hive over窗口函数的使用
前言:我们在学习hive窗口函数的时候,一定要先了解窗口函数的结构。而不是直接百度sum() over()、row_number() over()、或者count() over()的用法,如果这样做,永远也掌握不到窗口函数的核心,当然我刚开始的时候也是这样做的。
还好我比较顽强,在HIVE窗口函数问题上折腾了半个月、看了很多文章后才知道over()才是窗口函数,而sum、row_number、count只是与over()搭配的分析函数,当然除了这三个函数还有其他的函数。
个人对over()的窗口理解:这个永远是一行对应一个窗口,至于这个窗口的范围是什么就要看over()函数里面对窗口范围的约束是什么了(partition by order by between ... and)通过partition by 关键字来对窗口分组,特殊注意:通过order by 来对order by字段排序后的行进行开窗,只不过注意的是第一行数据的窗口大小是1,第二行数据的窗口范围是前2行,第n行的窗口范围是前n行,以此类推。如果里面没有条件,则每一行对应整张表。
特殊的窗口函数如rank(),rownumber(),dense()等,即使后面over()里面没有条件,默认的开窗类似order by效果,即第一行窗口大小为1,第二行窗口大小为2,以此类推,但是数据只不过没有什统计意义,所以一般还是会在over()里加入partiton by和order by(分组,排序)等,为其赋予意义 如排名等。
over(partition by ) 和 普通的group by的区别,为什么不同group by,因为有group by,只能select group by 后面的字段,和一些聚合函数 sum(),avg(),max(),min()等,而用了over(partition by),还能select 别的非partition by 字段 或者能直接“select *”,而且对于join 等有更好的支持。
一、hive窗口函数语法
在前言中我们已经说了avg()、sum()、max()、min()是分析函数,而over()才是窗口函数,下面我们来看看over()窗口函数的语法结构、及常与over()一起使用的分析函数
- over()窗口函数的语法结构
- 常与over()一起使用的分析函数
- 窗口函数总结
1、over()窗口函数的语法结构
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
over()函数中包括三个函数:包括分区partition by 列名、排序order by 列名、指定窗口范围rows between 开始位置 and 结束位置。我们在使用over()窗口函数时,over()函数中的这三个函数可组合使用也可以不使用。
over()函数中如果不使用这三个函数,窗口大小是针对查询产生的所有数据,如果指定了分区,窗口大小是针对每个分区的数据。
1.over() 默认此时每一行的窗口都是所有的行
select *,count(1) over() from business;

2.over(order by orderdate)
orderdate=1的窗口只有一行,orderdate=2的窗口包括orderdate=2017-01-01,orderdate=2017-01-02
select *,count(1) over(order by orderdate) from business;

3.over(partition by name)每一行根据 name来区分窗口
select *,sum(cost) over(partition by name) from business;
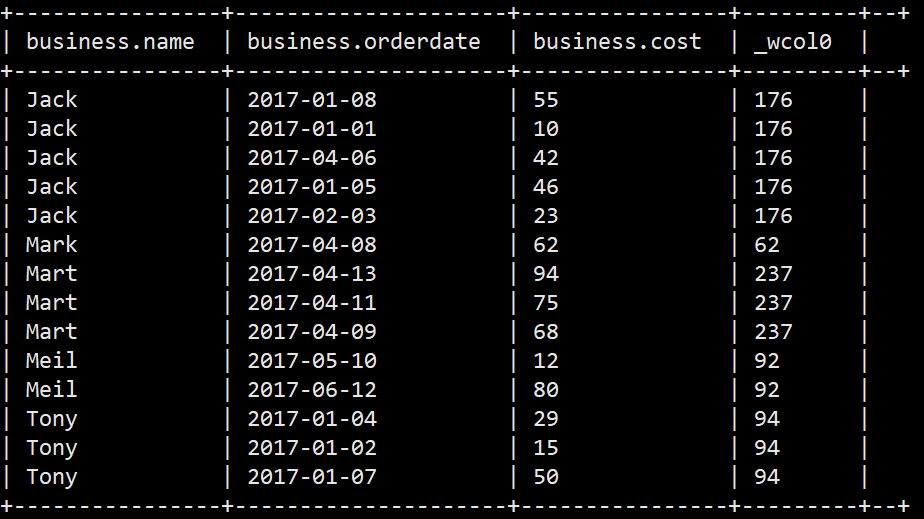
4.over(partition by name order by id) 每一行根据 name来区分窗口,再根据order by 取具体的范围
select *,sum(cost) over(partition by name order by orderdate) from business;
1.1、over()函数中的三个函数讲解
order by
order by是排序的意思,是该窗口中的
A、partition bypartition by可理解为group by 分组。over(partition by 列名)搭配分析函数时,分析函数按照每一组每一组的数据进行计算的。
B、rows between 开始位置 and 结束位置
是指定窗口范围,比如第一行到当前行。而这个范围是随着数据变化的。over(rows between 开始位置 and 结束位置)搭配分析函数时,分析函数按照这个范围进行计算的。
窗口范围说明:
我们常使用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行),常用该窗口来计算累加。
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
比如说:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行)
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING(表示往前2行到往后1行)
ROWS BETWEEN 2 PRECEDING AND 1 CURRENT ROW(表示往前2行到当前行)
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING(表示当前行到终点)
2、常与over()一起使用的分析函数:
2.1 聚合类
avg()、sum()、max()、min()
2.2 排名类
row_number()按照值排序时产生一个自增编号,不会重复(如:1、2、3、4、5、6)
rank() 按照值排序时产生一个自增编号,值相等时会重复,会产生空位(如:1、2、3、3、3、6)
dense_rank() 按照值排序时产生一个自增编号,值相等时会重复,不会产生空位(如:1、2、3、3、3、4)
2.3 其他类
lag(列名,往前的行数,[行数为null时的默认值,不指定为null]),可以计算用户上次购买时间,或者用户下次购买时间。或者上次登录时间和下次登录时间
lead(列名,往后的行数,[行数为null时的默认值,不指定为null])
ntile(n) 把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号
3、窗口函数总结:
其实窗口函数逻辑比较绕,我们可以把窗口理解为对表中的数据进行分组,排序等计算。要真正的理解HIVE窗口函数,还是要结合练习题才行。下面我们开始HIVE窗口函数的练习吧!
二、hive窗口函数练习28道题
第一套练习:hive之简单窗口函数 over()
1、使用 over() 函数进行数据统计, 统计每个用户及表中数据的总数
-
求用户明细并统计每天的用户总数
-
计算从第一天到现在的所有 score 大于80分的用户总数
-
计算每个用户到当前日期分数大于80的天数
测试数据
20191020,11111,85
20191020,22222,83
20191020,33333,86
20191021,11111,87
20191021,22222,65
20191021,33333,98
20191022,11111,67
20191022,22222,34
20191022,33333,88
20191023,11111,99
20191023,22222,33
建表并导入数据:
create table test_window
(logday string, #logday时间
userid string,
score int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
#加载数据
load data local inpath '/home/xiaowangzi/hive_test_data/test_window.txt' into table test_window;
我们先看下表中的数据:
select * from test_window;
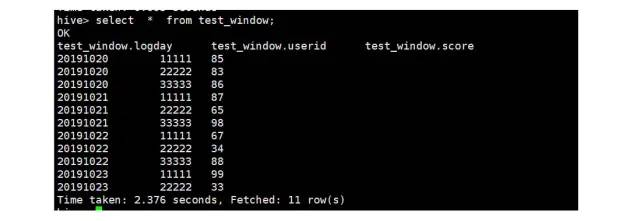
test_window
1、使用 over() 函数进行数据统计, 统计每个用户及表中数据的总数
select *, count(userid) over() as total from test_window;
这里使用 over() 与 select count(*) 有相同的作用,好处就是,在需要计算总数时不用再进行一次关联。
2、求用户明细并统计每天的用户总数
可以使用 partition by 按日期列对数据进行分区处理,如:over(partition by logday)
select *,count()over(partition by logday)as day_total from test_window;
求每天的用户数可以使用select logday, count(userid) from recommend.test_window group by logday,但是当想要得到 userid 信息时,这种用法的优势就很明显。
3、计算从第一天到现在的所有 score 大于80分的用户总数
此时简单的分区不能满足需求,需要将 order by 和 窗口定义结合使用。
select *,count()over(order by logday rows between unbounded preceding and current row)as total
from test_window
where score > 80;
通过 over() 计算出按日期的累加值。
其实自己刚开始的时候就计算我思路是错了,我就想的是不用累加,直接select *,count()over()as total from test_window where score > 80;这样计算,如果这样计算的话只会显示表中所有大于80的人数,如果我想看20191021或者看20191022的人数看不见。
4、计算每个用户到当前日期分数大于80的天数
select *,
count()over(partition by userid order by logday rows between unbounded preceding and current row) as total
from test_window
where score > 80 order by logday, userid;
第二套练习
有以下数据:字段名为:name、orderdate、cost
Jack,2017-01-01,10
Tony,2017-01-02,15
Jack,2017-02-03,23
Tony,2017-01-04,29
Jack,2017-01-05,46
Jack,2017-04-06,42
Tony,2017-01-07,50
Jack,2017-01-08,55
Mark,2017-04-08,62
Mart,2017-04-09,68
Meil,2017-05-10,12
Mart,2017-04-11,75
Meil,2017-06-12,80
Mart,2017-04-13,94
需 求
1、查询2017-04购买的顾客总人数
2、顾客购买明细及月份总额
3、上述场景,将cost按日期累加
4、查询顾客上次购买时间
5、查询前20%购买的订单信息
一、建表并导入数据:
-- 建表
create table business(
name string,
orderdate string,
cost int)
row format delimited
fields terminated by ",";
--导入数据
load data local inpath "/business.txt" into table business;
-- 查询表:
select * from business;
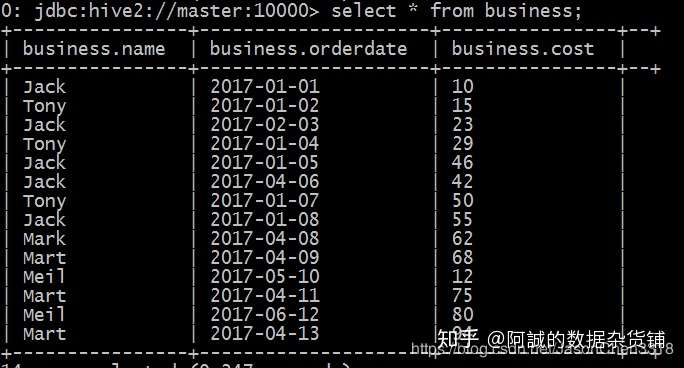
需求分析
一、查询2017-04购买的顾客总人数
a、首先想到使用聚合函数count()
-- 先求出2017-04这月一共有多少条记录
select count(*) from business where substr(orderdate,1,7) = "2017-04";
结果如下图:

b、现在按照顾客进行分组
select name,count(*) from business where substr(orderdate,1,7) = "2017-04" group by name;
结果如下图:

数据被分成了三组:
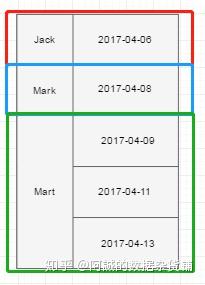

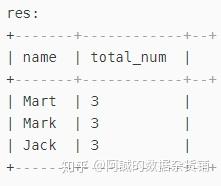
使用over()函数:over只对聚合函数起作用,count分别对上面三个组内进行计数,over统计一共有多少个组(有一个count进行累加一次)
select
name,count(*) over() total_num
from business where substr(orderdate,1,7) = "2017-04" group by name;
结果如下所示:
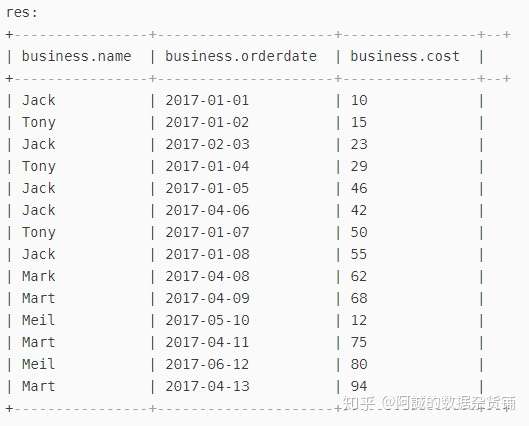
二、查询顾客购买明细及月份总额
a、首先选出所有明细信息:
select * from business;
b、求总额:(这是所有数据的总和,因为没有分组(group by),所以over()的针对的是每一条数据)
select *, sum(cost) over() from business;
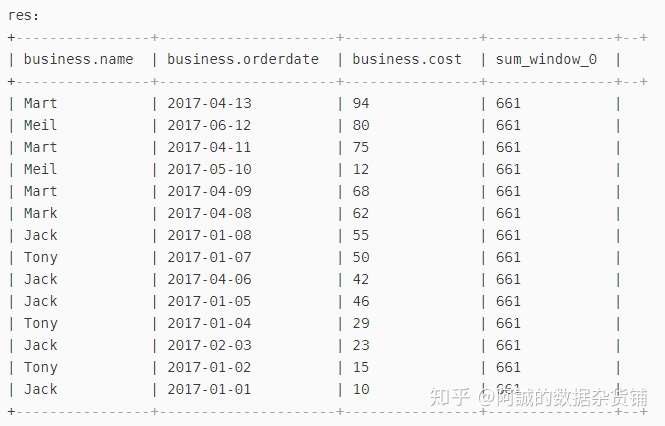
c、针对四月份的数据,我们需要进行求总额,
思路:分区或者分组,但是使用group by date,只能查询date,(select date ,name group by date)其它字段不能查询
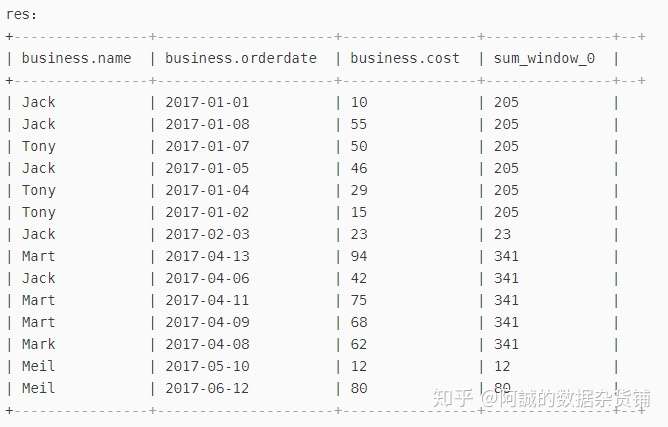
解决:使用窗口函数,并对窗口函数进行分区over(distribute by()) 或者over(partition by())
select *,sum(cost) over(distribute by month(orderdate)) from business;
结果如图所示:
三、上述场景,将cost按时间累加
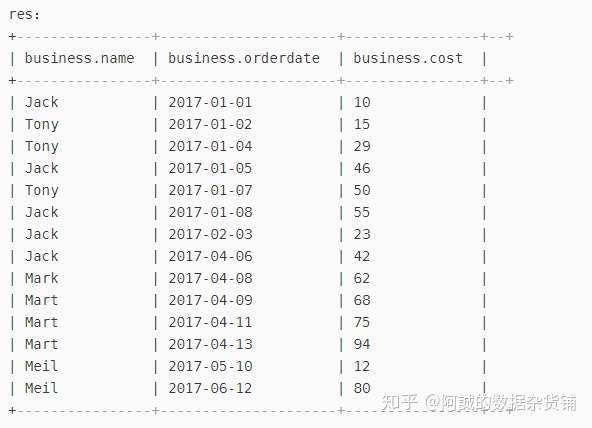
a、先按照购买时间进行排序
select * from business sort by orderdate;
结果如图所示:
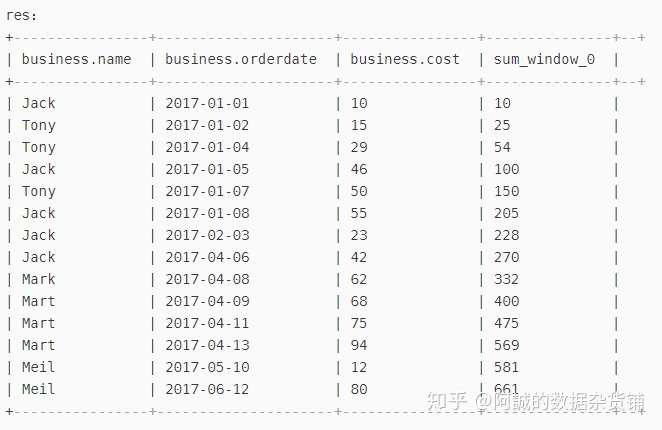
-- 参数讲解
-- sort by orderdate:按照购买日期进行排序
-- UNBOUNDED PRECEDING:从起点开始
-- CURRENT ROW:到当前行
-- 计算从开始到当前时间的总花费
select
*,
sum(cost) over(sort by orderdate rows between UNBOUNDED PRECEDING and CURRENT ROW)
from business;
结果如下图所示:
row函数:
current row:当前行
n PRECEDING:往前n行
n FOLLOWING:往后n行
UNBOUNDED:起点
UNBOUNDED PRECEDING:从前面起点
UNBOUNDED FOLLOWING:到后面终点
LAG(col,n):往前的第n行
LEAD(col,n):往后的第n行
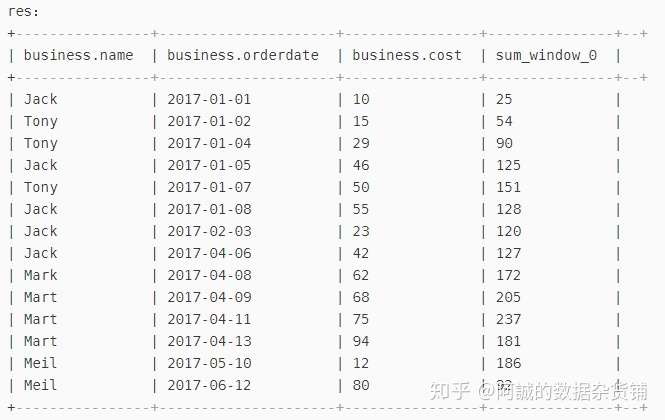
--参数讲解
-- sort by orderdate:按照时间排序
-- 1 preceding:当前行的前1行
-- 1 following:当前行的后一行
-- 计算相邻三行的值(第一行计算当前行 + 后一行; 最后一行计算当前行 + 前一行)
select
*,
sum(cost) over(sort by orderdate rows between 1 preceding and 1 following)
from business;
结果如下如所示:
demo2:
-- 参数详解:
-- distribute by name:按名字进行分区
-- sort by orderdate:在每个分区中按照时间进行排序
-- UNBOUNDED PRECEDING and current row:从起点行到当前行
-- 计算每个人一共的总花费
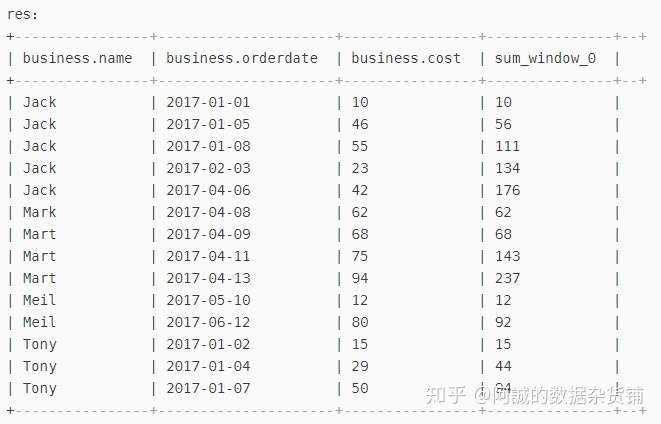
select
*,
sum(cost) over(distribute by name
sort by orderdate
rows between UNBOUNDED PRECEDING and current row)
from business;
结果如下图所示:
demo3:
--参数讲解:
-- sort by orderdate:按照时间排序
-- current row and unbounded following:当前行到终点行
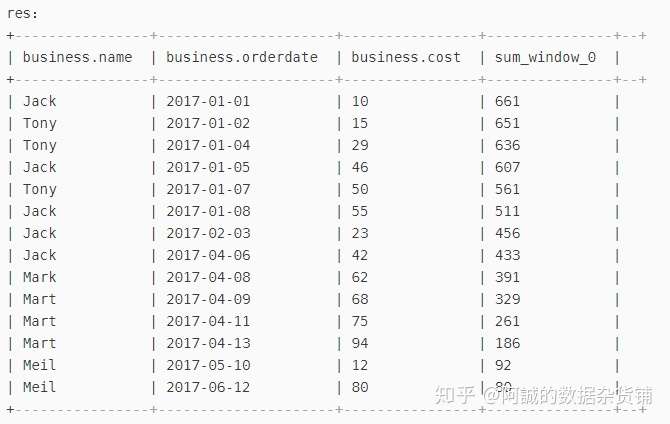
select
*,
sum(cost) over(sort by orderdate
rows between current row and unbounded following)
from business;
结果如下图所示:
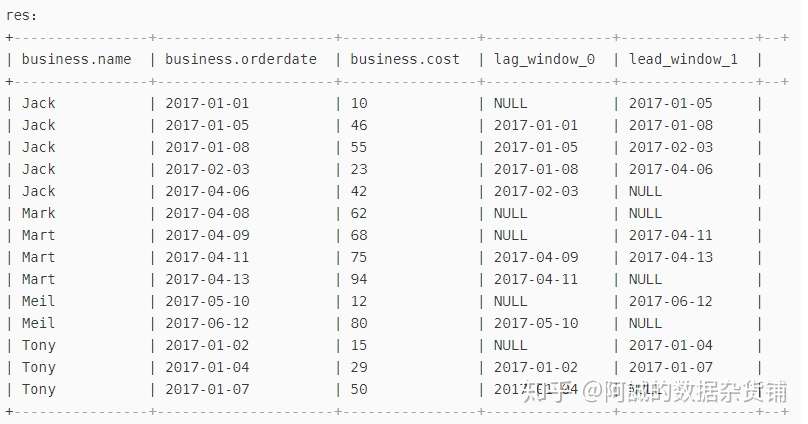
四、查询顾客上次购买时间,以及下次购买时间(电商网站常用于求页面跳转的前后时间)
分析:lag(clo,n):返回的是当前行的第前n行
-- 参数详解:
-- distribute by name:按照姓名分组
-- sort by orderdate:按照时间排序
-- lag(orderdate,1):返回当前orderdate行的前一行
-- lead(orderdate,1):返回当前orderdate行的后一行
select *,
lag(orderdate,1) over(distribute by name sort by orderdate),
lead(orderdate,1) over(distribute by name sort by orderdate)
from business;
结果如下图所示:
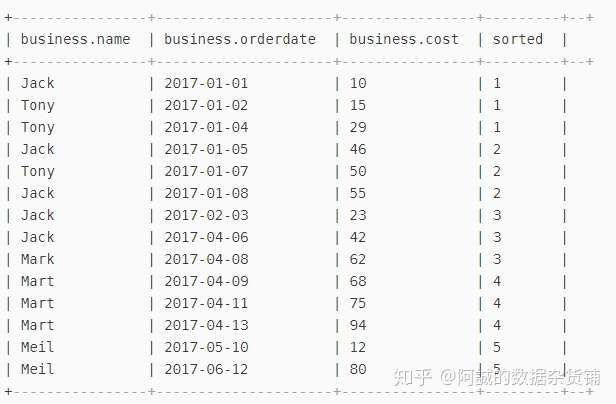
五、查询前20%购买的订单信息
分析:可以按照时间分成五等份,然后返回其中的第一份
NTILE(n):将数据等分成n份
select *, ntile(5) over(sort by orderdate) from business;
结果如下图所示:
-- 下面语句报错,因为 ntile、sum、agg等函数不能放在where后面当做查询条件select
*, ntile(5) over(sort by orderdate) as sorted
from business
where sorted = 1;
-- 下面语句报错,因为having必须跟在group by 语句后面
select
*, ntile(5) over(sort by orderdate) as sorted
from business
having sorted = 1;
-- 所以使用了子查询,将上一步查询的结果放在子句中 select name,orderdate,cost from ( select *,ntile(5) over(order by orderdate) sorted from business ) t where sorted = 1; -- Tips:子查询不能使用select *
第三套练习
-
每门学科学生成绩排名(是否并列排名、空位排名三种实现)
-
每门学科成绩排名top n的学生
原始数据(学生成绩信息)
name subject score
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
建表并加载数据
create table score
(
name string,
subject string,
score int
) row format delimited fields terminated by "\t";
#加载数据
load data local inpath '/home/fengGG/hive_test_data/score.txt' into table score;
查看数据
select * from score;
1、每门学科学生成绩排名(是否并列排名、空位排名三种实现)
select *,
row_number()over(partition by subject order by score desc),
rank()over(partition by subject order by score desc),
dense_rank()over(partition by subject order by score desc)
from score;
2、每门学科成绩排名top n的学生
select *
from(
select
*,row_number() over(partition by subject order by score desc) rmp
from score
) t
where t.rmp<=3;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号