


2023数据采集与融合技术实践作业一
作业一
(1)要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
代码如下:
import requests
import urllib.request
from bs4 import BeautifulSoup
import bs4
# 导入的库
def get_and_process_university_rankings():
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
try:
res = requests.get(url)
res.raise_for_status()
res.encoding = res.apparent_encoding
html = res.text
except Exception as err:
print(err)
html = "" # 如果出现异常,则将html设置为空字符串
if not html:
try:
request_obj = urllib.request.Request(url)
data = urllib.request.urlopen(request_obj).read().decode()
html = data
except Exception as err:
print(err)
html = ""
if html:
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
a = tr('a')
table_data = tr('td')# 遍历tbody标签的所有子元素
uinfo.append([table_data[0].text.strip(), a[0].string.strip(), table_data[2].text.strip(),
table_data[3].text.strip(),
table_data[4].text.strip()])
tplt = "{0:^10}\t{1:^10}\t{2:^12}\t{3:^12}\t{4:^10}"# 定义一个格式化字符串模板,用于输出表格
print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分"))
for i in range(30):
u = uinfo[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4]))
else:
print("无法获取网页内容")
if __name__ == '__main__':
get_and_process_university_rankings()
结果显示如下:
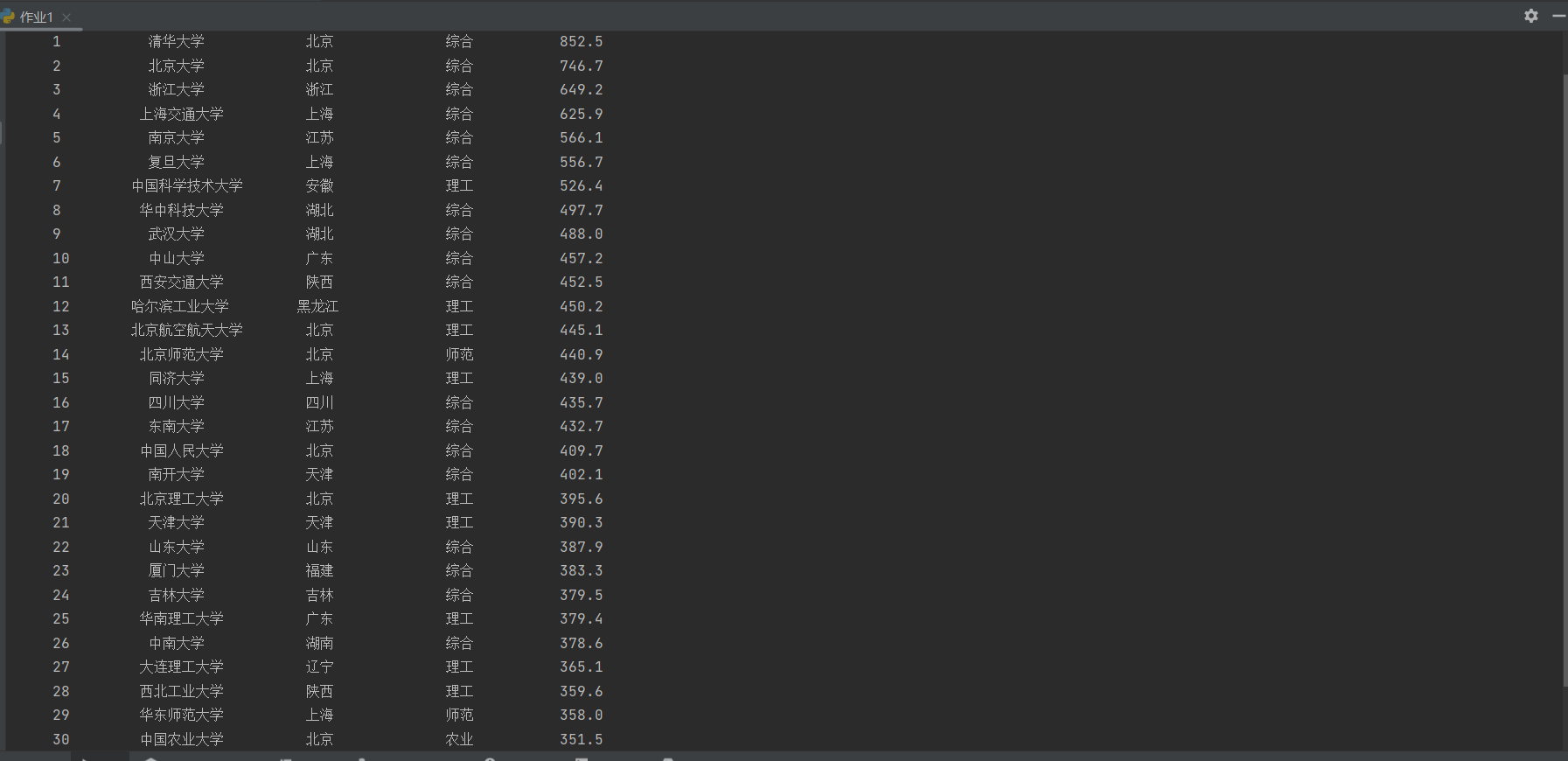
(2)心得体会
通过这次实验我对于html文本的内容的理解更加深刻和beautifulsoup的使用更加熟练
作业二
(1)要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码如下:
import re
import requests
headers = {
'user-agent' : '',
'cookie' : ''
}#user-agent 和 cookie 都可以在浏览器查找
url = ''#请求URL
response = requests.get(url = url , headers= headers)
datalist = response.text
#使用正则表达式爬取商品价格和名称
pricelist = re.findall('<i data-price=".*?">(.*?)</i>',datalist)
namelist1 = re.findall('<em>(.*?)<font class="skcolor_ljg">.*?</font>.*?</em>',datalist)
namelist2 = re.findall('<em>.*?<font class="skcolor_ljg">(.*?)</font>.*?</em>',datalist)
namelist3 = re.findall('<em>.*?<font class="skcolor_ljg">.*?</font>(.*?)</em>',datalist)
x=1
print('序号','价格','\t\t\t\t\t\t\t商品名')
for i,j,k,l in zip(pricelist , namelist1,namelist2,namelist3):
print(x,i,j,k,l)
x+=1
结果显示如下:
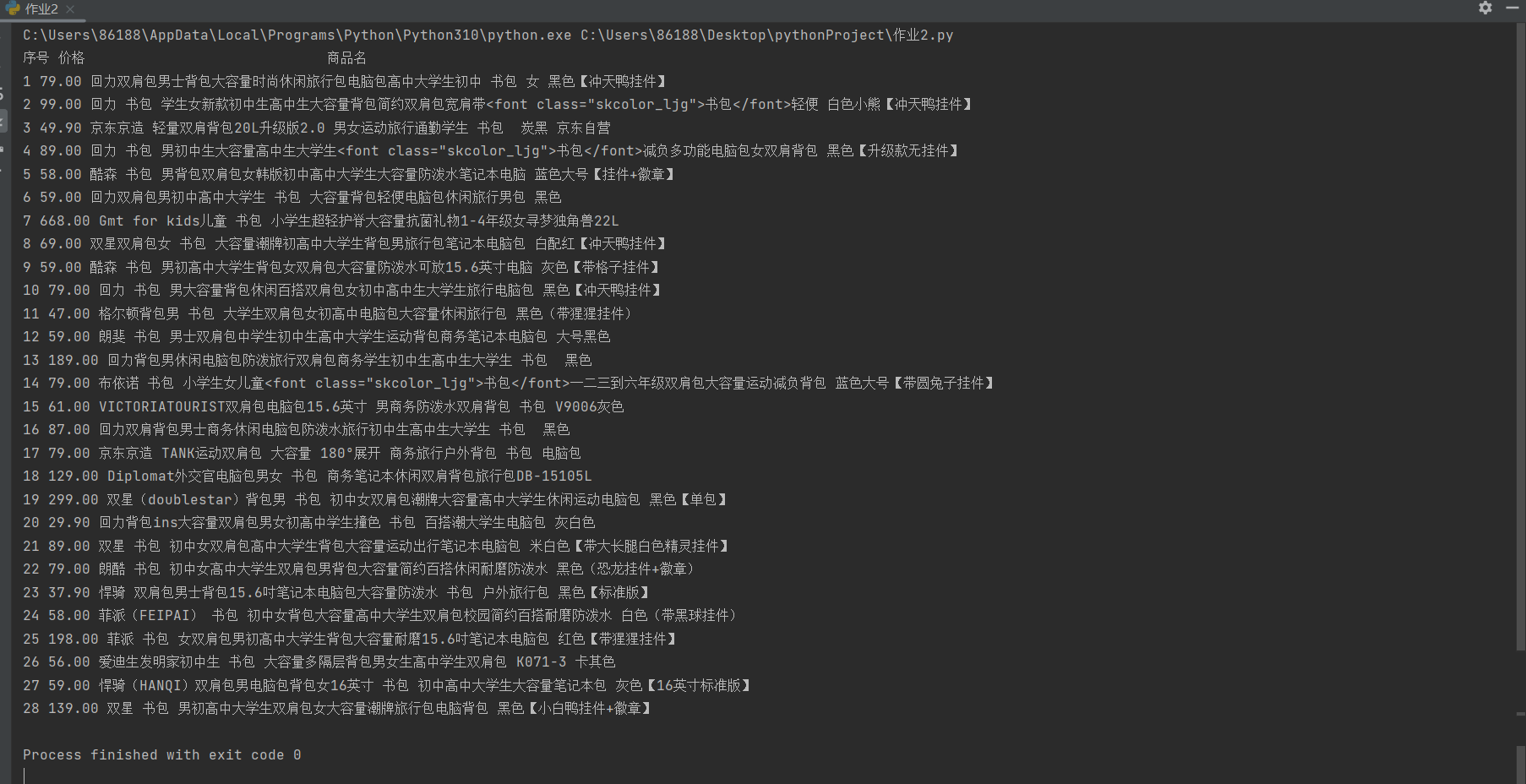
(2)心得体会
通过本次实验我更加熟悉了对于正则表达式的运用
作业三
(1)要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
代码如下:
import requests
import re
#要使用的库
headers = {
'user-agent' : '',
'cookie' : ''
}#输入代理和cooki
keyword = input("请输入要搜索的内容:")
startpage = int((input("请输入开始的页面:")))
endpage = int(input("请输入结束的页面:"))
#我选择的是爬取京东商品的图片
for page in range (startpage,endpage+1) :
reponse = requests.get(f"https://search.jd.com/Search?keyword={keyword}&isList=0&page={2*page-1}", headers= headers)#通过观察可知换页的规律
data = reponse.text
datalist = re.findall('<img width="220" height="220" data-img="1" data-lazy-img="(.*?)" />', data)
for j in datalist:
url2 = "https:"+j
reponse2 = requests.get(url2)
imagename = url2.split('/')[-1]
with open("image/"+imagename,'wb') as f:
f.write(reponse2.content)
结果显示如下:


(2)心得体会
通过这次实验我知道如何爬取网页的图片以及保存


 浙公网安备 33010602011771号
浙公网安备 33010602011771号