out.println("<"+i.getKey()+">: " + i.getValue());
}
// 关闭相应的IO流,保证安全
printStream.close();
bufferedReader.close();
} catch (IOException e) {
System.out.println("文件不存在");
e.printStackTrace();
}
}
}
- LinesCount 类: 行数统计类,通过使用此类的方法,返回得到文本中的行数
package com.zzjAndcyy;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
/**
* 统计行数
*/
public class LinesCount {
/**
* 根据文件的名称,创建输入流去读取文件的内容
* 可根据整行读取实现记录读取次数,也就是行数
* @param filePath
* @return
*/
public int linesNumber(String filePath) {
// 记录行数
int sum = 0;
try {
FileReader fileReader = new FileReader(filePath);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line;
// 通过循环不断整行读取文件
// 同时记录读取次数即可
while ((line = bufferedReader.readLine()) != null) {
if (line.length() != 0 && !line.matches("\\s+")) {
sum++;
}
}
} catch (IOException e) {
e.printStackTrace();
}
return sum;
}
}
- CharsCount类:字母统计类,通过使用此类的方法,返回得到文本中的字母数
package com.zzjAndcyy;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 提供一个方法,
*/
public class CharsCount {
/**
* 根据正则表达式来统计字母数
* @param content
* @return
*/
public int charsNumber(String content) {
// 编写正则表达式查询规则
String regex = "\\p{ASCII}";
Pattern pattern = Pattern.compile(regex);
// 开始去匹配
Matcher matcher = pattern.matcher(content);
// 定义一个int sum 去存储字母数目
int sum = 0;
while (matcher.find()) {
// 找到一个字母,累加
sum++;
}
// 匹配完毕,返回结果
return sum;
}
}
- WordsCount类:各单词出现频率统计类,通过使用此类的方法,返回得到文本中的单词与出现个数的数据结构
package com.zzjAndcyy;
import java.util.HashMap;
public class WordsCount {
/**
* 使用HashMap集合
* key保存单词,使得其保证唯一性
* value 存储该key(即单词)的次数
*/
private HashMap<String, Integer> map = new HashMap<>();
/**
* 根据题意
* 存储字母数大于4的单词 所在文章中出现的次数
*/
private int sum = 0;
/**
* 提供接口,返回sum的值
* @return
*/
public int getSum() {
return sum;
}
/**
* 提供接口,返回最后的HashMap查询结果
* @return
*/
public HashMap<String, Integer> getMap() {
return map;
}
public WordsCount(String content) {
// 构造正则表达式,去根据空格拆分整篇文章
// temp字符串数组将保存所有的单词
String[] temp = content.split("\\s+");
// 根据题意
// 构造正则表达式筛选规则:以字母开头且长度大于4的单词
String reg = "^[a-zA-Z]{4,}.*";
// 循环遍历这个数组,利用正则表达式去匹配
for (String i : temp) {
if (i.matches(reg)) {
// 匹配成功,计数加1
sum++;
// 根据题意,不区分大小写,所以统一转换成小写
String smallW = i.toLowerCase();
// 如果HashMap中没有这个key,则说明第一次出现该单词,放入集合,记录频率为1
if (!map.containsKey(smallW)) {
map.put(smallW, 1);
} else {
// 到这里说明HashMap中有这个key,将其出现次数累加即可
int num = map.get(smallW);
map.put(smallW, num + 1);
}
}
}
}
}
- CalMost类:将结果按照题目的要求排序,从高频词到低频次,如果相同,则按照字典顺序排列
package com.zzjAndcyy;
import java.util.*;
/**
* 返回包含单词和它数量的HashMap
*/
public class CalMost {
/**
* 传入已经统计完全的map集合
* 拿到排列后的所有单词数
* 通过List 返回 前十个高频词 即可
* @param map
* @return
*/
public List<Map.Entry<String, Integer>> mostWords(HashMap<String, Integer> map) {
// 将map中的所有键值对给新的集合list
List<Map.Entry<String, Integer>> list = new ArrayList<>(map.entrySet());
// 利用自己写的比较器,去根据单词的频率去排序
list.sort(new MapComparator());
// 返回list 前十个 数据,也即出现的前十的高频词
return list.size() < 10 ? list.subList(0, list.size()) : list.subList(0, 10);
}
/**
* 新建一个内部类 MapComparator 比较器
* 重写比较方法,使得能够让数据正确比较
*/
private class MapComparator implements Comparator<Map.Entry<String, Integer>> {
// 重写接口的比较方法,使得能够达到我们想要的比较效果
// 首先根据频率比较,如果频率相同,比较字典顺序
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue()) != 0 ? o2.getValue().compareTo(o1.getValue()) : o1.getKey().compareTo(o2.getKey());
}
}
}
从0到最后能够完成需求,我和陈远杨互相承担了很多,比如在遇到先去筛选前10高频词,然后如果频率相同用字典排序,我们就在想能不能用一个比较器类就达到效果。最终,两人通过题目的需求和查找相关资料实现了这个功能。
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue()) != 0 ? o2.getValue().compareTo(o1.getValue()) : o1.getKey().compareTo(o2.getKey());
}
四、代码的复审
1.关于文本标点符号,特殊字符的处理
第一次代码完工过后,通过测试简单的样例,我们以为达到了最后的要求,从网上下载了泰戈尔的《飞鸟集》进行测试。没想到就翻车了,比如把 love和love.识别为两个单词。
我们知道可以修改通过正则表达式或者最开始处理一下文本去修改。
String content = stringBuilder.toString()
.replace(".", " ")
.replace(",", " ")
.replace("!", " ")
.replace("?", " ");
2.性能优化
从一开始的将文本读入使用String来存储,发现性能实在是优化的空间太大。修改为StringBuilder去存储。
存字符串,Java有三种常规的方式,String、StringBuffer、StringBuilder
String一般用来存储常量更相对方便,底层实现是不可修改的char数组,导致每一次String的变化,都会使得新建一个String,而不能使得String动态改变。性能将会下降,在这一点上,是我们放弃String的原因。
StringBuffer和StringBuiler的底层char数组都可以动态变化, 区别在于很多方法是否加锁,StringBuffer更多的用于多线程,因为它的很多方法加了同步锁,而StringBuiler虽然没有同步机制,但更加适用于单线程,效率性能更快。
所以我们最后选择了StringBuiler进行字符的处理。
五、运行测试
我们首先进行飞鸟集的测试:

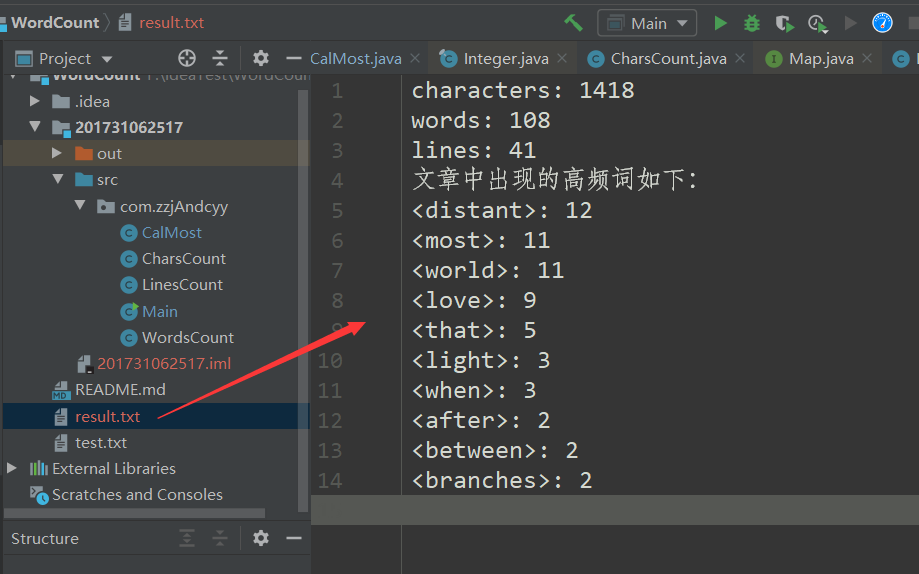
可以看到,结果很正确,那么我们就在思考,我们的程序统计的极限是哪里呢?
陈远杨同学采用了13MB大小的TXT文档做测试
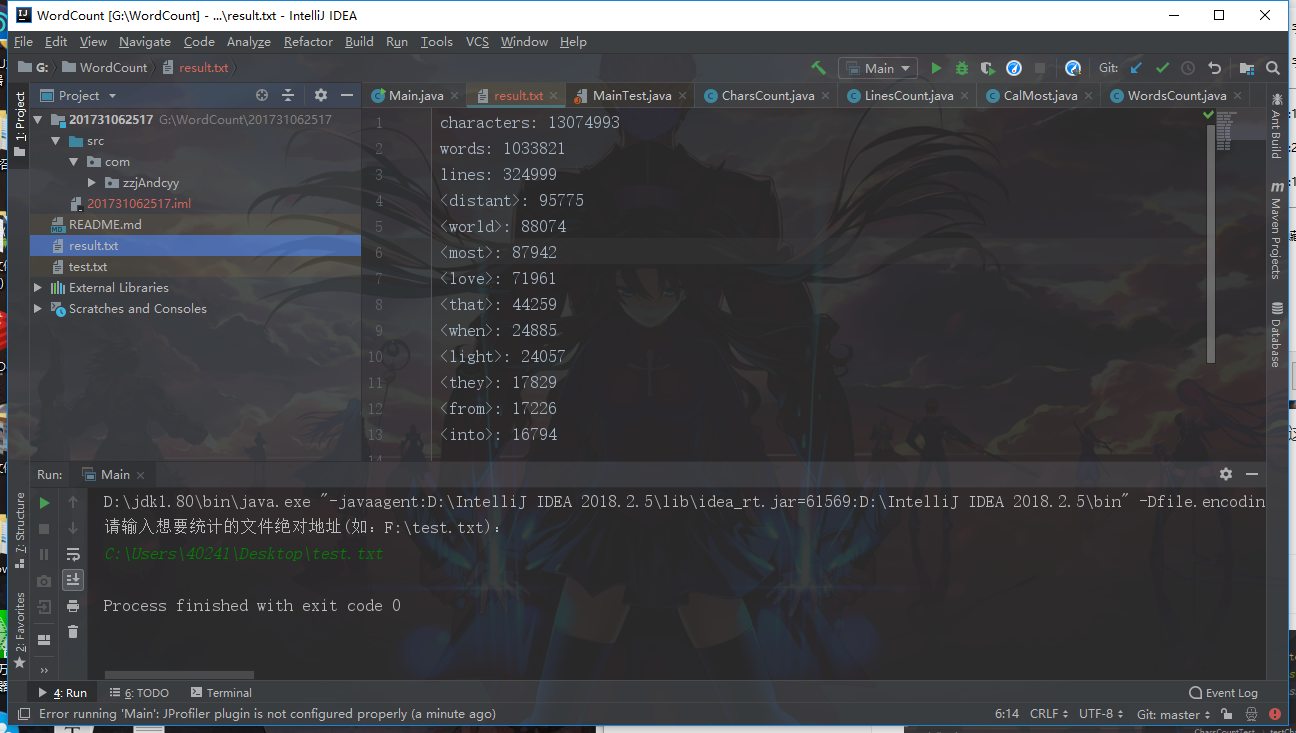
陈远杨同学说:
程序在经过大概3S左右的时间后才得出结果,花费时间这么久肯定某个地方耗时超出了预期,100W个单词1300W个字母。并且选取的是飞鸟集和1984 的混合素材,可以看出距离和爱出现的频率很高(很符合飞鸟集2333)
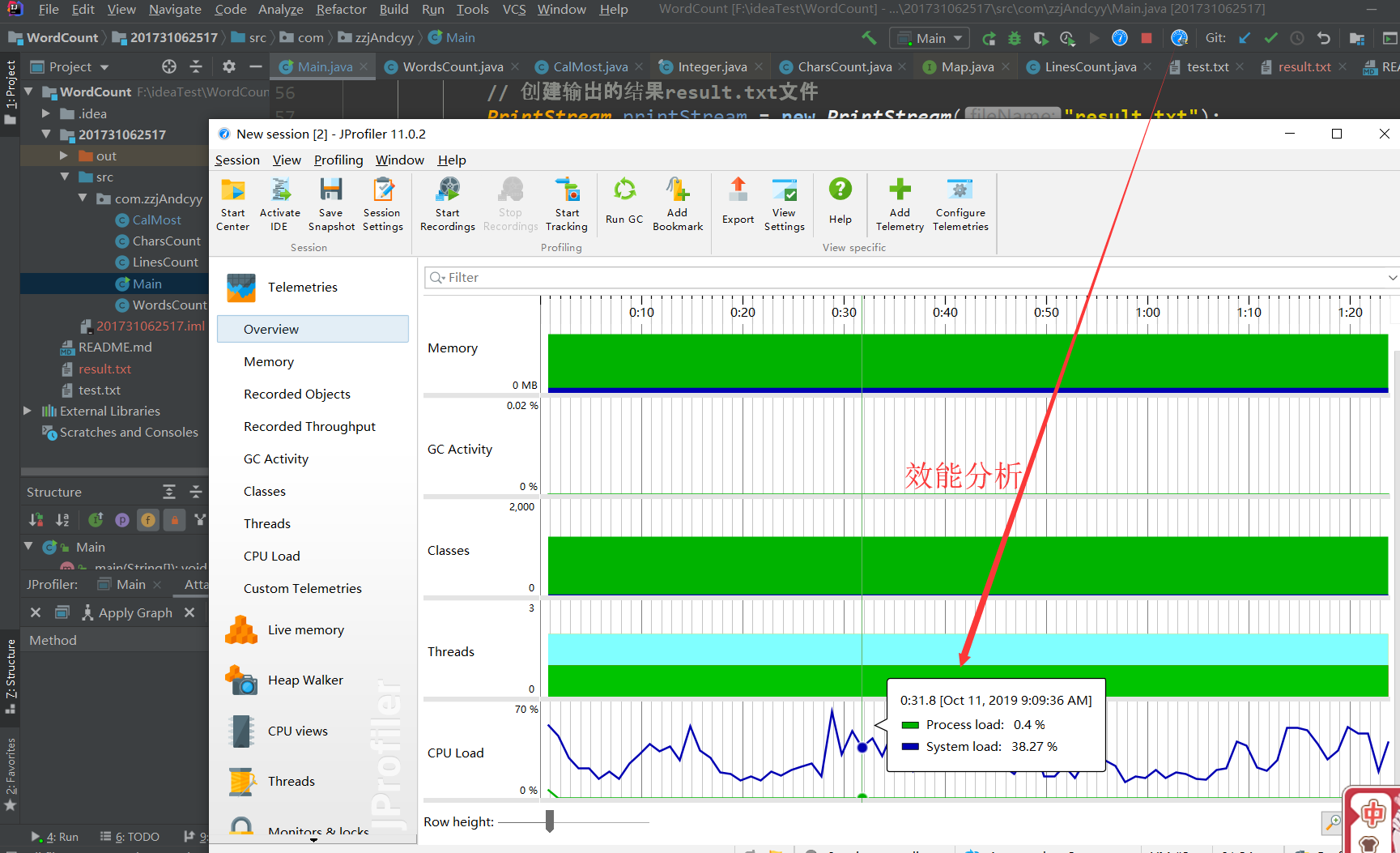
六、性能分析
JProfiler是用于分析J2EE软件性能瓶颈并能准确定位到Java类或者方法有效解决性能问题的主流工具,它通常需要与性能测试工具如:LoadRunner配合使用,因为往往只有当系统处于压力状态下才能反映出性能问题。
所以我采用JProfiler进行性能测试。
可以看到性能的影响并不大,毕竟只是一个单线程程序。
七、单元测试
行数单元测试

字符单元测试
单词频率统计
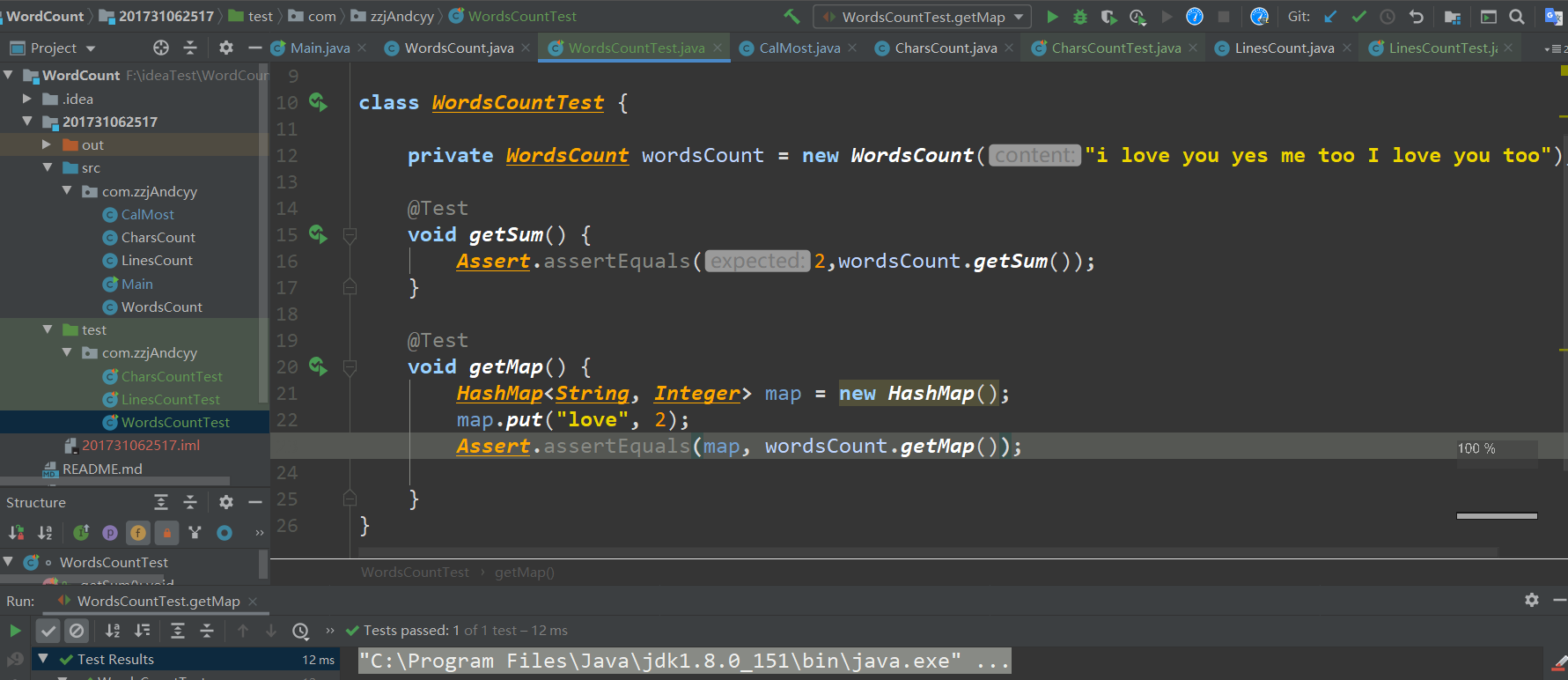
八、附加功能
窗体程序本来并没有这个打算,因为熟悉了C#的窗体设计的朋友就知道,C#直接拖控件写代码多么便利。而Java则要自己使用Swing工具包去调整控件的大小,位置,达到相对自己满意的地步。
即便如此,为了认真对待这门课,我们毅然决然还是搞定Java的窗体程序。
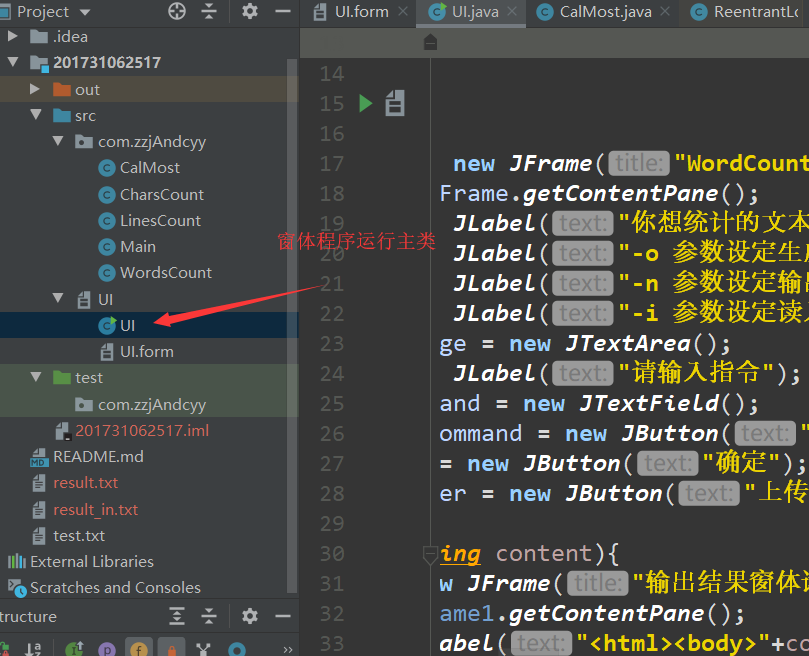
运行主类,主界面如下显示
分析文本输入
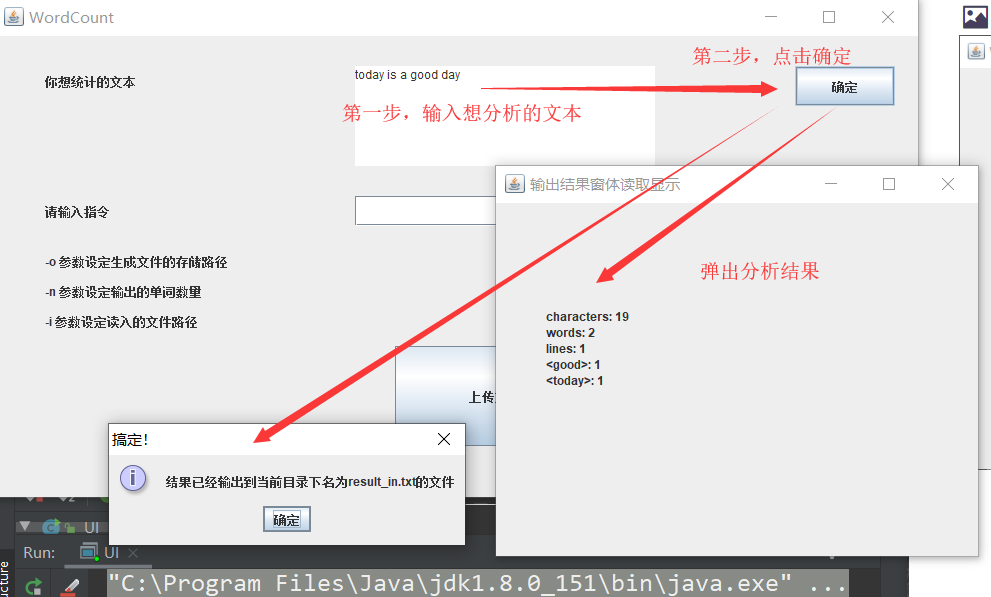
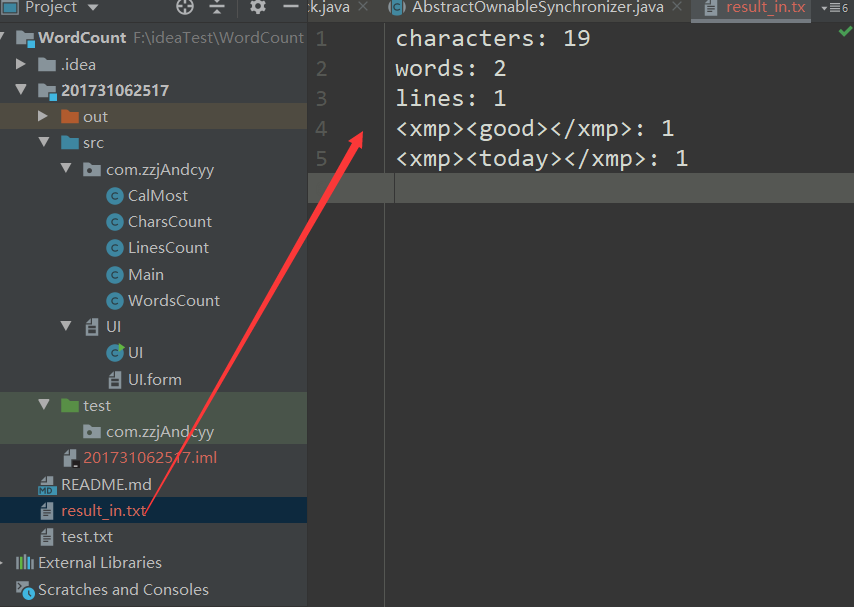
测试上传文件
注意:上传文件将会把文件上传到程序目录下,所以再次上传同样的文件将会提示 文件已经存在

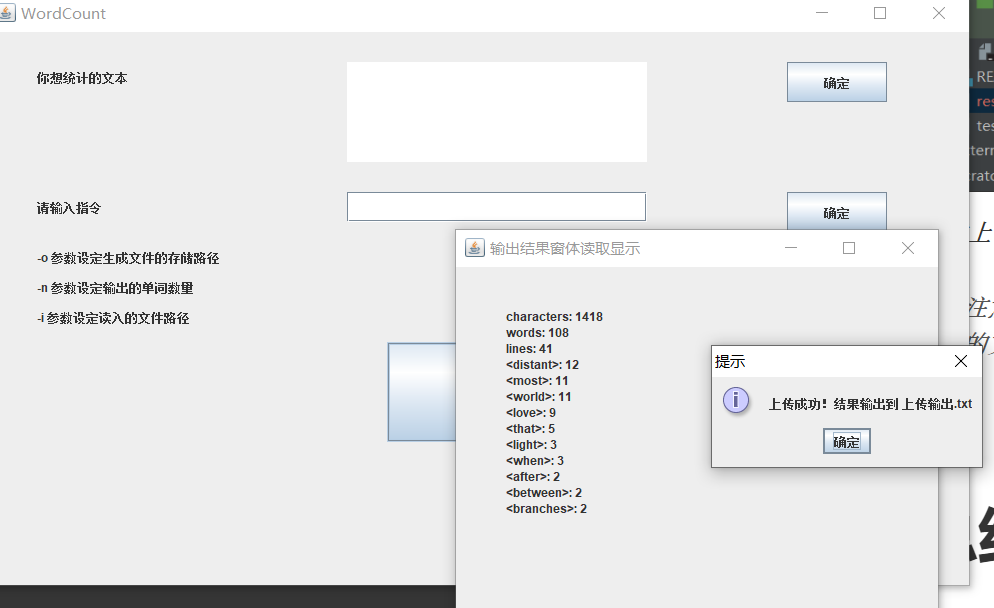
测试指令
-i 和 -n 指令的混合

总结
从看到了题目,我们便初步决定的首要目标,是先计划好主要有哪几个类。因为从本次的题目要求来看,功能需求很多,并且使用的是面向对象语言,那么动工写代码之前一定要规划化大概有多少个类,类担任的职责有哪些。
虽然提前规划的不一定会完美达到要求,但是也是利大于弊的。我们先来谈谈弊:
计划的太简单:
一开始的想法是既然就是完成统计一个文本中的字符数目情况,那么就可以拆分为两部分:运行主类+工具类。
- 运行主类:提供程序的入口,找到我们需要处理的文本
- 工具类,内含按照题目要求统计各种数目的方法,提供给运行主类调用
然后我们就开始动工了,我建立整个项目,包括从github上fork->拉取项目到本地->建立基本的运行环境->编写运行主类
陈远杨同学则进行编写较为复杂的工具类。
这时问题就出现了,代码风格不够统一,各自类的实现都有自己的见解,使得整个程序看起来很乱。
不过也得益于结对编程的利,互相检查出了很多以前没有注意到的错误,收获了很多可以改进的地方。所以,我们第一次编程完毕后,统一意见,将冗杂了各种方法的工具类提取出来分为多个功能明确的类,使得整个程序结构更为清晰。然后性能分析一起去找到了更为提高性能的一些改进,比如使用StringBuilder类...
综上所述:1+1在大家统一意见付之行动的情况下,确实>2.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号