
论文笔记:Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
http://arxiv.org/abs/2503.16419
为避免混淆,本文将 inference 翻译为推理,将 reasoning 翻译为思考。
背景
一些主流的 CoT 变体:
- Self-Consistency 采样多个思考路径,然后选择最一致的答案。
- Tree-of-Thought 将思考过程结构化为具有回溯功能的树状结构,显著提升了在可并行处理子任务中的效率。
- Graph-of-Thoughts 在此基础上将思维结构化为图谱,从而允许对各个思考步骤进行迭代优化。
上述 CoT 变体通常采用不同的 prompt 技术来引导模型行为,有时还会引入类似控制器的机制,以管理思维的推进与使用。
传统的 Reasoning 方法通常是测试时增强,即通过特定的提示词来要求模型进行思考。而现代思考模型(如 DeepSeek-R1 或 OpenAI o1)通过训练将思考能力内化到模型,不需要在测试时使用复杂的提示词即可自动进行思考。
小模型更容易过度思考。
过度思考的问题:
- 浪费计算资源
- 增加响应时间,使模型不适合需要快速响应的场景
- 有时过多的思考会产生内在的矛盾,进而引发错误。
尝试缓解过度思考与思考模型训练时鼓励生成更长的思考步骤是矛盾的。例如 DeepSeek-R1-Zero 的训练时长和响应长度以及基准性能的提升之间呈现相关性。
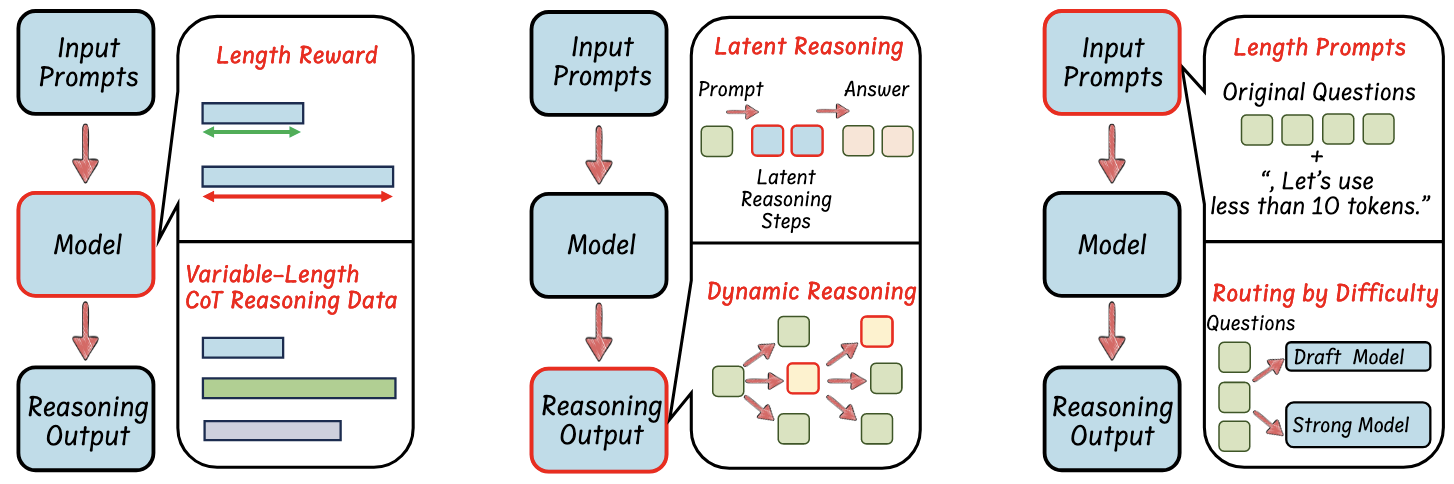
本文将高效思考方法分为以下几类(左、中、右):
- 基于模型的高效思考,即通过优化长思考模型为更简洁的思考模型,或直接训练高效思考模型;
- 基于输出的高效思考,旨在思考过程中动态减少思考步骤和输出长度;
- 基于输入提示的高效思考,旨在根据输入提示的特性(如难度或长度控制)来提升思考效率。
基于模型的高效思考
基于 RL 的方法
一些研究提出在强化学习框架中引入长度奖励,为简短且正确的答案赋予更高分数,而对冗长或错误的答案进行惩罚,从而优化思考路径的长度。
基于 SFT 的方法
可以通过直接在 CoT 数据上进行 SFT 使模型获得思考能力。一个典型例子是,将 DeepSeek-R1 蒸馏到较小的 Qwen 模型上。
变长 CoT 数据收集
主要有两种方案:
- 在 reasoning 之后进行 CoT 压缩。
- 极限做法是要求思考模型生成完整的思考过程和结果,然后直接删除 CoT 部分。
- 也有一些压缩方法,C3oT 先要求思考模型生成尽可能长且完善的思考过程,然后使用 GPT-4 压缩 CoT 部分。
- TokenSkip 估计每个思考部分对最终答案的语义重要性,并减少相应的思考 token。
- 在 reasoning 期间进行 CoT 压缩。其优势是,自然生成的思考步骤与 LLM 的内在知识相一致,从而有助于 LLM 更有效的学习。
- Can language models learn to skip steps? 提出一种两阶段策略,第一阶段使用专家标注的精简步骤或者随机合并步骤形成一个小规模 SFT 数据集,对思考模型进行微调,然后在第二阶段使用微调后的思考模型来生成真正的 SFT 数据集。
- Self-training elicits concise reasoning in large language models 提出在测试阶段采样多条路径,然后选取最短的那条形成训练数据集。
- CoT-Valve 通过混合思考模型和非思考模型的参数来控制思考的长短。
微调方法
大部分方法使用标准的全量微调或者 LoRA 微调。
也有方法使用所谓渐进式微调,例如在微调过程中逐渐减少 CoT 数据的长度。或者类似 CoT-Valve 使用两个 LoRA Adapter(无思考的和带长思考的模型)\(\Delta \theta_N\) 和 \(\Delta\theta_L\) 以参数 \(\alpha\) 控制进行组合:\(\alpha\Delta\theta_N+(1-\alpha)\Delta\theta_L\)。
也有使用模型融合方案的。例如 Kimi K1.5 和 Unlocking efficient long-to-short llm reasoning with model merging。
基于输出的高效思考
隐空间思考步骤压缩
近期的多项研究证明,性能的提升往往来自更多的隐空间计算,而非纯粹的文本分解。这种方法主要有两种路线:
- 训练 LLM 在推理时使用隐空间表示
- 使用辅助模型
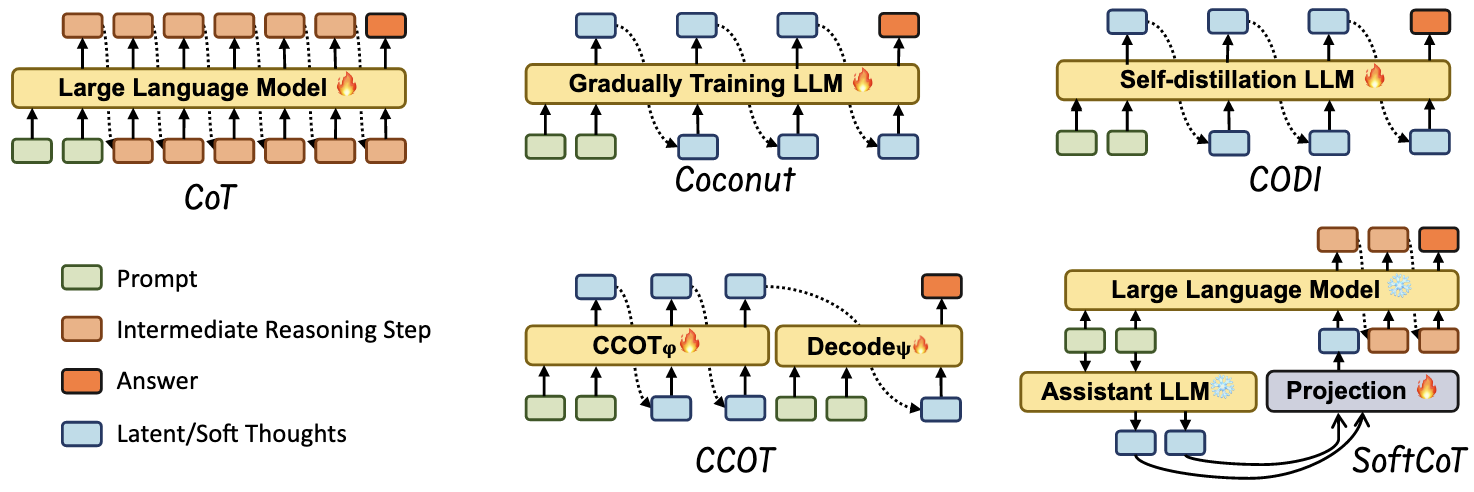
Looped Transformer 也属于此类。
推理期间的思考增强
通过确定标准实现动态思考
这类方法的主要思路是,在推理期间使用各种方式促使模型进行更长时间、更广泛的思考。
一些推理时扩展方法:
- Best-of-N 针对给定 prompt 生成多个响应,扩大搜索空间以发现更优解。生成完成后,通过多数投票(即选择出现频率最高的响应)或基于奖励模型(根据预定义标准评估响应质量)来选择最优响应。Self-consistency 即属于此类。
- 束搜索(Beam search)将生成过程划分为多个步骤,在每一步选择最有可能的中间输出,通过过程奖励模型淘汰较差的选项。
- 蒙特卡洛树搜索(MCLS)沿着解决方案树的不同分支生成部分响应,评估这些响应,并将奖励值回传到早期节点。最终模型选择累积奖励最高的分支,相比束搜索实现了更精细的选择过程。
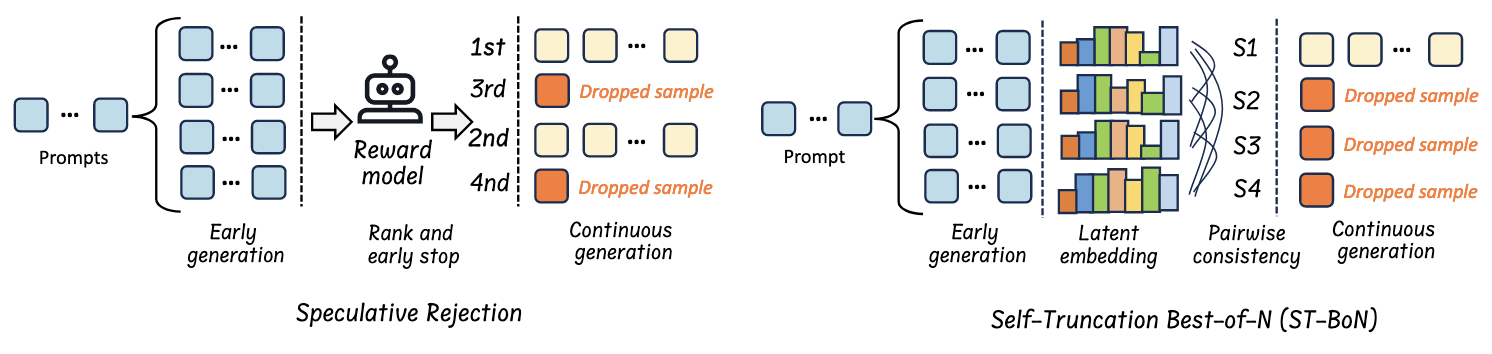
推理时扩展方法在推理时显著消耗了更多推理资源。为了改善,出现了一些奖励引导的高效思考方法。
- Speculative Rejection 是 Best-of-N 的改进方法,它生成多个响应,并在内存使用接近上限时,使用奖励模型剔除低质量的输出。
- Reward-Guided Speculative Decoding(RSD)是一种推测解码的改进方法,它使用一个 Process Reward Model(PRM)来动态评估 draft model 的输出,评分高的直接接受,评分低的由主模型重新生成。
基于置信度的自适应思考:
- Dynamic Parallel Tree Search
- FastMCTS
- Certaindex
- Dynasor-CoT
- Self-Calib
基于置信度的选择性思考:即上图中右侧的 ST-BoN。分析不同思考路径的 latent embeddings,选择最一致的路径。
基于总结的动态思考
这类方法的基本思路是,训练 LLM 总结其思考的中间步骤来优化效率。
- LightThinker 训练 LLM 将一些中间步骤压缩为紧凑的 gist tokens。配合了一种稀疏的 attention mask 来确保模型仅关注关键的压缩表示。
- InftyThink 通过迭代生成思维、摘要并丢弃之前的所有思维和摘要,仅保留最新的摘要来实现几乎无限长的思维链。
基于输入 prompt 的高效思考
prompt 引导的高效思考
即通过特定的 prompt 来约束模型进行高效思考。
- Token-budget-aware llm reasoning 引入了一种无需训练、零样本的思考预算估计方法:首先通过向 LLM 本身提问来估算一个合理的 token 预算,然后将该预算嵌入到 prompt 中。
- Chain of draft: Thinking faster by writing less 发现,LLM 常常生成冗长繁琐的推理步骤,而人类通常只记录最关键的洞察。为提升推理效率,他们提出了 Chain-of-Draft 提示方法。与 CoT 提示类似,CoD 鼓励逐步推理,但引入了限制冗长性的策略。例如,其提示指令为:“逐步思考,但每个思考步骤仅保留最少的草稿,最多五个词。” 他们发现,该方法在保留必要中间步骤的同时维持了准确性,显著减少了 token 消耗。
- How well do llms compress their own chain-ofthought? a token complexity approach 系统地研究了在不同 prompt 下(带有明确压缩指令,例如“用10个词或更少”)思考长度与模型准确率之间的关系。他们的分析揭示了一个普遍存在的思考长度与准确率之间的权衡关系,表明各种基于 prompt 的压缩策略均收敛于相同的准确性-压缩曲线。他们假设每个任务都存在一个内在的 token 复杂度,即成功解决问题所需的最少 token 数量。通过计算信息论意义上准确率与压缩之间的理论极限,他们发现现有的基于 prompt 的压缩方法远未达到这些极限,表明仍有巨大的改进空间。
- The benefits of a concise chain of thought on problemsolving in large language models 提出了 Concise Chain-of-Thought, CCoT 提示技术,要求 LLM 进行逐步思考的同时,明确指令其“要简洁”。
- Unlocking the capabilities of thought: A reasoning boundary framework to quantify and optimize chain-ofthought 通过修改提示词来限制单步计算,从而有效精炼思考边界。此外,他们还增加了每步的计算量并减少了全局规划步骤。
prompt 特征驱动的模型路由策略
基本思想是,将比较复杂的 prompt 分配到速度慢但能力强大的模型,将比较简单的 prompt 分配到速度快但能力较弱的模型。
这一路线的关键问题是:如何确定 prompt 的复杂度。
训练一个分类器
- Routellm: Learning to route llms with preference data 从 Chatbot Arena 收集的大量偏好数据作为训练数据,训练了一个查询路由模块,实现了在问答和思考任务中高效、准确的路由决策。
- Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching 利用路由和提示技术,在推理过程中最小化 token 消耗。基于轻量级的 DistilBERT 路由器,能够根据问题特征动态选择最合适的推理范式。受认知科学启发,SoT 采用三种不同的推理范式:概念链式推理(Conceptual Chaining),通过最少的言语表达连接思想;分块符号化(Chunked Symbolism),将数学推理结构化为简洁的符号表示;专家词典(Expert Lexicons),采用专家常用的领域专用缩略语。
基于不确定性的方法
- Learning to route llms with confidence tokens 通过提取内在不确定性分数作为自带的路由指示器,使 LLM 能够自主决定何时进行路由。具体而言,他们对LLM内部的专用于不确定性的标记进行微调,以使不确定性预测与问答和推理任务中的预测正确性保持一致。这确保只有在输出存在不确定性或错误时,才会触发路由至更强大的LLM,从而降低了LLM推理的延迟。
- Confident or seek stronger: Exploring uncertainty-based on-device llm routing from benchmarking to generalization 旨在在不需访问用户查询的情况下,为 LLM 的问答和思考任务提供校准的数据,以预测和初始化路由策略。该方法能够在决定 LLM 是否应自信生成答案或将查询转交给更强模型时,实现更高效且可靠的决策,从而从查询层面提升在线 LLM 服务场景下的推理效率。
通过高效训练数据和模型压缩实现思考能力
通过更少的数据训练思考模型
- Limo: Less is more for reasoning 通过使用极少但精心挑选的示例来激发复杂的思考能力。基于一系列标准和策略选择高质量解答,仅用 817 个精心挑选的训练样本,就超越此前使用超过 10 万条示例的模型。
- s1: Simple test-time scaling 基于质量、难度和多样性构建了一个紧凑的数据集 s1K,包含 1000 个高质量问题及其对应的思考轨迹。通过对该数据集进行 SFT,并引入“预算强制”(budget forcing)机制,在思考过程中调节推理时长,s1-32B 在 MATH 和 AIME24 两项任务上超越了 OpenAI o1-preview。
通过蒸馏或压缩为小模型赋予思考能力
大型模型直接蒸馏到小型模型时,小型模型往往难以达到大型模型的思考深度。为解决这一问题,已有多种方法被提出。
- Small models struggle to learn from strong reasoners 和 Mixed distillation helps smaller language models reason better 均探索了混合蒸馏方法。前者混合使用长和短的 CoT 思考示例,而后者则结合了 CoT 和 PoT(思维程序)来提升在特定任务上从大模型到小模型进行知识蒸馏的有效性。
- Teaching small language models reasoning through counterfactual distillation 提出了反事实蒸馏方法,通过在原始问题中掩盖因果特征,让 LLM 完成被遮蔽文本的补全,并为每个数据点生成多视角的思维链(正例和负例视角),从而增强知识蒸馏的效果。
- Improving mathematical reasoning capabilities of small language models via feedback-driven distillation 开发了一种基于反馈的蒸馏技术,通过迭代优化蒸馏数据集来实现。其流程是:首先用大模型生成初始的蒸馏数据集,然后通过基于已有问题创建多样且复杂的新问题来扩展该数据集,最后用这个丰富后的数据集对小模型进行微调。
- Distilling probing and reasoning capabilities into smaller language models 提出将探针(probing)和检索机制融入蒸馏流程中:训练两个互补的小模型——探针模型和思考模型,其中探针模型用于检索相关知识,思考模型则利用这些知识构建出逐步的思考过程。
- Distilling reasoning ability from large language models with adaptive thinking 引入了蒸馏过程中的自适应思考,使模型能够根据任务复杂度动态调整思考策略。
- Skintern: Internalizing symbolic knowledge for distilling better cot capabilities into small language models 将符号知识内化到小模型中,以提升 CoT 的质量和效率。
- Small language models need strong verifiers to self-correct reasoning 通过小模型自动生成自纠正数据,并对模型进行微调,使其具备自我纠错的思考能力。
上述工作说明,思考能力蒸馏不仅需要缩小模型规模,还需精心设计知识迁移过程,以保留逻辑深度和泛化能力。
压缩:本文没有讨论太多,只提到量化效果好,剪枝效果差。QAT 可能是重要方向。
评估
推理时的计算
- Inference-time computations for llm reasoning and planning: A benchmark and insights 从五个思考类别对 LLM 进行评测,包括算术、逻辑、常识、算法和规划任务。研究表明,仅通过提升推理时的计算量是不够的,因为没有任何单一技术能在所有思考任务上持续表现优异,这凸显了需要采用多样化方法来提升 LLM 的思考能力。
- Bag of tricks for inference-time computation of llm reasoning 探讨了各种常用策略如何影响 LLM 的思考能力。它在预设预算内对多种推理时计算方法进行了基准测试,通过灵活的 N-样本策略实现了可控的 token 使用。
- Can 1b llm surpass 405b llm? rethinking compute-optimal test-time scaling 探讨了测试时间扩展(TTS)策略对 LLM 性能的影响,重点关注策略模型、过程奖励模型和问题难度如何影响 TTS 的有效性。研究发现,计算最优的 TTS 策略高度依赖于这些因素。论文指出,采用合适的 TTS 策略后,1B 参数的 LLM 在复杂思考任务(如 MATH-500)上甚至可以显著超越 405B 参数的 LLM,这凸显了在评估和提升 LLM 推理能力过程中,采用定制化 TTS 方法的重要性。
对过度思考的评估
- The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks 系统性地分析 LLM 中的过度思考现象。通过对 agent 任务中 4018 条轨迹的分析,该研究识别出“分析瘫痪”、“越界行为”和“过早脱离”等模式。该工作还提出了一个新颖的“过度思考评分”(overthinking score),并发现该评分越高,任务表现越差,相关性显著。采用过度思考评分较低的解决方案作为策略,可使性能提升30%,同时将计算开销降低43%。
- Chain-of-thought can reduce performance on tasks where thinking makes humans worse 利用来自“过度思考”文献中的六个综合性任务,设计用于测试 LLM CoT 失败的评估基准。研究发现,在人类因过度反复推敲而失败的许多情况下,采用 CoT 的 LLM 也表现出类似的失败模式。
- S1-bench: A simple benchmark for evaluating system 1 thinking capability of large reasoning models 针对与 System-1 思维相一致的简单任务,对思考 LLM 进行评估。(System-1 和 System-2 猜测应当与人脑思维原理有关,System-1 简单直接,System-2 复杂)
长 CoT 思考的效果
- Demystifying long chain-of-thought reasoning in llms 对长 CoT 思考背后机制进行了全面分析。除了提出若干关键见解外,他们还设计了一种奖励机制,以提升训练过程中思考能力的稳定性,并缩短CoT长度。
- The impact of reasoning step length on large language models 发现 CoT 长度与模型输出效果之间存在强相关性。模型在思考步骤增加时表现更佳。
- Critical thinking: Which kinds of complexity govern optimal reasoning length? 基于确定性有限自动机研究了 LLM 的最优思考长度。
- Missing premise exacerbates overthinking: Are reasoning models losing critical thinking skill? 发现,当推理模型遇到缺少关键信息的问题时,往往倾向于反复“思考”,而不是承认无法作答。通过研究这一行为,他们表明当前的训练方法促使模型生成冗长、重复的推理步骤,而非识别出无解问题并提前终止。
思考模型压缩的效果
- When reasoning meets compression: Benchmarking compressed large reasoning models on complex reasoning tasks 在思考任务上对量化、蒸馏和剪枝等压缩技术进行了基准测试。结果表明,参数量对知识保留的影响大于对推理能力的影响,而生成更短的输出通常能带来更好的性能。
- Quantization hurts reasoning? an empirical study on quantized reasoning models 评估在不同算法和位宽配置下对权重量化、KV缓存量化和激活量化的表现。
应用和讨论
应用
- 自动驾驶
- 具身智能
- 医疗
- 推荐系统
讨论
- 提升思考能力
- 高效思考的安全问题
- 用于智能体 AI 的高效 LLM
- 强化学习和 SFT,哪个更好?强化学习通常效果较好,但不稳定且需要更高的训练成本。SFT 比较稳定但效果次优。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号