
MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map、Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析。
MapOutputBuffer顾名思义就是Map输出结果的一个Buffer,用户在编写map方法的时候有一个参数OutputCollector:
void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter) throws IOException;
这个OutputCollector是一个接口,典型实现是OldOutputCollector,这个类的构造方法如下:
OldOutputCollector(MapOutputCollector<K,V> collector, JobConf conf) { numPartitions = conf.getNumReduceTasks(); if (numPartitions > 0) { partitioner = (Partitioner<K,V>) ReflectionUtils.newInstance(conf.getPartitionerClass(), conf); } else { partitioner = new Partitioner<K,V>() { @Override public void configure(JobConf job) { } @Override public int getPartition(K key, V value, int numPartitions) { return -1; } }; } this.collector = collector; }
可以看出,其核心是MapOutputCollector的对象,另外,在构造方法里还创建了Partitioner<K,V> partitioner对象,如果用户写了分区的自定义方法,那么通过反射即可实例化自定义类(),否则使用系统自带的类。即默认为HashPartitioner,这在前面我们已经分析过:
public Class<? extends Partitioner> getPartitionerClass() { return getClass("mapred.partitioner.class", HashPartitioner.class, Partitioner.class); }
这样的话,当用户调用OutputCollector的collect()方法的时候,获取Key对应的分区号(getPartition())后,实际上调用的就是MapOutputCollector的collect()方法:
public void collect(K key, V value) throws IOException { try { collector.collect(key, value, partitioner.getPartition(key, value, numPartitions)); } catch (InterruptedException ie) { Thread.currentThread().interrupt(); throw new IOException("interrupt exception", ie); } }
MapOutputCollector实际上是一个接口,实现该接口的类有MapOutputBuffer和DirectMapOutputCollector,后者用于一个作业在没有Reduce阶段时使用,让Map处理的数据直接写入HDFS,前面已经看过这段代码:
MapOutputCollector collector = null; if (numReduceTasks > 0) { collector = new MapOutputBuffer(umbilical, job, reporter); } else { collector = new DirectMapOutputCollector(umbilical, job, reporter); }
典型的场合下使用的就是MapOutputBuffer的collect方法。因为用户在编写Map方法的时候,对于映射后的KV都是调用collect方法执行,因此关于KV的分区、合并、压缩、缓存、写盘等等功能都是在MapOutputBuffer的统一指挥下进行的。
明白了MapOutputBuffer的作用,我们下面分析一下MapOutputBuffer的细节。
MapOutputBuffer类里面包含的变量比较多,我们对其关键变量进行分析:
1、int partitions,分区数量,表示Map任务的输出需要分为多份,partitions的值等于job.getNumReduceTasks(),也就是等于Reduce的数量;
2、TaskReporter reporter,是一个Child子进程向父进程TaskTracker汇报状态的线程类,汇报接口使用umbilical RPC接口,这在前面各节已经多次分析过,不再赘述。
3、Class<K> keyClass和Class<K> valClass代表Map处理的Key和Value的类信息,代表用户上传的配置文件中指定的"mapred.mapoutput.key.class"和"mapred.mapoutput.value.class"
keyClass = (Class<K>)job.getMapOutputKeyClass(); valClass = (Class<V>)job.getMapOutputValueClass(); public Class<?> getMapOutputKeyClass() { Class<?> retv = getClass("mapred.mapoutput.key.class", null, Object.class); if (retv == null) { retv = getOutputKeyClass(); } return retv; } public Class<?> getMapOutputValueClass() { Class<?> retv = getClass("mapred.mapoutput.value.class", null, Object.class); if (retv == null) { retv = getOutputValueClass(); } return retv; }
4,RawComparator<K> comparator,表示用来对Key-Value记录进行排序的自定义比较器:
public RawComparator getOutputKeyComparator() { Class<? extends RawComparator> theClass = getClass("mapred.output.key.comparator.class", null, RawComparator.class); if (theClass != null) return ReflectionUtils.newInstance(theClass, this); return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class)); }
Map处理的输入并不排序,会对处理完毕后的结果进行排序,此时就会用到该比较器。
5,SerializationFactory serializationFactory,序列化工厂类,其功能是从配置文件中读取序列化类的集合。Map处理的输出是Key,Value集合,需要进行序列化才能写到缓存以及文件中。
6,Serializer<K> keySerializer和Serializer<V> valSerializer分别用于对Map后的Key和Value进行序列化。其创建来自序列化工厂类:
keySerializer = serializationFactory.getSerializer(keyClass); keySerializer.open(bb); valSerializer = serializationFactory.getSerializer(valClass); valSerializer.open(bb);
这里又涉及一个变量bb,其定义是:BlockingBuffer bb = new BlockingBuffer()
BlockingBuffer是MapOutputBuffer的一个内部类,继承于java.io.DataOutputStream,keySerializer和valSerializer使用BlockingBuffer的意义在于将序列化后的Key或Value送入BlockingBuffer。在其serialize序列化方法中,将可序列化的对象(实现Writable接口的对象)序列化后写入流,此处这个流也就是BlockingBuffer:
public void serialize(Writable w) throws IOException { w.write(dataOut); }
Writable是个接口,w.write方法又有什么实现呢?取决于KV类型。Hadoop中需要序列化的对象(包括输入输出Key,Value都必须是可序列化的)继承于Writable接口,该接口提供两个方法:读和写:
public interface Writable { void write(DataOutput out) throws IOException; void readFields(DataInput in) throws IOException; }
Hadoop内也有一些典型的实现,比较典型的比如IntWritable,其实现就是调用java.io.DataInput中的方法:
public void readFields(DataInput in) throws IOException { value = in.readInt(); } public void write(DataOutput out) throws IOException { out.writeInt(value); }
因此,当对Key、Value进行序列化的时候,实际上是调用如IntWritable(假如Key,Value类型是整型)的write方法,该方法又是反过来,调用DataOutput的writeInt方法。
在此处,BlockingBuffer内部又引入一个类:Buffer,也是MapOutputBuffer的一个内部类,继承于java.io.OutputStream。为什么要引入两个类呢?BlockingBuffer和Buffer有什么区别?初步来看,Buffer是一个基本的缓冲区,提供了write、flush、close等方法,BlockingBuffer提供了markRecord、reset方法,处理Buffer的边界等一些特殊情况,是Buffer的进一步封装,可以理解为是增强了Buffer的功能。Buffer实际上最终也封装了一个字节缓冲区,即后面我们要分析的非常关键的byte[] kvbuffer,基本上,Map之后的结果暂时都会存入kvbuffer这个缓存区,等到要慢的时候再刷写到磁盘,Buffer这个类的作用就是对kvbuffer进行封装,比如在其write方法中存在以下代码:
public synchronized void write(byte b[], int off, int len) { spillLock.lock(); try { do { 。。。。。。。。 } while (buffull && !wrap); } finally { spillLock.unlock(); } // here, we know that we have sufficient space to write if (buffull) { final int gaplen = bufvoid - bufindex; System.arraycopy(b, off, kvbuffer, bufindex, gaplen); len -= gaplen; off += gaplen; bufindex = 0; } System.arraycopy(b, off, kvbuffer, bufindex, len); bufindex += len; } }
上面的System.arraycopy就是将要写入的b(序列化后的数据)写入到kvbuffer中。关于kvbuffer,我们后面会详细分析,这里需要知道的是序列化后的结果会调用该方法进一步写入到kvbuffer也就是Map后结果的缓存中,后面可以看见,kvbuffer写到一定程度的时候(80%),需要将已经写了的结果刷写到磁盘,这个工作是由Buffer的write判断的。在kvbuffer这样的字节数组中,会被封装为一个环形缓冲区,这样,一个Key可能会切分为两部分,一部分在尾部,一部分在字节数组的开始位置,虽然这样读写没问题,但在对KeyValue进行排序时,需要对Key进行比较,这时候需要Key保持字节连续,因此,当出现这种情况下,需要对Buffer进行重启(reset)操作,这个功能是在BlockingBuffer中完成的,因此,Buffer相当于封装了kvbuffer,实现环形缓冲区等功能,BlockingBuffer则继续对此进行封装,使其支持内部Key的比较功能。本质上,这个缓冲区需要是一个Key-Value记录的缓冲区,而byte[] kvbuffer只是一个字节缓冲区,因此需要进行更高层次的封装。比如:1,到达一定程度需要刷写磁盘;2,Key需要保持字节连续等等。
那么,上面write这个方法又是什么时候调用的呢?实际上就是MapOutputBuffer的collect方法中,会对KeyValue进行序列化,在序列化方法中,会进行写入:
public void serialize(Writable w) throws IOException { w.write(dataOut); }
此处的dataout就是前面keySerializer.open(bb)这一方法中传进来的,也就是BlockingBuffer(又封装了Buffer):
public void open(OutputStream out) { if (out instanceof DataOutputStream) { dataOut = (DataOutputStream) out; } else { dataOut = new DataOutputStream(out); } }
因此,当执行序列化方法serialize的时候,会调用Buffer的write方法,最终将数据写入byte[] kvbuffer。
7,CombinerRunner<K,V> combinerRunner,用于对Map处理的输出结果进行合并处理,减少Shuffle网络开销。CombinerRunner是一个抽象类,根据新旧API的不同,有两种实现:OldCombinerRunner、NewCombinerRunner。这两个类里面都有一个combine方法,实现KeyValue的合并。以OldCombinerRunner为例,其combine方法如下:
protected void combine(RawKeyValueIterator kvIter, OutputCollector<K,V> combineCollector ) throws IOException { Reducer<K,V,K,V> combiner = ReflectionUtils.newInstance(combinerClass, job); try { CombineValuesIterator<K,V> values = new CombineValuesIterator<K,V>(kvIter, comparator, keyClass, valueClass, job, Reporter.NULL, inputCounter); while (values.more()) { combiner.reduce(values.getKey(), values, combineCollector, Reporter.NULL); values.nextKey(); } } finally { combiner.close(); } }
从其代码可以看出,首先根据combinerClass利用反射机制创建了一个combiner对象,实际上这个对象就是一个遵从Reducer接口的对象。之后利用CombineValuesIterator对KV进行逐一提取,执行其reduce方法,CombineValuesIterator在上一节看过,是ValuesIterator的子类,可以看出,combiner实现的就是本Map任务内的、局部的reduce。
8,CombineOutputCollector<K, V> combineCollector,即Combine之后的输出对象。其创建代码为:
if (combinerRunner != null) { combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, conf); } else { combineCollector = null; }
其定义里面有一个Writer对象:
protected static class CombineOutputCollector<K extends Object, V extends Object> implements OutputCollector<K, V> { private Writer<K, V> writer; 。。。
当启用了Combine功能后,会调用上面的combine方法进行(reduce)操作后再写入文件(reduce里会使用CombineOutputCollector对象进行collect,见下面Reducer接口的reduce定义代码),这里的Writer就是写入文件的作用。如果没有启用Combine功能呢,则直接利用Writer写文件。
void reduce(K2 key, Iterator<V2> values, OutputCollector<K3, V3> output, Reporter reporter) throws IOException;
9,CompressionCodec codec,用于对Map的输出进行压缩。其创建代码为:
// compression if (job.getCompressMapOutput()) { Class<? extends CompressionCodec> codecClass = job.getMapOutputCompressorClass(DefaultCodec.class); codec = ReflectionUtils.newInstance(codecClass, job); }
是否对Map的输出进行压缩决定于变量"mapred.compress.map.output",默认不压缩。
10,int[] kvoffsets,int[] kvindices,byte[] kvbuffer。三者是为了记录KV缓存的数据结构,kvBuffer按照Key-Value(序列化后)的顺序记录,前面说的BlockingBuffer和Buffer封装的底层数据结构就是kvbuffer(它们都是内部类,可以处理MapOutputBuffer中的变量);kvindices记录了一堆kvindex,每个kvindex包含三个信息:分区号、Key和Value在kvbuffer中的位置;为了对kvindices中的kvindex进行定位,于是有了第三个结构kvoffsets,只记录每个kvindex的位置(一个整数即可),另外一个作用是当超过了一定数量后,则会触发Spill操作,Spill的中文指溢出,大致的含义是当缓存放慢了,就溢出写到磁盘上去。三者关系的示意图如下:
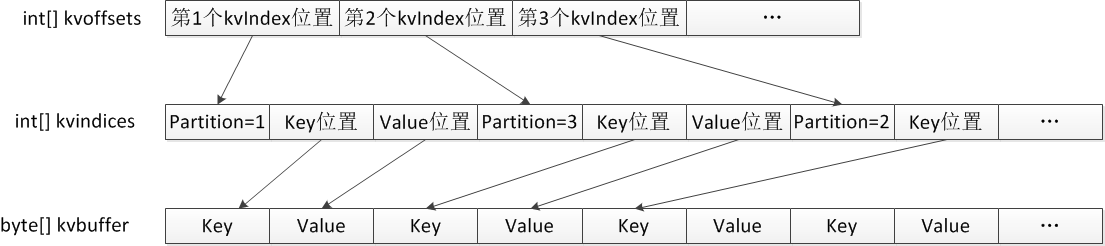
上面的结构有什么好处呢?我们知道,Map输出的结果是一堆KV对,可以不断地存入kvbuffer中,但怎么按照分区号提取相应的KV对呢?kvindices就是干这个的,通过解析这个数组,就可以得到某个分区的所有KV的位置。之所以需要按照分区号提取,是因为Map的输出结果需要分为多份,分别送到不同的Reduce任务,否则还需要对key进行计算才得到分区号,除了提高速度之外,更关键的作用是排序,Map处理后的结果有多份,每一份默认是按照分区号对KV记录进行排序的,但是在kvbuffer中源源不断过来的KeyValue序列并没有什么顺序,为此,当对kvbuffer中的某一个分区的KeyValue序列进行排序时,排序结果只需要将kvoffsets中对应的索引项进行交换即可(后面会看到这一详细过程),保证kvoffsets中索引的顺序其实就想记录的KeyValue的真实顺序。换句话说,我们要对一堆对象进行排序,实际上只要记录他们索引的顺序(类似于指针数组,每个指针指向一个对象)即可,原始记录保持不动(因为空间很大),而kvoffsets就是一堆整数的序列,交换起来快得多。
从上面的图可以看出,对于任意一个KeyValue记录,都会额外产生16个字节的索引开销,其中12个字节是kvindices中用于记录分区号、Key位置和Value位置(都是整型),另外4个字节是kvoffsets中的整数值。MapOutputBuffer类里也定义了几个变量用于说明上述四个变量的位置和所占字节数:
private static final int PARTITION = 0; // partition offset in acct private static final int KEYSTART = 1; // key offset in acct private static final int VALSTART = 2; // val offset in acct private static final int ACCTSIZE = 3; // total #fields in acct private static final int RECSIZE = (ACCTSIZE + 1) * 4; // acct bytes per record
ACCT表示kvindices中的一个kvindex,ACCTSIZE也就是3个字节,这里的命名稍微有些不规范,RECSIZE称为记录大小,这里的记录指的就是对每个KV索引的大小,即3+1=4个字节。
kvbuffer、kvindices、kvoffsets三个数组的大小之和由参数"io.sort.mb"指定,默认是sortmb=100,于是maxMemUsage = sortmb << 20,即100MB(1MB=2^20B),maxMemUsage是MapOutputBuffer所占内存的主要部分。这100MB中,有一部分拿出来存储kvindices和kvoffsets,占比为"io.sort.record.percent",默认是recper=0.05,即5MB左右用来(需要是16的整数倍)存储kvindices和kvoffsets。另外95MB左右用以存储kvbuffer。
在kvbuffer中,如果达到了一定容量,需要Spill到磁盘上,这个门限由参数"io.sort.spill.percent"指定,默认是spillper=0.8。softBufferLimit这个门限就是用于记录Spill门限容量:
softBufferLimit = (int)(kvbuffer.length * spillper);
此外,除了kvbuffer增加会引起Spill之外,kvoffsets的膨胀也会引起Spill,比例也是spillper=0.8,这个门限由softRecordLimit参数记录:
softRecordLimit = (int)(kvoffsets.length * spillper);
即无论哪个到达了80%,都触发Spill。为什么到达80%就需要刷写磁盘呢?如果写满了才刷写磁盘,那么在刷写磁盘的过程中不能写入,写就被阻塞了,但是如果到了一定程度就刷写磁盘,那么缓冲区就一直有剩余空间可以写,这样就可以设计成读写不冲突,提高吞吐量。KV缓存中的最顶级索引是kvoffsets,因此当出现Spill时,需要将kvoffsets中已经记录的索引对应的KV提取出来进行写磁盘,当spill后,kvoffsets又成为空数组。我们粗略想一下,kvoffsets不断地往后增加记录,到达一定程度后,触发Spill,于是从头(即下标0)到当前位置(比如称为kvindex)的所有索引对应的KV都写到磁盘上,Spill结束(此时假定KV缓存写入暂停)后,又从下标0开始增加记录,这种形式会有什么问题?
一个比较大的问题是Spill的时候,意味着有个用户在读取kvoffsets从0-kvindex的数据,这个时候这部分数据就不能写,因为下一次写要从下标0开始,这样就需要对kvoffsets加锁才行,否则会引起读错误,这样的话,还是难以实现读写并行。为了解决这种加锁引发的性能问题,典型方法就是采用环形缓冲区。kvoffsets看做一个环形数组,Spill的时候,只要kvbuffer和kvoffsets还没有满(能容纳新的KeyValue记录和索引),kvoffsets仍然可以继续往后面写;同理,kvbuffer也是一个环形缓冲区,这样的话,如果我们把spill到磁盘这一过程用另外一个线程实现(Hadoop里面确实也是这么做的),那么读写可以不冲突,提高了性能。
实现环形缓冲区的典型方法也是Hadoop中采用的方法。以kvoffsets为例,一共有三个变量:kvstart、kvindex和kvend。kvstart表示当前已写的数据的开始位置,kvindex表示写一个下一个可写的位置,因此,从kvstart到(kvindex-1)这部分数据就是已经写的数据,另外一个线程来Spill的时候,读取的数据就是这一部分。而写线程仍然从kvindex位置开始,并不冲突(如果写得太快而读得太慢,追了一圈后可以通过变量值判断,也无需加锁,只是等待)。
举例来说,下面的第一个图表示按顺时针往kvoffsets里面加入索引,此时kvend=kvstart,但kvindex递增;当触发Spill的时候,kvend=kvindex,Spill的值涵盖从kvstart到kvend-1区间的数据,kvindex不影响,继续按照进入的数据递增;当进行完Spill的时候,kvindex增加,kvstart移动到kvend处,在Spill这段时间,kvindex可能已经往前移动了,但并不影响数据的读取,因此,kvend实际上一般情况下不变,只有在要读取环形缓冲区中的数据时发生一次改变(即设置kvend=kvindex):
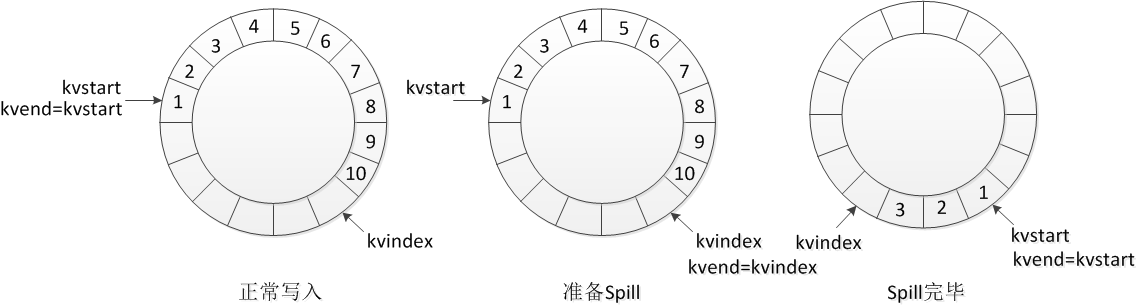
在源代码的解释中,kvstart是记录spill的起始位置,kvend是记录collectable的起始位置,kvindex是记录collected的结束位置,collect即前面说过的map方法产生的KV对需要写入缓冲区,从生产者-消费者角度来看,collect就是这个环形缓冲区的生产者,或者叫写线程;spill是这个环形缓冲区的消费者,或者叫读线程。这样看来,spill每次消费多少数据实际上可以与上面的图有所差别,比如目前只Spill从1-8这个区间的数据,那么之后kvstart设置为9所在的位置即可,下一次Spill即从9开始。
上图反映了环形缓冲区的利用,对于kvbuffer的使用原理也一样,同样存在三个变量:bufstart、bufmark(为什么不叫bufindex呢?下面分析)、bufend。对于kvoffsets来说,有三个变量就可以实现环形缓冲区,但对于kvbuffer来说,三个变量还不够,这是为什么呢?因为kvoffsets里面都是以整数为基本单位,每个整数占用4个字节,kvoffsets的类型是int[],不会出现什么问题,使用起来也很方便。但是kvbuffer就不一样,其定义为byte[],但是一个Key-Value的长度是不固定的,虽然形式上环形缓冲区不存在头部和尾部的概念,但其物理上缓冲区还是存在头和尾,并不是物理连续的,按理来说,对于Key-Value的操作,只要把接口封装好,让上层应用看起来是连续的即可。但Hadoop里面对Key的比较设计成逐字节比较,其定义为:
public interface RawComparator<T> extends Comparator<T> { public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2); }
为什么不设计成compare(Key1 key, Key2 key)这种形式呢?这不是更直观吗,个人理解,排序是对Map后的Key-Value缓冲区操作的,如果将Key、Value都看做JAVA对象,设计Object的排序,排序的速度要比byte这个层次更差,因为封装的层次更高了,所以,将所有key全部序列化后存入缓冲区,然后对其进行排序操作会更快,这样的话,就需要Key在物理上(实际上是JAVA字节数组这个层次,当然不是指硬盘的磁道等等更底层的层次)保持连续,毕竟,按Key排序作为MapReduce中一个很核心的东西,这样做还是值得的。为此,在缓存里面就需要保证Key的连续性,自然,当往缓冲区里面写入一个会超越边界的key的时候,就需要进行特殊处理,这种处理由BlockingBuffer实现,称为reset,当检测到这种情况的时候,就调用一下reset,代码如下:
// serialize key bytes into buffer int keystart = bufindex; keySerializer.serialize(key); if (bufindex < keystart) { // wrapped the key; reset required bb.reset(); keystart = 0; }
所谓reset,其实就是把跨越边界(如何判断:写入一个Key之后的bufindex还比写之前的bufindex位置还小)的Key的尾部拷贝一下到头部,使其连续。bufindex的含义和前面kvindex类似,代表了下一个可以写的位置。如下图所示,红色表示已经写入的KeyValue记录,蓝色表示要写入的下一个Key,在调用Buffer的write方法后,如果发现跨越了边界(bufindex变小了),则将尾部的那块蓝色区域拷贝到头部,头部那块蓝色区域往后挪,形成一个整体的Key,尾部蓝色那块区域空出来的就无效了,在读的时候就需要跳过。这样就需要多个变量来记录位置信息,除了bufindex,bufvoid就表示这个缓冲区在读取的时候需要停止的位置,因为这个位置不一定是缓冲区的最大长度,但肯定只会在缓冲区的尾巴处出现,所以需要1个变量来记录;这里还新增了一个bufmark,其含义是一个KeyValue的结尾处,因为kvoffsets里面不存在这个问题,每个整数值就是一个基本单元,但一个KeyValue长度不一,需要用bufmark记录下来。每当序列化写入一个Key-Value对,就更新这个数值。记下来的目的之一比如说下面这种情况,需要将尾部的蓝色区域拷贝到头部的时候,就需要知道尾部这一段有多少个字节,bufvoid-bufmark就等于尾部这段蓝色区域的长度。

理解了上面的变量,reset的代码就比较简单了,如下,其中headbytelen就是尾部蓝色区域的长度,另外,在下面的代码中,如果拷贝后的key长度超过了bufstart,也就是空间不够了,那么就会直接把key直接输出,此时bufindex置为0:
protected synchronized void reset() throws IOException { int headbytelen = bufvoid - bufmark; bufvoid = bufmark; if (bufindex + headbytelen < bufstart) { System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex); System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen); bufindex += headbytelen; } else { byte[] keytmp = new byte[bufindex]; System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex); bufindex = 0; out.write(kvbuffer, bufmark, headbytelen); out.write(keytmp); } }
12,SpillThread spillThread,这是一个线程对象,继承于Thread:
private final SpillThread spillThread = new SpillThread();
其作用就是当kvbuffer或kvoffsets超过80%以上,将触发该线程将kvbuffer中的数据写入到磁盘。读写分别是两个线程。触发Spill的代码为:
private synchronized void startSpill() { LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark + "; bufvoid = " + bufvoid); LOG.info("kvstart = " + kvstart + "; kvend = " + kvindex + "; length = " + kvoffsets.length); kvend = kvindex; bufend = bufmark; spillReady.signal(); }
从这里可以看出,触发Spill时,正是我们前面分析过的,需要执行这个动作:kvend = kvindex、bufend=bufmark。注意,写入磁盘的数据实际上只是kvbuffer里面的记录,kvoffsets索引只是同步更新,后面我们会看到,跟kvbuffer同时写入的实际上是有一个索引数据的,但不是上面提到的这几个。spillReady是一个java.util.concurrent.locks.Condition对象,环形缓冲区的读写线程之间的同步使用JAVA中提供的方法实现,涉及到以下变量:
private final ReentrantLock spillLock = new ReentrantLock(); private final Condition spillDone = spillLock.newCondition(); private final Condition spillReady = spillLock.newCondition();
我们前面分析过,环形缓冲区在一个生产者和一个消费者条件下,双方对读写数据是不需要加锁的,因为读写数据不会位于同一个位置,大家处理的是整个环上不同的部分,那么这里引入锁的目的是什么呢?一种情况自然是当缓冲区满了的时候,此时可以使用锁,理论上也可以判断变量,看看是否写满等等,但无论如何此时写线程需要阻塞,如果写线程每过一段时间来扫描一下是否可以写,这种方式造成的延时跟另一个线程直接发信号通知比起来更慢;另外,读写双方涉及到三个变量kvstart、kvend、kvindex的修改。也就是说,当写完毕,或者读完毕时需要修改变量的时候,加锁保证了变量的一致性。这里不使用synchronized这种传统的同步方法,主要原因是synchronized不够灵活,扩展性不好,JAVA中提供了另外一种机制,即ReentrantLock等典型锁类。这种方式灵活性更好,因为锁只是一个对象(synchronized是一个关键字,用语法来支持同步)。ReentrantLock的含义是可重入锁,因为Re-entrant就是可以重新进入的意思,什么叫可重入呢?比如一个函数被递归调用,在执行这个函数代码的过程中,还没执行完毕又被再次调用,就是不断重入的意思。ReentrantLock也如此,一个线程A获得锁以后,这个线程A还可以继续再次获取这把锁,其他线程B要想获得这把锁,要么等着A把锁释放了,如果A不显式释放,但是通过发信号等待的方式,也可以间接地使得锁释放(这一点很关键)。此时,线程B就可以获得这把锁。让一个线程多次获取一把锁有什么意义呢?比如有两段代码分布在不同的地方,都加了同样的一个锁对象,某个线程则可以连续执行这两段代码,因为是一把锁。否则,执行完了第一段后,第二段就无法执行了,这样就很容易出现死锁。另外,通过发信号(而且可以有很多不同的信号)的方式释放锁,为线程在不同特定条件下释放锁提供了极大灵活性。
在线程A拿到锁之后,可以通过发送信号控制其它线程B的执行。比如A拿到了锁,但是需要等待一个条件C才能往下执行,但我又不想释放这把锁,于是可以调用一个称为C.await的方法,让线程B可以获得这把锁,去执行它的代码,当在线程B里满足了条件C,它调用C.signal这个方法,则可以让线程A的条件满足不再等待,接着往下执行(但需要线程B释放锁,或者也调用另外一个条件D的await方法)。这种同步模式比较灵活,所以一般来说,典型应用场景是两个线程共有一把ReentrantLock锁,并且有两个以上共有的条件变量Condition1、Condition2。一个线程负责执行Condition1.signal和Condition2.await;另一个线程负责执行Condition2.signal和Condition1.await。
比如上面的例子就创建了两种信号:spillDone和spillReady,它们的逻辑如下:
1)对于写线程来说,如果写满了,就调用spillDone.await等待spillDone信号;否则不断往缓冲区里面写,到了一定程度,就发送spillReady.signal这个信号给读线程,发完这个信号后如果缓冲区没满,就释放锁继续写(这段代码无需锁),如果满了,就等待spillDone信号;
2)对于读线程来说,在平时调用spillReady.await等待spillReady这个信号,当读取之后(此时写线程要么释放锁了,要么调用spillDone.await在等待了,读线程肯定可以获得锁),则把锁释放掉,开始Spill(这段代码无需锁),完了读线程再次获取锁,修改相应参数,发送信号spillDone给写线程,表明Spill完毕。
上面的线程同步模式+环形缓冲区的使用是经典案例,值得仔细学习。
作为SpillThread这个消费者、读线程而言,主要代码是在其run方法内:
public void run() { spillLock.lock(); spillThreadRunning = true; try { while (true) { spillDone.signal(); while (kvstart == kvend) { spillReady.await(); } try { spillLock.unlock(); sortAndSpill(); } catch (Exception e) { 。。。 } finally { spillLock.lock(); if (bufend < bufindex && bufindex < bufstart) { bufvoid = kvbuffer.length; } kvstart = kvend; bufstart = bufend; } } } catch (InterruptedException e) { ........ } finally { spillLock.unlock(); spillThreadRunning = false; } }
MapOutputBuffer的collect方法是生产者、写线程,主要代码即在该方法内,其中startSpill前面已经看过,主要是改变kvend值以及发送spillReady信号:kvnext是kvindex加1,用于判断是否写满,如果kvnext==kvstart,表示写满,布尔变量kvfull则为true。
kvsoftlimit是是否超过Spill门限的标志。
public synchronized void collect(K key, V value, int partition ) throws IOException { final int kvnext = (kvindex + 1) % kvoffsets.length; spillLock.lock(); try { boolean kvfull; do { // sufficient acct space kvfull = kvnext == kvstart; final boolean kvsoftlimit = ((kvnext > kvend) ? kvnext - kvend > softRecordLimit : kvend - kvnext <= kvoffsets.length - softRecordLimit); if (kvstart == kvend && kvsoftlimit) { startSpill(); } if (kvfull) { try { while (kvstart != kvend) { reporter.progress(); spillDone.await(); } } catch (InterruptedException e) { 。。。。。。。。 } } } while (kvfull); } finally { spillLock.unlock(); } 。。。。 写数据 。。。
13,ArrayList<SpillRecord> indexCacheList,这个是SpillRecord的数组,SpillRecord里面缓存的是一个一个的记录,所以并不是一整块无结构字节流,而是以IndexRecord为基本单位组织起来 的,IndexRecord非常简单,描述了一个记录在缓存中的起始偏移、原始长度、实际长度(可能压缩)等信息。SpillRecord里面放了一堆 IndexRecord,并有方法可以插入记录、获取记录等。IndexRecord的定义很简单如下:
class IndexRecord { long startOffset; long rawLength; long partLength; public IndexRecord() { } public IndexRecord(long startOffset, long rawLength, long partLength) { this.startOffset = startOffset; this.rawLength = rawLength; this.partLength = partLength; } }
SpillRecord的意义在什么地方呢?当kvbuffer触发Spill的时候,会将kvbuffer的记录写入到磁盘(实际上还会包括记录的长度等信息)。Spill结束后,会生成一个spill文件,这个文件内部包含很多分区的数据,但是是排序过的KeyValue数据(关于排序后面会讨论),分为两层,首先是对分区号进行排序,其次是在一个分区号内,按照Key的大小进行排序,因此Spill文件是一个分区的数据接着一个分区的数据,且每个分区里面的Key-Value都已经按照Key的顺序进行排列;SpillRecord就记录了每个分区数据在文件中的起始位置、长度、以及压缩长度,这些内容表示成IndexRecord。一个IndexRecord记录的是一个分区的位置信息,因为一个Spill文件包含N个分区,于是就会有N个IndexRecord,这N个IndexRecord记录在一个SpillRecord对象中。SpillRecord里面有两个变量:ByteBuffer buf,以及LongBuffer entries。ByteBuffer和LongBuffer都是java.nio里面提供的类,ByteBuffer是IndexRecord存储的真正区域,LongBuffer就是对ByteBuffer进行了一点接口封装,把它当做一个存储Long型的Buffer。这种概念类似于数据库里面的视图跟表的关系一样。因为IndexRecor里面包含三个Long型变量,每个8字节,因此一个 IndexRecord记录占用24字节,这就是MapTask.MAP_OUTPUT_INDEX_RECORD_LENGTH这个变量指定的。分区数量是numPartitions,因此一个文件需要numPartitions*24来记录,这也就是一个SpillRecord的大小,每个文件都有一个SpillRecord,因为Spill会有很多次,每次都写成一个文件,所以会有很多个Spill文件,对应于很多个SpillRecord,这很多个SpillRecord即为ArrayList<SpillRecord> indexCacheList。
为什么要把各个分区数据的位置记录下来呢?因为MapReduce对Map后的结果会按照分区号对Key-Value进行排序,假定最终生成了10个Spill文件,需要按照分区,将每个分区对应的数据全部拿出来进行归并排序(Merger),这种排序在Map这一端就有两个阶段,首先是一个Spill文件内部要按照分区对KV排好序(kvoffsets排好序按照顺序写进Spill文件),之后还得把10个Spill文件内部的KV拿过来归并排序。另外,实际上在Reduce端还会进行归并排序,因为我们目前讨论的都只是在单个Map任务内的排序,Reduce之前还会把各个Map任务排好序的结果进行再次归并排序,可见,有三种归并排序,MapReduce中的排序就是不断地进行归并排序的过程。
另外,除了将kvbuffer的数据写进文件,SpillRecord的信息也会写到文件里,作为后面多个Spill文件归并的索引。如果不写入这个信息,怎么知道Spill文件里面的KeyValue是属于哪个分区呢?如果没有这个信息,也就无法实现后面的归并。
14,IndexedSorter sorter,理解了上面的过程,这个变量就容易了,如何对map后的KeyValue进行排序就取决于该对象。IndexedSorter是一个接口,用户可以实现自定义的方法,其创建代码如下:
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class", QuickSort.class, IndexedSorter.class), job);
可以看出,如果用户没有配置,默认就使用Hadoop自带的QuickSort类,即快速排序。另外,排序的规则是对Key进行比较,这里采用的比较对象就是RawComparator<K> comparator。
排序的对象是一个IndexedSortable接口对象,MapOutputBuffer实现了这个接口中的compare和swap方法,compare方法即比较两个Key的大小,返回整数:
public int compare(int i, int j) { final int ii = kvoffsets[i % kvoffsets.length]; final int ij = kvoffsets[j % kvoffsets.length]; // sort by partition if (kvindices[ii + PARTITION] != kvindices[ij + PARTITION]) { return kvindices[ii + PARTITION] - kvindices[ij + PARTITION]; } // sort by key return comparator.compare(kvbuffer, kvindices[ii + KEYSTART], kvindices[ii + VALSTART] - kvindices[ii + KEYSTART], kvbuffer, kvindices[ij + KEYSTART], kvindices[ij + VALSTART] - kvindices[ij + KEYSTART]); }
可见,这个比较分为两个层次,首先是分区号的排序,在分区号相同条件下,再进行Key的比较。怎么进行Key的比较呢?每个kvoffsets里面就一个字节,记录了对应的kvindex,kvindex又有3字节,分别是分区号、key在kvbuffer的位置、value在kvbuffer的位置,所以其比较就是首先获得i、j对应的两个kvindex,最终调用RawComparator<K> comparator的compare方法,比较两个Key值的大小,key在kvbuffer中的位置是在kvindices[ii + 1]开始到kvindices[ii + 2]之间,另一个key的位置是在kvbuffer的kvindices[ij + 1]到kvindices[ij + 2]之间。前面已经对kvbuffer、kvindices、kvoffsets进行了详细分析,这里也就比较简单了。
在排序的过程中会进行交换,kvbuffer和kvindices都保持不变,只有kvoffsets进行了交换:
public void swap(int i, int j) { i %= kvoffsets.length; j %= kvoffsets.length; int tmp = kvoffsets[i]; kvoffsets[i] = kvoffsets[j]; kvoffsets[j] = tmp; }
因为按照排序原则,如果不是同一个分区的KV,那就不用排序;如果是同一个分区的KV,那就进行排序,所以最终的排序只在kvoffsets中进行交换,当交换完毕后,排序也就结束。要写入文件时,只要按照kvoffsets的顺序将对应的kvbuffer中的数据写入文件即可。
15,上面对MapOutputBuffer涉及的变量进行了分析,其原理也基本涵盖在上面的各个分析之中,下面我们来看一看collect方法的过程。
该方法的声明为:
public synchronized void collect(K key, V value, int partition ) throws IOException
其作用就是对map之后的KeyValue进行处理。
首先获得kvoffsets中的kvindex的下一个位置,用于判断kvoffsets是否写满:
final int kvnext = (kvindex + 1) % kvoffsets.length;
因为kvindex代表了下一个可写的位置,如果再下一个已经等于kvstart,那么说明已经写满了,需要等待SpillThread处理。
于是设置了一个变量kvfull = kvnext == kvstart;即二者相等时即为true。
要判断是否Spill,加锁:
spillLock.lock();
之后判断是否应该Spill:
final boolean kvsoftlimit = ((kvnext > kvend) ? kvnext - kvend > softRecordLimit : kvend - kvnext <= kvoffsets.length - softRecordLimit);
之所以会有两种情况,是因为这是一个环形缓冲区,可能kvnext大于kvend(没有Spill时等于kvstart)很多,也可能kvnext已经绕回到了0那个位置,不管怎样,如果两者的差距(绝对值)大于softRecordLimit(80%的kvoffsets),则kvsoftlimit=true。
如果kvstart==kvend,表示此时没有处于Spill(前面分析过,Spill时会将kvend设置为kvindex),并且如果满足了kvsoftlimit,则进行Spill,向SpillThread发信号:
if (kvstart == kvend && kvsoftlimit) { LOG.info("Spilling map output: record full = " + kvsoftlimit); startSpill(); }
发完信号后不一定可以写了,因为此时缓冲区说不定满了,所以如果满了,就等待SpillDone信号,这个信号是SpillThread发过来的:
if (kvfull) { try { while (kvstart != kvend) { reporter.progress(); spillDone.await(); } } catch (InterruptedException e) { throw (IOException)new IOException( "Collector interrupted while waiting for the writer" ).initCause(e); } }
好了,如果跳出来了,说明此时缓冲区可写了,于是把锁释放,准备往缓冲区里面写数据(再重复一遍,读写数据不用加锁):
finally { spillLock.unlock(); }
要写入key,首先要将其序列化:
int keystart = bufindex; keySerializer.serialize(key);
之后,因为有可能key序列化后超出了kvbuffer的边界,进行一些边界条件处理,这一边界问题在前面已经分析过:
if (bufindex < keystart) { // wrapped the key; reset required bb.reset(); keystart = 0; }
紧接着是对value进行序列化:
// serialize value bytes into buffer final int valstart = bufindex; valSerializer.serialize(value); int valend = bb.markRecord();
之后,更新kvindices,kvoffsets中的索引信息:
// update accounting info int ind = kvindex * ACCTSIZE; kvoffsets[kvindex] = ind; kvindices[ind + PARTITION] = partition; kvindices[ind + KEYSTART] = keystart; kvindices[ind + VALSTART] = valstart; kvindex = kvnext;
此处的ind就是新的kvindex的位置,乘以3字节就等于其在kvindices中的位置。同时更新kvindices,kvindex向前移动一个字节。
于是,collect方法就结束了,KV已经被序列化进入kvbuffer了,下面看一看SpillThread涉及到的方法。
16,SpillThread在构造方法中被启动:
spillThread.setDaemon(true); spillThread.setName("SpillThread"); spillLock.lock(); try { spillThread.start(); while (!spillThreadRunning) { spillDone.await(); } } catch (InterruptedException e) { throw (IOException)new IOException("Spill thread failed to initialize" ).initCause(sortSpillException); } finally { spillLock.unlock(); }
进入SpillThread的run方法,该方法的处理逻辑在前面已经分析过,主要涉及的方法是sortAndSpill。
首先获得要写入的Spill文件的大小:
//approximate the length of the output file to be the length of the //buffer + header lengths for the partitions long size = (bufend >= bufstart ? bufend - bufstart : (bufvoid - bufend) + bufstart) + partitions * APPROX_HEADER_LENGTH;
每个分区都会有一些头开销,此处为150个字节,这个与Spill文件的文件格式有关,在每个分区之前都会加入一些记录信息,这里可以看出,Spill文件里面实际上是所有分区的数据混合在一起(但是是一个分区的数据跟着另一个分区的数据)。
然后获取要写入的本地文件的文件名,注意不是HDFS文件,而是本地Linux文件:
// create spill file final SpillRecord spillRec = new SpillRecord(partitions); final Path filename = mapOutputFile.getSpillFileForWrite(numSpills, size); out = rfs.create(filename); public Path getSpillFileForWrite(int spillNumber, long size) throws IOException { return lDirAlloc.getLocalPathForWrite(TaskTracker.OUTPUT + "/spill" + spillNumber + ".out", size, conf); }
在这时会创建一个与Spill文件对应的SpillRecord对象(输入参数为分区总数),其文件名为:
TaskTracker.OUTPUT + "/spill" + spillNumber + ".out"
TaskTracker.OUTPUT其实就是一个字符串String OUTPUT = "output",所以Spill的文件名为output/spill2.out等,表示这个文件是第2个Spill文件(最终会有多个Spill文件,前面分析过)。
然后调用上面分析过的排序对象进行排序,实际上就是通过交换kvoffsets里面的字节达到目的:
final int endPosition = (kvend > kvstart) ? kvend : kvoffsets.length + kvend; sorter.sort(MapOutputBuffer.this, kvstart, endPosition, reporter);
之后是一个大循环,对每个分区依次进行以下操作。
创建一个写文件的对象:
writer = new Writer<K, V>(job, out, keyClass, valClass, codec, spilledRecordsCounter);
此时有两种情况,排序后的Key-Value不一定直接写入文件,如果需要在Map端进行合并(Combiner)的话,则先进行合并再写入:
我们先来看不需要合并的代码。就是一个循环:
DataInputBuffer key = new DataInputBuffer(); while (spindex < endPosition && kvindices[kvoffsets[spindex % kvoffsets.length] + PARTITION] == i) { final int kvoff = kvoffsets[spindex % kvoffsets.length]; getVBytesForOffset(kvoff, value); key.reset(kvbuffer, kvindices[kvoff + KEYSTART], (kvindices[kvoff + VALSTART] - kvindices[kvoff + KEYSTART])); writer.append(key, value); ++spindex; }
注意while条件中只挑选那些分区号满足大循环中当前分区号的数据,获得KeyValue在kvbuffer中的位置(kvoff),然后key的值就从kvindices[kvoff + KEYSTART]到kvindices[kvoff + VALSTART]之间。KEYSTART和VALSTART是固定值1、2,我们再回顾一下,kvindices[kvoff]记录的是分区号、kvindices[kvoff + 1]记录的Key在kvbuffer中的起始位置,kvindices[kvoff + 2]记录的是Value在kvbuffer中的起始位置,于是就得到了key。
Value的获取是利用getVBytesForOffset实现的。原理也一样:
private void getVBytesForOffset(int kvoff, InMemValBytes vbytes) { final int nextindex = (kvoff / ACCTSIZE == (kvend - 1 + kvoffsets.length) % kvoffsets.length) ? bufend : kvindices[(kvoff + ACCTSIZE + KEYSTART) % kvindices.length]; int vallen = (nextindex >= kvindices[kvoff + VALSTART]) ? nextindex - kvindices[kvoff + VALSTART] : (bufvoid - kvindices[kvoff + VALSTART]) + nextindex; vbytes.reset(kvbuffer, kvindices[kvoff + VALSTART], vallen); }
即nextindex要么是bufend,要么是绕一圈之后的对应值。
之后调用writer.append(key, value)写入KV即可。
如果是需要对KeyValue进行合并的,则执行combine方法:
if (spstart != spindex) { combineCollector.setWriter(writer); RawKeyValueIterator kvIter = new MRResultIterator(spstart, spindex); combinerRunner.combine(kvIter, combineCollector); }
combine方法我们前面分析过,其实就是调用了用户写的reduce方法:
protected void combine(RawKeyValueIterator kvIter, OutputCollector<K,V> combineCollector ) throws IOException { Reducer<K,V,K,V> combiner = ReflectionUtils.newInstance(combinerClass, job); try { CombineValuesIterator<K,V> values = new CombineValuesIterator<K,V>(kvIter, comparator, keyClass, valueClass, job, Reporter.NULL, inputCounter); while (values.more()) { combiner.reduce(values.getKey(), values, combineCollector, Reporter.NULL); values.nextKey(); } } finally { combiner.close(); } } }
当写入Spill文件后,还需要对SpillRecord进行记录:
// record offsets rec.startOffset = segmentStart; rec.rawLength = writer.getRawLength(); rec.partLength = writer.getCompressedLength(); spillRec.putIndex(rec, i);
即当前这个分区中数据的起始位置、原始长度、压缩后长度。在Writer类中,其append方法会将Key长度和Value长度都写进去:
WritableUtils.writeVInt(out, keyLength);
WritableUtils.writeVInt(out, valueLength);
out.write(key.getData(), key.getPosition(), keyLength);
out.write(value.getData(), value.getPosition(), valueLength);
使用的VInt即变长整数编码,这种编码方式类似于ProtoBuf(但是否完全一样还没分析),见我写的另外一篇介绍ProtocolBuffer的博客。可以看出,KeyValue的记录加上了Key的长度、Value的长度两个信息,如果不加无法区分Key、Value的边界。
注意到,如果设置了压缩,则在Writer构造方法里将写入流对象换成另外一个:
if (codec != null) { this.compressor = CodecPool.getCompressor(codec); this.compressor.reset(); this.compressedOut = codec.createOutputStream(checksumOut, compressor); this.out = new FSDataOutputStream(this.compressedOut, null); this.compressOutput = true; } else { this.out = new FSDataOutputStream(checksumOut,null); }
按照上面的过程,对每个分区进行循环即可不断地写入到Spill文件,可见,一个Spill文件,比如output/spill2.out这个文件,其内容是一个分区跟着一个分区,每个分区里面的数据都经过了排序。每次触发Spill的时候就会生成一个文件。如:
output/spill1.out、output/spill2.out、output/spill3.out、....
写完了Spill文件后,还会把SpillRecord的内容写入成一个Spill索引文件,不过这个写不是一个Spill文件就对应于一个索引文件,而是超过了一个界限(1MB)再写入:
if (totalIndexCacheMemory >= INDEX_CACHE_MEMORY_LIMIT) { // create spill index file Path indexFilename = mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH); spillRec.writeToFile(indexFilename, job); } else { indexCacheList.add(spillRec); totalIndexCacheMemory += spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH; }
从getSpillIndexFileForWrite方法来看,其命名是output/spill2.out.index等等:
public Path getSpillIndexFileForWrite(int spillNumber, long size) throws IOException { return lDirAlloc.getLocalPathForWrite(TaskTracker.OUTPUT + "/spill" + spillNumber + ".out.index", size, conf); }
所以,实际上并不是一个Spill文件就对应于一个spill index文件。但一个Spill文件确实是对应于一个SpillRecord的,一个SpillRecord的大小等于分区数量*24字节。
17,到此为止,MapOutputBuffer的基本处理过程就明白了,那么,什么时候结束呢,自然是当Map输入数据处理完毕之后,由下面的代码进行结束的:
try { runner.run(in, new OldOutputCollector(collector, conf), reporter); collector.flush(); in.close(); in = null; collector.close(); collector = null; } finally { closeQuietly(in); closeQuietly(collector); }
此时就调用了collector的flush方法。在map内只是调用其collect方法。因此我们再来看看其flush方法。
flush方法的逻辑还是比较清楚的,首先对kvbuffer内剩余还没有Spill的数据进行Spill:
spillLock.lock(); try { while (kvstart != kvend) { reporter.progress(); spillDone.await(); } if (sortSpillException != null) { throw (IOException)new IOException("Spill failed" ).initCause(sortSpillException); } if (kvend != kvindex) { kvend = kvindex; bufend = bufmark; sortAndSpill(); } } catch (InterruptedException e) { throw (IOException)new IOException( "Buffer interrupted while waiting for the writer" ).initCause(e); } finally { spillLock.unlock(); }
可以看出,此时是这个线程调用了sortAndSpill方法(之前是SpillThread那个线程调用)。
全部刷写到磁盘后,给SpillThread线程发送暂停信号,等待SpillThread关闭(join方法):
try { spillThread.interrupt(); spillThread.join(); } catch (InterruptedException e) { throw (IOException)new IOException("Spill failed" ).initCause(e); }
之后,我们得到了N个Spill文件以及多个索引文件,于是需要按照分区归并成分区数量个文件,调用mergeParts方法。mergeParts方法的目的是将多个Spill文件合并为一个,注意,虽然最后要把结果送到多个Reduce任务去,但仍然只是写到一个文件里,不同Reduce任务需要的数据在文件的不同区域。按照SpillRecord索引信息可以取出来。
18,在mergeParts里,首先获得这些Spill文件的文件名:
for(int i = 0; i < numSpills; i++) { filename[i] = mapOutputFile.getSpillFile(i); finalOutFileSize += rfs.getFileStatus(filename[i]).getLen(); }
如果numSpills=1,那么Spill文件相当于就是要Map输出的文件,因为在Spill内部已经进行了排序。而且因为没有多余的Spill文件需要归并,所以重命名文件名即可:
if (numSpills == 1) { //the spill is the final output rfs.rename(filename[0], new Path(filename[0].getParent(), "file.out")); if (indexCacheList.size() == 0) { rfs.rename(mapOutputFile.getSpillIndexFile(0), new Path(filename[0].getParent(),"file.out.index")); } else { indexCacheList.get(0).writeToFile(new Path(filename[0].getParent(),"file.out.index"), job); } return; }
此时,Map输出文件名为output/file.out和output/file.out.index。
如果多于一个Spill文件,则需要进行归并处理。
首先将全部索引数据从文件中读出来,加入到indexCacheList数组里,这里似乎有一个问题,如果索引文件太大怎么办,会不会导致Out of Memory?不过粗略算一下应该不太可能,假定Reduce个数是100个,一个SpillRecord的大小则是2400字节。假定Map任务输出100个Spill文件,则indexCacheList大小为240000字节,240KB。这个数量级已经是MapReduce中比较大的了,所以可以忽略这个问题。
// read in paged indices for (int i = indexCacheList.size(); i < numSpills; ++i) { Path indexFileName = mapOutputFile.getSpillIndexFile(i); indexCacheList.add(new SpillRecord(indexFileName, job, null)); }
获得这个indexCacheList的目的是为了方便地找到某个分区在各个Spill文件中的位置,以便进行归并处理:
之后,获得最终要输出的文件名:
//make correction in the length to include the sequence file header //lengths for each partition finalOutFileSize += partitions * APPROX_HEADER_LENGTH; finalIndexFileSize = partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH; Path finalOutputFile = mapOutputFile.getOutputFileForWrite(finalOutFileSize); Path finalIndexFile = mapOutputFile.getOutputIndexFileForWrite(finalIndexFileSize);
从下面可以看出Map输出的文件名,分别是file.out和file.out.index,最终输出也就是这两个文件:
public Path getOutputFileForWrite(long size) throws IOException { return lDirAlloc.getLocalPathForWrite(TaskTracker.OUTPUT + Path.SEPARATOR + "file.out", size, conf); } public Path getOutputIndexFileForWrite(long size) throws IOException { return lDirAlloc.getLocalPathForWrite(TaskTracker.OUTPUT + Path.SEPARATOR + "file.out.index", size, conf); }
创建文件,rfs是本地文件系统:
//The output stream for the final single output file FSDataOutputStream finalOut = rfs.create(finalOutputFile, true, 4096);
如果一个分区文件都没有,也需要创建记录文件(CRC等信息,这样更不会出错,否则会不会文件被删了?):
if (numSpills == 0) { //create dummy files IndexRecord rec = new IndexRecord(); SpillRecord sr = new SpillRecord(partitions); try { for (int i = 0; i < partitions; i++) { long segmentStart = finalOut.getPos(); Writer<K, V> writer = new Writer<K, V>(job, finalOut, keyClass, valClass, codec, null); writer.close(); rec.startOffset = segmentStart; rec.rawLength = writer.getRawLength(); rec.partLength = writer.getCompressedLength(); sr.putIndex(rec, i); } sr.writeToFile(finalIndexFile, job); } finally { finalOut.close(); } return; }
否则,对于每个分区进行一个大循环,内部对每个Spill文件进行一个小循环:
for (int parts = 0; parts < partitions; parts++) { List<Segment<K,V>> segmentList = new ArrayList<Segment<K, V>>(numSpills); for(int i = 0; i < numSpills; i++) { IndexRecord indexRecord = indexCacheList.get(i).getIndex(parts); Segment<K,V> s = new Segment<K,V>(job, rfs, filename[i], indexRecord.startOffset, indexRecord.partLength, codec, true); segmentList.add(i, s); 。。。。。。。
segmentList是关于一个分区的信息,这个分区信息在每一个Spill文件中都存在,根据IndexRecord可以生成出来,除了位置信息,还包括是否采用了压缩等等信息。
之后,调用Merger中的merge方法进行归并处理:
//merge @SuppressWarnings("unchecked") RawKeyValueIterator kvIter = Merger.merge(job, rfs, keyClass, valClass, codec, segmentList, job.getInt("io.sort.factor", 100), new Path(mapId.toString()), job.getOutputKeyComparator(), reporter, null, spilledRecordsCounter);
这个方法也比较复杂,主要实现的是归并排序,在后面各节再进行详细分析。这里可以看出,在一个Map任务内,对于某个分区的那些记录,默认用快速排序(QuickSort)实现,之后更大范围的排序使用归并排序。
归并完毕后,将其写入文件,这里又见到了Combine,我们在前面已经分析过Combine,那里是对每个刷写Spill文件之前某个分区的KV进行合并,这里是对归并排序后每个分区的结果进行归并,是不是冗余了?实际上不是,前面那个Combine还是局部的Combine,后面这个Combine是在前面的那个合并的基础上进行的再次合并。比如要对64MB的文本计算hello这个单词出现的次数,前面那个Combine比如是对每1MB内的文本累积次数,一共有64个数,最后这个Combine是对64个数加起来,得到64MB中hello的次数,这就是Map的输出结果;Reduce那边则是对整个大文件(比如6400MB)的hello次数根据不同Map任务(即100个数)输出的结果进行再次累和,Combine基本上可以理解为就是Map端的Reduce。因此,从Combine、Sort等过程来看,MapReduce就是一个将小数据的结果进行处理,得到局部(合并、排序)结果后,然后不断汇总处理的过程。基本上有三个阶段,一个是在单个Spill内,一个是单个Map内,一个是全局处理。个人理解这算是MapReduce的核心思想。
Writer<K, V> writer =
new Writer<K, V>(job, finalOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null || numSpills < minSpillsForCombine) {
Merger.writeFile(kvIter, writer, reporter, job);
} else {
combineCollector.setWriter(writer);
combinerRunner.combine(kvIter, combineCollector);
}
同样,对每个分区都记录索引信息:
// record offsets rec.startOffset = segmentStart; rec.rawLength = writer.getRawLength(); rec.partLength = writer.getCompressedLength(); spillRec.putIndex(rec, parts);
等到每个分区都完成了上面的步骤后,将索引信息写入到一个文件:
spillRec.writeToFile(finalIndexFile, job);
然后删除以前写入的各个Spill文件:
for(int i = 0; i < numSpills; i++) { rfs.delete(filename[i],true); }
于是整个Map输出过程即结束。
后记:本节将Map处理后的结果(Key-Value记录序列)如何处理的过程分析了一遍,其核心思想是要按照分区来处理,以便送到不同的Reduce任务,先缓存、到达一定程度后刷写磁盘,刷写之前进行Spill这个层面的Combine和Sort,得到N个Spill文件,最后,对N个Spill文件的结果进行归并排序和二次Combine。最终得到一个结果文件写入到本地,等待Reduce来取,至于Reduce怎么来取,以及Map端又怎么配合,在后续博文中再进行分析。
另外,从本节可以看出,一个好的框架不仅仅是思想,更重要的是为了实现这些想法,采用哪些算法和数据结构,比如缓存怎么设计,排序如何实现,使得流程既高效,又通用,这可能就是软件框架设计的核心吧。慢慢学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号