



2023数据采集与融合技术实践作业3
本次作业的gitee链接:https://gitee.com/guo-hengxin/102102150/tree/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E4%BD%9C%E4%B8%9A
一.作业1
要求:指定一个网站爬取这个网站的所有图片,如中国气象网,使用scrapy框架分别实现单线程和多线程爬取
输出信息:将下载的url信息在控制台输出,并将下载的图片存储在images子文件当中,并给出截图
代码:
myspider.py
class myspider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
item = WeatherSpiderItem()
data = response.xpath('//img/@src').extract()
print(data)
for i in data:
list1 = []
list1.append(i)
item['image_urls'] = list1
print(item)
items.py
import scrapy
class WeatherSpiderItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
settings.py
DOWNLOADER_MIDDLEWARES = {
"weather_spider.middlewares.WeatherSpiderDownloaderMiddleware": 543,
}
ITEM_PIPELINES = {
# "weather_spider.pipelines.WeatherSpiderPipeline": 300,
'scrapy.pipelines.images.ImagesPipeline':300,
}
ROBOTSTXT_OBEY = False
IMAGES_STORE = 'C:/Users/86188/Desktop/pythonProject/image'
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl myspider -s LOG_ENABLED=False".split())
运行结果:运行run.py后在工程文件夹中有一个image文件夹
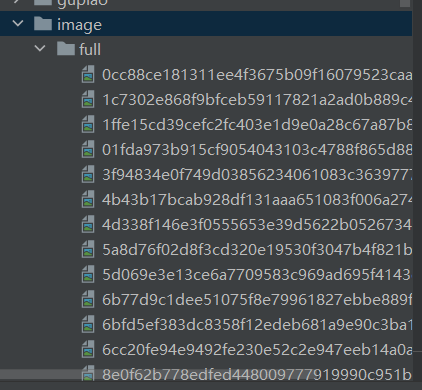

心得体会:
scrapy的框架学习了非常久才明白如何使用,scrapy有自己的下载图片文件之类的管道 可以不用自己写download函数,多线程只要开启DOWNLOADER_MIDDLEWARES并且使用thread即可
二.作业2
要求:熟练掌握scrapy中的item,pipeline 数据序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票先关信息(东方财富网:https://www.eastmoney.com/)
输出信息:MySQL数据库存储和输出格式如下,表头应该是英文名命名,自定义设计
代码:
myspider.py
import scrapy
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from ..items import GupiaoItem
class MyspiderSpider(scrapy.Spider):
name = "myspider"
allowed_domains = ["eastmoney.com"]
start_urls = ["http://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
def parse(self, response):
item = GupiaoItem()
driver = webdriver.Chrome()
driver.get(response.url)
for i in range(2):
content = driver.find_elements(By.XPATH, '//*[@id="table_wrapper-table"]/tbody/tr')
for m in content:
list = m.text.split(" ")
item['number'] = list[0]
item['id'] = list[1]
item['name'] = list[2]
item['newprice'] = list[6]
item['rise'] = list[7]
item['risenumber'] = list[8]
item['deal'] = list[9]
item['dealnumber'] = list[10]
item['z'] = list[11]
item['highest'] = list[12]
item['lowest'] = list[13]
item['today'] = list[14]
item['yes'] = list[15]
yield item
next_button = driver.find_element(By.XPATH, '//a[@class="next paginate_button"]')
next_button.click()
time.sleep(2)
items.py
import scrapy
class GupiaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
number = scrapy.Field()
id = scrapy.Field()
name = scrapy.Field()
newprice = scrapy.Field()
rise = scrapy.Field()
risenumber = scrapy.Field()
deal = scrapy.Field()
dealnumber = scrapy.Field()
z = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yes = scrapy.Field()
pass
pipelines.py
import pymysql
class GupiaoPipeline:
def process_item(self, item, spider):
try:
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', charset='utf8',database='spider')
self.cursor = self.conn.cursor()
sql = "INSERT INTO gupiao (deal, dealnumber, highest, id1, lowest, name, newprice, number, rise, risenumber, today, yes, z) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
values = (item['deal'], item['dealnumber'], item['highest'], item['id'], item['lowest'], item['name'],
item['newprice'], item['number'], item['rise'], item['risenumber'], item['today'], item['yes'],
item['z'])
self.cursor.execute(sql, values)
self.conn.commit()
except Exception as e:
print(f"Error processing item: {e}")
finally:
self.cursor.close()
self.conn.close()
return item
settings.py
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
ITEM_PIPELINES = {
"gupiao.pipelines.GupiaoPipeline": 300,
}
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl myspider -s LOG_ENABLED=False".split())
运行结果:
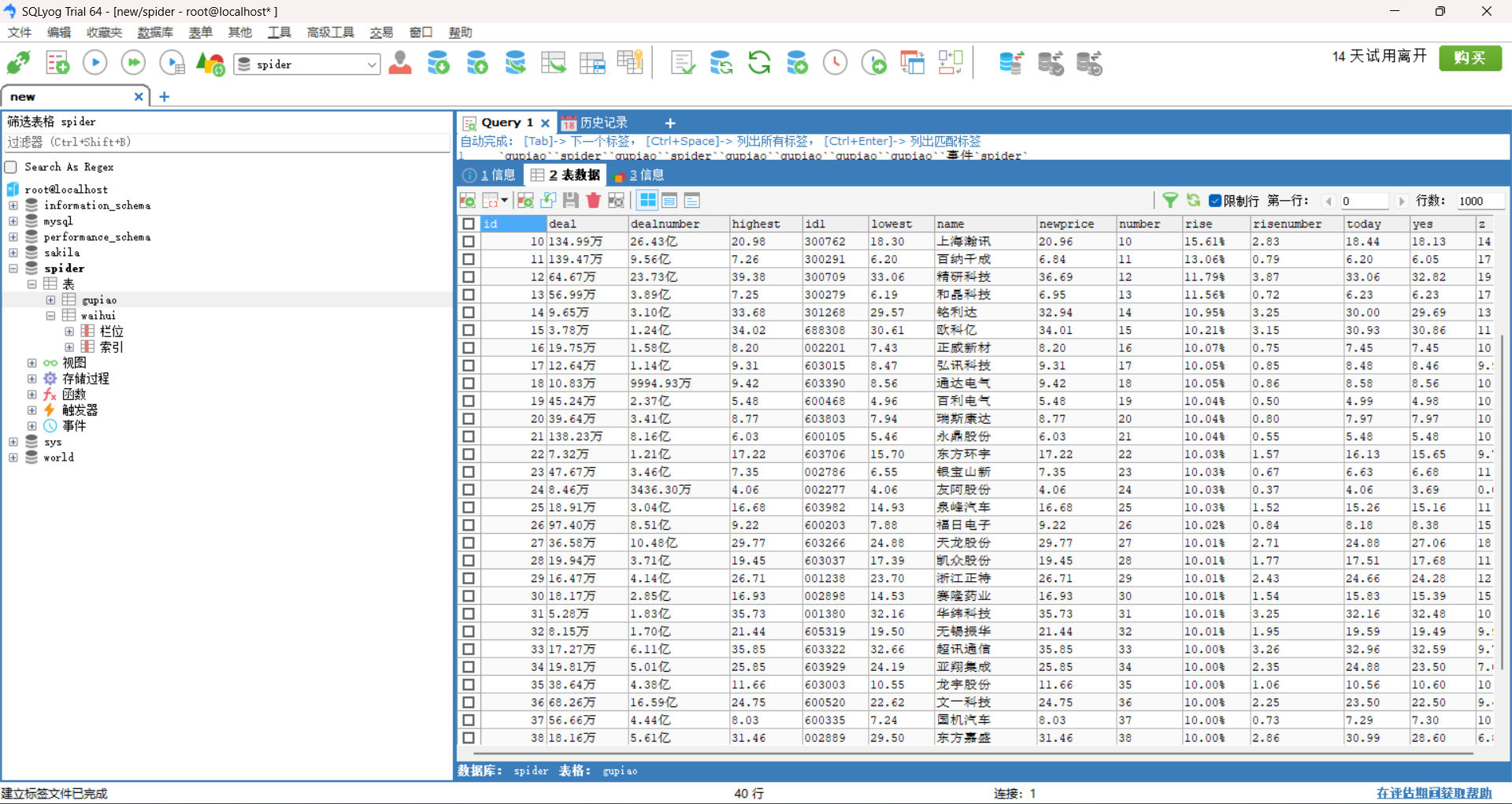
心得体会:
因为实验要求mysql加上Xpath所以翻页只能依靠selenium来实现,另外mysql的安装和配置以及pymysql实现和mysql数据库连接和传输数据耗费了我大量时间,十分痛苦
三.作业3
作业要求和作业2一致
代码:
myspider.py
import scrapy
from selenium.webdriver.common.by import By
from selenium import webdriver
from ..items import WaihuiItem
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
class MyspiderSpider(scrapy.Spider):
name = "myspider"
allowed_domains = ["www.boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
item = WaihuiItem()
driver = webdriver.Chrome()
driver.get(response.url)
wait = WebDriverWait(driver, 10)
for i in range(2):
a = wait.until(EC.presence_of_element_located((By.XPATH, '//html/body/div/div[5]/div[1]/div[2]/table/tbody/tr')))
for j in range(27):
content = driver.find_elements(By.XPATH,f'//html/body/div/div[5]/div[1]/div[2]/table/tbody/tr[{j + 2}]/td')
list = []
for k in content:
list.append(k.text)
item['Currency'] = list[0]
item['TBP'] = list[1]
item['CBP'] = list[2]
item['TSP'] = list[3]
item['CSP'] = list[4]
item['Time'] = list[7]
yield item
nextbutton = driver.find_element(By.XPATH, '//li[@class="turn_next"]/a')
nextbutton.click()
items.py
import scrapy
class WaihuiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
pass
pipelines.py
import pymysql
class WaihuiPipeline:
def process_item(self, item, spider):
try:
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='123456', charset='utf8',database='spider')
self.cursor = self.conn.cursor()
sql = "INSERT INTO waihui (Currency,TBP,CBP,TSP,CSP,Time) VALUES (%s, %s, %s, %s, %s, %s)"
values = (item['Currency'], item['TBP'], item['CBP'], item['TSP'], item['CSP'], item['Time'])
self.cursor.execute(sql, values)
self.conn.commit()
except Exception as e:
print(f"Error processing item: {e}")
finally:
self.cursor.close()
self.conn.close()
return item
settings.py
ITEM_PIPELINES = {
"waihui.pipelines.WaihuiPipeline": 300,
}
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl myspider -s LOG_ENABLED=False".split())
运行结果:
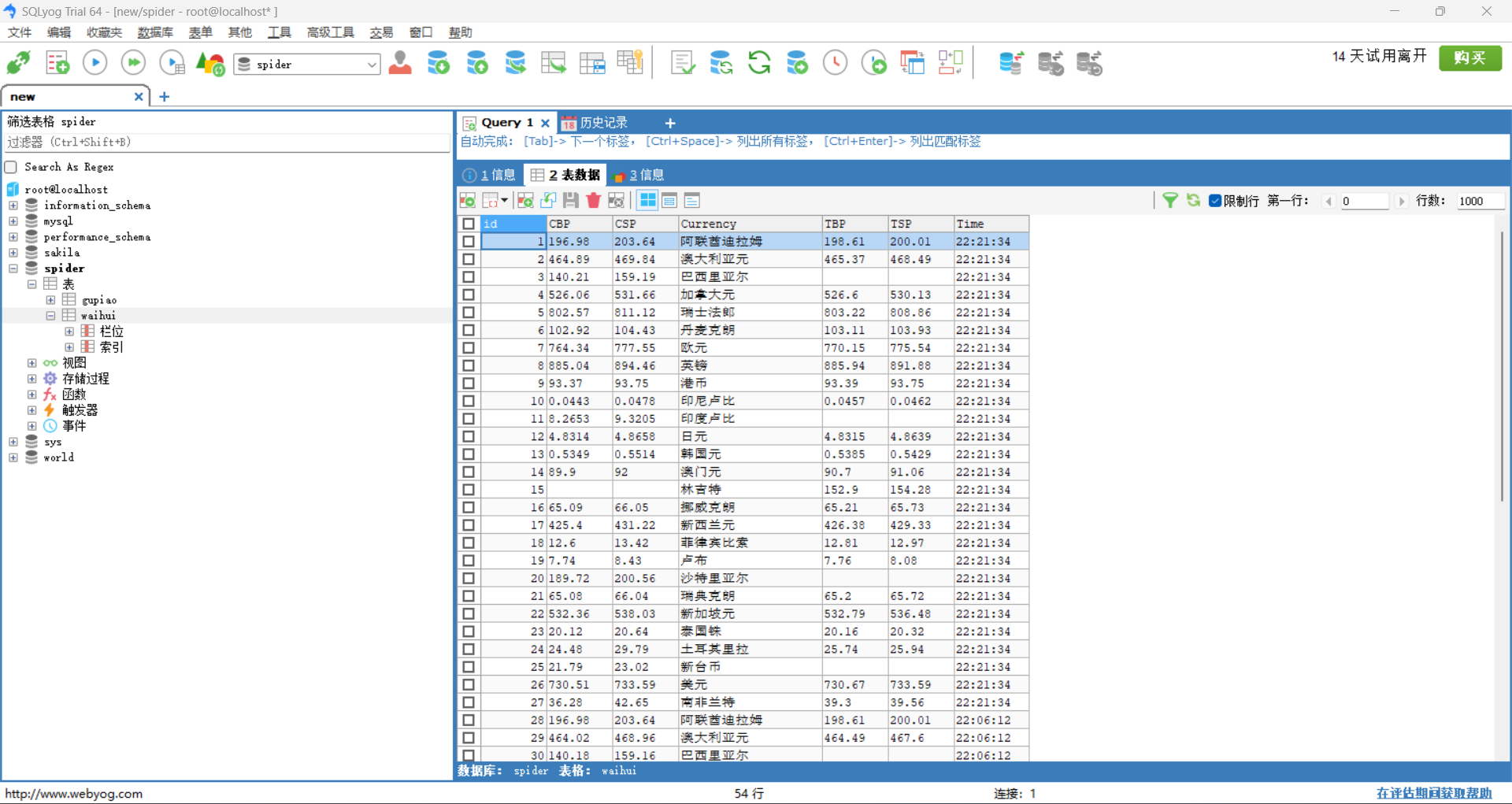
心得体会:
和作业2相似但是在翻页的时候加载数据很容易报错,可以使用wait.until()来等待元素的出现再爬取即可


 浙公网安备 33010602011771号
浙公网安备 33010602011771号