
MapReduce:Shuffle过程详解

1、Map任务处理
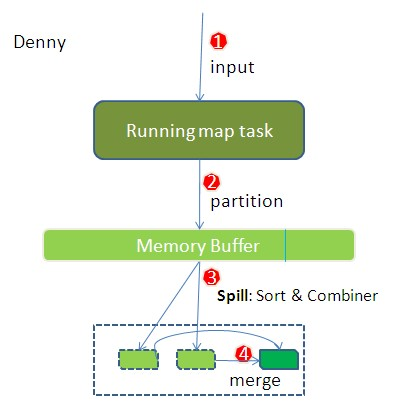
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。Partitioner
-
- partitioner的作用是将mapper输出的键/值对拆分为分片(shard),每个reducer对应一个分片。 默认情况下,partitioner先计算目标的散列值(通常为md5值)。然后,通过reducer个数执行取模运算key.hashCode()%(reducer的个数)。 这种方式不仅能够随机地将整个键空间平均分发给每个reducer,同时也能确保不同mapper产生的相同键能被分发至同一个reducer。 如果用户自己对Partitioner有需求,可以订制并设置到job上。 job.setPartitionerClass(clz);
1.4 溢写Split
-
- map之后的key/value对以及Partition的结果都会被序列化成字节数组写入缓冲区,这个内存缓冲区是有大小限制的,默认是100MB。
- 当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
- 当溢写线程启动后,需要对这80MB空间内的key做排序sort(1.5)
- 内存缓冲区没有对将发送到相同reduce端的数据做合并,那么这种合并应该是体现是磁盘文件中的。即Combine(1.6)。
1.5 对不同分区中的数据进行排序(按照k)Sort。
-
- 排序:每个分区内调用job.setSortComparatorClass()设置的Key比较函数类排序。可以看到,这本身就是一个二次排序。如果没有通过job.setSortComparatorClass()设置 Key比较函数类,则使用Key实现的compareTo()方法,即字典排序。job.setSortComparatorClass(clz); 排序后:<hello,1> <hello,1> <me,1> <you,1>
-
-
combiner是一个可选的本地reducer,可以在map阶段聚合数据。combiner通过执行单个map范围内的聚合,减少通过网络传输的数据量。
-
例如,一个聚合的计数是每个部分计数的总和,用户可以先将每个中间结果取和,再将中间结果的和相加,从而得到最终结果。
-
求平均值的时候不能用,因为123的平均是2,12平均再和3平均结果就不对了。Combiner应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景,比如累加,最大值等。
-
1.7 合并Merge
-
- 每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。
- 最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。
- “hello”从两个map task读取过来,因为它们有相同的key,所以得merge成group。什么是group。group中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。group后:<hello,{1,1}><me,{1}><you,{1}>
- 因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果设置过Combiner,也会使用Combiner来合并相同的key。
2、Reduce任务处理
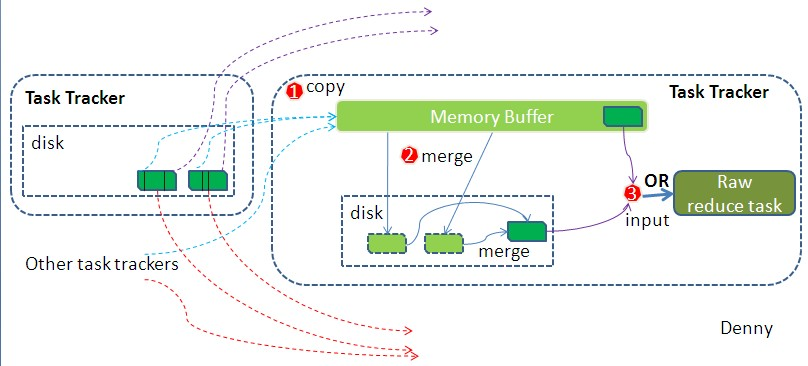
2.1 拉取数据Fetch
-
- Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2.2 合并Merge
-
- Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。
- 这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。
- 默认情况下第一种形式不启用。
- 当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,也有sort排序,如果设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束。
- 然后启动第三种磁盘到磁盘的merge方式,有相同的key的键值队,merge成group,job.setGroupingComparatorClass设置的分组函数类,进行分组,同一个分组的value放在一个迭代器里面(二次排序会重新设置分组规则)。如果未指定GroupingComparatorClass则则使用Key的实现的compareTo方法来对其分组。group中的值就是从不同溢写文件中读取出来的,group后:<hello,{1,1}><me,{1}><you,{1}>
- 最终的生成的文件作为Reducer的输入,整个Shuffle才最终结束。
2.3 Reduce
-
- Reducer执行业务逻辑,产生新的<k,v>输出,将结果写到HDFS中。
3、WordCount代码
package mapreduce; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountApp { static final String INPUT_PATH = "hdfs://chaoren:9000/hello"; static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf); Path outPath = new Path(OUT_PATH); if (fileSystem.exists(outPath)) { fileSystem.delete(outPath, true); } Job job = new Job(conf, WordCountApp.class.getSimpleName()); // 指定读取的文件位于哪里 FileInputFormat.setInputPaths(job, INPUT_PATH); // 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对 //job.setInputFormatClass(TextInputFormat.class); // 指定自定义的map类 job.setMapperClass(MyMapper.class); // map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略 //job.setOutputKeyClass(Text.class); //job.setOutputValueClass(LongWritable.class); // 指定自定义reduce类 job.setReducerClass(MyReducer.class); // 指定reduce的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 指定写出到哪里 FileOutputFormat.setOutputPath(job, outPath); // 指定输出文件的格式化类 //job.setOutputFormatClass(TextOutputFormat.class); // 分区 //job.setPartitionerClass(clz); // 排序、分组、归约 //job.setSortComparatorClass(clz); //job.setGroupingComparatorClass(clz); //job.setCombinerClass(clz); // 有一个reduce任务运行 //job.setNumReduceTasks(1); // 把job提交给jobtracker运行 job.waitForCompletion(true); } /** * * KEYIN 即K1 表示行的偏移量 * VALUEIN 即V1 表示行文本内容 * KEYOUT 即K2 表示行中出现的单词 * VALUEOUT 即V2 表示行中出现的单词的次数,固定值1 * */ static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { protected void map(LongWritable k1, Text v1, Context context) throws java.io.IOException, InterruptedException { String[] splited = v1.toString().split("\t"); for (String word : splited) { context.write(new Text(word), new LongWritable(1)); } }; } /** * KEYIN 即K2 表示行中出现的单词 * VALUEIN 即V2 表示出现的单词的次数 * KEYOUT 即K3 表示行中出现的不同单词 * VALUEOUT 即V3 表示行中出现的不同单词的总次数 */ static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s, Context ctx) throws java.io.IOException, InterruptedException { long times = 0L; for (LongWritable count : v2s) { times += count.get(); } ctx.write(k2, new LongWritable(times)); }; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号